




 该博客介绍了对小白菜试验数据进行统计分析的过程,包括数据的读取、正态性检验(通过QQ图和Shapiro-Wilk检验)、方差齐性检验(采用Bartlett检验)以及单因素方差分析。通过多重比较和图形化展示,揭示了不同处理条件对小白菜鲜重的影响,并以柱状图形式展示了结果,其中使用了Tukey检验进行显著性差异判断。
该博客介绍了对小白菜试验数据进行统计分析的过程,包括数据的读取、正态性检验(通过QQ图和Shapiro-Wilk检验)、方差齐性检验(采用Bartlett检验)以及单因素方差分析。通过多重比较和图形化展示,揭示了不同处理条件对小白菜鲜重的影响,并以柱状图形式展示了结果,其中使用了Tukey检验进行显著性差异判断。
读取数据
library(tidyverse)
library(readxl)
data2 <- readxl::read_xlsx("C:\\Users\\zhang\\Desktop\\小白菜试验数据.xlsx",sheet="Sheet3")
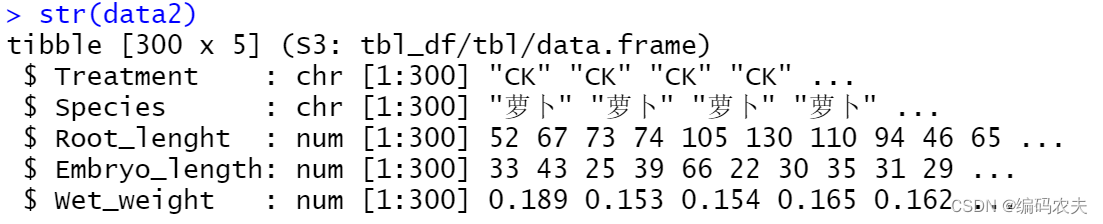
str(data2)
数据结构
正态检验
data2_baicai <- data2%>%filter(Species=="小白菜")
##定性检验
qqPlot(lm(data2_baicai$Wet_weight~data2_baicai$Treatment))
qqPlot(lm(log(data2_baicai$Wet_weight)~data2_baicai$Treatment)) ##log转化
##定量检验
shapiro.test(residuals(lm(data2_baicai$Wet_weight~data2_baicai$Treatment)))
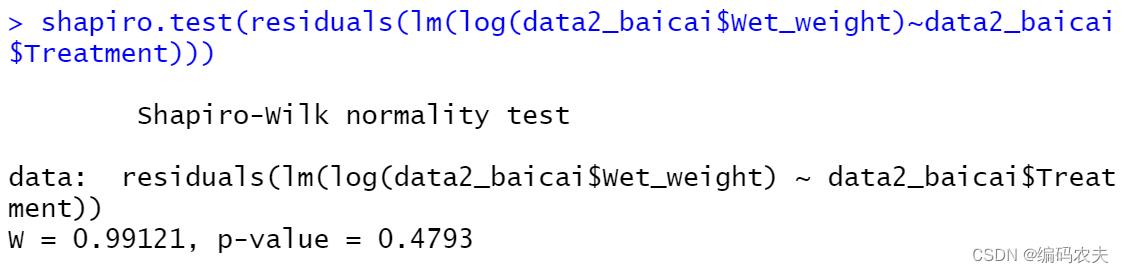
shapiro.test(residuals(lm(log(data2_baicai$Wet_weight)~data2_baicai$Treatment))) ##log转化
原数据残差正态检验
定性
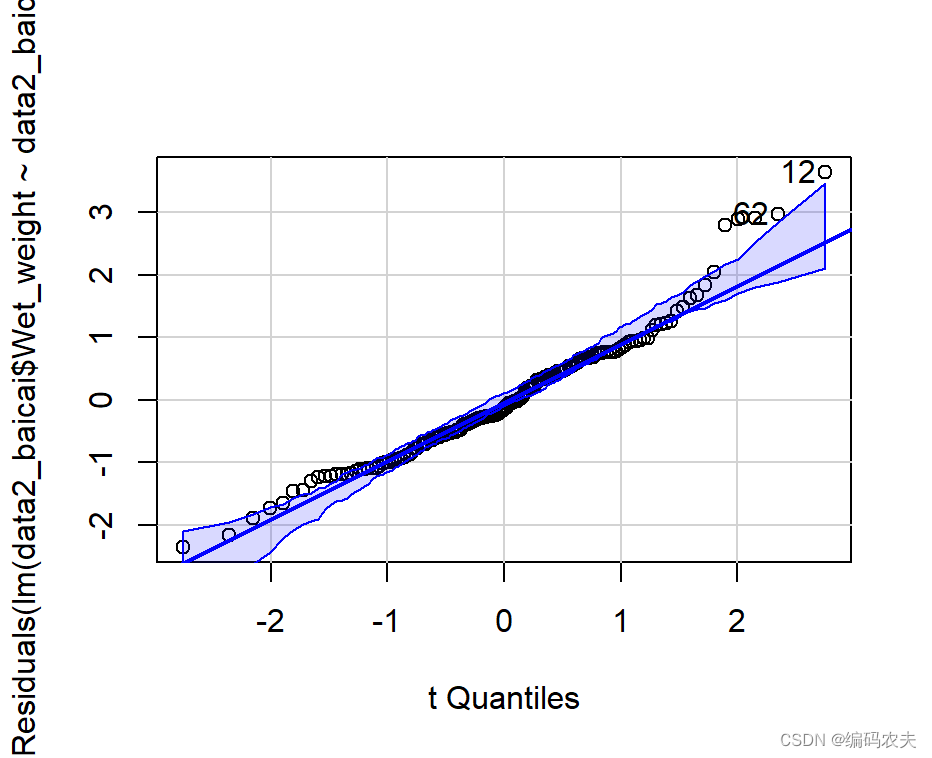
定量

log转化后正态检验
定性
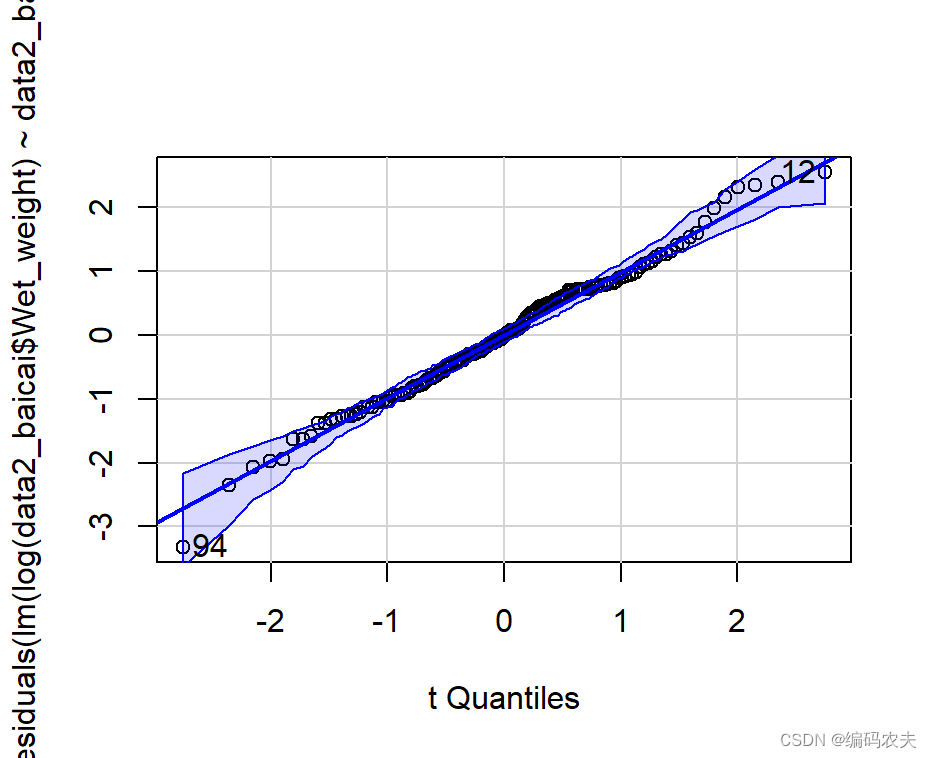
定量
方差齐性检验
bartlett.test(log(data2_baicai$Wet_weight),data2_baicai$Treatment)

单因素方差分析
library(multcomp) ##方差分析包
par(mar=c(4,4,7,4)) ##调整图形大小
data2_baicai$Treatment <- as.factor(data2_baicai$Treatment) ##将数据类型的处理改为因子类型
fit <- aov(log(Wet_weight)~Treatment,data2_baicai) ##方差分析
summary(fit) ## 方差分析结果

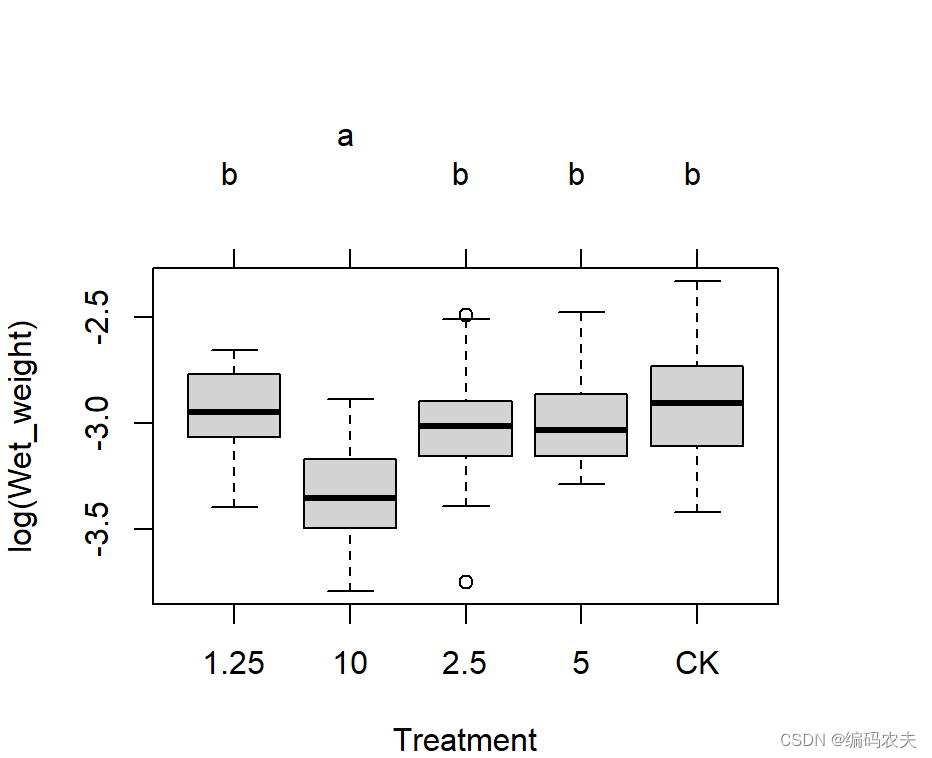
多重比较
plot(cld(glht(fit, linfct=mcp(Treatment="Tukey")),level = 0.05,col="lightgrey")) ##多重比较图形化,这里使用Tukey检验
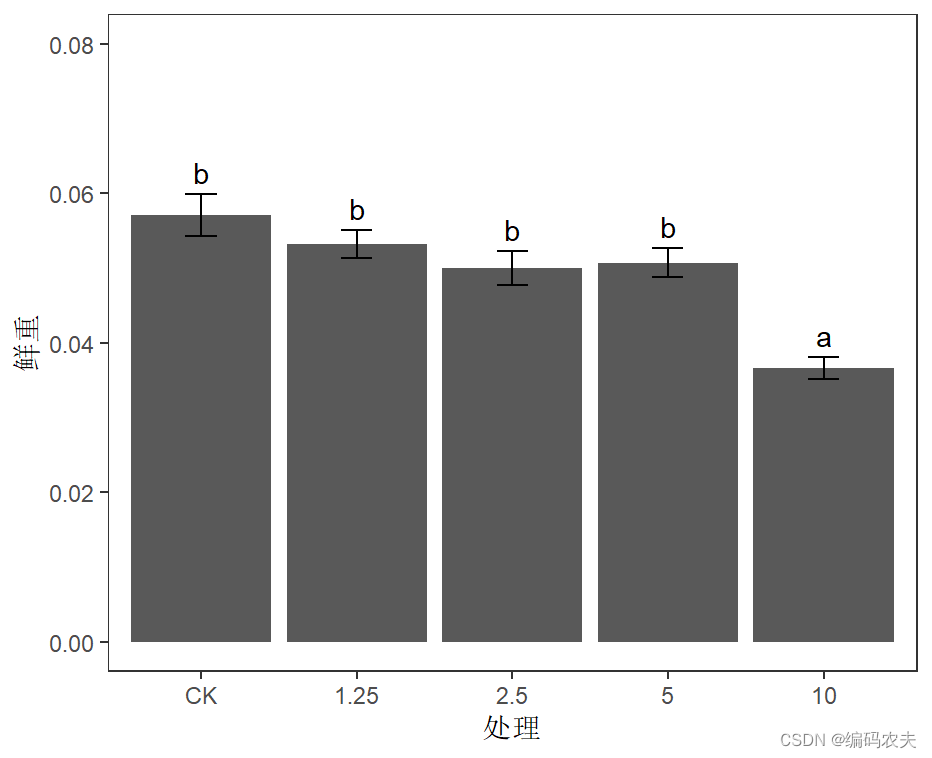
作图
library(sciplot) ##计算标准误的包
data2_baicai$Treatment <- factor(data2_baicai$Treatment,levels = c("CK","1.25","2.5","5","10"))##改变x轴坐标顺序
data2_baicai%>%group_by(Treatment)%>%
summarise(mean=mean(Wet_weight),se=se(Wet_weight))%>% ##分组计算平均值和标准误
mutate(labels=c("b","b","b","b","a"))%>% ##添加显著性标记到数据中
ggplot()+
geom_col(aes(x=Treatment,y=mean))+ ##画柱状图
geom_errorbar(aes(x=Treatment,ymin=mean-se,ymax=mean+se),width=0.2)+ ##添加误差线
labs(x="处理",y="鲜重")+ ##更改xy轴的名称
geom_text(aes(x=Treatment,y=mean+se,label=labels,vjust = -0.5, hjust = "center"))+ ## 添加显著性标记到图形中
ylim(0,0.08)+ ## 设置y轴的范围
theme_test() ## 设置图形主题


















 327
327

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











