






a=torch.rand(3)
a.requires_grad_()
p=F.softmax(a,dim=0)
p.backward()
结果报错了,原因在哪里呢

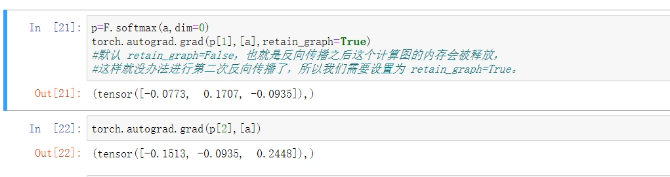
p=F.softmax(a,dim=0)
torch.autograd.gard(p[1],[a],retain_graph=True)#默认 retain_graph=False,也就是反向传播之后这个计算图的内存会释放,这样就没办法进行第二次方向传播了,所以我们需要设置retain_graph=True
torch.autograd.gard(p[2],[a])#这里去掉了retain_graph
结果:
感知机
import torch
x=torch.randn(1,10)
x
w=torch.randn(1,10,requires_grad=True)#自动推导
w
o=torch.sigmoid(x@w.t())#权重计算
o
o.shape
loss.backgrad()
w.grad

多输出感知机
x=torch.randn(1,10)
w=torch.randn(2,10,requires_grad=True)
x,w
o=torch.sigmoid(x@w.t())
o.shape
loss = F.mse.loss(torch.ones(1,1),o)
loss
loss.backward()
w.grad

链式法则
import torch
x=torch.tensor(1.)
w1=torch.tensor(2.,requires_grad=True)
b1=torch.tensor(1.)
w2=torch.tensor(2.,requires_grad=True)
b2=torch.tensor(1.)
最原始的特征:

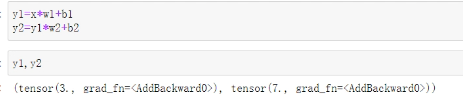
y1=x*w1+b1
y2=y1*w2+b2
dy2_dy1=autograd.grad(y2,[y1],retain_gragh=True)[0]
dy1_dw1=autograd.grad(y1,[w1],retain_gragh=True)[0]
dy2_dw1=autograd.grad(y2,[w1],retain_gragh=True)[0]
dy2_dy1*dy1_dw1
dy2_dy1

MLP(多层感知机)反向传播(复制自己学习里给的word,个人觉得很详细,自己看一部分复制一部分就大致了解了)
MLP应该算是最简单的神经网络了吧, 虽然是深度学习, 但是和普通的机器学习一样, 都是通过已有的数据训练出一个模型. 通过模型来进行预测

因此在我眼里, MLP和逻辑回归非常相似. 甚至可以把每一个神经元都看作是一个小的逻辑回归.
记得对于逻辑回归, 我的理解是寻找一组θ, 使得sigmoid函数可以表示概率.而对于MLP来说, 就是找到多组θ来使得整个神经网络模型可以预测输出结果.

这是一个神经网络的例子, 可以看到数据是这样前向传递的, 每一个节点都由前一层的所有节点决定.
计算方式也是极为简单, 就是给前一层的每一个节点一个权值(wight), 再加上一个偏置(bias), 最后放入一个激活函数中
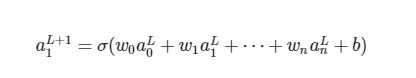
L+1层的第1个节点是由第L层所有的节点计算出来的
这也是我说每个神经元(节点)都是小的逻辑回归的原因. 因为这完全就是逻辑回归的思路.
可以想象, 在极端的情况下, 只有一个隐藏层, 这个隐藏层中只有一个神经元, 那么这个神经网络就退化成了逻辑回归. (对于MLP来说, 第一层为输入层, 最后一层为输出层, 中间的其余层为隐藏层)
输入层的神经元(节点)的个数是固定的, 它等同于样本的特征数.
因为这就是神经网络的思想, 下一层是根据上一层的节点进行加权求和计算出来的, 理所当然, 我们要给予不同的特征不同的权值.
同时输出层的神经元的个数也是固定的, 它等同与预测结果的特征数.换句话说, 我们所能改变的只有隐藏层的个数, 以及每一层的节点数.在接下来的讲解中, 激活函数统一使用sigmoid, 当然MLP的激活函数并不局限于此。
前向传播
前向传播就是一个矩阵的乘法, 每一个节点计算的公式也早已给出
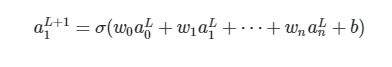
为了更直观的看到计算的方式, 将以下图MLP为例子, 来看它是怎么工作的.

暂且不管sigmoid函数, 单看加权求和的那一部分, 就是一个矩阵的乘法wijk的意思是第k层, 第i个节点所连接的第 j 条边
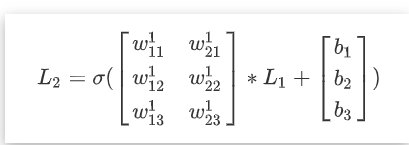
矩阵中每一个w都对应一个边. 因此从前一层计算下一层的方式可以看作是矩阵乘法之后再接一个sigmoid函数
我习惯于让矩阵的每一行代表下一个节点所需要的权值.
也就是矩阵的第一行是为了求得下一层第一个节点所要用到的权值.
同理第n行就是第n个节点的权值. 所以矩阵应该是m * n的
m代表第L+1层(下一层)的节点个数
n代表第L层(当前层)的节点个数
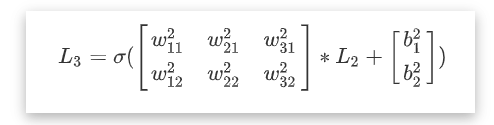
也就是说, 只要直到每条边(权值w), 和偏置(b), 以及输入层的数据. 就可以得到最后输出层的结果.
问题的关键是: 如何找到合适的权值w和偏置b, 使得整个网络可以正确预测.
反向传播
可以说MLP的核心就是反向传播. 但反向传播的核心是梯度下降, 也就是说, 本质上还是通过梯度(求导)来调整w和b
损失函数这里使用最为简单的
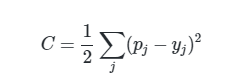
还有交叉熵等损失函数. p为预测值, y为真实值.
为什么选这个函数? 同样也是因为mathematically convenience 也就是说在数学处理上更方便
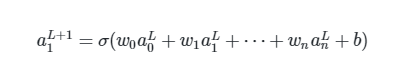
现在假设a1L+1是最终的输出层. 也就是p
如果此时 p < y, 我们要怎么调整才能使得p接近y?
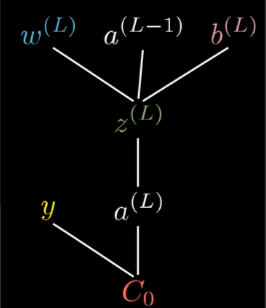
1.调整权值w
2.调整偏置b
3.调整节点a
显然p取决于上一层的这三个因素. 所以有这三种方法.
但是调整节点a是无法做到的. 因为节点a取决于上上层的w, b和a.
也就是说, 此层我们只能调整w和b.
















 691
691











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











