






 本文提出了一种新型的KEFA扬声器模型,通过知识细化模块和自适应时间对齐解决视觉特征差距及时间grounding的问题,提升了在R2R和UrbanWalk数据集上的指令生成性能,并贡献了新的SPICE-D评估指标,强调方向短语的重要性。
本文提出了一种新型的KEFA扬声器模型,通过知识细化模块和自适应时间对齐解决视觉特征差距及时间grounding的问题,提升了在R2R和UrbanWalk数据集上的指令生成性能,并贡献了新的SPICE-D评估指标,强调方向短语的重要性。
摘要
我们引入了一种新颖的扬声器模型 KEFA,用于生成导航指令。视觉和语言导航中现有的说话人模型存在不同环境之间视觉特征域差距较大且temporal grounding capability不足的问题。为了应对这些挑战,我们提出了一个知识细化模块来增强外部知识事实的特征表示,并提出了一种自适应时间对齐方法来强制生成的指令和观察序列之间的细粒度对齐。此外,我们提出了一种用于导航指令评估的新度量 SPICE-D,它可以识别方向短语的正确性。 R2R 和 UrbanWalk 数据集上的实验结果表明,所提出的 KEFA 扬声器在室内和室外场景中均实现了最先进的指令生成性能。
介绍
视觉和语言导航(VLN)[4]是一项智能体遵循自然语言指令采取行动并在虚拟环境中移动到目的地的任务。虽然在开发指令跟随智能体方面取得了巨大进展[45,60,9],但逆向任务——指令生成,最近受到了越来越多的关注。指令生成模型,或者说说话者,通常扮演着用自然语言描述环境中的轨迹的角色。在实际场景中,说话者模型可用于描述机器人在人类机器人协作任务中探索的路径[15, 54],或通过辅助指令引导盲人跟随者[25]。
尽管以前的指令生成方法[16,1,59,55]带来了有希望的进步,但大多数扬声器模型仍然面临两个主要挑战。第一个挑战是训练和测试基于视觉的说话人模型之间视觉观察特征的显着差异。第二个挑战是扬声器缺乏时间接地能力。语言解码器中的标准注意力机制不足以捕捉视觉和语言之间随时间变化的细粒度对应关系[44],这可能会导致生成时产生幻觉。
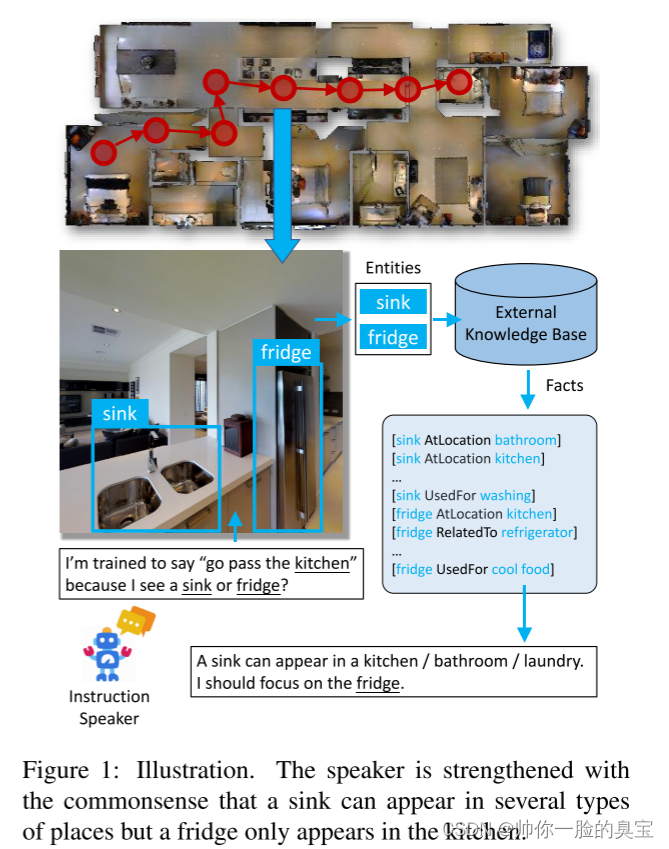
为此,我们提出了一种新颖的知识增强和细粒度对齐(KEFA)扬声器来生成指令。我们引入两种方法,即知识细化模块(KRM)和自适应时间对齐(ATA),从两个不同的方面来提高说话者的性能。首先,为了缓解视觉特征中不良的领域差距,我们利用外部知识为语言生成构建强大的语义线索。一个直观的例子如图1所示。我们人类有这样的常识:一个地方最有可能是厨房,因为有冰箱,而说话者在没有经过训练的情况下并不知道这些事实。为了将这些常识知识集成到模型中,知识细化模块从外部知识库(如 ConceptNet [53])检索并编码与环境中观察到的对象相关的有用知识事实。然后通过跨模式注意机制将编码的知识与全景特征聚合。其次,为了解决时间grounding问题,自适应时间对齐方法通过动态时间扭曲[7]算法以自监督的方式获得子指令和视点之间的细粒度对应关系。基于细粒度的对应关系,我们设计了注意力覆盖损失和对比损失来加强注意力和特征对齐。
此外,我们还贡献了一种新的度量 SPICE-D 来评估导航指令生成。之前的指标将方向性短语(例如右转)视为普通的 n 元语法,并且不强调此类短语的顺序 [47, 58]。然而,这些方向短语通常会告知指令接收者移动方向的关键和急剧变化,这对于导航的成功很重要。出于这种考虑,我们设计了 SPICE-D 度量标准,它将新的方向分量纳入标准 SPICE [3] 分数中。方向分量是根据最长公共子序列 (LCS) [6] 算法的候选方向短语和参考指令的顺序匹配来计算的。我们表明,与现有指标相比,SPICE-D 与方向正确性的相关性更高。
在实验中,我们在室内 R2R [4] 数据集和室外 UrbanWalk [25] 数据集上评估我们的 KEFA 扬声器以生成指令。与现有方法相比,所提出的 KEFA 扬声器实现了最先进的导航指令生成性能。
我们的贡献总结如下:
1、我们提出了一个知识细化模块来利用检测到的对象的语义常识知识。细化的特征提高了模型在未见过的环境下的指令生成能力。
2、我们引入了一种自适应时间对齐(ATA)方法,用于改善子指令级别的语言基础。 ATA 通过使用注意力损失和对比目标,鼓励视觉表示在对齐和未对齐的子指令特征之间进行区分,同时通过动态时间扭曲自适应地获得对齐。受益于 ATA,该模型显示出增强的一代性能。
3、我们引入了SPICE-D,这是一种用于评估导航指令生成的新颖的自动指标。 SPICE-D强调方向短语的匹配,这是导航指令的关键组成部分,现有指标中没有明确考虑这一点。我们表明,与现有指标相比,SPICE-D 与方向短语的正确性更相关。
相关工作
navigation instruction generation
最早的指令生成可以追溯到[43],并且已经在机器人学[18]、认知科学[32, 13]和心理学[56]等各个领域进行了研究。一些早期的方法 [62,2,39] 基于手工制定的规则 [11] 和人工设计模板 [38],遵循易于遵循的原则 [18] 从地图生成路线指示。最近的指令生成方法随着视觉和语言导航(VLN)的发展而进步。说话者模型用于数据增强和重新加权导航代理的路线选择[16]。为了训练更好的说话者,seqto-seq 模型 [1] 和基于提示模板的方法 [61] 都强调以地标为基础。此外,扬声器还与导航代理集成在反事实循环一致学习[59]或联合优化[12]中,因为它们的相关性可以提高性能。
external knowledge
来自大型知识库(如 ConceptNet [53] 和 WordNet [14])的外部知识是常识事实的丰富来源,可用于各种任务,包括视觉问答 [52,66,65,41]、图像字幕 [63]、文本生成[30]、用药报告生成[36, 33]等。在 VLN 相关任务中,Gao 等人。 [17]使用外部知识来推理房间和物体的关系,以提高智能体在远程引用表达任务上的性能。杨等人。 [64]利用知识图作为语义导航的先验场景。然而,在导航指令生成中,采用外部知识仍处于探索之中。
vision-language grounding
将语言概念与视觉线索对齐在各种视觉识别任务中发挥着重要作用,包括图像字幕[70]、视觉问答[41]、语言-图像预训练[34]、文本-视频基础[8]、短语和指代表达基础 [24, 37]、时间动作定位 [42] 等。对于指令follower智能体,Hu 等人 [23]建议使用专家混合的方法对视觉和几何模式进行grounding语言指令。 VLN-BERT [22] 使用来自网络的大量图像-文本对,并对 ViLBERT [40] 进行微调以对轨迹指令兼容性进行建模。尽管取得了这些进步,但在序列到序列指令生成器中对视觉语言基础的探索较少。
evaluation metrics of language generation
有许多用于文本相似性评估的自动评估指标。在机器翻译和图像字幕中,BLEU [47]、METEOR [5]、ROUGE [35]、CIDEr [58] 和 SPICE [3] 最常采用,它们也用于导航指令评估。随着 BERT [28] 等预训练大型语言模型的出现,BERTScore [67] 等基于模型的指标被引入。然而,这些指标不太重视方向短语,方向短语是导航指令的重要组成部分,必须以正确的顺序出现。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









