






摘要
本周学习了Word Embedding、Batch Normalization、attention的变体;复习了transformer;以及线性模型代码实操、对COVID 19 Cases Prediction (Regression)代码理解。Word Embedding是一种无监督的方法,将单词映射到连续向量空间,为词语赋予语义信息,使相似的单词在向量空间内距离更近,不相似的距离更远。Batch Normalization是一种优化方法,在每个小批量数据上进行归一化,使得网络层输入的均值和方差保持稳定。
ABSTRACT
This week, the focus of the study was on Word Embedding, Batch Normalization, and variants of attention. The Transformer model was reviewed, and practical implementation of linear models was conducted along with understanding the code for COVID-19 Cases Prediction (Regression).Word Embedding is an unsupervised method that maps words to continuous vector spaces, assigning semantic information to words. This allows similar words to have closer distances in the vector space, while dissimilar words have larger distances.Batch Normalization, on the other hand, is an optimization technique that normalizes the input data within each mini-batch, ensuring stable mean and variance for the network layers.
1 Unsupervised Learning: Word Embedding
1.1 定义
Word Embedding是一种单词表示类型,允许具有相似含义的单词在向量空间中具有相似的表示,使算法能够捕捉单词之间的语义关系。是一种无监督的学习方式,它通过阅读大量的材料学习单词的意思并生成相关词向量。
1.2 实现原理
生成Word Embedding最常用的方法是通过基于神经网络的模型,如Word2Vec、GloVe和FastText等。这些模型学习将单词映射到高维向量,使语义上相似的单词在向量空间中彼此靠近。训练过程涉及根据其相邻单词预测单词的上下文,或者根据上下文预测单词。随着模型准确地学习预测这些关系,Word Embedding捕捉到了有意义的语义信息。此外,这些模型可以在大型语料库上进行预训练,然后进行针对特定任务的微调以提高性能。
1.2.1 How to exploit the context?
- Count-based:Count-based方法通过统计词汇在语料库中的共同出现的频率来构建词向量。
- Perdition-based:Prediction-based方法尝试根据给定的上下文预测目标词,从而学习词向量。
① 定义模型结构:首先,定义一个模型结构,如神经网络模型,用于预测目标词。
② 输入表示:将目标词的上下文单词转化为向量表示,可以使用one-hot编码或者通过其他方式获得。
③ 模型训练:使用大量的训练数据,通过最大化目标词预测的概率或最小化损失函数来训练模型。
④ 提取词向量:在模型训练过程中,学习到的模型参数即为每个单词的词向量表示。
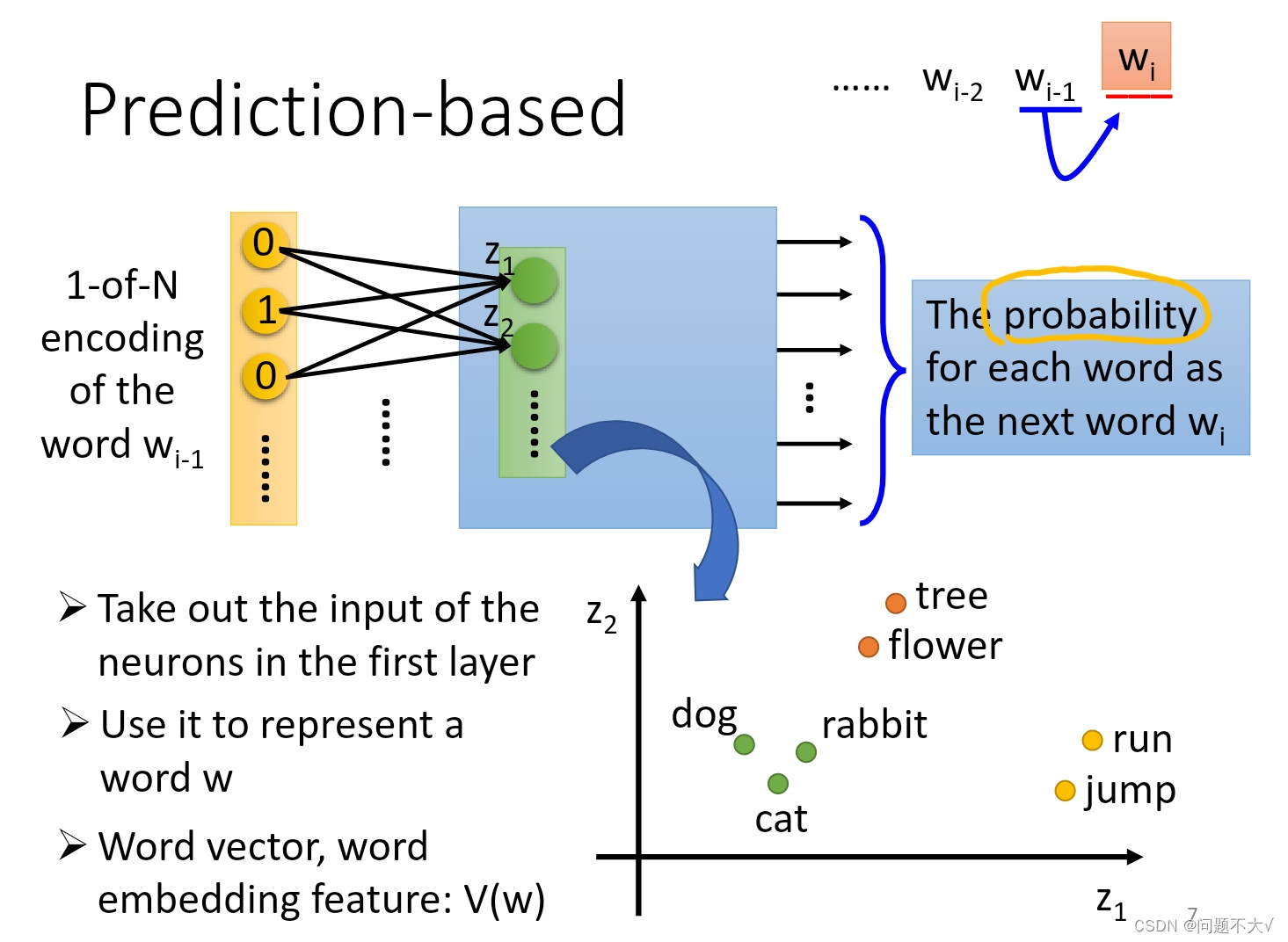
1.2.2 Question and Answer
— 为什么要在Prediction-based方法使用共享参数?有什么好处?
— 首先可以减少模型的参数数量:这样可以降低模型的复杂度,减少过拟合的风险,并提高模型的训练效率;其次可以提高泛化能力:共享参数可以帮助模型更好地泛化到不同长度或不同位置的输入上,这意味着模型可以更好地适应不同规模和结构的数据,从而提高了模型的鲁棒性和泛化能力;再次可以捕捉共性特征:通过共享参数,模型可以更好地捕捉数据中的共性特征,使得模型能够更好地理解数据中的模式和规律,从而提高了模型的表达能力。最后降低人工干预:共享参数可以减少对模型结构的人工干预,使得模型更加通用化。这使得模型更容易应用于不同的任务和数据集,减少了针对不同任务重新设计模型的需要。
— 为什么共享参数可以帮助模型更好地泛化到不同长度或不同位置的输入上?
— 待解决
— 为什么Word Embedding中的prediction-based方法只用一层网络?
— 计算效率: 单层网络相对于多层网络来说计算效率更高。在大规模语料库上进行词嵌入学习时,考虑到计算成本和效率,使用单层网络可以更快地进行训练和推理。参数数量: 单层网络具有较少的参数数量,这使得模型更加简单并且容易训练。与深层网络相比,单层网络不容易过拟合,并且更容易泛化到新的数据上。数据表征能力: 单层网络已经被证明在许多自然语言处理任务中具有很强的数据表征能力。通过合适的损失函数和训练技巧,单层网络可以学习到高质量的词嵌入表示,有效地捕捉单词之间的语义关系。模型简化: 在实践中,已经发现单层网络在许多自然语言处理任务中能够取得不错的性能,而且模型结构的简化有助于减少过拟合风险,并提高模型的鲁棒性。
1.3 优缺点
优点:
- 语义信息捕捉: Word Embedding可以捕捉单词之间的语义关系,使算法能够更加细致地理解单词的含义和上下文。
- 降维处理: Word Embedding可以降低输入空间的维度,有助于降低计算复杂性并提高模型性能。
- 泛化能力: 训练后,Word Embedding可以转移并用于各种自然语言处理任务,使其非常灵活。
缺点:
- 数据依赖: Word Embedding的质量高度依赖于训练语料库的质量和规模。有限或有偏见的数据可能导致不良的表示。
- 歧义处理: Word Embedding可能无法有效捕捉多义性(单词的多个含义)和同音异义词(拼写相同,含义不同)。
1.4 实际应用
Word Embedding在各种自然语言处理任务中得到应用,包括:
- 文本分类: 用于情感分析、垃圾邮件检测和主题分类。
- 信息检索: Word Embedding有助于基于语义相似性检索相关文档或段落。
- 命名实体识别: 有助于在文本数据中识别和分类人名、组织名和地名等命名实体。
- 机器翻译: Word Embedding通过捕捉不同语言中单词之间的语义相似性,有助于更好地进行翻译。
1.5 未来发展
- 上下文相关词向量(Contextualized Word Embedding)
- 多语言词向量(Multilingual Word Embedding)
- 长文本建模(Modeling Long Texts)
- 跨媒体词向量(Cross-modal Word Embedding)
- 解释性词向量(Interpretable Word Embedding)
2 Batch Normalization
2.1 定义
是一种深度神经网络训练中的优化方法。Batch Normalization通过在每个小批量数据上进行归一化,使得网络层输入的均值和方差保持稳定(均值为0,方差为1)(降低了模型对初始化权重的敏感度),从而减少了网络内部协变量偏移(covariate shift)问题的影响,加速了网络的训练。
具体操作:在每个mini-batch的数据上计算出均值和方差,并对当前mini-batch的每个特征进行标准化。即通过对每个输入进行减去均值、除以方差的方式,对其进行归一化处理。标准化后的结果再通过缩放和平移的方式进行调整,以便网络可以学习到合适的权重和偏置,最终得到更好的特征表示。
什么是网络内部协变量偏移?指的是在深度神经网络中,每一层的输入分布随着网络参数的更新而发生变化,导致网络训练过程中的不稳定性。具体来说,当网络的前一层参数发生变化时,会导致当前层的输入分布也发生变化。会导致梯度消失或者梯度爆炸和难以收敛的问题。为什么会导致梯度消失或者梯度爆炸?因为随着网络的加深,每一层的输入分布的不稳定性会逐渐放大,导致梯度在传播过程中被压缩或放大,进而影响梯度的有效传递和损失函数的优化。为什么难以收敛?当输入分布发生变化时,网络需要不断适应新的输入分布,这会导致网路训练的不稳定性,使得网络更难以收敛到一个较好的解。
2.2 Changing Landscape
Batch Normalization就是把崎岖的error surface变平滑的想法,将分散的数据统一,具有统一规格的数据, 能让机器学习更容易学习到数据之中的规律。
不要轻视优化问题的重要性,有时候即使你的误差曲面呈现碗状,也不能保证训练会很顺利。如下图横轴和纵轴两个参数对Loss的斜率差别非常大。如果这个时候使用固定的学习率,可能很难得到很好的结果。
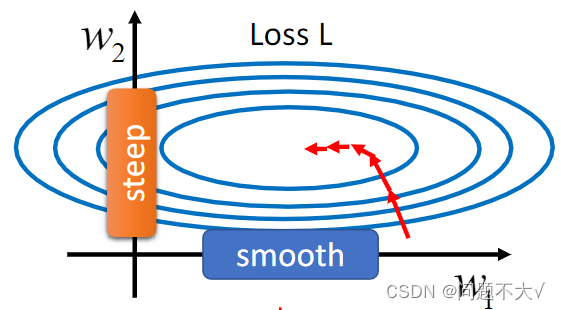
为什么会有这种w1跟 w2的斜率差很多的状况? 用一个例子来说明这件事,假设我们现在有一个非常简单的 linear model,没有 activation function,它的输入是 x1跟x2,它对应的参数是 w1跟 w2 ,如下所示:w1乘 x1,w2 乘 x2,再加上 b 以后就得到 y,然后会计算 y 跟之间的差距当做 e,把所有 training data 的 e 加起来就得到Loss。如果我们对w1进行一个小小的变换,输出的y就会改变,而y的改变又会导致e的改变,最终导致改变了L。这时我们可能会发现,由于x1 会直接乘上 w1, 在 delta w1 不变的情况下,如果x1本身的数量级很大,那么算出的delta就很大,w1 在 error surface 上的斜率就大;如果x1 本身的数量级很小,那么算出的delta就很小,w1在 error surface 上的斜率就小。
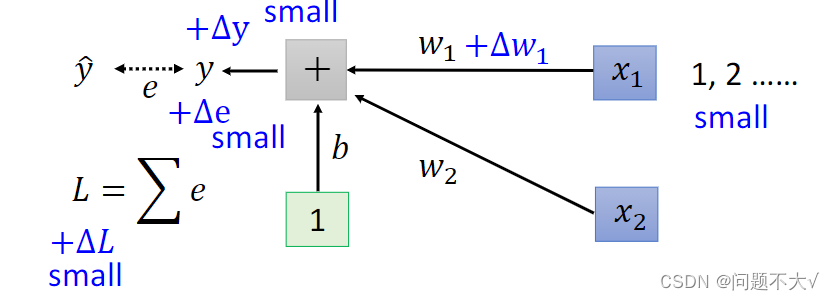
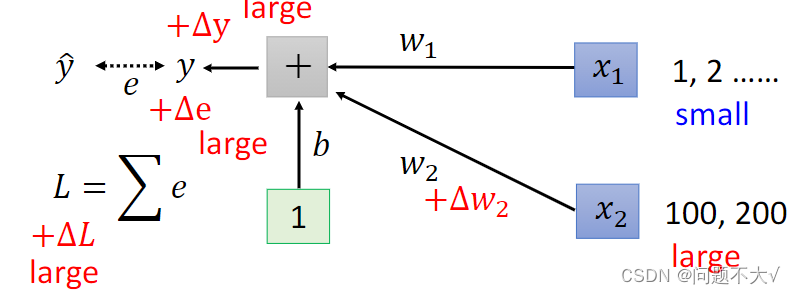
在这个线性模型里,当我们输入的每一个特征(在误差曲线上,每一个特征都代表一个维度),他们的取值范围相差很大的时候,我们就可能产生不同方向坡度非常不同的 error surface。所以如果我们可以让不同的维度拥有同样的范围,我们就有可能产生比较容易训练的error surface。可以用Feature Normalization来实现。
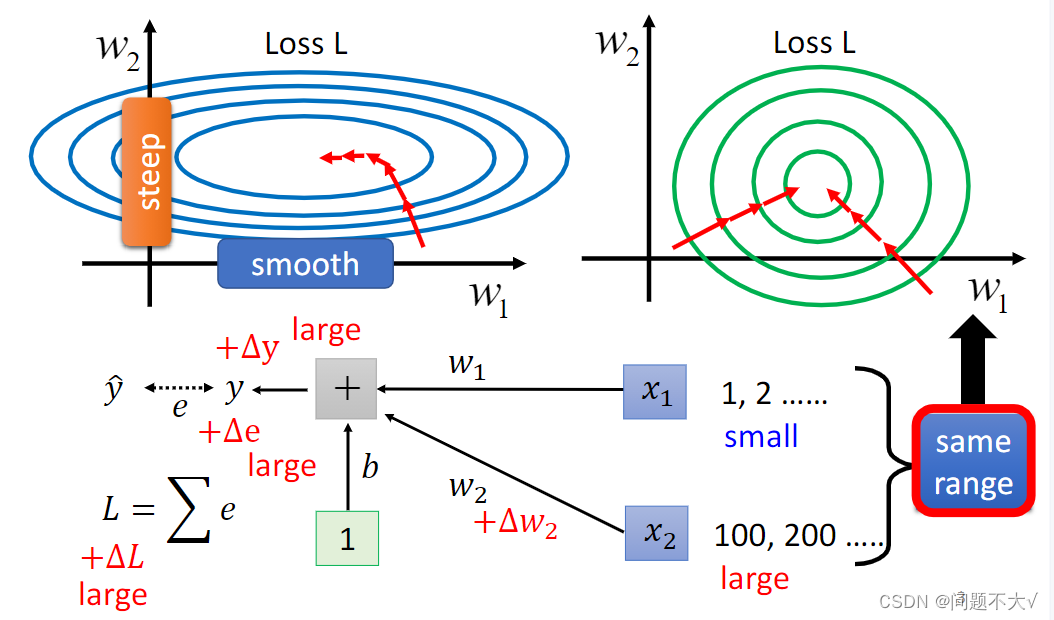
为什么参数的取值范围差别很大的时候,考虑固定学习率,会得不到好的结果?因为固定学习率意味着对所有参数应用相同大小的更新步长,而参数的取值范围差异很大时,一些参数可能会因为学习率太大而产生过大的更新,而另一些参数则可能因为学习率太小而更新缓慢,这就导致了无法很好地收敛到最优解。举个例子,如果一个参数的取值范围在 0 到 1 之间,而另一个参数的取值范围在 100 到 1000 之间,使用相同的固定学习率会导致对较小取值范围的参数变化过快,可能会导致错过最优解,而对于较大取值范围的参数,则可能需要更多的迭代才能收敛到最优解。
2.3 Feature Normalization
FN的其中一种情况:
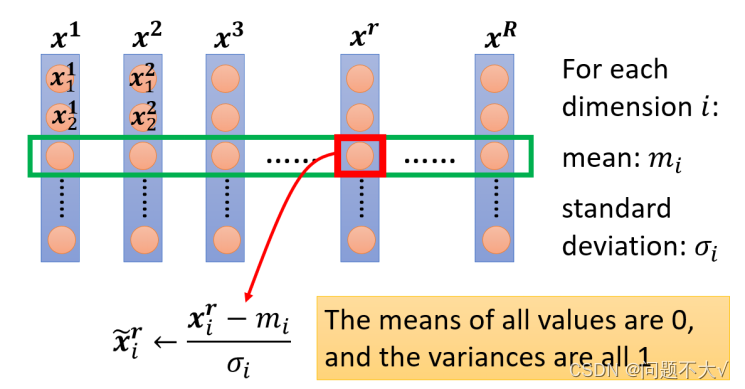
将特征矩阵里面的每一维特征取出来,对其求均值和方差,然后用上面那个式子计算,再将新算出来的值代替原来的值。(使输入之间变得有关联)
normalize 以后有什么好处呢?
①使得每一维的方差为1,均值为0(用替换后的数据进行运算)。这样就使得这一排数值的分布就都会在 0 上下。
②对每一个 dimension都做一样的 normalization,就会发现所有 feature 不同 dimension 的数值都在 0 上下,这样就更可能产生比较容易训练的error surface(产生圆碗的形状---都在一个范围内)
2.4 Considering Deep Learning
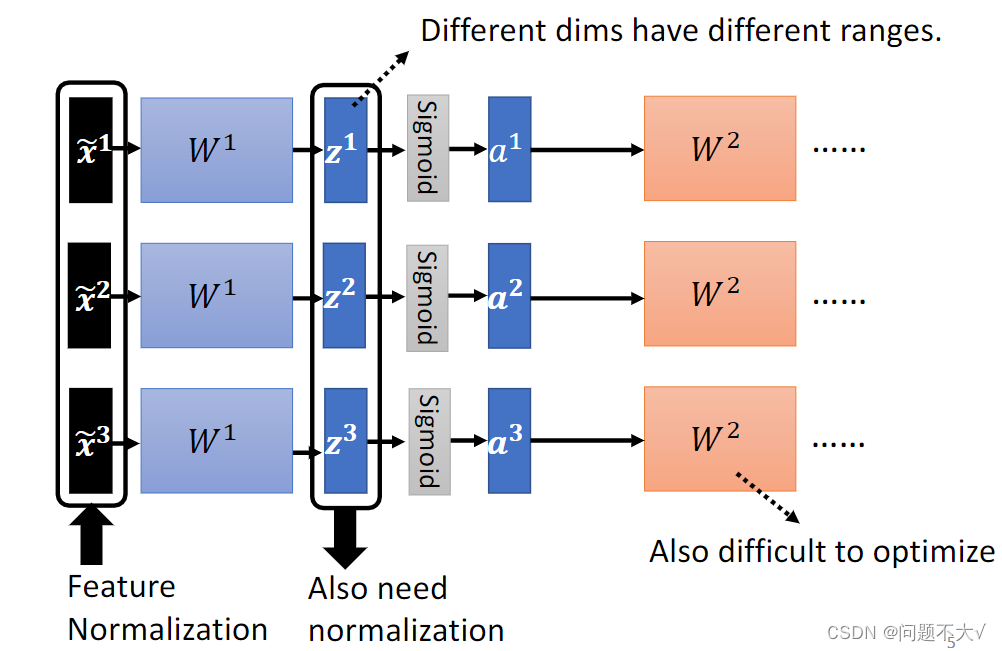
输入在经过我们的处理以后,会处于同一个范围内。但是当它经过一层网络以后,又需要作为下一层的输入,而对于下一层来说,这里的a1 a2 a3的数值的分布可能又有了很大的差异。对 w2 来说,这边的 a 或 z 其实也是一种 feature,我们应该要对这些 feature 也做 normalization。
可以发现,不做FN时。其中一个z改变时,只会改变对应的a,但做FN以后,均值和方差是使用输入数据计算出来的,改变z时,所有的a都会发生相应的改变。这样就使得输入之间变得有关联。
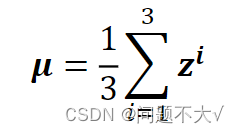
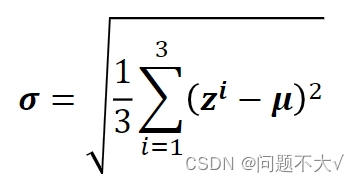
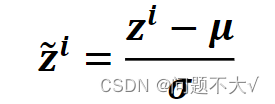
当数据很大的时候,通常没有办法将一大笔资料全部丢进模型,这个时候我们就要考虑batch(一般都只会丢一个batch里面的数据进去)。
为什么在做feature normalization的时候,只丢一个batch大小的数据进去训练?一个batch可以代表整个数据吗?

这边还要注意一个问题:
需要一个足够大的batch:一定要有一个够大的 batch,你才算得出比较有用的 μ 跟 σ 。举个极端一点的例子,假如我们的 batch size 设为 1,那你其实就没有什么 μ或 σ 可以算,也没什么意义。换句话说,这里的 μ跟 σ是两个统计量,我们在一个batch上统计这两个量,希望它能够代表整个data set的情况,所以你的batch一定不能太小,不然就不具有代表性。
2.5 优缺点
优点:
- 加速收敛速度:Batch Normalization有助于加速模型的收敛速度,减少了训练深度神经网络时的训练时间。
- 减少梯度消失问题:Batch Normalization有助于缓解梯度消失或梯度爆炸问题,使得深层网络的训练更加稳定。
- 允许更高的学习率:通过减少内部协变量偏移,Batch Normalization使得模型对学习率的选择更加鲁棒,可以使用更高的学习率进行训练。
缺点:
- 需要额外计算:Batch Normalization会引入额外的运算,尤其是在推理阶段,需要保存每个特征的均值和方差,在某些情况下增加了模型的推理成本。
- 不适用于小批量样本:当训练使用较小的batch size时,Batch Normalization的效果可能不佳,因为统计量的估计可能不准确。
- 限制了单样本的预测能力:在推理阶段,Batch Normalization使用了整个batch的统计数据,这意味着无法对单个样本进行预测,可能会影响模型的部署。
2.6 实际应用
Batch Normalization在深度学习中有着广泛的应用,特别是在卷积神经网络(CNN)和全连接神经网络中。以下是Batch Normalization的一些实际应用场景:
-
图像分类:在图像分类任务中,特别是在大规模的图像数据集上,使用Batch Normalization可以加速模型的收敛过程,提高准确性,并且能够处理不同尺度和亮度的图像。
-
目标检测:在目标检测领域,如Faster R-CNN、YOLO等模型中,Batch Normalization可以帮助加速训练过程,并提高检测准确性,特别是对于大规模复杂的数据集。
-
语音识别:在语音识别任务中,使用循环神经网络(RNN)或长短时记忆网络(LSTM)时,Batch Normalization可以有效地加速模型的收敛速度,提高模型的泛化能力。
-
自然语言处理:在自然语言处理领域,如文本分类、序列标注等任务中,通过在全连接层或者嵌入层上应用Batch Normalization,可以改善模型的性能和稳定性。
-
生成对抗网络(GAN):在生成对抗网络中,Batch Normalization可以帮助生成器网络更快地收敛到稳定状态,加速训练过程,并且有助于生成更具真实感的样本。
3 Transformer
3.1 定义
Transformer是一种神经网络架构,用于处理序列数据。可以把Transformer看作是一种“翻译机”,它能够读取一种语言的文本(英文),然后用另一种语言(中文)生成相同的含义。Transformer也会对输入数据中的重要部分给予更多关注。这使得模型能够更好地理解上下文关系,从而生成更准确的输出。
让Transformer更特殊的是其“自注意力”(Self-Attention)机制。这指的是模型可以考虑输入的所有部分来决定每个部分的重要性,而不仅仅是当前正在处理的部分。也就是可以捕获全局依赖。
3.2 Transformer的结构(Sequence-to-sequence)
Sequence-to-sequence:输入一个序列,输出一个序列,但是输出的长度由机器来自己来决定。
Transformer里的一些重要概念:
- 自注意力机制(Self-Attention Mechanism):使得模型在生成每个元素的表示时,可以考虑输入序列的所有元素。并根据其重要性进行加权。可以捕获序列中的长距离依赖。
- 位置编码(Positional Encoding):由于 Transformer 模型不像 RNN 那样具有内在的序列顺序概念,因此需要通过添加位置编码来提供序列中的位置信息。位置编码可以是基于正弦和余弦函数的函数,也可以是学习得到的。
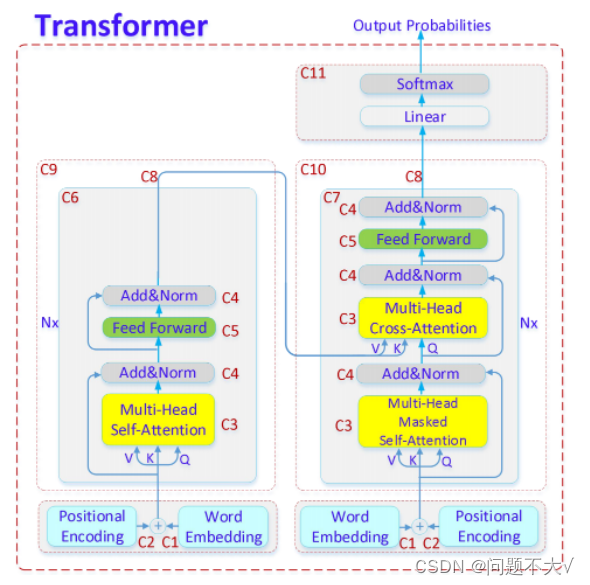
- 编码器与解码器(Encoder and Decoder):Transformer 模型由编码器和解码器组成。编码器接收输入序列,并生成一组连续的表示。解码器则使用这些表示来生成输出序列。每个编码器和解码器都由多个自注意力层和全连接层组成。
- 多头注意力(Multi-Head Attention):在 Transformer 中,通常会同时进行多次自注意力计算,这被称为多头注意力。不同的注意力“头”会学习到输入数据的不同方面。
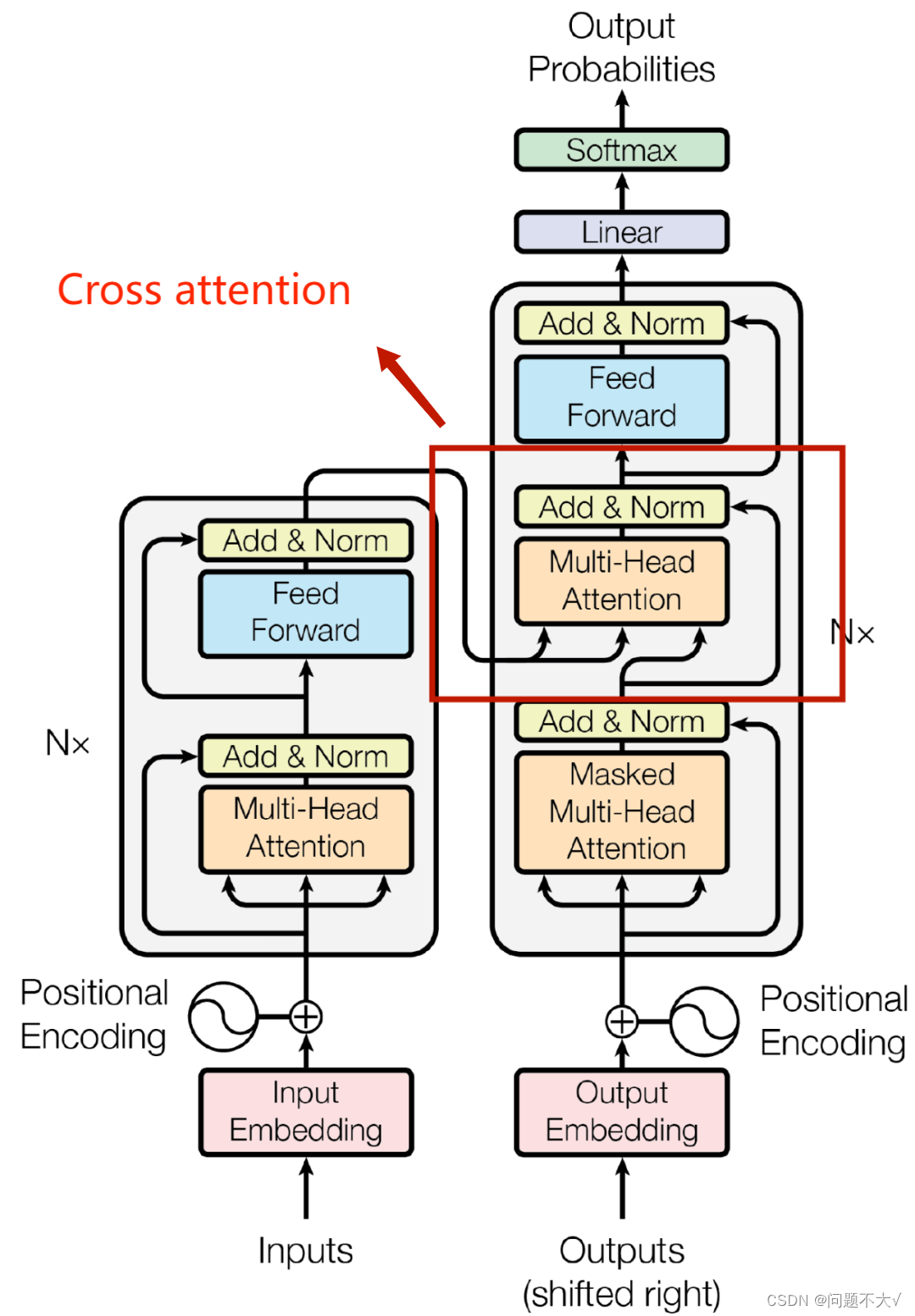
3.2.1 Encoder
Encoder(可以使用CNN/RNN):给一排向量,输出另外一排向量。 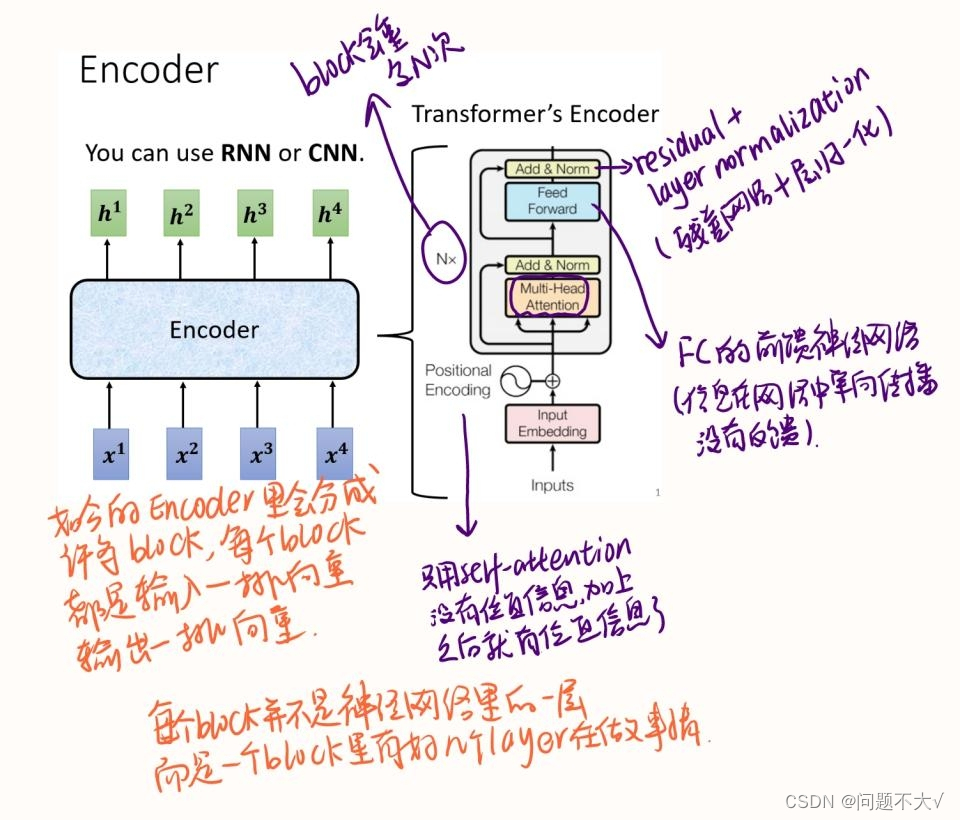
现在的encoder里面会分成很多的block,每个block都是输入一排向量输出一排向量。但是每个block并不是neural network的一层(layer),是因为一个block里面是好几个layer在做事情。
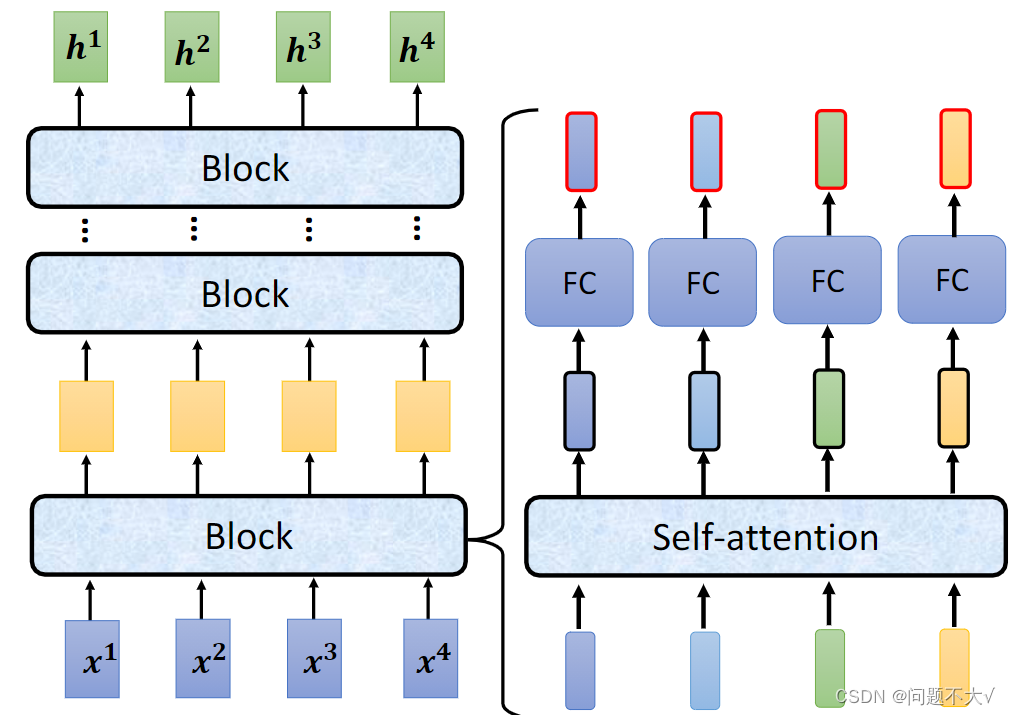
3.2.2 Decoder
Decoder:输出的东西是一个一个产生的,自己决定输出的长度。Decoder自己决定输出的长度,但是到底输出的sequence的长度应该是多少呢?也就是机器如何决定该何时停下来。这里没办法决定,输出多少是非常复杂的,我们其实是期望机器可以自己学到。(输出END)
Autoregressive decoder(AT)(自回归解码器):首先输入start表示解码开始,将Encoder里的数据输入进去,然后产生“机”,再将“机”作为下一次的输入,产生“器”,一直循环下去,知道碰到终止。当decoder在产生一个句子的时候,它其实有可能看到错误的东西,因为它是将自己的输出作为产生下一个字符的输入,而那个输出有可能是错误的。这里就会产生一个疑问:让decoder看到自己产生出来的错误的输入,再被decoder自己吃进去会不会造成Error Propagation(一步错,步步错)的问题呢?这种情况下,如果Decoder在生成某个位置的词时受到前面错误的词的影响,那么这个错误可能会一直传播下去,最终导致整个序列的错误。
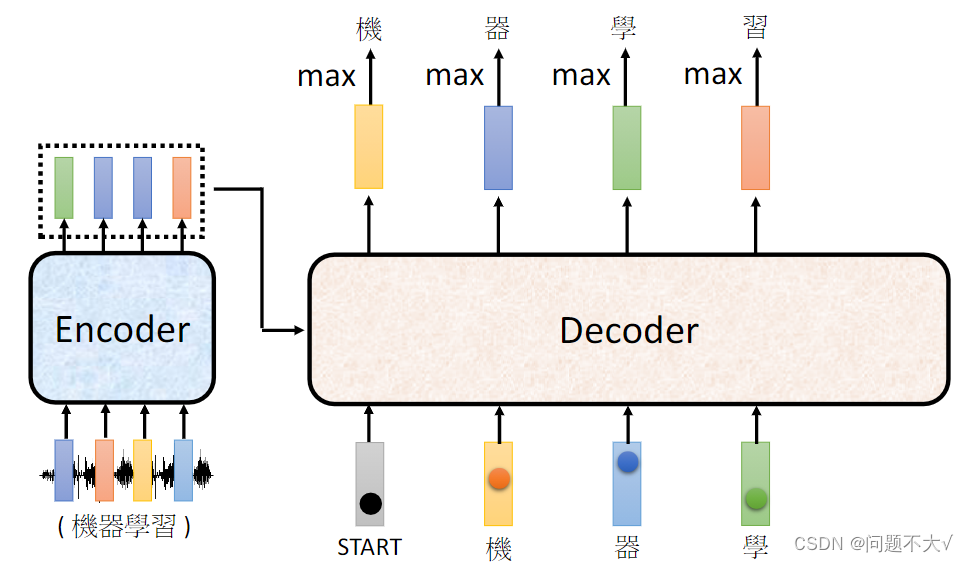

3.2.3 Encoder V.S. Decoder
Decoder和Encoder的不同:
(1)Decoder最后会做一个softmax,使得它的输出变成一个几率。
(2)加了一个Masked。(现在我们不能再看右边的部分,也就是我们产生b1的时候只能考虑a1的资讯,不能去看a2、a3、a4,产生b2的时候只能考虑a1、a2的资讯,不能考虑a3、a4的资讯,后面类似,最后产生b4时可以考虑所有的资讯)
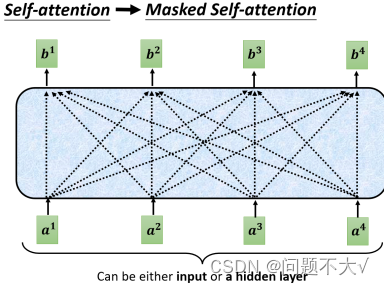
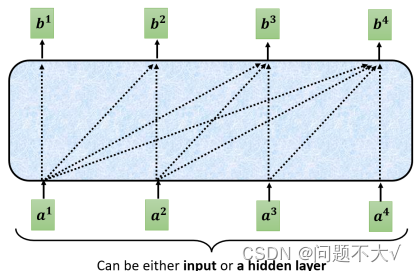
一开始decoder的运作方式它是一个一个输出的,是先有a1,再有a2,然后是a3、a4,所以当计算b2时是没有a3和a4的,所以没办法将后面的考虑进来。这跟原来的Self-Attention不一样,原来的Self-Attention中a1到a4是一次整个输入到Model里面的。
Transformer的Decoder为什么要引入Masked self-attention?主要出于两个原因:
①避免信息泄露:在解码过程中,为了确保模型只能看见当前位置之前的信息,需要对未来位置的信息进行屏蔽,以避免信息泄露。如果在解码时不考虑masked self-attention,模型可能会在生成当前位置的词时利用未来位置的信息,导致信息泄露和不正确的预测。②确保自回归性:Transformer的解码器是一个自回归模型,它需要按顺序逐步生成目标序列。在每一步生成时, 只能利用已经生成的部分序列作为输入,而不能利用当前位置之后的信息。通过使用masked self-attention,可以确保在每个解码步骤中,模型只能关注到当前位置及之前的部分,从而满足自回归性的要求。因此,为了保证解码器在生成目标序列时能够正确地按顺序逐步生成,并且不会利用未来信息,需要在self-attention机制中使用mask来屏蔽未来位置的信息。这样做可以确保模型在解码过程中能够产生合理的输出,并且符合自回归的生成要求。masked self-attention在Transformer的解码器中起着至关重要的作用,使得模型能够更好地应对生成任务。
自回归模型?
是一种统计模型,用于描述一个变量如何依赖其自身之前的取值。在时间序列分析和自然语言处理等领域,自回归模型被广泛应用。自回归模型是一种建立当前值与过去值之间关系的模型,它能够捕捉到变量内部的时间相关性或者序列相关性。
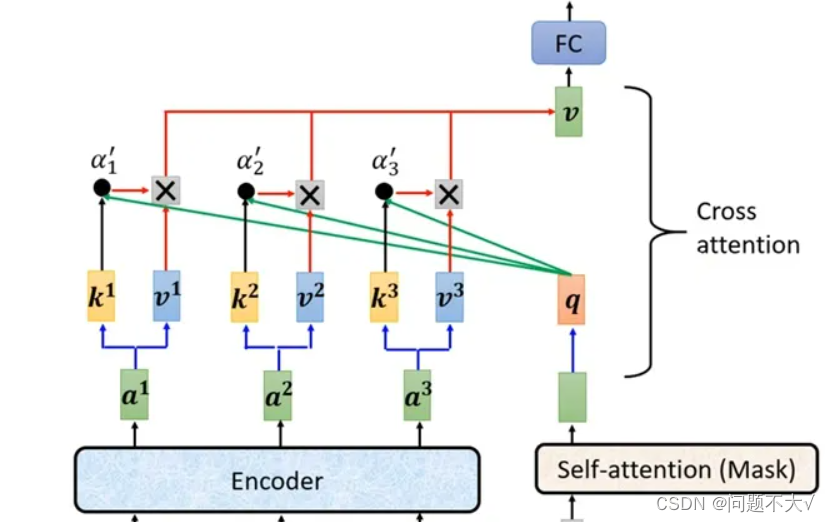
3.2.4 Cross Attention
是连接Encoder跟Decoder之间的桥梁。允许模型在处理一个序列时,能够同时关注另一个相关的序列,从而更好地捕捉它们之间的关联信息。在实践中,跨注意力机制通常会结合自注意力机制(self-attention)来实现。自注意力机制主要用于处理单个序列内部的信息关联,而跨注意力机制则在此基础上将不同序列之间的信息关联考虑进来。以Transformer模型为例,它就是通过使用自注意力机制和跨注意力机制来实现序列到序列的建模,其中自注意力机制用于捕捉序列内部的依赖关系,而跨注意力机制用于捕捉不同序列之间的关联信息。
3.3 优缺点
优点:
-
并行计算:相较于循环神经网络(RNN)等序列模型,Transformer 模型能够有效地进行并行计算,因为在自注意力机制中,所有的位置都可以同时计算注意力权重,这使得 Transformer 在处理长序列时具有明显的计算优势。
-
长距离依赖性:Transformer 模型通过自注意力机制能够更好地捕捉长距离的依赖关系,这使得它在处理长文本或长序列数据时表现较好,例如在机器翻译中能够更好地捕捉源语言和目标语言之间的长距离对应关系。
-
模块化:Transformer 模型的结构相对清晰,由多个堆叠的编码器-解码器模块组成,每个模块都有明确定义的输入输出,这种模块化的结构使得它更易于理解和修改。
-
捕捉全局信息:自注意力机制允许每个位置都可以依赖其他所有位置的表示,这使得 Transformer 能够更好地捕捉全局信息,有利于提高模型的泛化能力。
缺点:
-
计算资源消耗:由于 Transformer 模型需要处理全连接的自注意力操作,其计算复杂度较高,特别是在处理大规模数据集时会消耗大量的计算资源。
-
需要大量数据:与传统的 RNN 模型相比,Transformer 模型通常需要更大规模的数据来进行训练,以避免过拟合,这可能对一些数据稀缺的任务构成挑战。
-
对位置信息敏感:原始的 Transformer 模型并未直接考虑输入序列的位置信息,虽然可以通过添加位置编码来解决这一问题,但这样的处理方式也增加了模型的复杂性。
3.4 实际应用
Transformer 模型作为一种强大的深度学习模型,在自然语言处理和其他领域有着广泛的实际应用。以下是一些 Transformer 模型的实际应用:
-
机器翻译:Transformer 模型在机器翻译任务中取得了巨大成功,尤其是通过 Google 的 "Transformer" 模型(即基于注意力机制的 Transformer 模型)的提出,使得神经网络在翻译任务上取得了新的突破。目前,很多在线翻译服务都在采用 Transformer 模型进行翻译。
-
文本生成:Transformer 模型在文本生成任务中也有广泛的应用,包括语言模型的训练、对话系统的构建、文本摘要等方面。通过生成式的方式,Transformer 能够生成具有语义和逻辑关系的文本。
-
语言建模:由于 Transformer 模型能够捕捉长距离依赖性和全局信息,因此在语言建模任务中具有很好的表现,可以被用来预测下一个单词或者生成连贯的句子。
-
语音识别:Transformer 模型在语音识别任务中也有所应用,能够将语音信号转换成文字。通过结合自注意力机制和卷积神经网络,Transformer 能够更好地捕捉语音数据之间的依赖关系。
-
推荐系统:Transformer 模型可以用于个性化推荐系统,通过学习用户和商品之间的关系,从而更加准确地为用户推荐商品。
-
图像处理:除了自然语言处理领域,Transformer 模型也被用于图像处理任务,例如图像生成、图像描述生成等方面,通过自注意力机制来捕捉图像中不同位置的特征之间的关系。
3.5 未来发展
Transformer 模型在深度学习领域有着广泛的应用,并且随着不断的改进和优化,其未来发展方向包括但不限于以下几个方面:
-
模型规模的扩大:随着计算资源的增加,未来 Transformer 模型可能会继续扩大规模,包括更多的层、更多的参数,从而提高模型的表示能力和学习能力。
-
跨模态应用:除了在自然语言处理领域,未来的 Transformer 模型有望应用到更多的跨模态任务中,如图像处理、视频理解等。通过结合文本和视觉信息,Transformer 模型可以更好地理解和处理多模态数据。
-
改进的注意力机制:未来的研究可能会集中在改进自注意力机制,以处理长序列和长距离依赖关系时的效率和性能问题,比如探索更加高效的注意力机制结构,或者结合其他注意力机制来处理特定类型的输入数据。
-
迁移学习与领域自适应:针对数据稀缺的任务,未来的研究可能致力于在 Transformer 模型中实现更好的迁移学习和领域自适应能力,从而使得模型能够更好地适应新的领域和任务。
-
模型压缩与加速:为了使得 Transformer 模型能够在移动设备上得到更好的应用,未来的研究可能会集中在模型压缩和加速技术上,以减小模型的体积和计算量,同时保持较高的性能。
-
可解释性和因果推理:随着对模型可解释性的要求日益增加,未来的 Transformer 模型可能会更注重开发可解释性强的模型结构,以及支持因果推理的能力。
4 线性模型代码实操(刘二大人)
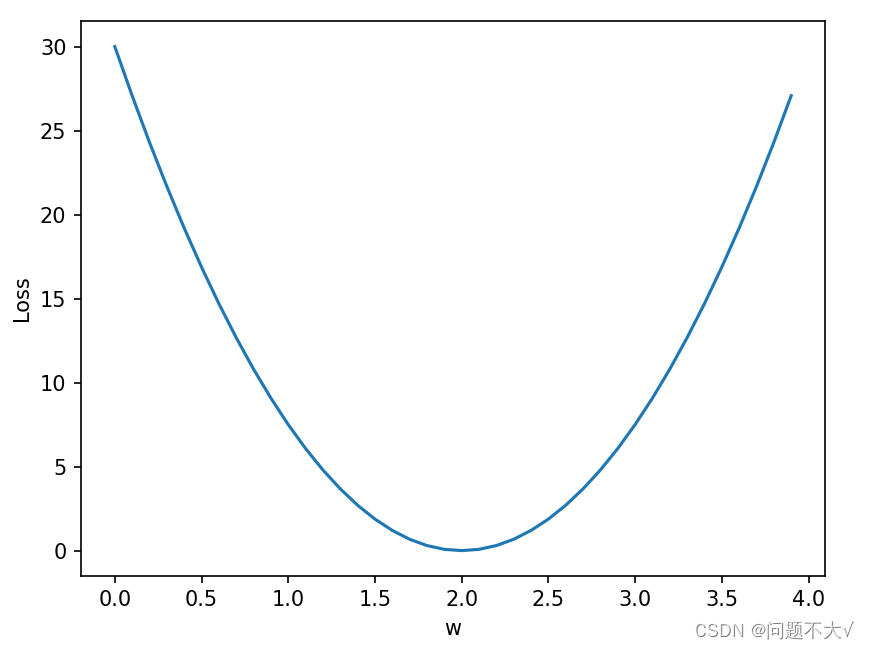
4.1 Y=WX的损失函数的代码与图像:
import numpy as np
import matplotlib.pyplot as plt
# 准备数据集
x_data = [1.0, 2.0, 3.0, 4.0]
y_data = [2.0, 4.0, 6.0, 8.0]
# 前馈网络
def forward(x):
return x * w
# 损失函数定义
def loss(x, y):
y_pred = forward(x)
return (y_pred - y)*(y_pred - y)
# 准备两个数组装w和mse
w_list = []
mse_list = []
# 进行训练
for w in np.arange(0.0, 4.0, 0.1):
print("w=", w)
l_sum = 0 # 损失值初始化为0
for x_val, y_val in zip(x_data, y_data):
y_pred_val = forward(x_val)
loss_val = loss(x_val, y_val)
l_sum += loss_val
print('\t', x_val, y_val, y_pred_val, loss_val)
print('MSE=', l_sum/4)
w_list.append(w)
mse_list.append(l_sum/4)
# 画图
plt.plot(w_list, mse_list)
plt.ylabel("Loss")
plt.xlabel("w")
plt.show()运行结果:
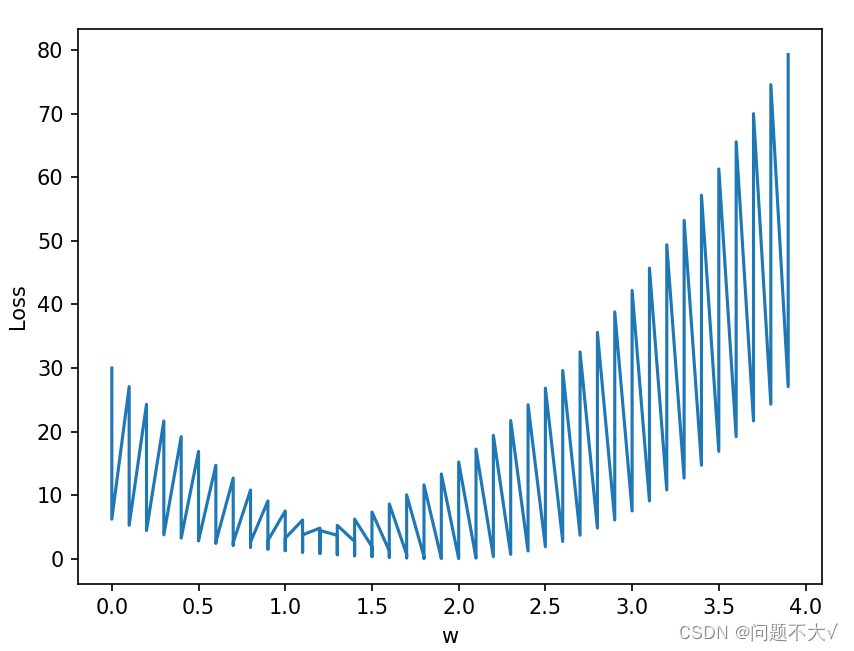
4.2 Y=WX+B的损失函数的代码与图像:
我一开始的错误思路,没有想到他现在是有两个参数:
import numpy as np
import matplotlib.pyplot as plt
# 准备数据集
x_data = [1.0, 2.0, 3.0, 4.0]
y_data = [2.0, 4.0, 6.0, 8.0]
# 前馈网络
def forward(x, w, b):
return x*w + b
# 损失函数定义
def loss(x, y, w, b):
y_pred = forward(x, w, b)
return (y_pred - y)*(y_pred - y)
w_list = []
b_list = []
mse_list = []
for w in np.arange(0.0, 4.0, 0.1):
print("w=", w)
for b in np.arange(0.0, 4.0, 0.1):
print("b=", b)
l_sum = 0
for x_val, y_val in zip(x_data, y_data):
y_pred_val = forward(x_val, w, b)
loss_val = loss(x_val, y_val, w, b)
l_sum += loss_val
print('\t', x_val, y_val, y_pred_val, loss_val)
print('MSE=', l_sum/4)
w_list.append(w)
b_list.append(b)
mse_list.append(l_sum/4)
plt.plot(w_list, mse_list)
plt.ylabel("Loss")
plt.xlabel("w")
plt.show()运行结果:
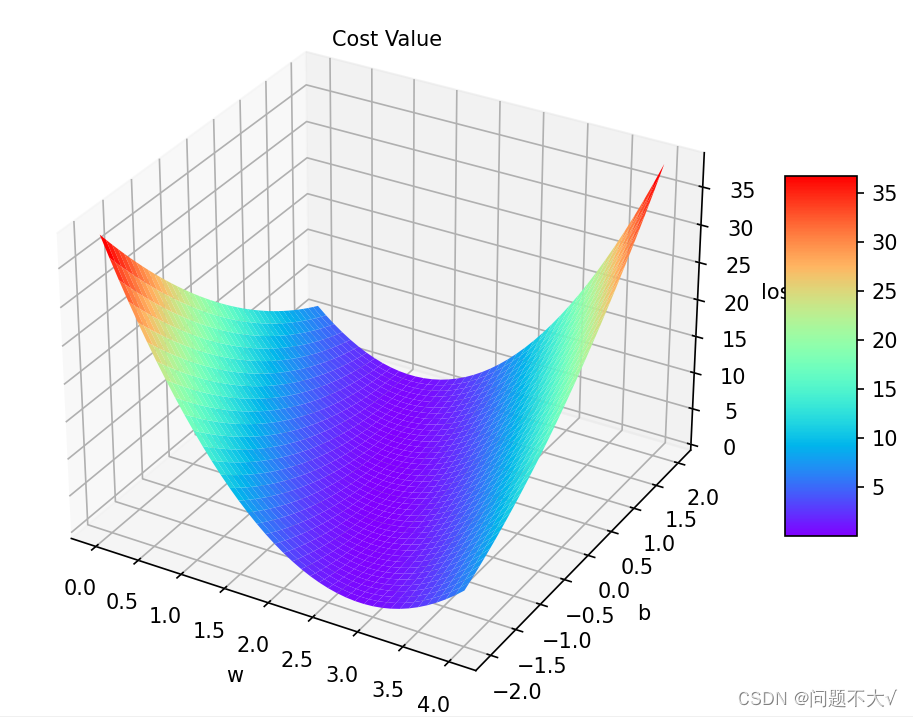
正确解法:参考代码 以后绘制3D图可以参考以下代码。
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
x_data = [1.0, 2.0, 3.0]
y_data = [2.0, 4.0, 6.0]
def forward(x):
return x * w + b
def loss(x, y):
y_pred = forward(x)
return (y_pred - y) ** 2
mse_list = []
W = np.arange(0.0, 4.1, 0.1)
B = np.arange(-2.0, 2.1, 0.1)
# meshgrid函数生成的X,Y是大小相等的矩阵,xgv,ygv是两个网格矢量,xgv,ygv都是行向量
[w, b] = np.meshgrid(W, B)
l_sum = 0
for x_val, y_val in zip(x_data, y_data):
y_pred_val = forward(x_val)
print(y_pred_val)
loss_val = loss(x_val, y_val)
l_sum += loss_val
fig = plt.figure()
# ax = Axes3D(fig)
# ax = Axes3D(fig) # 原代码在新版本的画图上用不了,所以改成以下新代码,或者降低版本
ax = fig.add_axes(Axes3D(fig)) # 新代码
ax.set_xlabel("w")
ax.set_ylabel("b")
ax.set_zlabel("loss")
ax.text(0.2, 2, 43, "Cost Value")
surf = ax.plot_surface(w, b, l_sum / 3, cmap=plt.get_cmap('rainbow'))
fig.colorbar(surf, shrink=0.5, aspect=5)
plt.show()运行结果:
5 COVID 19 Cases Prediction (Regression)代码理解
5.1 数据集准备
我尝试过很多下载数据的方式,都下载不下来,最后是在百度网盘里面下载的csv数据。训练集中给出美国某些州五天COVID-19的感染人数(及相关特征数据),测试集中给出前四天的相关数据,预测第五天的感染人数。

5.2 导入相关包:
# 数学操作
import math
import numpy as np
from sklearn.model_selection import train_test_split
# 读写数据
import pandas as pd
import os
import csv
# 进度条显示
from tqdm import tqdm
from d2l import torch as d2l
# pytorch
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader, random_split, TensorDataset
# 绘制学习曲线
from torch.utils.tensorboard import SummaryWriter5.3 一些重要的函数:
# 设置种子 设置随机数生成器的种子是为了确保在进行随机操作时,可以得到可重现的结果,
# 通过设置不同库的随机数种子,以确保在同一个种子下每次运行时得到的随机结果是一致的,
# 从而实现结果的可重现性。
def same_seed(seed):
'''Fixes random number generator seeds for reproducibility.'''
# 使得在同一个种子下,每次运行时CuDNN的计算结果是确定的,以确保结果的可重现性。
会使用确定性算法来执行卷积操作
torch.backends.cudnn.deterministic = True
# 禁用CuDNN中的benchmark功能,以确保每次运行时的计算结果是一致的。
寻找最快的卷积算法进行计算
torch.backends.cudnn.benchmark = False
# 使用NumPy库,并将随机数生成器的种子seed传递给np.random.seed(),以确保在同一个种子下,NumPy生成的随机数也是相同的。
np.random.seed(seed)
# 将seed传递给torch.manual_seed(),以确保PyTorch中的随机数生成器使用相同的种子
torch.manual_seed(seed)
# 首先检查系统是否有GPU可用,然后如果有GPU,则将种子seed传递给torch.cuda.manual_seed_all(),以确保在同一个种子下,GPU计算时的随机结果也是可重现的
if torch.cuda.is_available():
torch.cuda.manual_seed_all(seed)
# 划分数据集:训练集和验证集
# data_set代表输入的训练数据集,valid_ratio表示验证集所占的比例,seed是随机种子,指定随机种子来确保拆分的可重复性
def train_valid_split(data_set, valid_ratio, seed):
'''Split provided training data into training set and validation set'''
valid_set_size = int(valid_ratio * len(data_set))
train_set_size = len(data_set) - valid_set_size
# 利用了PyTorch的random_split函数将数据集data_set按照给定的大小拆分为训练集和验证集。random_split函数接受三个参数,第一个参数是待划分的数据集,第二个参数是一个整数列表,表示每个子集的大小,第三个参数是一个指定了随机种子的生成器,用于控制数据集的随机拆分过程
train_set, valid_set = random_split(data_set, [train_set_size, valid_set_size],
generator=torch.Generator().manual_seed(seed))
# 使用了np.array将PyTorch的Dataset对象转换为NumPy数组
return np.array(train_set), np.array(valid_set)
# 用于对测试数据集进行预测
# test_loader代表测试数据集的数据加载器,model代表训练好的模型,device代表模型所在的设备(如CPU或GPU)
def predict(test_loader, model, device):
model.eval() # Set your model to evaluation mode.
preds = []
# 用于遍历测试数据集test_loader,并对每个样本进行模型预测
for x in tqdm(test_loader):
# 首先将输入数据x移动到指定的设备上
x = x.to(device)
# torch.no_grad()上下文管理器来禁止梯度计算
with torch.no_grad():
pred = model(x)
preds.append(pred.detach().cpu())
# torch.cat函数将所有预测结果拼接成一个张量,并且指定dim=0表示沿着第一个维度进行拼接。随后使用.numpy()将张量转换为NumPy数组,以便后续处理
preds = torch.cat(preds, dim=0).numpy()
return preds
一些问题:
如何理解种子?种子到底是啥,跟什么有关系?种子是训练数据吗?
种子(seed)在随机数生成中扮演着重要的角色。种子是一个初始值,它作为随机数生成器的输入,用来确定随机数序列的起始状态。换句话说,给定相同的种子,随机数生成器将产生相同的随机数序列。种子本质上是一个整数,它可以唯一地确定一个随机数序列。种子与随机数生成器之间存在着确定性的关系。当使用相同的种子时,随机数生成器会按照相同的算法产生相同的序列,这样就确保了随机性操作的可复现性。种子不是训练数据,而是用来初始化随机数生成器的一个固定值。在深度学习中,种子通常用于初始化模型参数和设置随机数生成器,以便实现实验结果的可复现性。例如,在训练神经网络时,通过设置种子可以确保每次训练时权重初始化和数据采样的随机性是一致的,从而使得训练过程具有可重复的特性。总之,种子是随机数生成器的初始值,它决定了随机数序列的起始状态,从而影响了随机操作的结果。种子并不是训练数据,而是用来控制随机性操作的工具,以确保实验的可复现性。
CuDNN是什么?
CuDNN是NVIDIA(英伟达)公司提供的用于深度学习加速的GPU加速库。它是专门针对深度神经网络所设计的,提供了高效的卷积神经网络(CNN)实现和优化,能够在NVIDIA的GPU上实现快速的深度学习计算。CuDNN库包含了一系列高度优化的深度学习基础操作,如卷积、池化、激活函数等,旨在提供针对深度学习任务的高性能计算。通过使用CuDNN,深度学习框架(如PyTorch、TensorFlow等)可以充分利用NVIDIA GPU的并行计算能力,加速神经网络模型的训练和推理过程。由于CuDNN是针对NVIDIA GPU进行优化的,因此它能够充分发挥NVIDIA GPU在深度学习任务中的优势,提供高性能的深度学习计算支持。许多流行的深度学习框架都集成了对CuDNN的支持,以便充分利用GPU加速进行深度学习模型的训练和推断。
random_split函数
PyTorch的random_split函数将数据集data_set按照给定的大小拆分为训练集和验证集。random_split函数接受三个参数,第一个参数是待划分的数据集,第二个参数是一个整数列表,表示每个子集的大小,第三个参数是一个指定了随机种子的生成器,用于控制数据集的随机拆分过程。
model.eval()的用法
是用于将神经网络模型切换到评估(evaluation)模式的方法。当调用model.eval()时,模型内部的一些特定层(比如Dropout和Batch Normalization)会被设置为评估模式,这意味着它们将以固定的方式处理输入数据,而不是像训练期间那样随机地丢弃部分输入或者使用批标准化的移动平均值。在评估模式下,模型会保持不变,不会进行梯度计算,并且输出结果将保持一致性。这对于模型的部署和推断阶段非常重要,因为我们通常希望在这些阶段得到可重复且稳定的输出结果。
pred.detach().cpu()的作用
对pred进行两步操作:首先是移除梯度追踪以避免梯度对其影响,然后是将其数据从GPU上转移到CPU上,以便后续的处理或输出。(一般情况下,深度学习模型会在GPU上进行训练和推断,但有时候需要将数据转移到CPU上进行进一步处理或输出)
torch.cat的作用
是PyTorch中用于在指定维度上对张量进行拼接的函数。这个函数的作用是将多个张量沿着指定的维度进行连接,生成一个新的张量。具体来说,torch.cat函数有以下重要参数:
- tensors:需要拼接的张量序列,可以是一个元组、列表或其他序列类型。
- dim:指定拼接的维度。例如,如果dim=0,则表示沿着第一个维度拼接;如果dim=1,则表示沿着第二个维度拼接,依此类推。
举个例子,假设有两个形状为(3, 4)的张量t1和t2,通过torch.cat((t1, t2), dim=0),这将在第一个维度上拼接这两个张量,得到一个形状为(6, 4)的新张量。
在很多情况下,当我们处理多个样本或序列时,通常希望沿着第一个维度(通常是样本维度或时间步维度)进行拼接。
5.4 数据集
# 数据集
# 根据传入的特征和目标数据(如果有)来创建一个数据集对象。该数据集对象可以用于PyTorch中的数据加载器(DataLoader),从而方便地用于训练深度学习模型
class COVID19Dataset(Dataset):
'''
x: Features.
y: Targets, if none, do prediction.
'''
# 构造函数 x代表特征,y代表目标(如果为None,则表示进行预测)
def __init__(self, x, y=None): # y为缺省参数,如果不传参y则默认为none
if y is None:
self.y = y
else:
self.y = torch.FloatTensor(y)
self.x = torch.FloatTensor(x)
# 获取具体的某一条数据
def __getitem__(self, idx):
if self.y is None:
return self.x[idx]
else:
return self.x[idx], self.y[idx]
# 返回整个数据集的长度,即样本的数量
def __len__(self):
return len(self.x)5.5 模型建立
class My_Model(nn.Module):
def __init__(self, input_dim):
super(My_Model, self).__init__()
# TODO: modify model's structure, be aware of dimensions.
self.layers = nn.Sequential(
nn.Linear(input_dim, 16),
nn.ReLU(),
nn.Linear(16, 8),
nn.ReLU(),
nn.Linear(8, 1)
)
def forward(self, x):
x = self.layers(x)
x = x.squeeze(1) # (B, 1) -> (B)
return x
5.6 特征选择
def select_feat(train_data, valid_data, test_data, select_all=True):
'''Selects useful features to perform regression'''
# 从训练数据和验证数据中提取出标签(即最后一列数据)和原始特征(去除最后一列数据)
# [:,-1]冒号表示第一个维度选择全部,即全部行,-1:表示倒数第一个元素,即label
# 选取标签数据
y_train, y_valid = train_data[:, -1], valid_data[:, -1]
# [:,:-1]第一个冒号表示第一个维度选择全部,即全部行,:-1表示在第二个维度上从开始至最后一个元素(不包含最后一个元素)即选择了除最后一列的所有特征
# 选取特征数据
raw_x_train, raw_x_valid, raw_x_test = train_data[:, :-1], valid_data[:, :-1], test_data
if select_all:
# 选择所有特征
# raw_x_train形状2160*95 raw_x_train.shape[1]表示第二个维度元素的个数95
feat_idx = list(range(raw_x_train.shape[1]))
else: # 自定义特征
feat_idx = [0, 1, 2, 3] # Select suitable feature columns.
# 函数返回经过特征选择后的训练特征、验证特征、测试特征以及对应的训练标签和验证标签
return raw_x_train[:, feat_idx], raw_x_valid[:, feat_idx], raw_x_test[:, feat_idx], y_train, y_valid
5.6 训练函数
def trainer(train_loader, valid_loader, model, config, device):
criterion = nn.MSELoss(reduction='mean') # Define your loss function, do not modify this.
# Define your optimization algorithm.
optimizer = torch.optim.SGD(model.parameters(), lr=config['learning_rate'], momentum=0.9)
writer = SummaryWriter('../logs_covid19') # Writer of tensoboard.
if not os.path.isdir('../models'):
os.mkdir('../models') # Create directory of saving models.
# 从配置中读取了总的训练轮数,并初始化了最佳损失值、步数和早停计数器
n_epochs, best_loss, step, early_stop_count = config['n_epochs'], math.inf, 0, 0
# 训练循环开始
for epoch in range(n_epochs):
model.train() # Set your model to train mode.
loss_record = []
# 显示训练进度的进度条
train_pbar = tqdm(train_loader, position=0, leave=True)
for x, y in train_pbar:
optimizer.zero_grad() # Set gradient to zero.
x, y = x.to(device), y.to(device) # Move your data to device.
pred = model(x)
# 计算模型预测值与真实标签之间的损失值
loss = criterion(pred, y)
loss.backward() # Compute gradient(backpropagation).
optimizer.step() # Update parameters.
step += 1
loss_record.append(loss.detach().item())
# Display current epoch number and loss on tqdm progress bar.
train_pbar.set_description(f'Epoch [{epoch + 1}/{n_epochs}]')
train_pbar.set_postfix({'loss': loss.detach().item()})
mean_train_loss = sum(loss_record) / len(loss_record)
writer.add_scalar('Loss/train', mean_train_loss, step)
model.eval() # Set your model to evaluation mode.
loss_record = []
for x, y in valid_loader:
x, y = x.to(device), y.to(device)
with torch.no_grad():
pred = model(x)
loss = criterion(pred, y)
loss_record.append(loss.item())
mean_valid_loss = sum(loss_record) / len(loss_record)
print(f'Epoch [{epoch + 1}/{n_epochs}]: Train loss: {mean_train_loss:.4f}, Valid loss: {mean_valid_loss:.4f}')
writer.add_scalar('Loss/valid', mean_valid_loss, step)
# early stopping 如果平均验证集低于最好的,说明模型仍然可以优化
if mean_valid_loss < best_loss:
best_loss = mean_valid_loss
torch.save(model.state_dict(), config['save_path']) # Save your best model
print('Saving model with loss {:.3f}...'.format(best_loss))
early_stop_count = 0
else:
early_stop_count += 1
# 如果早停计数大于域值,那就停止
if early_stop_count >= config['early_stop']:
print('\nModel is not improving, so we halt the training session.')
return
5.7 超参数设置
device = 'cuda' if torch.cuda.is_available() else 'cpu'
config = {
'seed': 5201314, # Your seed number, you can pick your lucky number. :)
'select_all': True, # Whether to use all features.
'valid_ratio': 0.2, # validation_size = train_size * valid_ratio
'n_epochs': 3000, # Number of epochs.
'batch_size': 256,
'learning_rate': 1e-5,
'early_stop': 400, # If model has not improved for this many consecutive epochs, stop training.
'save_path': '../models/model.ckpt' # Your model will be saved here.
}
5.8 数据加载
# Set seed for reproducibility
same_seed(config['seed'])
# train_data size: 2699 x 118 (id + 37 states + 16 features x 5 days)
# test_data size: 1078 x 117 (without last day's positive rate)
train_data, test_data = pd.read_csv('covid_data/covid.train_new.csv').values, pd.read_csv('covid_data/covid.test_un.csv').values
train_data, valid_data = train_valid_split(train_data, config['valid_ratio'], config['seed']) # 按照k折交叉验证法分成训练集和验证集
# Print out the data size.
print(f"""train_data size: {train_data.shape}
valid_data size: {valid_data.shape}
test_data size: {test_data.shape}""")
# Select features
x_train, x_valid, x_test, y_train, y_valid = select_feat(train_data, valid_data, test_data, config['select_all'])
# Print out the number of features.
print(f'number of features: {x_train.shape[1]}')
train_dataset, valid_dataset, test_dataset = COVID19Dataset(x_train, y_train), \
COVID19Dataset(x_valid, y_valid), \
COVID19Dataset(x_test)
# 用统一的Pytorch加载器包装待处理数据 Pytorch data loader loads pytorch dataset into batches.
# pin_memory=True:这个参数用于告诉DataLoader是否将数据存储在固定内存区域中,
# 以便能够更高效地将数据传输到GPU上进行计算。通常情况下,在使用GPU训练时,
# 将pin_memory设置为True可以提高数据传输的速度。
train_loader = DataLoader(train_dataset, batch_size=config['batch_size'], shuffle=True, pin_memory=True)
valid_loader = DataLoader(valid_dataset, batch_size=config['batch_size'], shuffle=True, pin_memory=True)
test_loader = DataLoader(test_dataset, batch_size=config['batch_size'], shuffle=False, pin_memory=True)
5.9 开始运行
model = My_Model(input_dim=x_train.shape[1]).to(device) # put your model and data on the same computation device.
trainer(train_loader, valid_loader, model, config, device)5.10 保存模型
# 保存测试数据
def save_pred(preds, file):
''' Save predictions to specified file '''
with open(file, 'w') as fp:
writer = csv.writer(fp)
writer.writerow(['id', 'tested_positive'])
for i, p in enumerate(preds):
writer.writerow([i, p])
model = My_Model(input_dim=x_train.shape[1]).to(device)
model.load_state_dict(torch.load(config['save_path']))
preds = predict(test_loader, model, device)
save_pred(preds, 'pred.csv')5.11 运行结果
tensorboard --logdir=logs_covid19

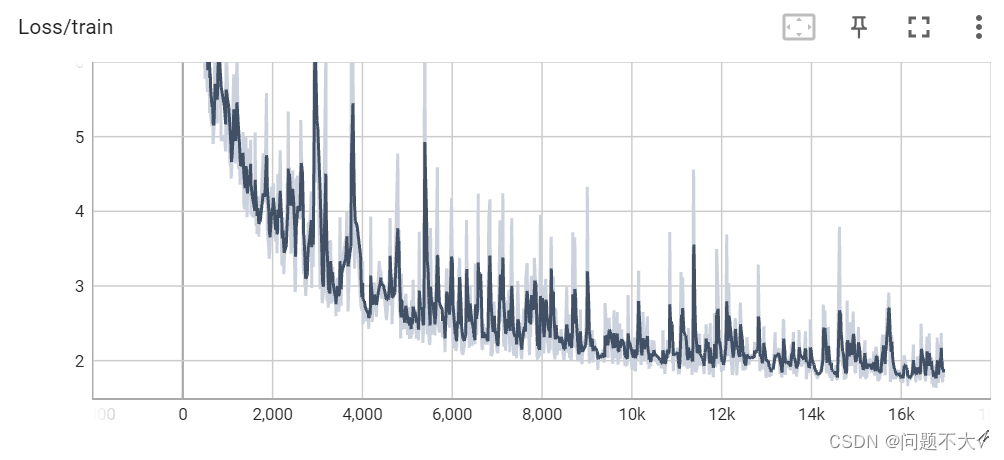
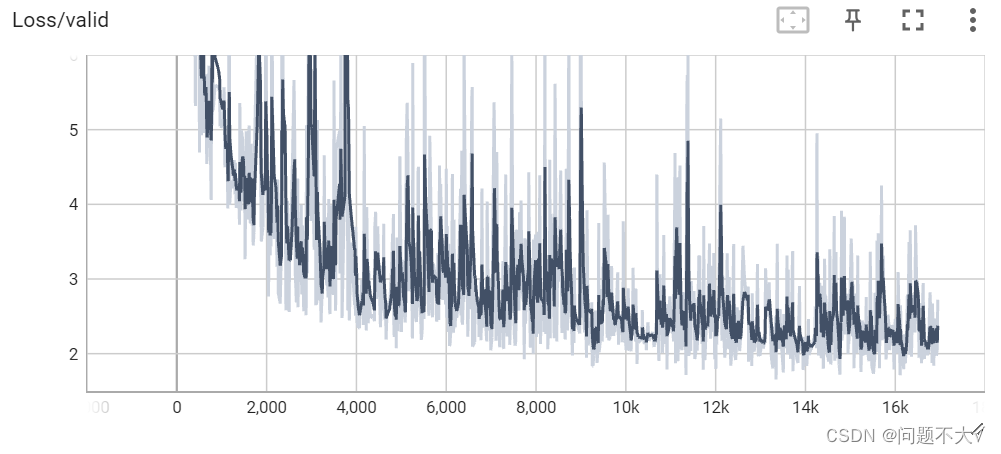
6 总结
目前,对于学习的内容仍然是保持一种懵的状态,希望到后面越学越清晰!对于 COVID 19 Cases Prediction (Regression)代码理解还不够透彻。多看看,仔细研究一下。















 130
130











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









