






超越指令导航:障碍环境中的视觉和语言导航
摘要
现实世界的导航常常涉及处理意外的障碍物,如关闭的门、移动的物体和不可预测的实体。然而,主流的视觉与语言导航(VLN)任务通常假设指令与固定和预定义的导航图完全对齐,且没有任何障碍物。这一假设忽略了实际导航图和给定指令之间可能存在的差异,这可能会导致室内和室外代理的严重失败。为了解决这个问题,我们将各种障碍物整合到R2R数据集中,通过修改导航图和视觉观测,提出了一个创新的数据集和任务:R2R with UNexpected Obstructions (R2R-UNO)。R2R-UNO包含多种类型和数量的路径障碍,旨在为VLN研究生成指令与现实不匹配的场景。
在R2R-UNO上的实验表明,当前最先进的VLN方法在面对这些不匹配时不可避免地遇到重大挑战,这表明它们倾向于僵硬地遵循指令,而不是自适应地导航。因此,我们提出了一种新的方法,称为ObVLN (Obstructed VLN),该方法包括课程训练策略和虚拟图构建,以帮助代理有效适应有障碍物的环境。实验结果显示,ObVLN不仅在无障碍场景中表现出稳健的性能,还在意外障碍物场景中实现了显著的性能优势。
引言
在视觉与语言导航(Vision-and-Language Navigation, VLN)任务中,代理需要根据自然语言指令到达指定的目的地。随着大语言模型(LLMs)的快速发展,这一领域因其在现实世界应用(如家用机器人)中的巨大潜力而备受关注。然而,当前的VLN任务受到多个不切实际的假设限制,使得这些技术大多停留在模拟器中,难以广泛应用于实际的机器人部署。
一个显著的限制是所谓的“完美指令假设”,即假设给定的导航指令总是与环境完美对齐,忽略了实时动态变化(如意外出现的障碍物)。在这种假设下训练的代理善于精确地执行指令,但缺乏应对现实中指令与环境不一致情况的适应性。如图1所示,人类可能会基于对房屋的先验知识告诉代理“沿着走廊直走”,但现实环境可能发生了变化,例如有一个行李箱挡住了走廊的路。当人类面对这些变化时,可以快速适应并找到绕行的路径,而现有的VLN代理在这种指令与现实不匹配的情况下则常常表现不佳,导致导航失败。
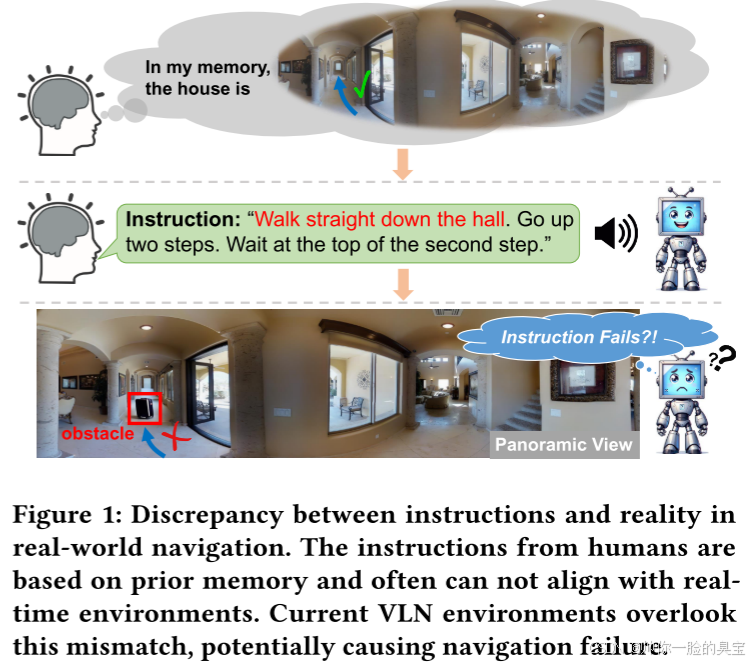
为了解决指令与现实不匹配的问题,有必要在视觉与语言导航(VLN)任务中引入这些不一致性。虽然各种因素都可能导致这种不匹配,但本文关注其中最具代表性和常见的原因:障碍物。我们提出将障碍物整合到现有的离散VLN环境中,通过在路径中设置障碍,模拟现实中的路径被阻挡的情况,进而导致指令与现实不匹配。在问题设置、导航重点和潜在解决方案上与ETPNav和SafeVLN有所不同,选择采用离散环境设置。
为了应对指令与现实不匹配的问题,我们对R2R数据集进行了各种修改,提出了R2R with UNexpected Obstructions (R2R-UNO) 数据集,作为首个强调指令与现实不匹配的VLN任务。在图的层面上,我们有选择性地阻塞了某些边,这些边的移除不会影响整个图的连通性,确保代理仍然能够到达目的地。通过这种方法,障碍物的加入不会完全阻断路径,而是为代理创造了绕行和适应的机会。为了保持图与视觉观测之间的一致性,我们设计了一个对象插入模块,利用文本到图像修补技术(inpainting),将不同的障碍物无缝集成到场景中。由于inpainting技术的不稳定性,我们引入了一个过滤模块,从多个候选中筛选出高质量的障碍物生成结果。使用R2R-UNO的数据集进行的实验表明,当前最先进的VLN代理在面对障碍物时表现不佳,限制了其在实际环境中的应用。
尽管我们期望代理在应对指令与现实不匹配时表现出色,但同时保持其在原始环境中的性能同样至关重要,因为大多数场景仍然符合原始设定。然而,直接在这两类不同类型的数据上进行训练会给代理带来挑战,因为代理不仅需要学会如何遵循指令,还需要能够区分不匹配和对齐的场景。实验表明,在这两种环境中(有障碍物和无障碍物)的差异可能会导致优化不平衡,即代理可能更偏向于适应一种场景,而忽略另一种场景。为了应对这一问题,我们开发了Obstructed VLN (ObVLN) 方法,具体包含课程学习策略与新颖的图构建机制,为阻塞边缘引入虚拟节点,以促进高效探索。如图2所示。
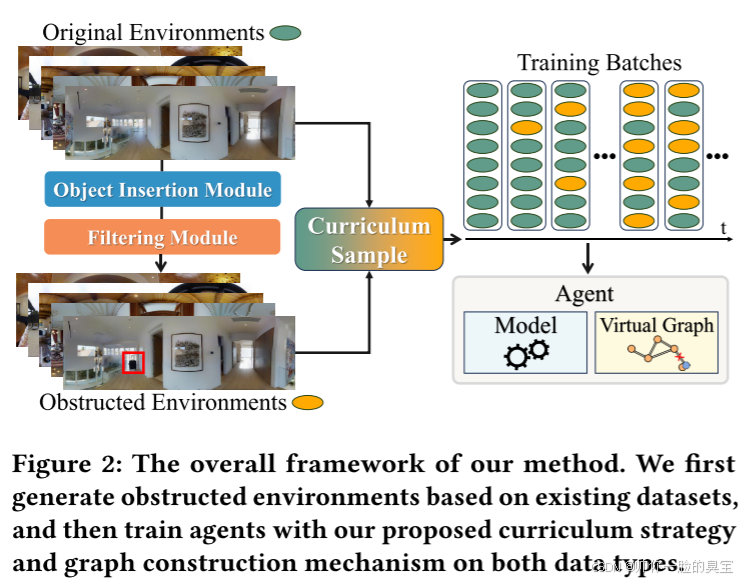
我们在R2R、REVERIE [51]和R2R-UNO数据集上进行了全面的实验,以验证在视觉与语言导航(VLN)任务中引入指令与现实不匹配场景的重要性。实验结果表明,现有的方法(如DUET [13])在有障碍物的设置中表现不佳,成功率(Success Rate, SR)显著下降了30%。我们提出的对象插入和过滤模块为代理提供了关键的视觉反馈,使其与导航图的变化保持一致。通过采用ObVLN方法,代理不仅在原始环境中保持了稳健的性能,还能有效适应指令与现实不匹配的场景,成功率(SR)达到了令人印象深刻的67%,这标志着一个显著的进步。
贡献总结:
-
解决了指令与现实不匹配的问题:我们提出了R2R-UNO,这是第一个通过导航图变化和多样化障碍物生成来模拟指令与现实不匹配的VLN数据集,提供了反映现实世界导航复杂性的独特挑战。
-
提升了现有VLN方法的适应性:我们指出当前VLN方法在有障碍物的环境中缺乏适应性,并提出了ObVLN作为解决方案。该方法通过课程学习和虚拟图构建提升了代理的适应能力。
-
实验验证了R2R-UNO的有效性:通过广泛的实验,我们证明了R2R-UNO在VLN研究中的重要性,且ObVLN在原始和有障碍物的环境中都表现出色,在R2R-UNO数据集上的成功率提高了23%。
相关工作
视觉语言导航
VLN中的环境改变
避障
障碍物避让一直是视觉导航中的一个长期挑战 [1, 9, 48, 58]。在视觉与语言导航(VLN)任务中,ETP-Nav [3] 应用了带有试错启发式的障碍避让控制器,用于明确摆脱死锁。SafeVLN [70] 则采用了基于LiDAR的航点预测器和重选策略,避免选择不可导航的路径点和障碍物。然而,我们的工作在连续环境[29] 与这些研究有三个关键方面的不同,因此选择了离散环境。
本研究的三大区别:
-
更广泛的指令-现实不匹配情境:
- 我们的研究针对更广泛的场景,包括可避让的障碍物、关闭的门、重新布置的家具、指令错误等。这些情况可以通过对导航图的更改有效地捕捉,但很难用连续信号来建模。
-
关注导航图的变化而非障碍物的性质:
- 障碍物避让方法专注于评估障碍物的属性以进行避让,而我们的工作更强调导航图的变化,这些变化会使指令暂时失效,而不关心障碍物的具体形状或大小。采用离散设置将路径规划与技术细节(如障碍物的形状和大小)解耦,从而更关注当指令失效时的高层次适应性,增强了其通用性。
-
指令-现实不匹配涉及复杂的策略:
- 解决指令与现实不匹配的问题,不仅仅是绕过障碍物,还需要一种复杂的策略来找到绕行路径,以及在没有指令引导的情况下进行导航的能力。这种适应性挑战对于当前的连续环境代理来说过于困难,因此我们选择了离散设置,以更好地应对这些高层次的导航挑战。
障碍环境的构建
问题设定
在VLN任务中,代理需要遵循自然语言指令在一个模拟环境导航。这些环境通常是离散的,预定义了无向导航图,包含可导航的节点和连通边。在每个时间步,代理接收到一个全景表示(包含36个视角)和一个方位信息(编码了当前节点的朝向和仰角)。代理通过选择与目标节点最匹配的视图,决定采取的动作,并移动到相邻的节点。
每个指令都存在对应的地面真实路径,表示代理要遵循的轨迹。然而,之前的工作假设指令与现实之间的对齐是完美的,所有的边都可以被访问,忽略了现实世界中导航图可能发生的变化。
在导航图变化的各种原因中,我们关注最具代表性的一个:障碍物。在障碍环境中,某些特定的边可能会被阻塞,使得部分指令无法应用于当前场景。这些阻塞不仅影响导航图,还导致节点之间的全景视图发生变化。代理需要找到替代路径来到达目标节点。
R2R-UNO
Graph Changes

值得注意的是,在构造时,当 𝑃′ 包含来自 𝑃 的未来视点时,我们故意避免缩短路径,即使这会导致 𝑃´ 中形成循环。 这种设计符合实际的导航场景,因为当偏离指令时,由于缺乏上下文线索,代理很难将当前的观点与所描述的路径保持一致。 因此,对于智能体来说,在尝试重新遵循指令之前寻求绕行障碍物是合乎逻辑且有效的。具体来说,当代理遇到障碍时,它需要寻找绕行的替代路径
。然而,这并不意味着代理应该尽可能缩短路径。相反,代理应该绕过障碍物,并在绕行后尝试重新与原始导航指令保持一致。即使在某些情况下,这可能会导致路径稍微变长甚至形成某种“循环”,也更符合实际导航场景中的逻辑和效率要求。
Visual Changes
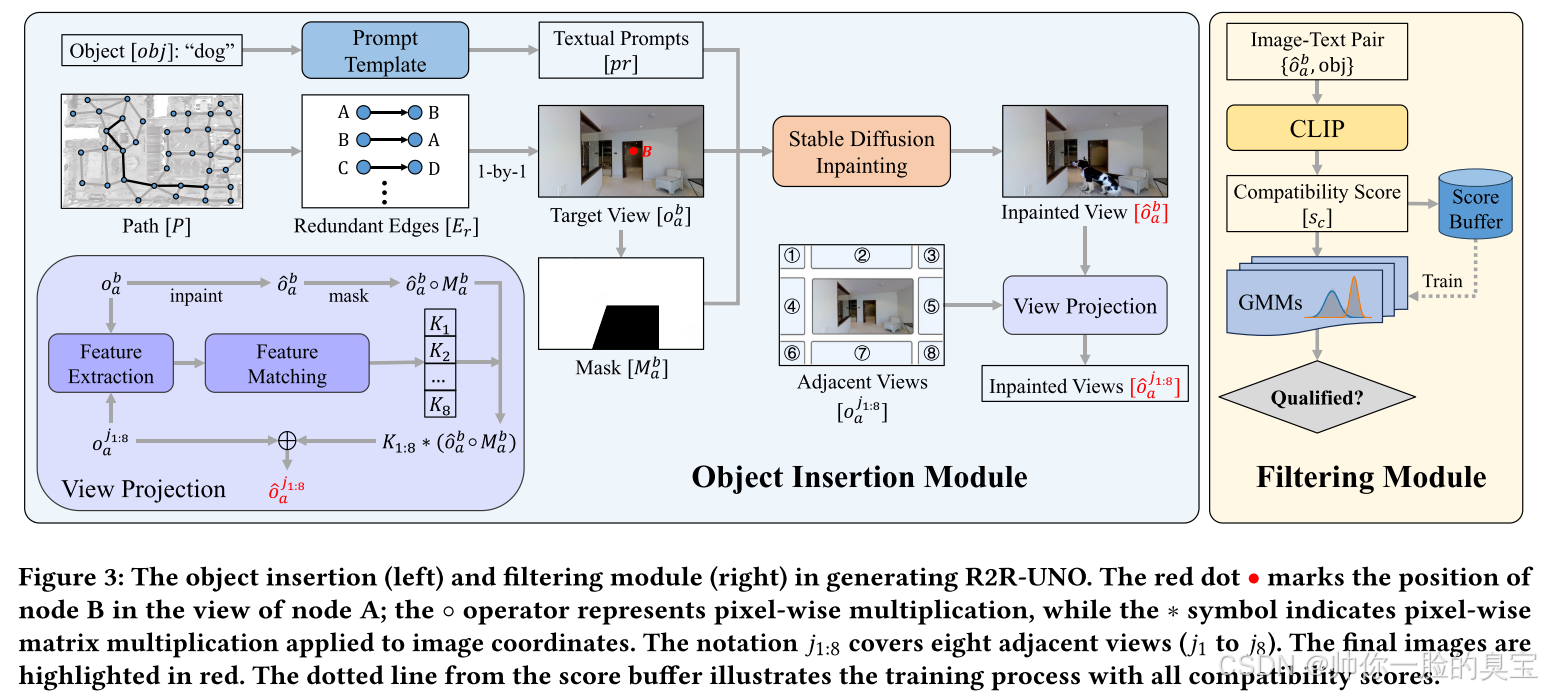
对象插入模块

虽然使用修复模型可以生成看起来视觉上连贯且逼真的图像,但这些模型并不总是稳定的。例如:在修复过程中,掩模外部的区域(即不受掩模控制的图像部分)已经包含了与目标对象相似的元素,那么即使为模型提供了复杂的提示,模型仍然可能会受到误导,无法准确地处理或合并目标对象。这种情况下,模型可能错误地将现有的类似元素视为目标对象,而无法生成正确的图像。
过滤模块

Score buffer的作用是保存每个图像-文本对({ôᵇₐ, obj})的兼容性评分(sc),这些评分由CLIP模型生成。通过将评分存储在Score buffer中,可以为后续的高斯混合模型(GMM)训练提供数据支持。GMM需要通过这些评分的分布来学习每个对象类别的特征,并区分成功融合和失败融合的图像。
最后,我们从合格的候选视图中随机选择一个作为修改后的视图。如果没有合适的候选项,则从得分最高的前三名中进行选择。该模块不仅大大提高了合并可见障碍物的概率,还确保所选对象在上下文中是合适的。

指令-现实的错位及解决方案
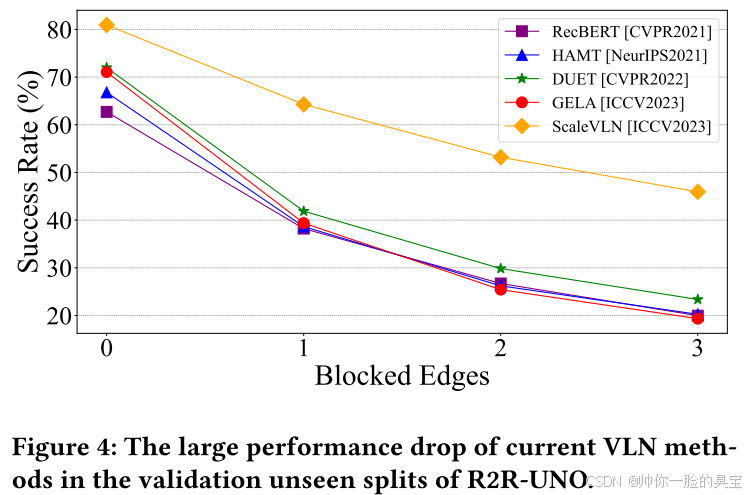
为了评估指令与现实失配的影响,我们使用五种先进的VLN方法对R2R-UNO验证不可见的分离进行零命中评估,这些方法以在完美指令假设下的出色性能而闻名,包括RecBERT[22]、HAMT[12]、DUET[13]、Gela[14]和ScaleVLN[67]。图4示出了它们的成功率如何随着阻塞边的不同数量而变化。虽然大多数方法在原始环境中的成功率为60%-70%,但当单边受阻时,曲线急剧下降到40%左右,在Block-2和Block-3场景中观察到进一步恶化。ScaleVLN在R2R-UNO中的性能优于其他方法,这得益于大量训练数据带来的强大泛化能力,但在R2R-UNO的块1集中,ScaleVLN的性能仍然下降了近20%。我们得出的结论是,目前的VLN模型过于关注指令跟随能力,而缺乏必要的基本导航功能来适应图形变化。这些发现强调了在外语学习研究中使用完美教学假设的严肃性和解决问题的紧迫性。
Ob-VLN

实验
数据集和评估指标
我们主要在广泛使用的 VLN 基准 R2R [6] 上评估我们的方法,该基准使用逐步指令,并且我们提出了 R2R-UNO 来专注于应对指令与现实不匹配的挑战。我们在附录中展示了没有这些不匹配的目标导向基准 REVERIE [51] 的结果。R2R 基于 Matterport3D 数据集 [11],包括来自 90 个建筑级场景的 10,800 个全景视图。每个 R2R 路径有三到四个由人类注释的自然语言指令。R2R 共有四个划分:训练集、已见验证集(val seen)、未见验证集(val unseen)和未见测试集(test unseen)。我们使用训练集进行训练,并使用已见验证集和未见验证集进行评估,以与 R2R-UNO 保持一致。
在评估中,我们遵循以往的工作 [2, 71],使用 VLN 中的四个主要指标:
- 轨迹长度 (TL):导航的总长度(米)。
- 导航误差 (NE):停止位置与目标位置之间的距离。
- 成功率 (SR):代理在目标3米范围内停止的比例。
- 路径长度加权成功率 (SPL) [4]:成功率(SR),按最短路径与预测路径的长度比例进行归一化。
由于包含了障碍物修改的轨迹,像 CLS [24] 或 nDTW [23] 这样的指令忠实度相关指标没有包括在内。
实现细节
为了创建 R2R-UNO 数据集,我们使用 stable-diffusion-v1.5-inpainting 模型进行物体插入,并使用 CLIP ViT-L/14 来评估文本-图像对。我们采用暴力搜索和 K-近邻匹配方法对齐两个相邻视图的 SIFT 特征。对于图 4 中的方法,我们使用这些方法在验证集(unseen split)中的最佳模型,并根据其设置提取有障碍环境的特征。我们采用 HAMT [12] 和 DUET [13] 进行导航训练,并遵循它们官方仓库中的实现细节。障碍环境仅用于微调阶段。最大样本比例 𝛼max 被设置为 0.5,增加步长 c 为 20,000。我们将最大动作长度增加到 30,以适应更长的真实路径。使用 PREVALENT [19] 作为增强数据来稳定训练过程。我们使用 AdamW 优化器 [43],并根据 R2R 和 R2R-UNO 验证集中的平均 SPL 选择最佳模型。所有模型均在 NVIDIA A6000 GPU 上进行 100K 次迭代微调,学习率为 1e-5,批次大小为 8。
主要实验结果
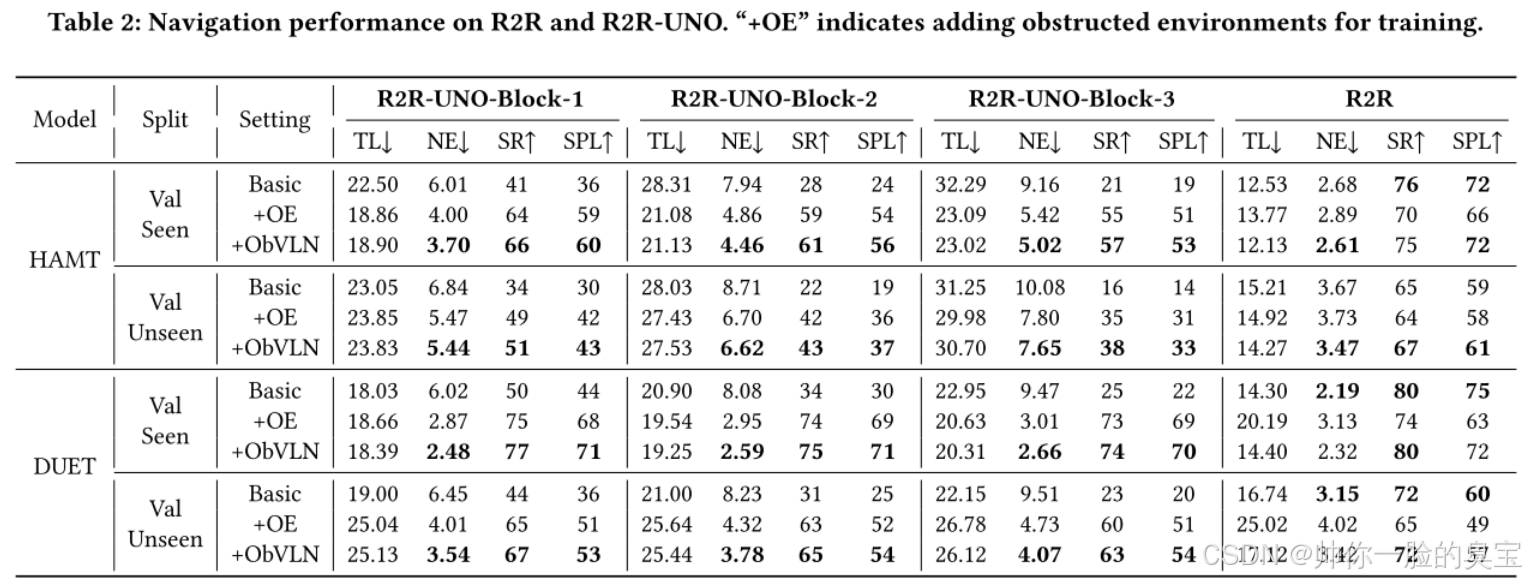
我们首先证明了所提出的障碍环境和 ObVLN 方法能够帮助代理适应指令与现实的不匹配。因此,我们对 HAMT 和 DUET 两种方法在三种不同的训练设置下进行了评估:
- Basic:仅使用 R2R 进行训练;
- +OE:结合 R2R 和 R2R-UNO 数据进行训练;
- +ObVLN:使用 ObVLN 方法在 R2R 和 R2R-UNO 上进行训练。
需要注意的是,设置 2 和 3 都包含了 R2R-UNO 数据集中的所有三组数据。表2展示了不同模型在 R2R 和 R2R-UNO 验证集(seen 和 unseen 集合)上的导航性能。结果表明,使用两种数据训练的模型在导航 R2R-UNO 数据集中的障碍场景时,明显优于仅在 R2R 上训练的模型。然而,这种改进伴随着 R2R 性能的显著下降,例如 DUET 在 seen 和 unseen 集合中 SR(成功率)分别下降了 6% 和 7%。这一现象可以通过 R2R 中轨迹长度(TL)的显著增加来解释,这表明代理在优化障碍环境时过度适应,导致即使在没有障碍的情况下也倾向于绕道而行。
我们的 ObVLN 方法有效地解决了这一问题。对于 HAMT 来说,ObVLN 在 R2R 上超过了基础设置,并在 R2R 和 R2R-UNO 的四个数据集上取得了最佳结果。对于 DUET,由于其拓扑地图和全局动作空间的设计,代理倾向于返回到与指令最佳匹配的被阻挡边缘的节点。这导致了 ObVLN 在 R2R 上 SPL(路径长度加权成功率)方面的效率略有下降。然而,它仍然在成功率(SR)上与基础设置相当,并且显著超过了设置 2(+OE)在 R2R 上的表现。此外,ObVLN 在 R2R-UNO 的三组数据上都达到了最先进的结果。
由于 HAMT 不是基于地图的方法,因此我们提出的图构建机制对 HAMT 的优势影响较小。尽管 DUET 在 R2R 上的成功率领先 HAMT 7%,但这一优势在障碍环境中变得更加显著,尤其是在最具挑战的 Block-3 数据集上,DUET 取得了约 25% 的成功率领先。这一优势归因于 DUET 中的拓扑图设计,它显著增强了探索效率,并在寻找绕行路径时起到了关键作用。这一优势在像 REVERIE 这样的依赖探索的对象导向数据集中表现尤为明显。
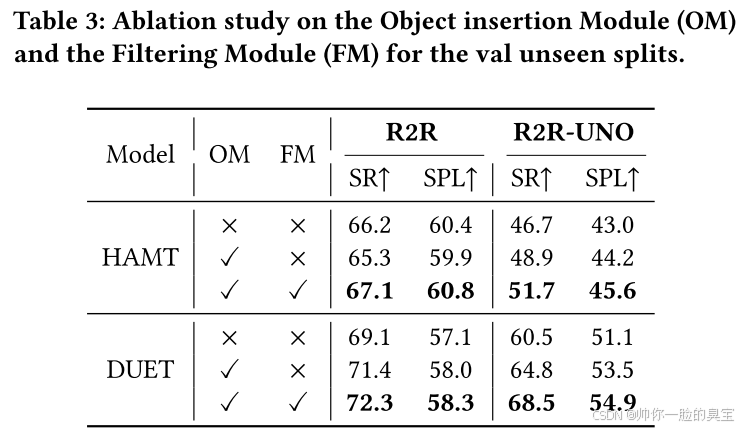
消融研究
R2R-UNO两个模块的消融
采样策略
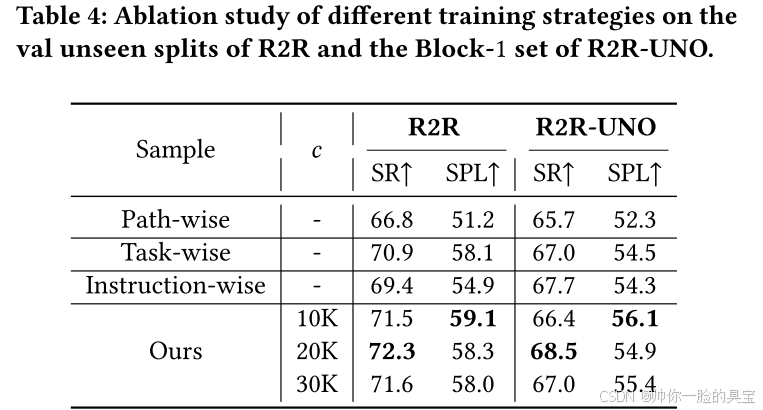
们探讨了四种用于 DUET 模型在原始环境和障碍环境中采样的策略:
- Path-wise:从 R2R 和 R2R-UNO 路径的合并池中随机选择一个路径进行训练;
- Task-wise:使用伯努利混合分布从原始环境和障碍环境中采样,分别以概率 1 − 𝛼t 和 𝛼t 进行数据采样;
- Instruction-wise:对于每条指令,从所有可能的路径中随机选择一个路径;
- 课程采样(Curriculum sample, 我们的策略):逐步增加采样比例 𝛼,直到达到最大值 𝛼max,增加步长为 c。
表4展示了这些采样策略在 R2R 和 R2R-UNO 未见验证集(val unseen splits)中的表现。我们将 𝛼t 设置为 0.5 以匹配 𝛼max,并在附录中提供了不同 𝛼t 和 𝛼max 的实验结果。
在所有采样策略中,课程采样(Curriculum sample)策略表现最佳,在 R2R 和 R2R-UNO 两个数据集中都取得了优异的性能。其他方法由于过度优化问题,导致在 R2R 数据集上的性能下降。Path-wise 采样表现最差,原因是路径不平衡问题,在包含大量冗余边的路径上进行了更多训练,而忽略了那些没有或较少冗余边的路径。
图构建机制
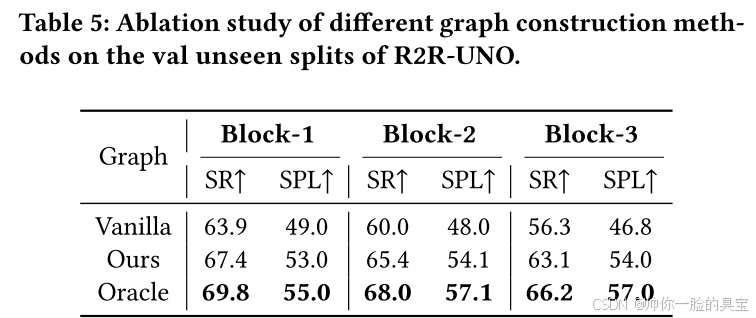
我们将我们的图构建机制与两个基线进行比较:
- Vanilla 设置:忽略图中的障碍物,不考虑阻挡情况。
- 理想化的 Oracle 设置:该设置被赋予了关于由于障碍物而被遮挡节点的真实信息,作为性能的上限。
表5展示了不同图构建方法下 DUET 模型在 R2R-UNO 数据集未见验证集(val unseen splits)上的表现。我们的方法通过将虚拟节点引入到图中,在所有三个数据集中显著优于 Vanilla 设置,尤其是在更具挑战性的情景(例如有三个阻挡边)中表现尤为出色。正如预期的那样,Oracle 图由于能够获取准确的未受障碍影响的节点信息,达到了最高的性能。

















 635
635

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









