





作者知乎说明
原文链接:https://pan.baidu.com/s/14Cx0U8aW32t4ir8ZFtbGHw 密码:969g
原文链接
参考:我爱计算机视觉公众号
摘要:
对象检测器通常根据尺度变化质量,在小对象上的性能是最不令人满意的。在本文中,我们研究了这一现象,发现在大多数的训练迭代中,小对象对总损失的贡献很小,导致性能差且优化不均衡。受到这一发现的启发,我们提出了一种反馈驱动的数据提供Stitcher,它旨在以一种平衡的方式训练对象检测器。在缝合器中,图像被重新调整成更小的组件,然后缝合成相同大小的常规图像。缝合图像包含不可避免的较小对象,这将有利于我们的核心思想,利用损失统计作为反馈,以指导下一个迭代更新。在各种检测器、主干、训练周期、数据集,甚至实例分割上都进行了实验。Stitcher在所有设置下都能稳定地大幅度提高性能,特别是对于小对象,在训练和测试阶段几乎不需要额外的计算。代码和模型将公开提供。
1.介绍
深目标探测器的性能以一种复杂的方式变化。在目标检测的深度网络中,一个关键的挑战是大尺度的变化,而大尺度的变化往往成为检测小目标的难点。例如,在[1](AP: 36.7%, APs: 21.1%, APm: 39.9%, APl: 48.1%)中发布的ResNet-50[11,13]的FPN结果中,由于各种尺度的不平衡优化,小对象的精度几乎是中型或大型对象的一半。这一问题降低了总体性能,阻碍了对象检测器在不同场景下的通用性。一个合理的解释是,对小物件的监控信号是不够的。监督信号可以通过训练损失自然地反映出来。我们研究了不同尺度上迭代的损耗分布,如图1所示。
 图1:训练迭代过程中小目标的损耗比。对于更快的R-CNN基线,在超过50%的迭代中,小对象对总体损失的贡献小于10%。采用缝纫机时,损耗分布得到平衡。
图1:训练迭代过程中小目标的损耗比。对于更快的R-CNN基线,在超过50%的迭代中,小对象对总体损失的贡献小于10%。采用缝纫机时,损耗分布得到平衡。
 图2:使用fasterR-CNN进行COCO训练的准确性与训练时间对比。在各种情况下,Stitcher几乎不需要额外的训练时间就可以提高大约2%的AP性能,而多尺度的训练则相对较差,需要更多的成本。
图2:使用fasterR-CNN进行COCO训练的准确性与训练时间对比。在各种情况下,Stitcher几乎不需要额外的训练时间就可以提高大约2%的AP性能,而多尺度的训练则相对较差,需要更多的成本。
统计数据是在一个共同的基线上计算的,即faster-RCNN,ResNet-50[11]和FPN[13]作为Microsoft COCO数据集[14]的骨架。小、中、大尺度的对象是根据它们的大小来定义的。具体地说,在迭代t中,小对象的损失L占了真实框的大小小于1024。rt表示Lt与Ltin电流迭代的总损耗之比。值得注意的是,在超过50%的迭代中,rt可以忽略不计(小于0.1),如图1所示。对小物件知识的缺乏导致不平衡和相应的表现不佳。
在这篇论文中,我们提出了一种反馈驱动的数据提供程序,通过反馈的方式利用训练损失来提高目标检测的性能。我们介绍了缝合图像具有相同的大小和常规的组成部分大小调整较小的组成部分。其核心思想是利用当前迭代中的损失统计信息作为反馈,自适应地确定下一个迭代的输入选择。如图3所示,如果在当前迭代t中,小对象的丢失率rt可以忽略不计,则迭代t+ 1的输入为缝合后的图像,其中小对象不可避免的更为丰富。否则,在默认设置下,输入仍然是常规图像。图像拼接缓解了原始数据分布上输入特征空间的图像电平不平衡。同时,反馈模式减轻了不公平优化。它们都致力于更平衡的对象检测。
 图3:管线图。是否在下一次迭代中使用拼接图像由当前反馈自适应地决定。
图3:管线图。是否在下一次迭代中使用拼接图像由当前反馈自适应地决定。
在实验中,我们验证了Stitcher在各种检测框架(Faster R-CNN、RetinaNet)、主干(ResNets、ResNexts)、训练计划(1×、2×)、数据集(COCO、VOC)甚至实例分割上的有效性。在所有这些设置中,我们的方法在很大程度上提高了精度,如图2所示,特别是对于小对象。正如缝合也涉及图像在多尺度下,我们也比较了缝合与多尺度训练。后者需要较长的训练时间,但其性能较差。
拼接可以很容易地纳入任何检测器。它在训练和推理过程中几乎没有额外的负担。额外的成本只是由于损失统计计算和图像拼接,这几乎是微不足道的相比,更重的正向和反向传播。接下来,我们首先在第2节中分析存在的问题,然后在第3节中介绍我们的方法。第四部分讨论了缝合术与以往文献的关系。实验结果见第5节。
2.问题分析
2.1图像水平分析
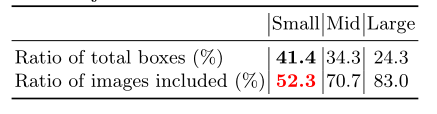
定量分析:小对象在自然图像中非常常见,而它们在不同图像中的分布是不可预测的。如表1所示,COCO训练集中41.4%的对象是小对象,远多于其他两个量表中的对象。然而,只有52.3%的图像包含小的物体。而中、大型物品的比例分别为70.7%和83.0%。换句话说,在一些图像中,大多数对象都很小,而近一半的图像不包含小的对象。这种严重的不平衡妨碍了训练进程。
定性分析。在常规的图像中,对象可能会因为摄影问题而变得模糊,例如焦点模糊或运动模糊。如果将常规图像调整为更小的尺寸,那么里面的中等大小或较大的物体也会变得更小,但其轮廓或细节仍然比原来的小物体更清晰。在图4中,从更大的尺度上调整大小的球比风筝更清晰,尽管它们的大小分别为29×31和30×30。
 图4:通过重新缩放得到的自然小物体(风筝)与小图像中物体(球)的定性比较。调整大小的球在视觉上比风筝更清晰的纹理-他们有相似的大小。
图4:通过重新缩放得到的自然小物体(风筝)与小图像中物体(球)的定性比较。调整大小的球在视觉上比风筝更清晰的纹理-他们有相似的大小。
表1:MS-COCO训练集上不同尺度的对象分布
上述分析启发了第3.1节中的组件拼接。
2.2训练水平分析
本节通过损失统计分析训练水平中的量表问题。我们在COCO数据集中使用trainval35k分割进行训练,使用minival进行评估。以ImageNet预训练的带有FPN的ResNet-50为骨干。我们在fasterR-CNN上训练,1×训练周期(90k)。所有的训练设置,包括学习率、动量、重量衰减和批处理大小,都直接遵循默认值。在训练期间,我们在每个培训迭代中记录超过三个尺度的损失。根据这些统计数据,图1显示了不同尺度下的损耗分布。小对象在图像上的分布不均匀,使得训练进一步出现不平衡问题。即使在一些图像中包含了小的物体,它们仍然有可能在训练过程中被忽略。从图1可以看出,在超过50%的迭代中,小对象占不到总数的10%。训练损失主要是由大的和中等大小的对象。因此,对小对象的监控信号不足,严重影响了小对象的精度,甚至整体性能。这一现象激发了在Stitcher中的选择范例,该范例将在第3.2节中介绍。
 图5:常规图像和缝合图像。(a)一批常规图像作为训练输入,具有形状(n, c, h, w);(b)一批具有形状(n、c、h、w)的拼接图像,其中一幅四倍小图像沿空间维度进行拼接;©一批缝合后的图像,形状(kn, c, h/√k, w/√k),图像沿批量尺寸n拼接,设k = 4进行可视化。
图5:常规图像和缝合图像。(a)一批常规图像作为训练输入,具有形状(n, c, h, w);(b)一批具有形状(n、c、h、w)的拼接图像,其中一幅四倍小图像沿空间维度进行拼接;©一批缝合后的图像,形状(kn, c, h/√k, w/√k),图像沿批量尺寸n拼接,设k = 4进行可视化。
3.拼接
根据前面的分析,不同尺度的不平衡是由图像水平的分布引起的,在训练阶段变得更糟。受到这一发现的启发,我们深入研究了对象检测中普遍存在的问题——如何减轻尺度不平衡,尤其是小对象。为此,本节提出了一种新的训练策略,称为Stitcher。它由图像和训练水平两个不同的阶段组成,与第2节的分析相对应。
3.1图像水平操作-组件拼接
参照表1所示的统计数据,训练集中近一半的图像包含不小的对象。这种映像粒度不平衡严重干扰了小型批处理级优化过程。为了解决这个问题,我们提出了一种自适应数据生成器Stitcher,它可以在惩罚信号的引导下动态生成拼接图像或规则图像。对于少数几个分辨率调整后的图像进行统一处理,通过对k (k = 1,2^2, 3^2, …)自然图像进行缩放和拼贴,从而形成一幅拼接后的图像。(h /√k w /√k)。为了保留原始对象属性,必须保持高宽比。一般情况下,取k为1时,在拼接图像中引入自然图像。将拼接顺序k指定为4,如图5 (b)所示。通过制造更多的小对象,图像批量(作为最小训练实体)的尺度不平衡得到缓解。由于拼接后的图像与常规图像具有相同的尺寸,因此在网络传播中不需要进行额外的计算。除非指定,否则缝合器的实验将使用图5 (b)中的图像进行。
缝线数目(k = 12,22,32,…)的隐含的正方形约束是主要的关注点。为了使它更灵活,我们提供了另一个版本的实现,其中图像沿批处理尺寸缝合,批处理张量形状成为(kn, c, h/√k, w/√k)。总的来说,张量像素量保持不变,而拼接数没有被施加在某个数的平方上。如图5 ©所示。具体的拼接顺序k的选择请参考第5.4节。Stitcher提供的数据具有一致的张量容量和动态批大小,它推广了传统的多尺度训练(固定批大小)。
 图6:缝合器和fasterR-CNN Res-50-FPN在不同尺度上的损耗分布
图6:缝合器和fasterR-CNN Res-50-FPN在不同尺度上的损耗分布
 图7:训练迭代的性能曲线
图7:训练迭代的性能曲线
3.2训练水平模块-选择范例
缝合图像可能包含更多的小对象,而利用它们的时机取决于。从图1可以看出,在超过50%的迭代中,来自小对象的损失占不到10%。为了避免这种不良趋势,我们提出了一个修正的范例,根据当前遍历的反馈来确定下一个迭代的输入。如果小物体的损失可以忽略不计(低于一个阈值τ)迭代t,我们假定知识小物体远远不够。为了弥补信息的不足,我们采用缝合后的图像作为迭代t + 1的输入。否则,将选择常规图像。要计算所有尺度中小对象丢失的比例,我们有以下步骤。严格地说,一个对象的尺度是由它的掩码区域决定的,只在分割任务中可用。但是,对于一般的对象检测,地面真相掩码是不可用的。因此,我们使用方框区域。如式(1)所示,对于对象o,其面积aois近似表示为box area,记为ho×wo。Lt表示来自面积不大于As(COCO协议中为1024)的小对象的损失。小对象的比例由式(3)得到:


比率r作为一个潜在的反馈来指导下一次迭代的学习。这种策略平衡了损失分布,以便更好地优化。我们在图6中对比了损耗分布,在图7中对比了性能差异。我们每10k次迭代测量统计数据,并以平滑的方式加以说明。它揭示了在不同尺度上的损耗分布在我们的缝合器上得到了更好的平衡,这导致了更好的准确性。
3.3时间复杂度
只有训练过程是利用的缝合,因此没有负担的推理时间。在这里,我们详细说明了它在训练中的时间复杂性。缝合器由构件缝合和选择范式组成。在拼接部分,利用最近邻插值对图像进行降阶处理。由于COCO中原始图像的最大边长为640像素,因此插值运算所需乘法次数不超过2×6402≈0.8M。与检测网络的正向/反向传播相比,它是可以忽略的。例如,处理224×224图像的成本为ResNet-50 3.8G FLOPs(乘法和加法)。在选择范例中,我们需要计算每个选中的真实框的面积。然而,每次都只剩下几个盒子。这一步的计算费用可以忽略不计。在理论分析的基础上,对缝合机的运行时间进行了实际测量。如果需要缝合图像,在此迭代中,除了常规的培训外,还需要额外花费大约0.02秒的时间。在总训练时间方面,基线训练时间约为8.7小时,RCNN速度更快,采用ResNet-50-FPN骨干。当在同一个gpu上计时时,Stitcher会多花一刻钟的时间。当使用较大的脊骨时,这个间隙会缩小。
4.与之前工作的联系
我们的工作与以前的工作有几个方面的联系。下面我们将讨论它们之间的关系以及主要的区别。
多尺度图像金字塔[2]是一种传统的、直观的弥补大尺度变化的方法。它从手工制作的时代就开始流行了,例如SIFT[16]和HOG[6]。如今,基于cnn的深度物体探测器也可以从多尺度的训练和测试中受益,图像可以随机调整成不同的分辨率。因此,以这种方式学习的特征更能适应尺度变化。与多尺度训练类似,Stitcher也被设计用来使特征更健壮地适应尺度变化。然而,有两个本质的区别。(1) Stitcher既不需要图像金字塔构造,也不需要输入尺寸调整。
缝合后的图像仍然与常规图像一样大小,这是非常大的减轻了图像金字塔中不可避免的计算负担。
2)通过训练迭代过程中的损耗分布自适应确定缝制机的目标尺度。相反,在图像金字塔中,不同大小的图像在每次迭代中被随机选择。这导致了比多尺度训练明显更好的性能,这将在第5.2节的实验结果中得到证明。
SNIP和SNIPER[17,18]这些方法都是图像金字塔策略的高级版本。针对多尺度训练中目标尺度的规范化问题,提出了SNIP[17]算法。感兴趣的区域(roi)在每个尺度的指定范围之外被认为是无效的。狙击手[18]利用补丁作为训练数据,而不是常规图像。它选择地面真实实例周围的区域作为正芯片,并将背景样本作为负芯片。
缝匠的操作本质上不同于狙击手。狙击中的作物操作要复杂得多,它需要计算ground-truth盒和用于标签分配的作物之间的重叠(IoU)。然而,在缝合机的缝合操作只涉及插值和拼接。此外,狙击和狙击依赖于多尺度测试-他们仍然遭受推理时间的增加。对于消融对检测策略的影响,我们在5.2节中比较了它们与Stitcher的性能。
这种混合技术首先被引入到图像分类[20]中,以减轻对偶扰动。然后,在对象检测[21]中对其进行评估。它混合图像像素,并将组真理标签与经验混合比例进行调整。在操作方面,拼接和混搭都很简洁。
就性能而言,缝合机优于混纺机。如[21]所示,mix - up在训练前没有mix的情况下提高了基线(更快的R-CNN/ResNet-101/2×)0.2% AP,在训练前和微调阶段都提高了基线(更快的R-CNN/ResNet-101/2×)1.2% AP。相比之下,在未应用于训练前阶段的情况下,Stitcher将同一基线提高了2.3% AP。
自动增强[4]方法能够自主学习增强策略[4,22]。搜索空间包含几个预定义的扩展策略。它利用搜索算法,例如强化学习,来优化数据扩充策略。之后,表现最好的公司将被重新培训网络。
自动增强[22]花费了GPU数千天的离线处理时间来完成搜索,这完全背离了我们的目标。然而,Stitcher的性能与自动扩增[22]类似(自动扩增+1.6% vs.具有ResNet-50主干的更快R-CNN上的Stitcher +1.7%)。此外,自动增强方法通常涉及更复杂的转换,如颜色操作(均衡、亮度)和几何操作(旋转、剪切)。
与操纵图像不同,另一种处理尺度变化的方法是设计尺度感知神经网络,通常分为两类:基于特征金字塔的方法和基于扩张的方法。在特征金字塔方法方面,SSD[15]检测不同尺度的对象,将对应层的特征图作为输入。FPN[13]引入横向连接来构建所有尺度的高级语义特征图。另一方面,基于扩张的方法适应对象的接受域。变形卷积网络(DCN)[5]将扩展卷积推广到自适应接受域学习。Trident网络[12]通过构造多个具有不同扩张的分支来生成特定于尺度的特征。
5.实验
5.1实验细节
在涉及80个对象类别的COCO检测数据集[14]上进行了实验。我们在原始训练集(包含80k个图像)和原始验证集(trainval35k)的一个子集(35k个图像)的并集上训练网络,并在验证图像的一个5k子集(minival)上求值。按照常用的[10]方法,首先在ImageNet数据集[7]上通过图像分类对骨干网进行预训练。这些模型进一步配置了head子网络,在有目标检测任务的COCO监督下进行微调。为了便于改进,我们采用预先培训过的模型供公众使用。我们的实现基于maskrcn -benchmark2。
在训练阶段,输入图像被调整大小,使短边有800像素。我们使用同步SGD在8个gpu (RTX 2080 TI)上训练网络。除非特别说明,每个小批处理中每个GPU有2张图像,整个批处理大小为16。培训设置直接遵循常用的配置。我们设置权值衰减为0.0001,动量为0.9,初始学习率为0.02。在1×训练周期内,共进行90k次迭代。学习速度除以10在60k和80k。在2×训练期间,我们将总迭代次数加倍至180k,学习速率下降时刻分别为120k和160k。对于评价,我们采用标准平均精度(mAP)度量。还报告了小、中、大尺寸对象(即APs、APm和APl)[14]的平均精度。
5.2目标检测评价
在这一节中,我们比较了Stitcher与普通基线和它的竞争对手,包括多尺度训练和SNIP/SNIPER。与普通基线的比较。我们用不同的检测器(更快的R-CNN和RetinaNet)和不同的训练周期来评估缝合器的效果
表2:与更快的R-CNN常用基线的比较

表3:与RetinaNet上常见基线的比较

(1×和2×),结果见表2和表3。在所有这些情况下,精度稳步提高时,缝机是杠杆,特别是小对象。在细节上,我们观察到以下几点。(1)在ResNet-50条件下,2×训练比1×训练(1×训练+1.93%,2×训练+2.2%)提高更快的R-CNN。(2)在大多数情况下,除了R-CNN在1×训练时速度更快外,性能增益并不随着骨骼从ResNet-50[11]增大到ResNet-101而衰减。简而言之,实验结果表明,Stitcher在基线上带来了一致的改进,并且对各种设置(脊骨、检测头和训练时间)都具有鲁棒性。
与多尺度训练的比较。表4给出了与多尺度训练技术的比较,即,从[600,700,800,900,1000]中随机选择一个比例来调整图像的短边。与多尺度训练相比,缝合器产生了更好的性能。除了性能收益之外,下面的观察结果也值得讨论。(1)在精度方面,缝合器相对于多尺度训练的优势主要来源于小尺度。它们在探测大型物体方面的能力大致相当。这种对比验证了我们的设计目标,即通过图像拼接实现小目标检测。
表4:与快速R-CNN多尺度训练的比较

表5: SNIP and SNIPER 在Faster R-CNN的比较

(2)缝合比多尺度训练计算更经济。它们都使用相同的GPU (RTX 2080Ti)进行训练。然而,在相同的训练周期内,多尺度训练所花费的时间要比缝合训练多。
比较SNIP和SNIPER。如表5所示,我们将Stitcher与SNIP和SNIPER在Faster R-CNN与ResNet-50/101进行比较。缝合器表现稍好,SNIP和SNIPER都可以看作是多尺度的训练。但也存在一些明显的差异。首先,Stitcher的实现比较简单。SNIPER需要标签分配,有效的范围调整和积极/消极芯片选择。其次,缝合是反馈驱动的优化过程更侧重于它的缺点。
主干网络的评估。表6显示了从缝合器到大的主干的进步,如ResNext 101 [19], ResNet-101与DCN[5]和ResNext-32×8d-101与DCN[5]。实验在1×训练周期的fasterR-CNN上进行。在较高的基线条件下,Stitcher仍能将性能提升1.0% ~ 1.5% AP,证明了Stitcher对复杂情况的鲁棒性。
表6:faster-R-CNN对主干的评估

对较长训练时间的评估。表7给出了在更快的R-CNN上进行更长时间的训练,使用ResNet-50和FPN骨干。对于6×训练,过拟合降低了基线的性能,而Stitcher仍能保持良好的精度。缝合后的图像组成不固定,丰富了数据模式,防止过拟合。
表7:更快的R-CNN上较长的训练时间的评估

另外,一个合理的问题是,从Stitcher得到的改进是否是由训练实例的增加引起的。1×Stitcher所涉及的实例最多不超过4×baseline,而1×Stitcher在任何训练阶段的表现都好于baseline。验证了这一因素并不是改进的主要原因。
PASCAL VOC评价。虽然Stitcher的灵感来自COCO的发现,但它在其他数据集上仍然有效。我们在Pascal VOC[8]上对缝合机进行了评价。按照[9]协议,对模型进行VOC 2007培训和VOC 2012培训的联合培训。对VOC 2007测试进行评估。在8个gpu上总共执行24k次迭代。在前三分之二和剩下的三分之一迭代中,学习率分别设置为0.01和0.001。实验在使用ResNet-50和FPN的快速R-CNN上进行。如表8所示,Stitcher带来的mAP提升率为1.1%。

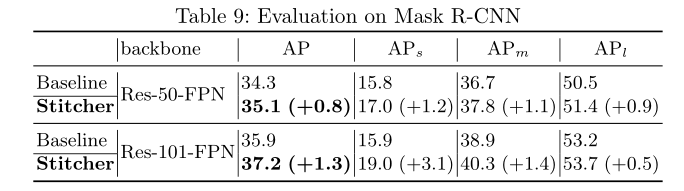
实例分割的评估。除了对象检测之外,我们还将Stitcher应用于实例分割。对COCO实例分割轨迹[14]进行了实验研究。我们报告COCO掩模AP在minival split。模型按1×训练周期进行训练,迭代次数为90k。它是在第60k和80k次迭代时除以10。训练设置,包括学习率、重量衰减、动量和预先训练的重量,直接遵循默认配置。如表9所示,在Stitcher的帮助下,性能在ResNet-50上提高了0.9%,在ResNet-101上提高了1.3%。
5.3消融研究
在本节中,我们提供了实证分析每个组件的拼接,选择范式和阈值τ。以ResNet-50和FPN为骨架,在1×训练期对fast R-CNN进行消融研究。
选择模式。为了评估Stitcher中的选择范例,我们建立了几个实验进行比较,如表10所示。
所有缝合:所有迭代使用缝合后的图像;
所有常规:始终使用常规图像(公共基线);
随机样本:随机抽取缝合或规则图像;
输入反馈:这是一种简化版本的Stitcher,其中的反馈比是根据输入批处理中的小对象数量来计算的;
分类/回归/全损反馈:通过损耗反馈进行引导。

如表10所示,如果连续使用缝合图像,则会获得无法接受的性能。单纯的图像拼接不起作用,也不会带来任何好处。这反映了选择范式在缝合中是不可缺少的。随机抽样可以看作是多尺度训练的一种特殊形式。它比一般的基准表现得更好,但前景并不乐观。如果反馈比率是基于输入,而不是损失,准确性仍然高于基线,但略低于缝合。输入数据不能像损失一样强大的反映优化过程,因为小对象仍然有被忽略的概率。这些比较反映了选择的必要性在缝纫机范式。此外,Stitcher不管以哪种损耗作为反馈,都能获得稳定的性能。它们的性能稳定在38.5% ~ 38.6%的AP之间。为了方便起见,我们选择回归损失作为通用设置。

阈值:只有一个hyper-parameter介绍缝纫机,选择的阈值τ。我们研究了在Stitcher中阈值的影响,如图8所示。当阈值设置在0.4以下时,Stitcher的性能优于通用基线。否则,性能会迅速下降到“全缝合”基线。这个观察结果验证了将阈值设置为0.1可以带来很好的平衡。
5.4沿着批处理维度进行连接
为了使缝合更灵活,我们建议沿着批处理维度聚合调整大小的图像,而不是原来的空间维度。表11比较了两种实现方法对同一幅缝合图像中不同图像编号k的结果。观察可以总结。(1)当k = 4时,两种拼接方法的拼接精度均为38.6%。证明了这两种实现是等价的。(2)当采用其他k值时,Stitcher仍能达到类似的性能。
最高的性能是在k为5时达到的。批缝线迹对k值的变化具有较强的鲁棒性,可满足不同设备的缝制要求。
6.总结
在本文中,我们提出了一种简单而有效的对象检测数据提供程序,称为Stitcher,它可以显著提高性能。它可以很容易地应用于各种检测器,主干,训练周期,数据集,甚至其他视觉任务,如实例分割。此外,它在训练过程中需要的额外计算量可以忽略不计,并且不影响推理时间。大量实验验证了该方法的有效性。我们希望缝合器可以作为一个共同的配置在未来。















04-29
 2407
2407
2407
“相关推荐”对你有帮助么?
-

 非常没帮助
非常没帮助 -

 没帮助
没帮助 -

 一般
一般 -

 有帮助
有帮助 -

 非常有帮助
非常有帮助
提交

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









