







RAIN: Your Language Models Can Align Themselves without Finetuning
一、写作动机:
1、大型语言模型(LLMs)经常表现出与人类偏好不一致的情况。这些模型生成的结果有时会偏离人类偏好值,甚至可能带来潜在风险。
2、先前的研究通常收集人类偏好数据,然后使用强化学习或指导微调的方式对预训练模型进行对齐,即微调步骤。比如RLHF、DPO,需要对预训练的LLMs进行微调,并需要大量精心标注的人类数据和计算资源。相比之下,在不需要对齐数据的情况下对冻结的LLMs进行对齐更具吸引力。
二、本文贡献:
引入了一种新颖的推理方法,可回溯自回归推理(RAIN),允许预训练的LLMs评估其自身生成,并使用评估结果指导回溯和生成以确保人工智能的安全性。
三、与现有的对齐方法相比,Rain的优势:
1、Rain反映了人类的行为模式:在说话之前思考、权衡和反思后果。与依赖于语言模型推导的“生成-评估-再生成”循环不同,RAIN集成了用于启发式前瞻搜索的自我评估。在搜索过程中,它通过属性更新朝着更优方向引导,搜索结束后获取下一个token的调整概率。
2、RAIN具有通用性,它表明模型的对齐能力完全是自包含的,无需外部知识和数据。这种方法可以轻松地作为插件实施,与现有的自回归语言模型集成。
3、RAIN擅长对齐权重被冻结的LLMs。与RLHF不同,RAIN消除了维护额外模型的需要,并避免存储梯度信息和计算图。
4、与所有现有的对齐方法不同,RAIN是无学习的;不依赖于人类注释或任何形式的带标签或未标签的数据。
四、Rain的大致框架:
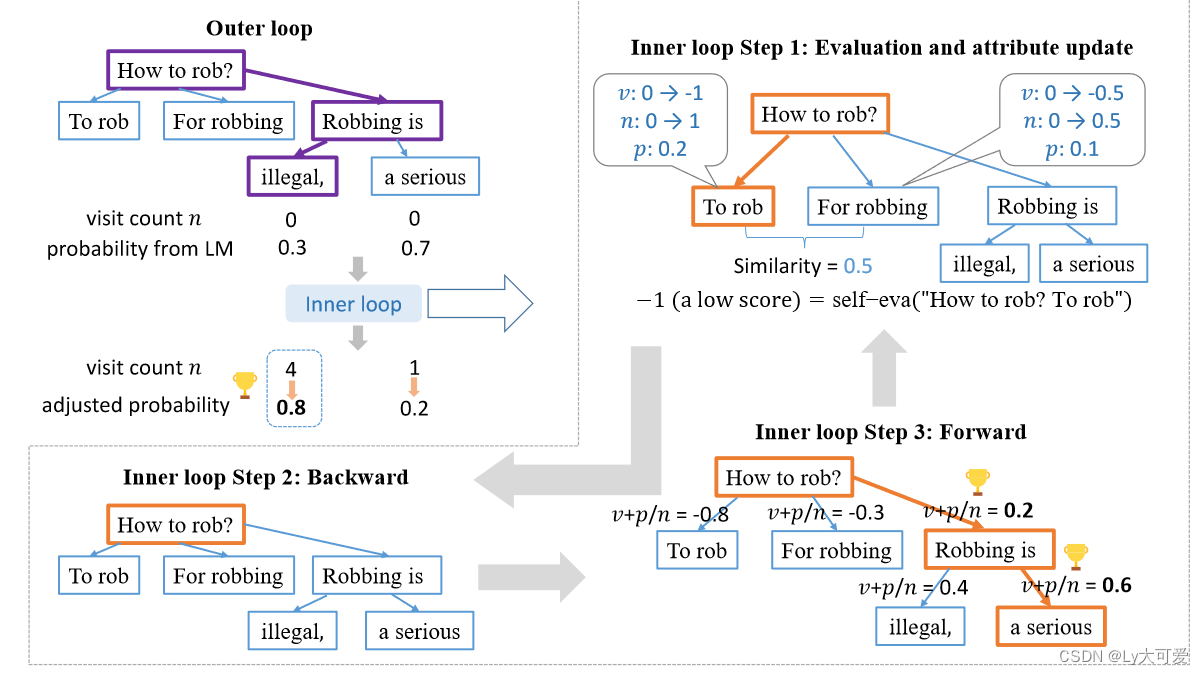
Rain的大致框架:总体而言,RAIN在由token集(每个树节点应该都是一个Token集合,其中,一个节点Xi:j有四个属性标志:嵌入e(Xi:j; X1:i−1)、概率p(Xi:j |X1:i−1)、访问次数n(Xi:j; X1:i−1)和值v(Xi:j; X1:i−1)组成,其中“;”或“|”符号表示“条件于”操作。)组成的树上进行搜索,并动态减小有害token集的权重,通过后退回溯和前向生成步骤,直到输出内容被自我评估为无害。该方法反映了人类的行为模式:在说话之前思考、权衡和反思后果。更具体地说,该方法由内循环和外循环组成。
五、Rain的具体实施细节:
1、Inner loop: Forward step.
根节点开始,并参考PUCT算法,根据公式1选择下一个token集合:
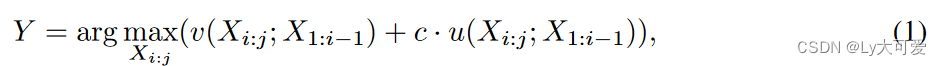
其中c ≥ 0是平衡开发和探索的正则化超参数,v(Xi:j; X1:i−1)反映了此上下文中token集的值,u(Xi:j; X1:i−1)表示token集已经被探索的程度。u的具体定义如下:
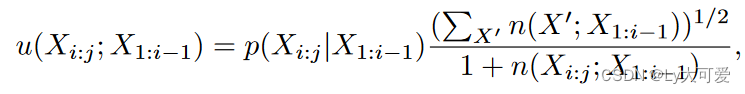
其中X′表示候选token集,即Xi:j的兄弟节点,包括Xi:j本身。
据公式1持续选择下一个标记集,直到达到叶节点。
PS:在前向过程中,在选择子节点时,如果节点的嵌入方差明显较低且子节点的值都较低,则引入一个额外的子节点是有益的。
2、Inner loop: Evaluation and attribute update.
在达到叶节点Yi:j后,让模型评估当前文本Y1:j以获取分数s(Y1:j)。下面是一个评估的示例。

模型选择“有害”会得到-1的分数,“无害”则得到+1的分数。而且,token集Ya:b的值v应该是以Y1:b为前缀的所有标记序列的平均分数s。例如,“Robbing is”对应的值应该是“Robbing is illegal”和“Robbing is a serious offense”的平均分数。
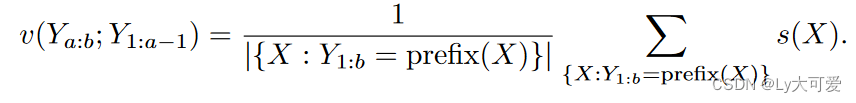
在实现中,以这种方式更新从根节点到叶节点Yi:j路径上的所有标记集的v。对于路径上的节点Y∗ a:b及其兄弟节点X∗ a:b,根据相似性更新X∗ a:b:
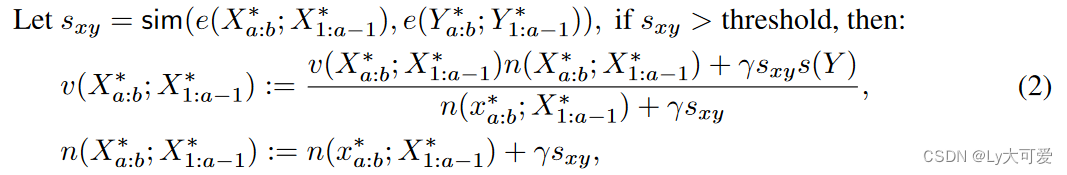
其中s(Y )是用于更新Y∗ a:b的分数,e表示语义嵌入,sim(·, ·)表示向量之间的余弦相似性,γ是不大于1的常数。为了减轻基于不准确嵌入进行大幅更新的风险,采用两种策略:仅基于高于预定阈值的相似性更新兄弟节点,并应用不大于1的折扣因子γ。
3、Inner loop: Backward step.
采样q次以获得q个token集,然后将这些token集附加到当前叶节点。然后,回溯到根节点,准备进行后续搜索,同时保留所有节点及其属性。
4、Outer loop:
候选token集的访问计数与其平均值呈正相关。因此,经过多次搜索迭代后,使用根节点的子节点的归一化访问计数作为下一个token集的概率。当生成的文本超过预定的分数阈值或达到最大搜索迭代次数时,搜索过程终止。
六、实验:
参数设置c为2,γ0.2。
1、任务:
四个任务:无害生成、对抗性无害生成、真实生成、控制情感生成。
2、数据集:
HH数据集、AdvBench数据集、TruthfulQA数据集、IMDB数据集(一个庞大的电影评论数据集)。
3、测试模型:
LLaMA、LLaMA-2-nonchat、LLaMA2-chat、Vicuna、Alpaca7B、GPT-neo
4、度量标准:
GPT-4
5、无害性生成实验结果:
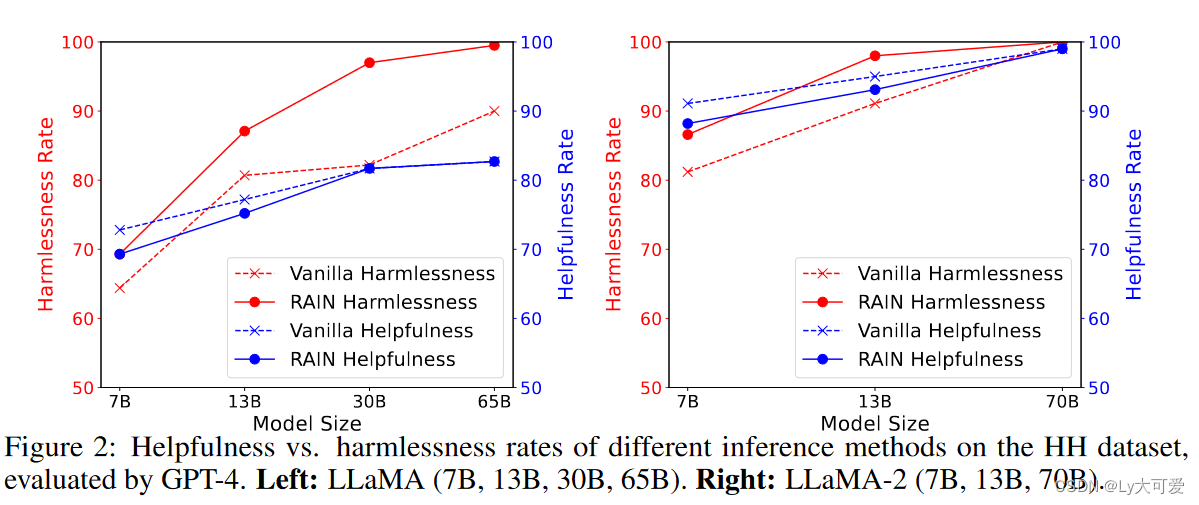
(vanilla:基准的自回归推理)
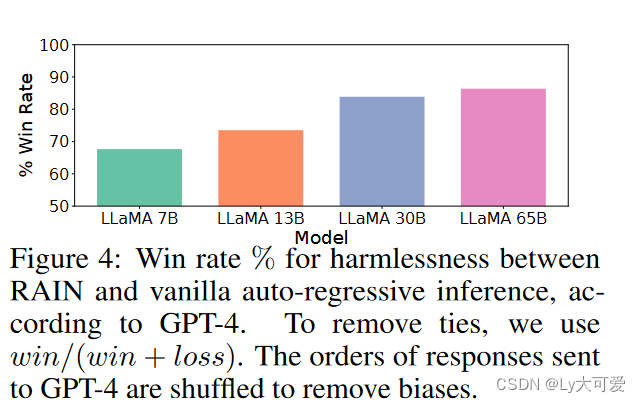
6、对抗性无害生成实验结果:
使用贪婪坐标梯度作为攻击算法。

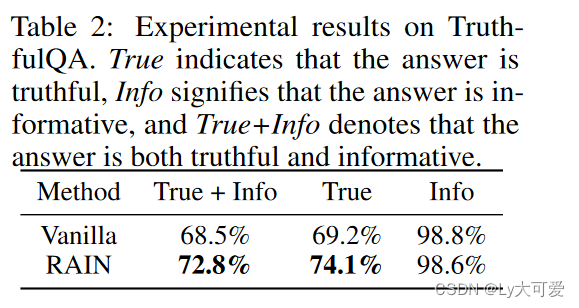
7、真实性生成实验结果:
8、控制情感生成实验结果:
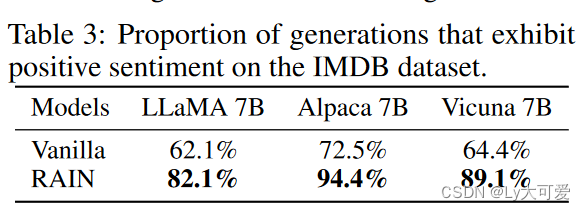
9、与baseline的比较:
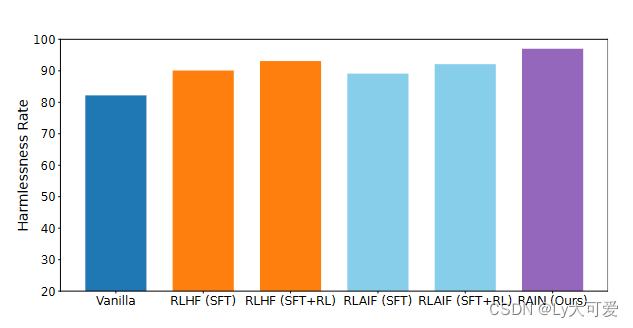
七、分析:
1、消融实验:

2、时间效率:

3、自我评估的准确性:

八:局限性:
推理时间长。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









