







R语言详解
安装
刚入门R语言下这俩东西,R(R语言版本)和RStudio(R编译平台)
R:R
RStudio:Rstudio
详细安装过程
R一门统计学软件
R语言是一门面向对象的编程语言
程序语句由换行符或者分号分隔;
R语言比较像python,语句格式跟py很像,语句后不用分号,需缩进;for循环、if判断后用{},不用:(冒号);
R是一种块状结构程序语言。块由大括号划分。
R语言不需要“声明”变量。
R语言处理对象是向量,频繁调用数据库
单行注释:#注释
多行注释:R不提供多行注释
代替方法:RStudio选中需要注释的代码,快捷键Ctrl+Shift+C
RStdio批量模式运行需要把代码都选中,再点运行
help(),获取在线帮助,等价于?
example(),展示例子
getwd(),返回当前目录
setwd(),指定目录
cat(x,sep=" "),输出,print()也可以,不过这个没有转义字符,即没法换行。sep和seq都一样。
数据类型
R语言不需要声明变量,直接赋值即可。
R语言允许使用FURE和FALSE缩写为T和F
在R语言中,TRUE和FALSE是保留字,表示逻辑常量,而T和F是全局变量,其初始值设置为这些。
在需要数值的上下文中,逻辑向量被强制为整数向量,TRUE映射到1L, FALSE映射到0L, NA映射到NA_integer_。
查看logical文档:help("logical")
typeof() #查看数据类型
#integer #整型
#double #小数(浮点型)(默认为双精度)
#character #字符串类型
#logical #逻辑型,T、F
mode() #查看数据结构
#numeric #数值向量,数值类型,包括整数,小数,科学计数的方式
#character #字符串向量
#list #列表
#矩阵也是数向量的一种
#matrix(矩阵)
#array(数组)
向量(vector)
向量类型是R语言核心,一切类型都可称为向量,一个数(标量),也是一个有一个元素的向量,R语言的数据类型里没有标量
- R语言中的变量类型被称为模式(mode)
- R语言的向量索引从1开始
- R语言调用函数typeof(x)查看变量x的类型
R语言数值变量不指明的一般都是双精度“double”类型,冒号运算符":"生成的是整型、c()生成的是浮点数double
向量中允许元素重复
向量插入和删除需要重新给向量赋值(R中向量是连续存储的)
length(),获取向量长度
#赋值:
> x<-3 #=赋值也可以
> x[1]
[1] 3 #x也是一个向量,只有一个元素
#向量
a<-c(1,3,5,7,9)
> a[2]
[1] 3 #下标从1开始,不是从0
> a[2:4]
[1] 3 5 7 #下标从第2到第4
> a[c(1,3,4)] #指定第1,3,4位置
[1] 1 5 7
#改变向量,重新赋值
> a<-c(a[1:3],66,18)
> a
[1] 1 3 5 66 18
#mean()求向量均值
mean(x)
#hist()绘制直方图
冒号运算符
冒号运算符生成的是向量
?Syntax,运算符优先级详细说明,其中冒号运算符优先级最高
冒号运算符生成的数值是整数类型
> 6:1 #冒号运算符,步长为1
[1] 6 5 4 3 2 1
> 1:5/2 #冒号优先级最高
[1] 0.5 1.0 1.5 2.0 2.5
> 1:5+1
[1] 2 3 4 5 6
向量运算
向量加、减、乘、除,对应元素直接相加(格式相等)
单个向量x与向量A加减乘除,向量A的每个元素分别对应x运算
索引,下标从1开始
负索引把相应的元素删除
> li
a
[1,] 1 1
[2,] 3 1
[3,] 5 1
[4,] 66 1
[5,] 18 1
> li + c(1,2) #循环补齐
a
[1,] 2 3
[2,] 5 2
[3,] 6 3
[4,] 68 2
[5,] 19 3
#等价于:
> li + array(c(1,2),dim(li))
a
[1,] 2 3
[2,] 5 2
[3,] 6 3
[4,] 68 2
[5,] 19 3
> b <- c(1:9)
> b
[1] 1 2 3 4 5 6 7 8 9
> b[-2:-4] #把下标从2到4的元素删除
[1] 1 5 6 7 8 9 #R语言索引都是闭区间
若某运算要求向量(数组)具有相同的长度,R会自动循环补齐,即重复较短的向量,直到与另一个相匹配
等差与重复
seq(),生成等差向量
seq(from, to, by, length, along.with)
from,to 序列的起始值和(最大)结束值。
by 步长
length/length.out 序列的期望长度。一个非负数,对于seq和seq.int,如果是小数则将其四舍五入。
along.with 从这个参数的长度中取长度。
> seq(1, 6, by = 3)
[1] 1 4
> seq(0, 1, length.out = 11)
[1] 0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0
req(),生成重复向量
> rep(c(12,34,7),2) #对向量整体重复
[1] 12 34 7 12 34 7
> rep(c(1,12,13),each=2) #分别先对向量中每个元素重复,each指重复次数
[1] 1 1 12 12 13 13
> c(1:4,rep(c(1,0),each=2),rep(c(1,0),2))
[1] 1 2 3 4 1 1 0 0 1 0 1 0
NA与NULL
NA表示缺失值
NULL表示不存在的值,没有模式
若要运算中跳过NA值,na.rm=T
> x <- c(3,NA,8,123,5)
> x
[1] 3 NA 8 123 5
> mean(x)
[1] NA
> mean(x,na.rm=T)
[1] 34.75
> x <- c(3,NULL,8,123,5)
> mean(x) #运算中NULL会自动被过滤
[1] 34.75
subset(),筛选过程中移除NA
向量比较
all(),参数中都为真,返回True
any(),参数中只要有一个为真,则返回True
identical(x,y),函数判断两个对象是否完全一致
> x <- 1:3 #模式(元素)为整型
> y <-c(1,2,3) #模式为浮点数
> x == y #"=="是一个向量化函数,返回值为一个布尔值的向量
[1] TRUE TRUE TRUE
> all(x==y) #两个向量中元素值相等,返回值TRUE
[1] TRUE
> identical(x,y) #两个对象完全一致
[1] FALSE
看个例子:

n-k+1,每次循环k个值,到最后k个值的第一个位置
[1:(i+k-1)],k个值,不要忘记了括号(冒号优先级高)
字符串
字符串是实际上是字符模式的单元素向量,默认用双引号"",赋值时用单引号也行。
R语言中字符串包含字符,说是一个字符是字符串也可。
> st = 'my gril'
> st
[1] "my gril"
> mode(st)
> [1] "character" #字符串向量
#只要向量中有一个是字符串,这个向量就是字符串向量
> ch = c('a',o,9,'45')
Error: object 'o' not found
> ch = c('a','one',9,'45')
> ch
[1] "a" "one" "9" "45"
> mode(ch)
[1] "character"
> length(ch)
[1] 4
#可以用character()函数构造初始字符型向量
> character(length=5)
[1] "" "" "" "" ""
字符串函数操作
获取字符串长度:nchar()
字符串分割:strsplit()
字符串拼接:paste()
字符串截取:substr()
字符串替代:gsub(), chartr(), sub()
字符串匹配:grep()
字符串格式化:sprintf()
大小写替换:toupper(), tolower()
1、获取字符串长度,nchar()
> a <- 'apple orange grape banana'
> nchar(a)
> fruit <- c('apple', 'orange', 'grape', 'banana')
> nchar(fruit)
[1] 5 6 5 6
> length(fruit) #注意跟length()是有区别的
[1] 4
2、字符串分割,strsplit()
strsplit()函数:将字符型向量分解成多个字符串,返回值为列表。
unlist()函数:将列表转换成向量。
> a <- 'apple orange grape banana'
> strsplit(a," ")
[[1]]
[1] "apple" "orange" "grape" "banana"
> strsplit(a,split = " " ) #带不带split=都一样
[[1]]
[1] "apple" "orange" "grape" "banana"
> unlist(strsplit(a," ")) #将列表转化为向量
[1] "apple" "orange" "grape" "banana"
3、字符串拼接
paste()函数:将多个对象(如向量)“粘贴”在一起,返回成单独的字符串。其优点在于,就算有的处理对象不是字符型也能自动转为字符型。


4、字符串截取,substr()
substr(x, start, stop)
substring(text, first, last = 1000000L)
substr()函数和substring()函数是截取字符串最常用的函数,两个函数功能方面是一样的。
substr()函数:必须设置参数start和stop,如果缺少将出错。
substring()函数:可以只设置first参数,last参数若不设置,则默认为1000000L,通常是指字符串的最大长度。
substr()函数:对给定的一个字符串执行一次求子串操作
substring()函数:对给定的一个字符串执行给定次求子串操作
> substr("abcdef",2,4)
[1] "bcd"
> substring("abcdef",2,4)
[1] "bcd"
> substr("abcdef",1:6,1:6)
[1] "a"
> substring("abcdef",1:6,1:6) #substring()执行给定次求子串
[1] "a" "b" "c" "d" "e" "f"
> substr("abcdef",1:6,6)
[1] "abcdef"
> substring("abcdef",1:6,6)
[1] "abcdef" "bcdef" "cdef" "def" "ef" "f"

5、字符串匹配,grep()
grep(pattern, x),在字符串向量x里捜索给定子字符串pattern
如果x有n个元素,则grep(pattern,x)会返回一个长度不超过n的向量。这个向量的每个元素是x的索引,表示在索引对应的元素x[i]中有与pattern匹配的子字符串。
> grep("Pole",c("Equator","North Pole","South Pole"))
[1] 2 3
> grep("pole",c("Equator","North Pole","South Pole")) #小写p(ploe)
integer(0)
正则化表达式
正则表达式是一种通配符,它是用来描述一系列字符串的简略表达式。例如,表达式"[au]"表示的是含有字母a或u的字符串。
英文句点.表任意一个字符,使用两个反斜线取消.全匹配作用
> grep("[au]",c("Equator","North Pole","South Pole"))
[1] 1 3
> grep(".",c("abc","de","f.g")) #英文句点.表任意一个字符
[1] 1 2 3
> grep("\\.",c("abc","de","f.g")) #使用两个反斜线取消.全匹配作用
[1] 3
> grep("o.e",c("Equator","North Pole","South Pole"))
[1] 2 3
> grep("N..t",c("Equator","North Pole","South Pole"))
[1] 2
regexpr()和gregexpr()匹配
regexpr(pattern,text)在字符串text中寻找pattern,返回与pattern匹配的第一个子字符串的起始字符位置。返回类型为数值列表
gregexpr(pattern,text)的功能与regexpr()一样,不过它会寻找与pattern匹配的全部子字符串的起始位置。返回类型为列表
> regexpr("uat",c("Equator","UIEopj")) #没有匹配到的返回-1
[1] 3 -1 #匹配的起始位置
attr(,"match.length")
[1] 3 -1 #匹配的字符串长度为3
attr(,"index.type")
[1] "chars"
attr(,"useBytes")
[1] TRUE
> mode(regexpr("uat",c("Equator","UIEopj")))
[1] "numeric"
> a = gregexpr("iss","Mississippi")
> a
[[1]]
[1] 2 5 #匹配的起始位置
attr(,"match.length")
[1] 3 3 #匹配的字符串长度为3
attr(,"index.type")
[1] "chars"
attr(,"useBytes")
[1] TRUE
> mode(a)
[1] "list"
6、字符串格式化,sprintf()
sprintf()函数:把若干个字符串或变量按一定格式“打印”到字符串里
> i <- 8
> s <- sprintf("the square of %d is %d",i,i^2)
> s
[1] "the square of 8 is 64"
7、大小写替换
> a <- "Hello World"
> toupper(a) #全部替换为大写
[1] "HELLO WORLD"
> tolower(a) #全部替换为小写
[1] "hello world
数组
array
array(data = NA, dim = length(data), dimnames = NULL)
dim:每个维度最大索引
dimnames:可以是NULL,也可以是维度的名称。这必须是一个列表。
> array(1:3, c(2,4))
[,1] [,2] [,3] [,4]
[1,] 1 3 2 1
[2,] 2 1 3 2
矩阵
矩阵有行和列,二维向量,是一种特殊的数组,数组可以是多维的,矩阵只有行和列两维,一般用matrix生成矩阵,行row,列column
函数matrix()是构造矩阵(二维数组)的函数,其构造形式为:
matrix(data=NA,nrow=1,ncol=1,byrow=FALSE,dimnames=NULL)
其中data是一个向量数据,nrol是矩阵的行数,ncol是矩阵的列数。
当byrow=TRUE时,生成矩阵的数据按行放置,缺省时相当于byrow=FALSE,数据按列放置。
dimname,是数组维的名字,缺省时为空。
a、矩阵的创建:
> matrix(c(1,2,3,4,5,1,2,8),nrow=2)
[,1] [,2] [,3] [,4]
[1,] 1 3 5 2
[2,] 2 4 1 8
> rbind(c(1,5),c(2,7)) #按行绑定
[,1] [,2]
[1,] 1 5
[2,] 2 7
> cbind(c(1,2),c(5,7)) #按列绑定
[,1] [,2]
[1,] 1 5
[2,] 2 7
b、给行列取名:
> mat <- matrix(1:9, nrow=3, dimnames=list(c('r1', 'r2', 'r3'), c('c1', 'c2', 'c3'))) #matrix创建时直接取名
> mat
c1 c2 c3
r1 1 4 7
r2 2 5 8
r3 3 6 9
> mat2 <- matrix(1:12,nrow=3)
> mat2
[,1] [,2] [,3] [,4]
[1,] 1 4 7 10
[2,] 2 5 8 11
[3,] 3 6 9 12
> rownames(mat2) <- c(1,2,3) #行取名
> colnames(mat2) <- c('a', 'b', 'c', 'd') #列取名
> mat2
a b c d
1 1 4 7 10
2 2 5 8 11
3 3 6 9 12
#可以通过rbind,cbind添加行列
> rbind(mat, c(12, 13, 14)) #在原矩阵mat后面添加一行
> rbind(mat, c(12, 13, 14))
c1 c2 c3
r1 1 4 7
r2 2 5 8
r3 3 6 9
12 13 14
t(),矩阵转置
det(),求方阵的行列式
dim(),矩阵的行列数
两个矩阵直接相乘A * B,对应元素相乘(矩阵必须相似)
矩阵乘法:mat %*% mat
**向量内积**
A %*% B
**向量外积(叉积)**
A %o% B
outer()是更为强大的外积运算函数,outer(x,y)计算向量二与y的外积,它等价于A %o% B
函数。outer()的一般调用格式为
outer(A,B,fun=”*”)
其中A,B矩阵(或向量),fun是作外积运算函数,缺省值为乘法运算。函数outer()在绘制三维曲面时非常有用,它可生成一个x和y的网格。
c、矩阵运算
> m<-rbind(c(1,5),c(2,6))
> m
[,1] [,2]
[1,] 1 5
[2,] 2 6
> c = cbind(c(1,5),c(2,6))
> c
[,1] [,2]
[1,] 1 2
[2,] 5 6
#矩阵直接相乘*
> m * c
[,1] [,2]
[1,] 1 10
[2,] 10 36
#矩阵内积c
> m %*% c
[,1] [,2]
[1,] 26 32
[2,] 32 40
#矩阵外积
> m %o% c
, , 1, 1
[,1] [,2]
[1,] 1 5
[2,] 2 6
, , 2, 1
[,1] [,2]
[1,] 5 25
[2,] 10 30
, , 1, 2
[,1] [,2]
[1,] 2 10
[2,] 4 12
, , 2, 2
[,1] [,2]
[1,] 6 30
[2,] 12 36
>mc<-m %o% c
> dim(mc)
[1] 2 2 2 2
#dim(mc) = c(dim(m), dim(c)) #注意维数
矩阵相关函数
1)drop函数避免矩阵降为

2)向量转化为矩阵

3)apply()函数

列表
从技术上讲还是向量,不过是递归型向量
列表中各项可以是不同的数据类型
a、列表创建list()
> li <- list(a=55,b="34",c=c(3,5)) #创建有标签的列表
> li
$a
[1] 55
$b
[1] "34"
$c
[1] 3 5
> li$a #使用$加标签访问元素
[1] 55
> li2 <- list(55,"34",c(3,5)) #list(),创建一个向量
> li2
[[1]]
[1] 55
[[2]]
[1] "34"
[[3]]
[1] 3 5
b、列表索引

使用names()获取列表的标签
使用unlist()获取列表的值,返回值是一个向量。
#继承上面的变量(li,li2)
> unlist(li) #li带有标签
a b c1 c2
"55" "34" "3" "5"
> class(unlist(li)) #li列表中有字符串,返回字符型向量
[1] "character"
> unlist(li2)
[1] "55" "34" "3" "5"
c、列表增删

数据框
R语言中的数据框可视为二维列表
数据框每列是一个变量,每行是一个观测
数据框通常通过读取文件或数据库来创建
在R语言中,数据框使用data.frame()函数来创建,其格式如下:
data.frame(col1, col2, ..., row.name=NULL, check.rows = FALSE, check.names=TRUE, stringsAsFactors = default.stringsAsFactors())
其中,row.name用于指定各行(样本)的名称,默认没有名称,使用从1开始自增的序列来标识每一行;
check.rows用于用来检查行的名称和数量是否一致,默认为FALSE;
check.names来检查变量(列)的名称是否唯一且符合语法,默认为TRUE;
用来描述是否将字符型向量自动转换为因子,默认转换,若不改变的话使用stringsAsFactors = FALSE来指定即可。
可以使用rbind()函数和cbind()函数将新行或新列添加到数据框变量中。遵循循环补齐
> arr1 = array(1:12,c(3,4))
> arr1
[,1] [,2] [,3] [,4]
[1,] 1 4 7 10
[2,] 2 5 8 11
[3,] 3 6 9 12
> mode(arr1)
[1] "numeric"
> data.frame(arr1)
X1 X2 X3 X4
1 1 4 7 10
2 2 5 8 11
3 3 6 9 12
> mode(data.frame(arr1))
[1] "list"
> df1<-df1[-2,];df1 #删除第2行数据
X1 X2 X3 X4
1 1 4 7 10
3 3 6 9 12
> df1<-df1[,-c(1,3)];df1 #删除第列和第3列的数据
X2 X4
1 4 10
3 6 12
#增添
> lis<-list(name=c("张三","四姐","王五"," 小七"), sex=c("男", "女", "男", "男"), score=c(90, 85, 82, 93))
> df2 <- data.frame(lis);df2
name sex score
1 张三 男 90
2 四姐 女 85
3 王五 男 82
4 小七 男 93
> lis2 <- list(name="八哥",sex="男",score=92) #创建一个新列表
> df2<-rbind(df2, as.data.frame(lis2)) #将列表lis2添加到df2中
> df2
name sex score
1 张三 男 90
2 四姐 女 85
3 王五 男 82
4 小七 男 93
5 八哥 男 92
> lis3<-list(height=c(170,168,185,178,175)) #创建一个新列表,保存身高
> df2 <- cbind(df2, as.data.frame(lis2))
> df2
name sex score height
1 张三 男 90 170
2 四姐 女 85 168
3 王五 男 82 185
4 小七 男 93 178
5 八哥 男 92 175
访问数据框:

缺失值处理:
complete.cases()

合并数据框:
merge(x,y)


因子和表
因子(factor)是R语言中很多强大运算的基础,包括许多针对表格数据的运算。
因子的设计思想来源于统计学中的名义变量,或称之为分类变量。这种变量的值本质上不是数字,而是分类。尽管可以用数字对它们编码。例如,党员用1表示,团员用0表示;男生用1表示,女生用0表示等。
因子与水平:



table(),统计因子向量中各水平出现的频数

运算符

x && y,返回标量
x & y,返回向量
> x <- c(T,F,T)
> y <- c(T,T,F)
> x & y #返回一个向量
[1] TRUE FALSE FALSE
> x[1] && y[1] #返回T or F
[1] TRUE
> x && y #赶回T or F
[1] TRUE
创建自己的二元运算符

全局变量
<<-,超赋值运算符

R语言中没有指针

输入与输出
输入,scan(), readline()
在R中,可以使用scan()从文件中读取或者用键盘输入一个向量;
scan()默认以“空白字符”分隔各项。空白字符包括空格、回车/换行符、水平制表符。可用可选参数sep设置其他分隔符,键入空行表示结束输入。

在R中,从键盘输入单行数据,用readline()函数会非常方便。

输出,cat()
在R中,cat()会比print()好用一点。cat()输出的内容默认以空格分隔。或者利用sep参数设置为其他分隔符。
> x <- 1:3
> cat(x,"abc","de\n")
1 2 3 abc de
> cat(x,"abc","de\n",sep="\n")
1
2
3
abc
de
#这有一个空格
> cat(x,"abc","de\n",sep="")
123abcde
读写文件
getwd(),获取代码文件执行目录
setwd(dir),设置代码文件执行路径
file.info(),查看文件详细信息
file.exists(),判断当前路径下是否存在文件
dir(),获取当前路径下文件
read.table(),读入数据框(表)
从文件中读取数据框或矩阵

读excel表格或csv文件
安装运行读取Excel文件的包readxl:library("readxl")
read_excel(path,sheel=1)
read.csv(path,header=TRUE)
读取文本文件函数readLines()
# z.txt
name age
John 25
Mary 28
Jim 19
> v <- readLines("z.txt")
> v
[1] "name age" "John 25" "Mary 28" "Jim 19"
> class(v) #字符串向量
[1] "character"
#利用readLines()函数逐行读取文件中的内容
> v <- file("z.txt","r")
> readLines(v,n=1)
[1] "name age"
> readLines(v,n=1)
[1] "John 25"
> readLines(v,n=1)
[1] "Mary 28"
> readLines(v,n=1)
[1] "Jim 19"
> readLines(v,n=1)
character(0)
#利用seek()函数实现“倒带”功能:从文件开始处重新读取文件
# where=0参数表示从文件开头读文件
> v <- file("z.txt","r")
> readLines(v,n=2)
[1] "name age" "John 25"
> seek(con=v,where=0)
[1] 36
> readLines(v,n=1) #上一步seek(0),从起点开始
[1] "name age"
写文件
由于R语言主要用于统计功能,读文件可能比写文件更为常用;
write.table()函数的用法与read.table()非常相似,把数据框写入文件。

函数cat()可以用来写入文件,一次写入一部分

用函数writeLines()写入文件

控制语句
循环
for(i in x),x是一个向量
while()
repeat()

分支函数
if/else
switch
向量化的ifelse()函数
ifelse(test, yes, no)
text,可以强制转换为逻辑模式的对象。
yes,返回test的真元素的值。
no,返回test的假元素的值。
> x<-3
> y <- ifelse(x>0, x+1, x-1)
> y
[1] 4
switch(EXPR, ...)
EXPR:求值为数字或字符串的表达式。
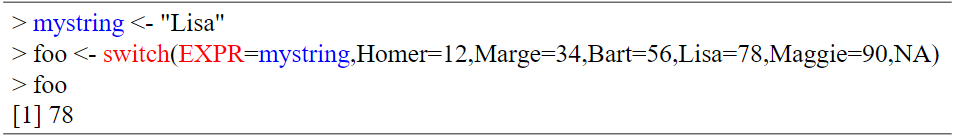

函数
f <- function(x, y),创建函数
formals(f),返回函数形参
body(f),返回函数体
函数都是对象,可以作为其他函数的参数。
自定义函数
#向量求和
add<-function(x){ #x:形参,不带类型
sum<-0 #初始值,赋值
#for循环:
for(i in x){
sum = sum + i #没有sum+=i
}
return(sum)
}
返回值
可以显式调用函数return(),把一个值返回给主调函数,如果不使用这条语句,默认将会把最后执行的语句作为返回值。不推荐使用return(),因为调用这个函数会延长执行时间。

默认参数

source(),导入函数或库

匿名函数

常用函数
排序

apply()函数
apply()常用于矩阵,相当于函数映射,比较常用。
apply(m,dimcode,f,fargs)
m表示矩阵
dimcode,取1表示对行应用函数f(默认),取2表对列
f是函数,f可以是内置函数,也可是自定义函数
fargs是f的可选参数集
> z
[,1] [,2] [,3]
[1,] 2 6 10
[2,] 4 8 12
> apply(z,2,mean) #对矩阵z按列取平均数
[1] 3 7 11
lapply()函数
lapply()和apply()的区别在于输出的格式,lapply()的输出是一个列表(list),不需要dimcode参数。
lapply(m, fargs)
sapply()函数
sapply()函数做的事情和lapply()一样,返回的是一个向量(vector)使得对解读更加友好,其使用方法和lapply一样,不过多了两个参数:
simplify&use.NAMEs:
simplify = T可以将输出结果数组化,如果设置为false,sapply()函数就和lapply()函数没有差别了;
use.NAMEs = T可以设置字符串为字符名。
tapply()函数
对一个向量里面进行分组统计操作
tapply(X, INDEX, FUN = NULL)
- X: 一个对象,一般都是向量
- INDEX: 一个包含分类因子的列表(list)
- FUN: 对X里面每个元素进行操作的函数
数学运算与模拟
数学函数
幂用:^

计算概率
choose(),生成组合数,
C
n
k
=
(
k
n
)
=
n
!
k
!
(
n
−
k
)
!
C^k_n=(^n_k)=\frac{n!}{k!(n-k)!}
Cnk=(kn)=k!(n−k)!n!
prod(),连乘函数
累积和cumsum()、累积乘积cumprod()

函数min()把所有元素组成一个向量,然后返回最小值。
函数pmin()把两个向量对应位置的元素两两比较,返回一个向量。
> z<-matrix(c(1,5,6,2,3,2),ncol=2)
> z
[,1] [,2]
[1,] 1 2
[2,] 5 3
[3,] 6 2
> z[,1]
[1] 1 5 6
> z[1,1]
[1] 1
> min(z[,1],z[,2])
[1] 1
> pmin(z[,1],z[,2])
[1] 1 3 2
nlm(),求函数极小值点
optimize(),求一元极值的函数
D(),求导
integrate(),微积分

统计分布函数

绘图
基本绘图plot()
plot(x, y = NULL, type = "p", xlim = NULL, ylim = NULL,
log = "", main = NULL, sub = NULL, xlab = NULL, ylab = NULL,
ann = par("ann"), axes = TRUE, frame.plot = axes,
panel.first = NULL, panel.last = NULL, asp = NA,
xgap.axis = NA, ygap.axis = NA,
...)
| 参数 | 作用 |
|---|---|
| xlim | 二维向量,表示所绘图形x轴的范围 |
| ylim | 二维向量,表示所绘图形y轴的范围 |
| log | “x”或“y”,表示对x轴或y轴的数据取对数,“xy”或“yx”,表示对x轴与y轴的数据同时取对数 |
| main | 字符串,描述图形的标题 |
| sub | 字符串,描述图形的副标题 |
| xlab | 字符串,描述x轴的标签,默认值为对象名 |
| ylab | 字符串,描述y轴的标签,默认值为对象名 |
多图par()
> par(mfrow=c(3,2)) #按行填放3行2列,共计6个图
> par(mfcol=c(3,2)) #按列填放3行2列,共计6个图
> par(mfrow=c(1,1)) #取消多图环境
> x<-1:8
> y<-5:12
> par(mfrow=c(2,4)) #按行填放2行4列,共计8个图
> plot(x,y,type="p",col="red",xlab="线型p",ylab="")
> plot(x,y,type="l",col="blue",xlab="线型l",ylab="")
> plot(x,y,type="o",col="black",xlab="线型o",ylab="")
> plot(x,y,type="b",col="green",xlab="线型b",ylab="")
> plot(x,y,type="c",col="red",xlab="线型c",ylab="")
> plot(x,y,type="s",col="blue",xlab="线型s",ylab="")
> plot(x,y,type="S",col="black",xlab="线型S",ylab="")
> plot(x,y,type="h",col="green",xlab="线型h",ylab="")

| 选项 | 作用 |
|---|---|
| “p” | 绘点, |
| “l” | 画线, |
| “b” | 同时绘点和画线,而线不穿过点, |
| “c” | 仅画参数“b”所示的线, |
| “o” | 同时绘点和画线,且线穿过, |
| “h” | 绘出点到横轴的竖线, |
| “s” | 绘出阶梯图(先横再纵), |
| “S” | 绘出阶梯图(先纵再横), |
| “n” | 作一幅空图,不绘任何图形。 |
添加点points()
先执行plot函数后,points函数才会生效。
后出现的绘图命令的坐标范围要比先出现的小,否则R环境会截断不显示。
> par(mfrow=c(1,2))
> x<-seq(from=1,to=3,length=20)
> y<-rep(3,20)
> plot(x,y)
> x<-seq(from=2,to=3,length=20)
> y<-rep(2,20)
> points(x,y,pch="+") #添加点,先执行plot函数后,points函数才会生效。
> text(locator(1),"HPU") #添加文字text()与精确定位locator() #在单击的位置绘制HPU
> text(locator(1),"HPU",cex=3) #改变字符大小:cex选项
运行结果:

添加线条abline()

添加多边形polygon()
> par(mfrow=c(1,2))
> f <- function(x) return(1-exp(-x))
> curve(f,0,2) #在区间[0,2]内绘制函数f
> polygon(c(1.2,1.4,1.4,1.2),c(0,0,f(1.3),f(1.3)),col="yellow")

箱线图boxplot()
箱线图不仅可用于反映一组数据分布的特征,比如,分布是否对称,是否存在离群点(outlier)等,还可以对多组数据的分布特征进比较。

par(mfrow=c(3,1),mai=c(0.4,0.2,0.3,0.2))
x<-rnorm(1000,50,5)
boxplot(x,range=1.5,col="red",lwd=2,horizontal=TRUE,main="相邻值与箱子连线的箱线图(range=1.5)",cex=0.8)
boxplot(x,range=3,col="green",lwd=2,horizontal=TRUE,main="相邻值与箱子连线的箱线图(range=3)",cex=0.8)
boxplot(x,range=0,varwidth=T,lwd=2,col="pink",horizontal=TRUE,main="极值与箱子连线的箱线图(range=0,varwidth=T)",cex=0.8)
















 5511
5511











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









