









今天来学习pytorch中有关自动求导模块中的**torch.autograd.backward()**函数的用法和其涉及到的数学原理
函数的作用
官方解释
原话:Computes the sum of gradients of given tensors w.r.t. graph leaves.
个人翻译:计算那些有关图中叶子节点的tensors的梯度的和
这里的叶子节点指的是那些requir_gard=true的叶子节点
这个函数的运行结果就是返回各个叶子节点的梯度。说到现在还是有点太笼统了,我们结合一下函数的参数列表来继续研究一下。
参数列表
这个函数一共有4个参数,并不多,我们一一来看,他们分别是:tensors,grad_tensors,retain_graph,create_graph
1.tensors:
首先看看官方给出的解释:Tensors of which the derivative will be computed
个人翻译:那些将要被计算导数的tensors
所以这个参数的作用已经很明显了,就是我们要对其求导的那个tensor,但要注意这个参数必须要有,不能空着,其他三个参数都是可以空着的。ok,下一个
2.grad_tensors:
这个参数的官方解释较长,也是这个函数复杂的一个地方,我现将官方解释贴上来,然后贴上自己的理解。
官方解释:
The “vector” in the Jacobian-vector product, usually gradients w.r.t. each element of corresponding tensors.
想要理解这个参数的意思,我们必须得先知道一个专有名词的背景,那就是
Jacobian-vector product,翻译过来就是雅可比向量积
雅可比向量积
什么是雅可比向量积呢,首先我们要知道什么是雅可比矩阵,雅可比矩阵出现在多元微分学,可以理解为是高维的导数,举个例子,当有一个n个自变量的m元函数函数f,他的雅可比矩阵(导数)就是下面那个样子。
定义1:
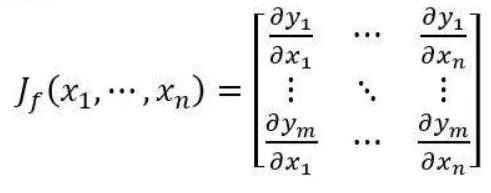
ok,我们搞懂了雅可比矩阵是什么了,那么上面官方文档中提到的Jacobian-vector product又是什么呢?我们都知道正常的一元函数,它对某个自变量求导是一个数,就是我们熟知的
一元函数偏导数:
d
y
d
x
1
\frac{dy}{dx_{1}}
dx1dy
而在多元函数中则是一个向量,例如对
x
1
x_1
x1进行求导:
多元函数偏导数:
(
d
y
1
d
x
1
,
d
y
2
d
x
1
,
.
.
.
d
y
n
d
x
1
)
(\frac{dy_1}{dx_1},\frac{dy_2}{dx_1},...\frac{dy_n}{dx_1})
(dx1dy1,dx1dy2,...dx1dyn)
我们都知道在训练的时候,梯度是用来更新权重的,最简单的更新公式就是
x
n
e
w
=
x
o
l
d
+
W
∗
g
r
a
d
x_{new}=x_{old}+W*grad
xnew=xold+W∗grad,而往往这个梯度只能是一个标量,但在多元函数的情况下,对一个自变量
x
1
x_1
x1求导却出现了一个向量,这该如何更新权重呢,这个时候我们的Jacobian-vector product就出现了,我们想要将这个向量转化为一个标量只需要再来一个同杨长度的向量进行点乘就可以得到。这个同样长度的向量就是Jacobian-vector中的vector,也就是这个参数所代表的tensor。
举个例子,如果这个参数你不设置的话,默认是单位向量。
我们继续拿上面的多元函数举例子:此时对
x
1
x_1
x1求导,他的值就不是一个向量,而是
(
d
y
1
d
x
1
,
d
y
2
d
x
1
,
.
.
.
d
y
n
d
x
1
)
⋅
(
1
,
1...1
)
=
d
y
1
d
x
1
+
d
y
2
d
x
1
+
.
.
.
d
y
n
d
x
1
(\frac{dy_1}{dx_1},\frac{dy_2}{dx_1},...\frac{dy_n}{dx_1})·(1,1...1)=\frac{dy_1}{dx_1}+\frac{dy_2}{dx_1}+...\frac{dy_n}{dx_1}
(dx1dy1,dx1dy2,...dx1dyn)⋅(1,1...1)=dx1dy1+dx1dy2+...dx1dyn
看,已经出现了,这就是Jacobian-vector product.
如果你设置这个向量,上面的单位向量就会替换成你输入的tensor,你也可以理解为你设置了一个权重,用来调整各个因变量y对最终那个“标量梯度”的影响大小。
到现在我们基本读懂了这个参数的意思,但官方文档后面还有一段话,我们继续来分析一下:
原文:None values can be specified for scalar Tensors or ones that don’t require grad. If a None value would be acceptable for all grad_tensors, then this argument is optional.
第一句:当待求导的tensors是标量或者是一个不需要梯度的tensors,那么我们这个参数将设置为None类型。意思是如果待求导的tensor是一个标量,那么这就属于一元函数,就不需要雅可比向量乘积了,所以这个时候设置成None就可以了。
第二句:如果None适用于所有需要梯度的tensor,那么这个时候此参数可以不填。
ok第二个参数解决了 我们来看下一个
3.retain_graph
还是先看看官方文档:
If False, the graph used to compute the grad will be freed. Note that in nearly all cases setting this option to True is not needed and often can be worked around in a much more efficient way. Defaults to the value of create_graph.
个人理解:首先我们看到这是一个布尔类型变量,通过名字可以感觉到这是跟保存记录有关的
如果为False:过去计算过的图将被释放
如果为True:则会保留
就是如果在retain_graph=False的情况下调用了backward(),调用之后,forward过程中创建的所有计算图将全部销毁。如果要再次调用backward,要重新进行forward过程。但如果retain_graph=True的话,调用完backward(),计算图仍然保存。
注意:在几乎所有情况下都不需要将这里设置为True,并且有更有效的方式解决这个问题。默认值为create_graph的值,就是我们要了解的最后一个变量
4.create_graph
官方文档:
If True, graph of the derivative will be constructed, allowing to compute higher order derivative products. Defaults to False.
个人翻译:
如果为True,则导数的计算图将会被创建,这将允许计算更高阶导数,默认值为False
至此所有的参数我们都已经学习完毕了,我们来总结一下:
总结
torch.autograd.backward()是一个用来计算导数的函数,计算第一个参数的tensors对所有计算图中require_grad=True的tensor的导数,如果第一个参数不是标量tensor,则需要第二个参数设置vector,进行Jacobian-vector product,将梯度向量转换为一个梯度标量值,如果需要保留计算图,则设置retain_graph=True,如果要计算高阶导数或利用梯度值请设置create_graph=True。
至此torch.autograd.backward()函数学习就完事啦。以上均为学习笔记,如有错误指出。
官方文档地址:https://pytorch.org/docs/stable/autograd.html















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









