 使用OpenPose进行人体、脸部和手部关键点检测
使用OpenPose进行人体、脸部和手部关键点检测





 这篇博客介绍了如何利用OpenPose库在Python中进行人体、脸部和手部关键点检测。首先,通过导入pyopenpose库并设置参数,包括指定模型路径、开启face和hand检测。接着,读取图片并进行识别,关键点信息存储在datum对象中,包括BODY25、face和handKeypoints。BODY25包含25个全身关节点,face有70个坐标点,手部有21个关节点。识别后的图片可以显示出来,关节点坐标可用于后续的分析或应用。
这篇博客介绍了如何利用OpenPose库在Python中进行人体、脸部和手部关键点检测。首先,通过导入pyopenpose库并设置参数,包括指定模型路径、开启face和hand检测。接着,读取图片并进行识别,关键点信息存储在datum对象中,包括BODY25、face和handKeypoints。BODY25包含25个全身关节点,face有70个坐标点,手部有21个关节点。识别后的图片可以显示出来,关节点坐标可用于后续的分析或应用。
Step1: 识别图片中的关节点
根据examples中的例子,首先导入pyopenpose库
# Import Openpose (Windows)
dir_path =r'C:\Users\WJT\Desktop\myopenpose\build\examples\tutorial_api_python'
if platform == "win32":
# Change these variables to point to the correct folder (Release/x64 etc.)
sys.path.append(dir_path + '/../../python/openpose/Release');
os.environ['PATH'] = os.environ['PATH'] + ';' + dir_path + '/../../x64/Release;' + dir_path + '/../../bin;'
import pyopenpose as op
之后按照实例中的写法,输入待检测的图片地址
# Flags
parser = argparse.ArgumentParser()
parser.add_argument("--image_path", default="../../../examples/media/COCO_val2014_000000000474.jpg",
help="Process an image. Read all standard formats (jpg, png, bmp, etc.).")
args = parser.parse_known_args()
添加参数,由于我们在此做全身的识别,所以要将face和hand设为True(具体看实例)
# Custom Params (refer to include/openpose/flags.hpp for more parameters)
params = dict()
params["model_folder"] = "../../../models/"
params["face"] = True
params["hand"] = True
之后,再照抄实例的写法,将参数进行进一步设置
# Add others in path?
for i in range(0, len(args[1])):
curr_item = args[1][i]
if i != len(args[1])-1: next_item = args[1][i+1]
else: next_item = "1"
if "--" in curr_item and "--" in next_item:
key = curr_item.replace('-','')
if key not in params: params[key] = "1"
elif "--" in curr_item and "--" not in next_item:
key = curr_item.replace('-','')
if key not in params: params[key] = next_item
再进行下一步,代码注释已经很详细
opw = op.WrapperPython()# 创建openpose的包装器
opw.configure(params)# 将之前的参数配置到包装器中
opw.start()# 类似于包装器建立成功
datum = op.Datum()# datum是openpose的一个管理数据的类
path = args[0].image_path
img = cv2.imread(path)# 读取待识别的图片
datum.cvInputData = img# 将图片作为输入图片导入
然后,开始识别图片中的关节点
opw.emplaceAndPop(op.VectorDatum([datum]))# 进行识别
可以通过以下两种形式打印识别好的图片
1、
cv2.imshow("datum.cvOutputData", datum.cvOutputData)
效果:

2、
cv2.imshow("datum.outputData", datum.outputData)
效果:

Step2: 提取关节点的坐标
关节点的坐标保存在datum中,主要分为三类:
-
全身骨关节点(pose)
骨关节点作者了解的是两个,貌似有三个,一个是BODY25,另一个是COCO18BODY25:
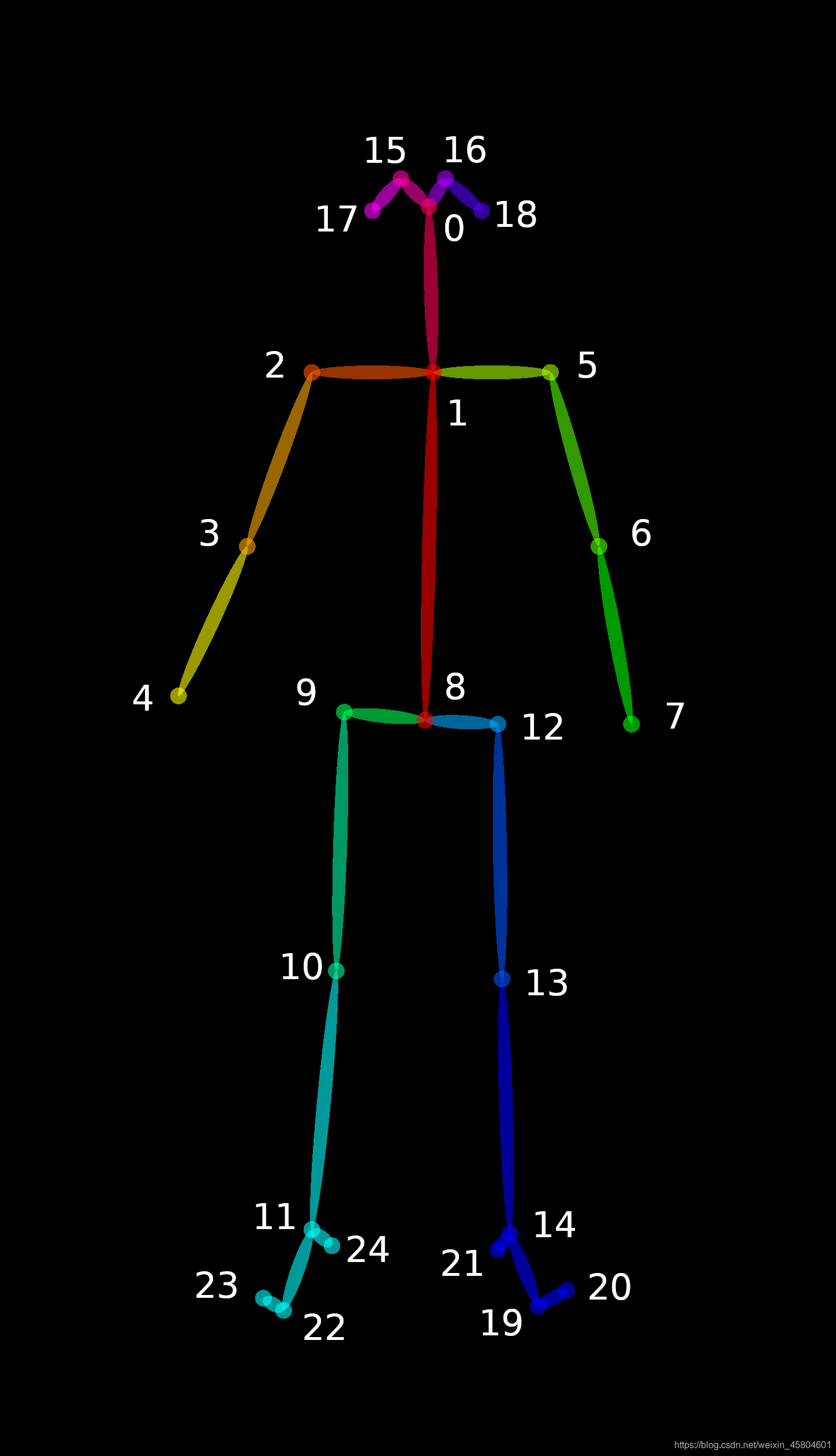
COCO18:
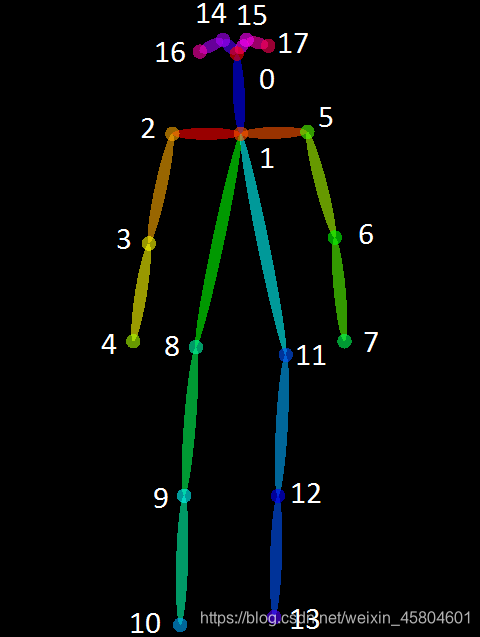
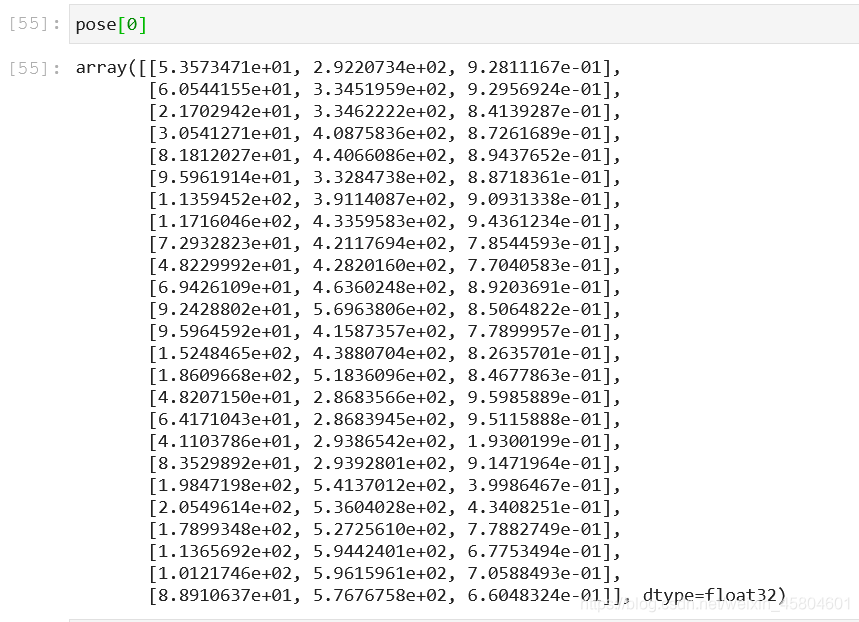
我用到的是BODY25,它储存在datum.poseKeypoint中,数据形式如下:
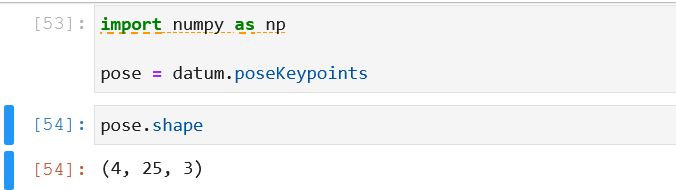
在(4,25,3)的数据结构中:
4代表图片中有4个人,25表示BODY25中的25个关节点对应的坐标,3的前两列表示关节点在图中的坐标,第三列表示置信度(大于0小于1)
- 脸关节点(face)
同全身骨关节,脸有70个坐标点,如图
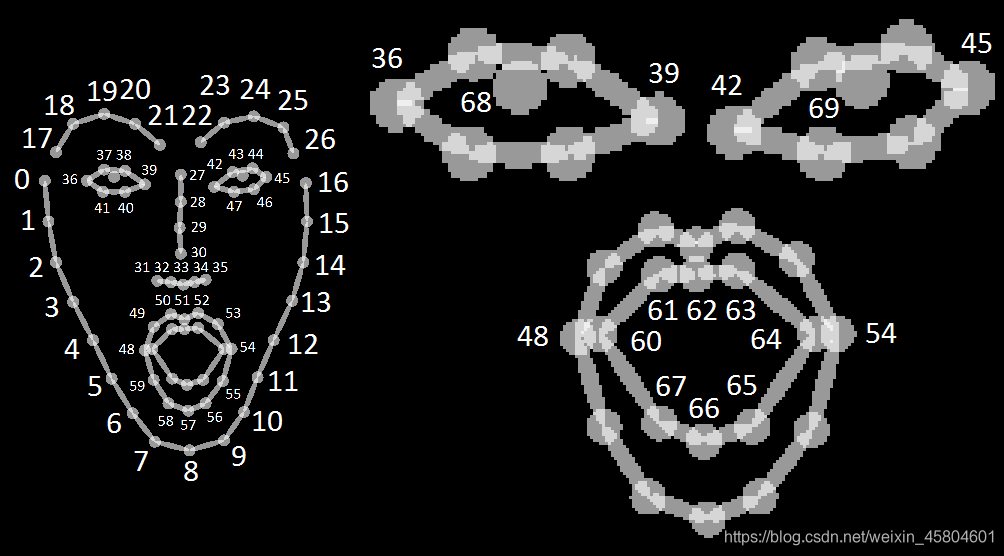
坐标点储存在datum.faceKeypoints中
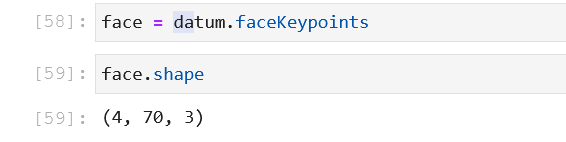
数据格式的理解同上
- 手关节点(hand)
手的关节点为21个:
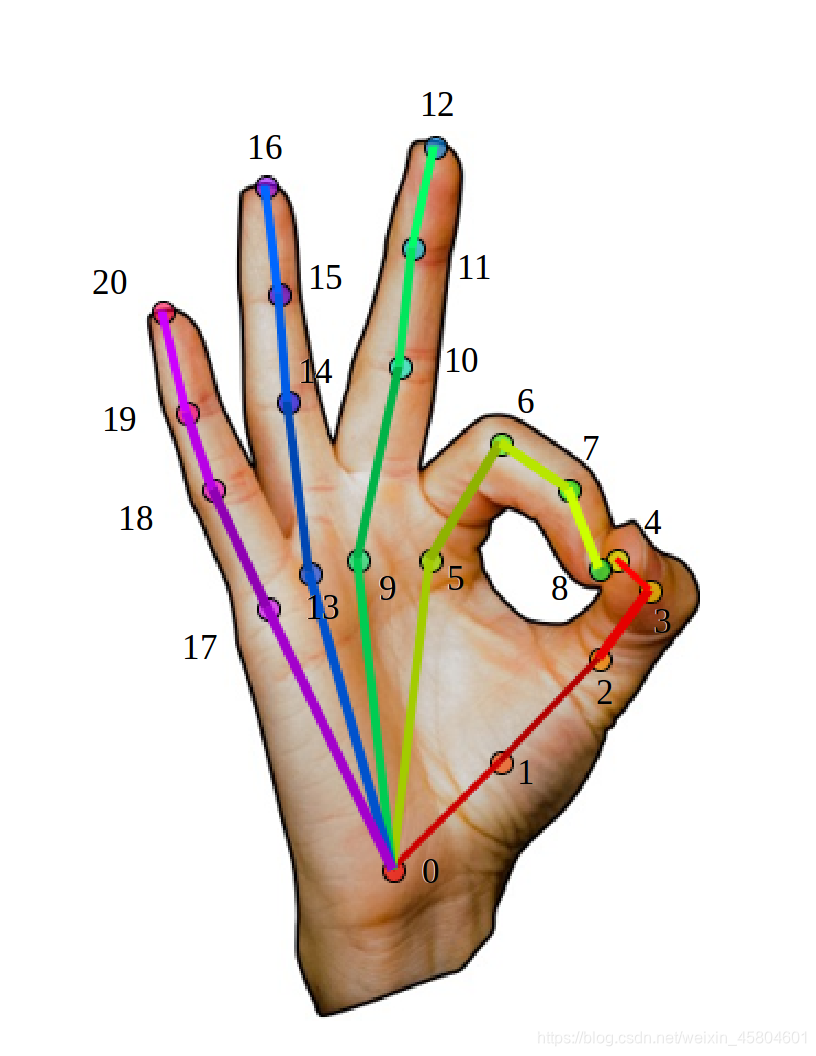
储存在datum.handKeypoints,由于有两个手,所以该属性是一个列表,存放了两个手的坐标数组

数据格式的理解同上
至此,关节点的坐标解释完成
https://github.com/CMU-Perceptual-Computing-Lab/openpose/blob/master/doc/02_output.md
https://github.com/CMU-Perceptual-Computing-Lab/openpose/blob/master/doc/03_python_api.md


















 5321
5321

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









