







文章目录
一、介绍
1.1 什么是ck
是一个面向列的数据库管理系统 (DBMS),用于查询的在线分析处理 (OLAP)。
1.2 OLAP 场景的关键属性
- 绝大多数请求都是针对读取访问的。
- 数据以相当大的批次(> 1000 行)更新,而不是单行更新;或者根本没有更新。
- 数据被添加到数据库中,但不会被修改。
- 对于读取,从数据库中提取了相当多的行,但只提取了一小部分列。
- 表是“宽的”,这意味着它们包含大量列。
- 查询相对较少(通常每台服务器每秒有数百个查询或更少)。
- 对于简单查询,允许大约 50 毫秒的延迟。
- 列值相当小:数字和短字符串(例如,每个 URL 60 个字节)。
- 处理单个查询时需要高吞吐量(每台服务器每秒高达数十亿行)。
- 交易不是必需的。
- 对数据一致性要求低。
- 每个查询有一个大表。所有的桌子都很小,除了一张。
- 查询结果明显小于源数据。换句话说,数据被过滤或聚合,因此结果适合单个服务器的 RAM。
1.3 列式存储和行式存储的区别
面向行的表是“长”的,而面向列的表是‘宽”的。
- 行式存储
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-CwnSET3E-1650767754248)(https://clickhouse.com/docs/en/images/row-oriented.gif)]
-
列式存储
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-TngQ8x3K-1650767754248)(https://clickhouse.com/docs/en/images/column-oriented.gif)]
-
行式存储的数据库,在进行数据查询时,要先将目标数据的一整行数据全部检索出来,然后再从中抽取出自己想要的目标字段,接着进行下一行的检索,导致查询出了很多多余的数据,还要进行抽取目标字段的操作,消耗性能。
-
列式数据库它的每一行存储的都是同一个Name的数据,检索时只需要找到目标字段所在的行数,然后取出该行所有数据
比如:我想取出
Title字段?- 行式数据库 表一:
Row WatchID JavaEnable Title GoodEvent EventTime #0 89354350662 1 Investor Relations 1 2016-05-18 05:19:20 #1 90329509958 0 Contact us 1 2016-05-18 08:10:20 #2 89953706054 1 Mission 1 2016-05-18 07:38:00 - 列式数据库 表二:
Row: #0 #1 #2 WatchID: 89354350662 90329509958 89953706054 JavaEnable: 1 0 1 Title: Investor Relations Contact us Mission GoodEvent: 1 1 1 EventTime: 2016-05-18 05:19:20 2016-05-18 08:10:20 2016-05-18 07:38:00 对于表一来说,我需要将三行数据全部检索出来,再去取它们的
Title值。对于表二来说,我只需要将第三行
Title所在的那一行数据全部读取出来,就是我想要的目标值。 -
二、安装&卸载
2.1 安装
- 安装 macOS Aarch64 版本
curl -O 'https://builds.clickhouse.com/master/macos-aarch64/clickhouse' && chmod a+x ./clickhouse
- 启动服务
./clickhouse server - 第一次启动服务后另外打开一个终端输入
ls -la
- Clickhouse 的界面
开启服务后进入转到http://localhost:8123/play以访问UI:
2.2 卸载
直接通过命令rm -rf clickhouse
2.3 相关的文件夹
三、 SQL语句
3.1 数据库操作
- 查看数据库命令
SHOW DATABASES
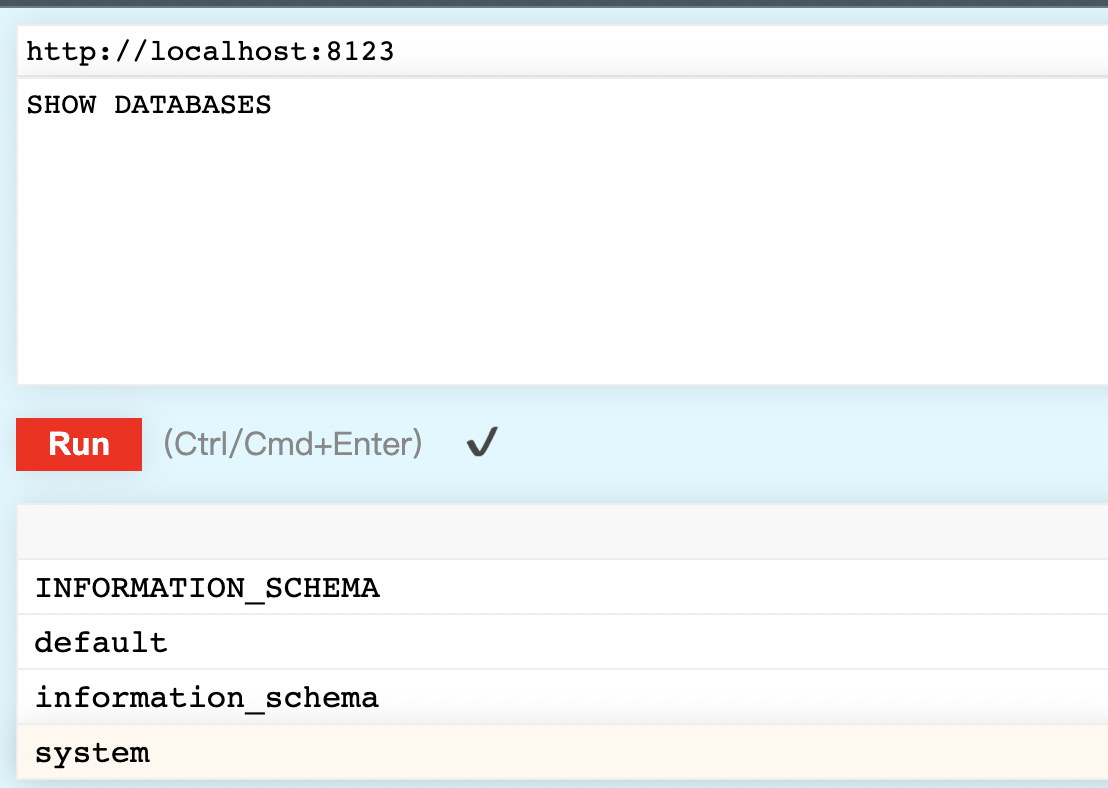
- 查看数据库中的表名
SHOW TABLES IN [数据库名称]
#比如
SHOW TABLES IN system
- 创建&删除数据库
CREATE DATABASE [数据库名称]
drop database [数据库名称]
3.2 数据表操作
- 创建数据表
ClickHouse 有自己的数据类型,每个表都必须指定一个Engine属性来确定要创建的表的类
CREATE TABLE tianzhuang.devin (
customer_id String,
time_stamp Date,
click_event_type String,
country_code FixedString(2),
source_id UInt64
)
ENGINE = MergeTree()
ORDER BY (time_stamp)
表引擎决定了数据的存储方式和存储位置、支持哪些查询、对并发的支持
- 查看表结构
DESCRIBE [数据库.表名]
DESCRIBE tianzhuang.devin
- 插入数据
- 典型 插入
INSERT INTO [数据库.表名] VALUES ()
INSERT INTO tianzhuang.devin
VALUES ('customer1', '2021-10-02', 'add_to_cart', 'US', 568239 )
- 指定列名插入
INSERT INTO [数据库.表名] (列名,列名,列名,,) VALUES (, , ,)
INSERT INTO tianzhuang.devin (customer_id, time_stamp, click_event_type)
VALUES ('customer2', '2021-10-30', 'remove_from_cart' )
- 排除某一列后插入数据
INSERT INTO [数据库.表名] (* EXCEPT(列名)) VALUES (,,,)
INSERT INTO tianzhuang.devin (* EXCEPT(country_code))
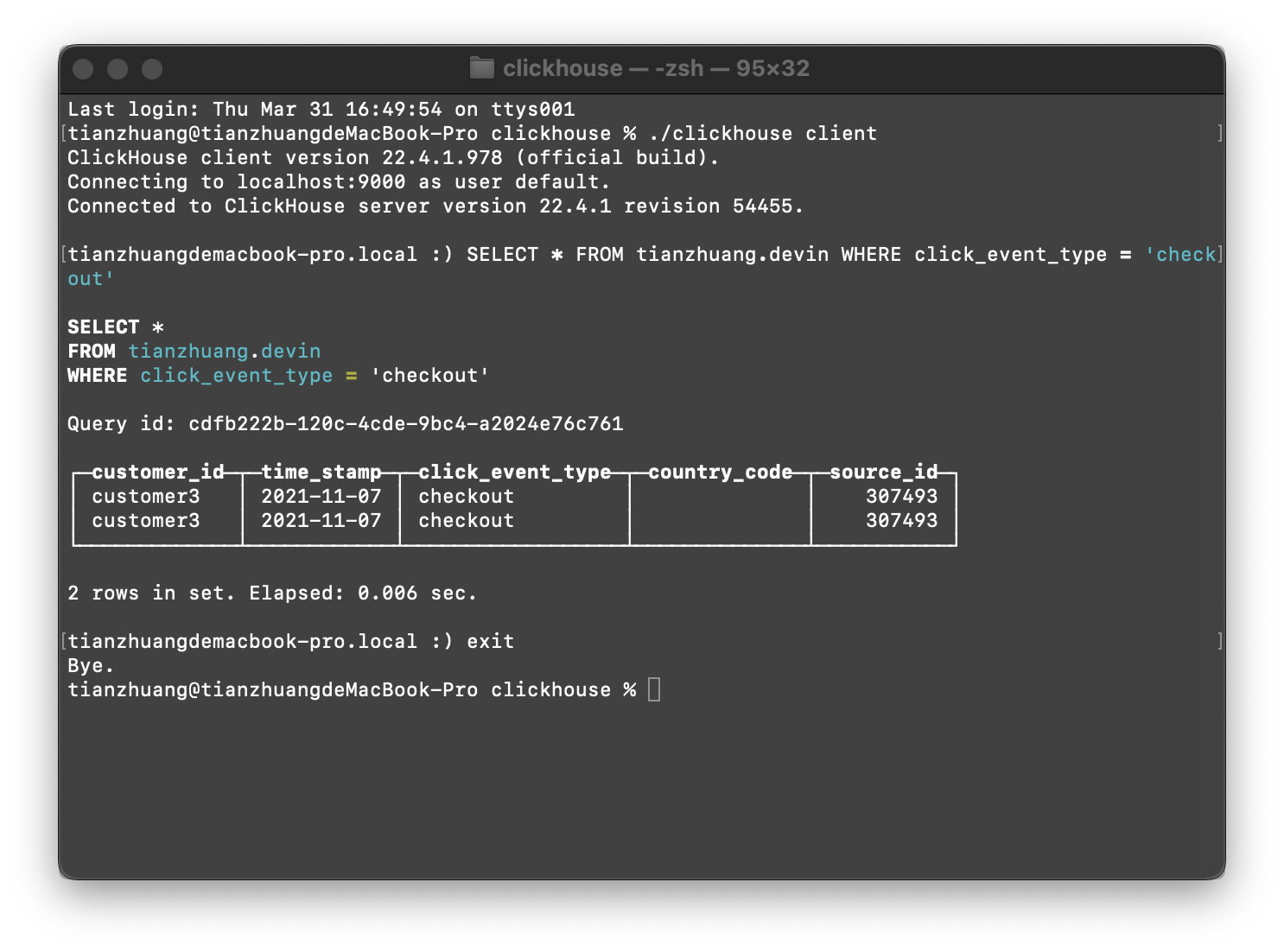
VALUES ('customer3', '2021-11-07', 'checkout', 307493 )
- 查看表中存储的数据
SELECT * FROM [数据库.表名]
SELECT * FROM [数据库.表名] WHERE [列名]=
SELECT * FROM [数据库.表名] WHERE [列名]>=
SELECT [列名] FROM [数据库.表名] WHERE [列名]>=
3.3 Select
3.3.01 查询所有列
SELECT * FROM ...
3.3.02 COLUMNS()
以下查询所有列名包含 字段
SELECT COLUMNS('[字段]') FROM [数据库.表名]SELECT COLUMNS('[字段]'), COLUMNS('c'), toTypeName(COLUMNS('c')) FROM col_names
toTypeName()可以返回该数据的类型
3.3.03 ALL 子句
SELECT ALL和SELECT不带DISTINCT是一样的
3.3.04 ARRAY JOIN
对于包含数组列的表来说是一种常见的操作,用于生成一个新表,该表具有包含该初始列中的每个单独数组元素的列,而其他列的值将被重复显示。
CREATE TABLE arrays_test
(
s String,
arr Array(UInt8)
) ENGINE = Memory;
INSERT INTO arrays_test
VALUES ('Hello', [1,2]), ('World', [3,4,5]), ('Goodbye', []);
#表的结构 第二列是array
┌─s───────────┬─arr─────┐
│ Hello │ [1,2] │
│ World │ [3,4,5] │
│ Goodbye │ [] │
└─────────────┴─────────┘
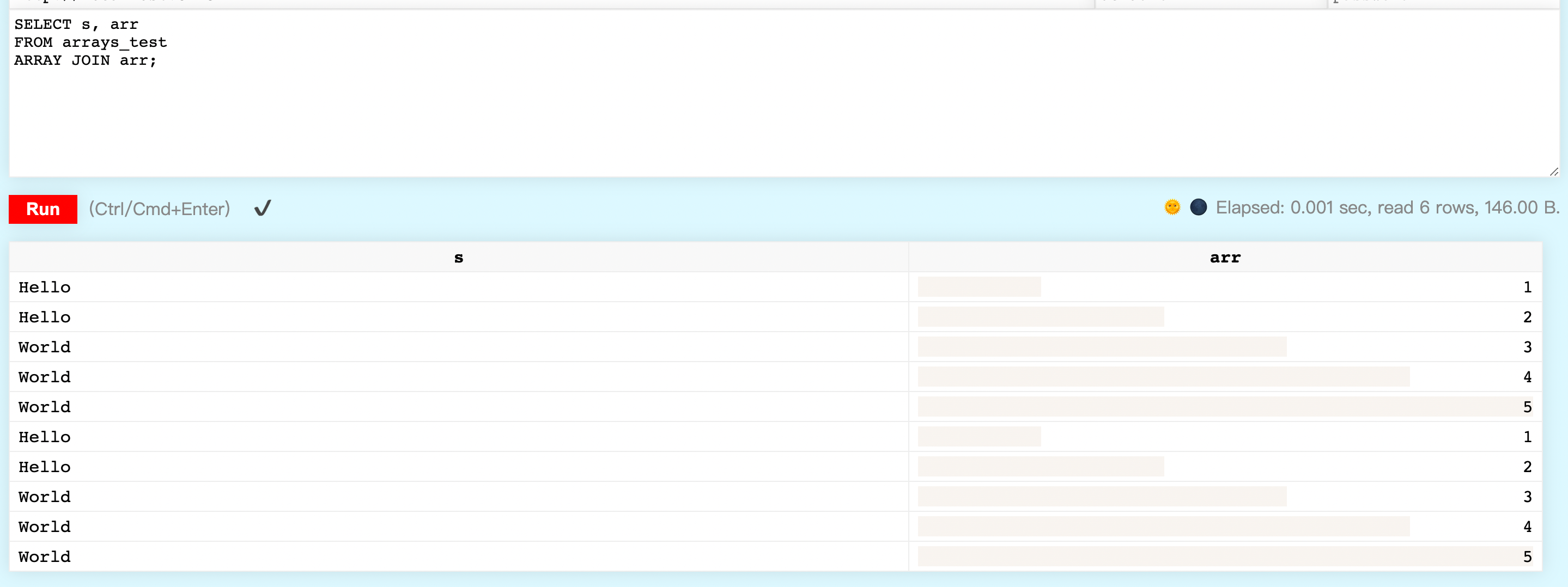
#使用ARRAY JOIN 将arr展开
SELECT s, arr
FROM arrays_test
ARRAY JOIN arr;
#使用ARRAY JOIN 将arr展开
┌─s─────┬─arr─┐
│ Hello │ 1 │
│ Hello │ 2 │
│ World │ 3 │
│ World │ 4 │
│ World │ 5 │
└───────┴─────┘
# 使用LEFT ARRAY JOIN
SELECT s, arr
FROM arrays_test
LEFT ARRAY JOIN arr;
┌─s───────────┬─arr─┐
│ Hello │ 1 │
│ Hello │ 2 │
│ World │ 3 │
│ World │ 4 │
│ World │ 5 │
│ Goodbye │ 0 │
└─────────────┴─────┘
ARRAY JOIN 支持的类型有:
ARRAY JOIN- 一般情况下,空数组不包括在结果中JOINLEFT ARRAY JOIN- 的结果JOIN包含具有空数组的行。 空数组的值设置为数组元素类型的默认值(通常为0、空字符串或NULL)
3.3.05 AS
- 关键字用指定别
SELECT s, arr, a
FROM arrays_test
ARRAY JOIN arr AS a;
# 结果
┌─s─────┬─arr─────┬─a─┐
│ Hello │ [1,2] │ 1 │
│ Hello │ [1,2] │ 2 │
│ World │ [3,4,5] │ 3 │
│ World │ [3,4,5] │ 4 │
│ World │ [3,4,5] │ 5 │
└───────┴─────────┴───┘
- 可以使用别名与外部数组执行
ARRAY JOIN
SELECT s, arr_external
FROM arrays_test
ARRAY JOIN [1, 2, 3] AS arr_external;
┌─s───────────┬─arr_external─┐
│ Hello │ 1 │
│ Hello │ 2 │
│ Hello │ 3 │
│ World │ 1 │
│ World │ 2 │
│ World │ 3 │
│ Goodbye │ 1 │
│ Goodbye │ 2 │
│ Goodbye │ 3 │
└─────────────┴──────────────┘
3.3.06 SELECT DISTINCT
-
去重**,查询结果中只保留唯一行
-
可结合
ORDER BY添加限制
原始表t1
┌─a─┬─b─┐
│ 2 │ 1 │
│ 1 │ 2 │
│ 3 │ 3 │
│ 2 │ 4 │
└───┴───┘
SELECT DISTINCT a FROM t1 ORDER BY b ASC
┌─a─┐
│ 2 │
│ 1 │
│ 3 │
└───┘
SELECT DISTINCT a FROM t1 ORDER BY b DESC
┌─a─┐
│ 3 │
│ 1 │
│ 2 │
└───┘
3.3.07 GROUP BY
-
分组操作
-
在clickhouse中
NULL也是一个值┌─x─┬────y─┐ │ 1 │ 2 │ │ 2 │ ᴺᵁᴸᴸ │ │ 3 │ 2 │ │ 3 │ 3 │ │ 3 │ ᴺᵁᴸᴸ │ └───┴──────┘ 查询 SELECT sum(x), y FROM t_null_big GROUP BY y ┌─sum(x)─┬────y─┐ │ 4 │ 2 │ │ 3 │ 3 │ │ 5 │ ᴺᵁᴸᴸ │ └────────┴──────┘
3.3.08 HAVING
-
过滤结果
- 与
WHERE不同的是WHERE是从数据库中查找数据的,HAVING是从查询到的结果集中去过滤数据
- 与
3.3.09 JOIN
- Join通过使用一个或多个表的公共值合并来自一个或多个表的列来生成新表
- 语法:
SELECT <expr_list>
FROM <left_table>
[GLOBAL] [INNER|LEFT|RIGHT|FULL|CROSS] [OUTER|SEMI|ANTI|ANY|ASOF] JOIN <right_table>
(ON <expr_list>)|(USING <column_list>) ...
-
支持的JOIN操作
INNER JOIN,只返回匹配的行。LEFT OUTER JOIN,除了匹配的行之外,还返回左表中的非匹配行。RIGHT OUTER JOIN,除了匹配的行之外,还返回右表中的非匹配行。FULL OUTER JOIN,除了匹配的行之外,还会返回两个表中的非匹配行。CROSS JOIN,产生整个表的笛卡尔积, “join keys” 是 不 指定。
JOIN没有指定类型暗指INNER. 关键字OUTER可省略LEFT SEMI JOIN和RIGHT SEMI JOIN,白名单 “join keys”,而不产生笛卡尔积。LEFT ANTI JOIN和RIGHT ANTI JOIN,黑名单 “join keys”,而不产生笛卡尔积。LEFT ANY JOIN,RIGHT ANY JOINandINNER ANY JOIN, partially (for opposite side ofLEFTandRIGHT) or completely (forINNERandFULL) disables the cartesian product for standardJOINtypes.ASOF JOINandLEFT ASOF JOIN, joining sequences with a non-exact match.ASOF JOINusage is described below.
3.3.10 LIMIT
-
分页操作
-
LIMIT m允许选择结果中起始的m行。LIMIT n, m从第n+1个开始选择m行。 -
语法
SELECT * FROM 表名 ORDER BY n LIMIT 0,5LIMIT n BY [字段A]取[字段A]的前n个值
SELECT * FROM limit_by ┌─id─┬─val─┐ │ 1 │ 10 │ │ 1 │ 11 │ │ 1 │ 12 │ │ 2 │ 20 │ │ 2 │ 21 │ └────┴─────┘ #查询 SELECT * FROM limit_by ORDER BY id ASC, val ASC LIMIT 2 BY id ┌─id─┬─val─┐ │ 1 │ 10 │ │ 1 │ 11 │ │ 2 │ 20 │ │ 2 │ 21 │ └────┴─────┘
3.3.11 OFFSET FETCH
OFFSET N表示跳过N行取出数据
SELECT * FROM test_fetch ORDER BY a LIMIT 3 OFFSET 1;
3.3.12 ORDER BY
-
ORDER BY排序DESC(降序)ASC(升序),未指定时默认升序
-
有两种方法
NaN和NULL排序顺序:- 默认情况下或与
NULLS LAST修饰符:首先是值,然后NaN,然后NULL. - 与
NULLS FIRST修饰符:第一NULL,然后NaN,然后其他值
┌─x─┬────y─┐ │ 1 │ ᴺᵁᴸᴸ │ │ 2 │ 2 │ │ 1 │ nan │ │ 2 │ 2 │ │ 3 │ 4 │ │ 5 │ 6 │ │ 6 │ nan │ │ 7 │ ᴺᵁᴸᴸ │ │ 6 │ 7 │ │ 8 │ 9 │ └───┴──────┘ 查询 SELECT * FROM t_null_nan ORDER BY y NULLS FIRST ┌─x─┬────y─┐ │ 1 │ ᴺᵁᴸᴸ │ │ 7 │ ᴺᵁᴸᴸ │ │ 1 │ nan │ │ 6 │ nan │ │ 2 │ 2 │ │ 2 │ 2 │ │ 3 │ 4 │ │ 5 │ 6 │ │ 6 │ 7 │ │ 8 │ 9 │ └───┴──────┘ - 默认情况下或与
3.3.13 Prewhere
3.3.14 SAMPLE 采样子句
-
类似于
SELECT。- 比如:查询一万条数据时,只需要查询出100条数据,然后通过运算放大100倍比例即可
-
启用数据采样时,不会对所有数据执行查询,而只对特定部分数据(样本)执行查询。 例如,如果您需要计算所有访问的统计信息,只需对所有访问的1/10分数执行查询,然后将结果乘以10即可。
-
使用场景
- 当你有严格的时间需求(如<100ms),但你不能通过额外的硬件资源来满足他们的成本。
- 当您的原始数据不准确时,所以近似不会明显降低质量。
- 业务需求的目标是近似结果(为了成本效益,或者向高级用户推销确切结果)。
-
语法:
SAMPLE k这里k是从0到1的数字。 -
举个栗子
SELECT Title, count() * 10 AS PageViews FROM hits_distributed SAMPLE 0.1 WHERE CounterID = 34 GROUP BY Title ORDER BY PageViews DESC LIMIT 1000 # 对0.1(10%)数据的样本执行查询。 聚合函数的值不会自动修正,因此要获得近似结果,值 count() 手动乘以10
3.3.15 UNION ALL
-
可以使用
UNION ALL结合任意数量的SELECT来扩展其结果SELECT CounterID, 1 AS table, toInt64(count()) AS c FROM test.hits GROUP BY CounterID UNION ALL SELECT CounterID, 2 AS table, sum(Sign) AS c FROM test.visits GROUP BY CounterID HAVING c > 0 -
结果列通过它们的索引进行匹配(在内部的顺序
SELECT). 如果列名称不匹配,则从第一个查询中获取最终结果的名称。
3.3.16 WHERE
- 查询条件为NULL
CREATE TABLE t_null(x Int8, y Nullable(Int8)) ENGINE=MergeTree() ORDER BY x;
INSERT INTO t_null VALUES (1, NULL), (2, 3);
SELECT * FROM t_null WHERE y IS NULL;
SELECT * FROM t_null WHERE y != 0;
┌─x─┬────y─┐
│ 1 │ ᴺᵁᴸᴸ │
└───┴──────┘
┌─x─┬─y─┐
│ 2 │ 3 │
└───┴───┘
3.3.17 WITH子句
- 结果
WITH子句可以在其余部分中使用SELECT查询
WITH '2019-08-01 15:23:00' as ts_upper_bound
SELECT *
FROM hits
WHERE
EventDate = toDate(ts_upper_bound) AND
EventTime <= ts_upper_bound
3.4 ALTER
-
ALTER仅支持MergeTree,Merge以及Distributed等引擎表。- 语法:
ALTER TABLE [db].name [ON CLUSTER cluster] ADD|DROP|CLEAR|COMMENT|MODIFY COLUMN ... - 配置一个或多个表时,用逗号分隔
- 语法:
-
支持的子语句:
ADD COLUMN— 添加列DROP COLUMN— 删除列CLEAR COLUMN— 重置列的值COMMENT COLUMN— 给列增加注释说明MODIFY COLUMN— 改变列的值类型,默认表达式以及TTL
-
增加列
ADD COLUMN [IF NOT EXISTS] name [type] [default_expr] [codec] [AFTER name_after] -
删除列
DROP COLUMN [IF EXISTS] name -
清空列
CLEAR COLUMN [IF EXISTS] name IN PARTITION partition_name -
增加注释
COMMENT COLUMN [IF EXISTS] name 'comment' -
修改列
MODIFY COLUMN [IF EXISTS] name [type] [default_expr] [TTL] 示例 ALTER TABLE visits MODIFY COLUMN browser Array(String)- 改变列的类型是唯一的复杂型动作 - 它改变了数据文件的内容。对于大型表,执行起来要花费较长的时间。
该操作分为如下处理步骤:- 为修改的数据准备新的临时文件
- 重命名原来的文件
- 将新的临时文件改名为原来的数据文件名
- 删除原来的文件
- 改变列的类型是唯一的复杂型动作 - 它改变了数据文件的内容。对于大型表,执行起来要花费较长的时间。
3.5 SYSTEM
-
RELOAD EMBEDDED DICTIONARIES
重新加载所有内部词典(Internal dictionaries)。
默认情况下,内部字典是禁用的。
始终返回OK, 无论内部字典更新的结果如何
-
RELOAD DICTIONARIES
重新加载之前已成功加载的所有词典。
-
KILL
中止ClickHouse进程(像是kill -9 {$ pid_clickhouse-server})
3.6 SHOW 查询
-
SHOW CREATE TABLESHOW CREATE [TEMPORARY] [TABLE|DICTIONARY] [db.]table [INTO OUTFILE filename] [FORMAT format]返回单个字符串类型的 ‘statement’列,其中只包含了一个值 - 用来创建指定对象的
CREATE语句。如果使用该查询去获取系统表的
CREATE语句,你得到的是一个虚构的语句,仅用来展示系统的表结构,而不能实际创建表。 -
SHOW DATABASESSHOW DATABASES [INTO OUTFILE filename] [FORMAT format]打印所有的数据库列表
-
SHOW PROCESSLISTSHOW PROCESSLIST [INTO OUTFILE filename] [FORMAT format] 输出 system.processes表的内容,包含有当前正在处理的请求列表,除了 SHOW PROCESSLIST查询 -
SHOW TABLESSHOW [TEMPORARY] TABLES [{FROM | IN} <db>] [LIKE '<pattern>' | WHERE expr] [LIMIT <N>] [INTO OUTFILE <filename>] [FORMAT <format>] #举个栗子 下列查询获取最前面的2个位于system库中且表名包含 co的表。 SHOW TABLES FROM system LIKE '%co%' LIMIT 2 ┌─name───────────────────────────┐ │ aggregate_function_combinators │ │ collations │ └────────────────────────────────┘ -
SHOW DICTIONARIES以列的形式展示外部字典 -
SHOW GRANTS [FOR user]显示用户权限 -
SHOW CREATE USER显示user creation用到的参数。SHOW CREATE USER [name | CURRENT_USER]
3.7 EXPLAIN
执行计划
-
EXPLAIN [ PLAN | AST | SYNTAX | PIPELINE ] [setting = value, ...] SELECT ...-
PLAN用于查看执行计划; -
AST用于查看语法树; -
SYNTAX用于优化语法; -
PIPELINE用于查看 PIPELINE 计划。 -
PLAN&PIPELINE还可以进行额外的显示设置
-
四、客户端
操作
-
进入客户端
./clickhouse client -
退出客户端
exit -
通过命令执行SQL文件
cat [sql文件] | ./clickhouse client -mn
五、数据类型
-
String类型替换来自其他数据库的 VARCHAR、BLOB、CLOB 和其他类似字符串的数据类型
-
UInt64是一个 64 位无符号整数
-
日期是在 ClickHouse 中存储日期的几种方法之一
-
如果知道列中所有字符串的精确长度,则使用**FixedString( n )**数据类型
-
整型:
Int8— [-128 : 127] 占用8个字节,对应java中的byteInt16— [-32768 : 32767] 占用16个字节,对应java中的shortInt32— [-2147483648 : 2147483647] 占用32个字节,对应java中的intInt64— [-9223372036854775808 : 9223372036854775807] 对应64个字节,对应java中的long
-
无符号整型范围
UInt8— [0 : 255]UInt16— [0 : 65535]UInt32— [0 : 4294967295]UInt64— [0 : 18446744073709551615]
-
Decimal
-
有符号的浮点数,可以在加减鞥发运算中保持精度,对于除法,最低有效数字将被抛弃(不进行四舍五入)。
-
通常有三种声明:
- Decimal32(s)
- Decimal64(s)
- Decimal128(s)
后面的s表示小数点后的数字位数,前面的32,64,128表示浮点精度
-
-
Enum 枚举类型,包含两种类型
-
enum8
-
Enum16
enum保存在’string’=integer的对应关系中
CREATE TABLE t_enum ( x Enum('hello' = 1, 'world' = 2) ) ENGINE = TinyLog 插入数据 INSERT INTO t_enum VALUES ('hello'), ('world'), ('hello') 正常查询 SELECT * FROM t_enum ┌─x─────┐ │ hello │ │ world │ │ hello │ └───────┘ 查询对应的numeric值 SELECT CAST(x, 'Int8') FROM t_enum ┌─CAST(x, 'Int8')─┐ │ 1 │ │ 2 │ │ 1 │ └─────────────────┘ SELECT toTypeName(CAST('a', 'Enum(\'a\' = 1, \'b\' = 2)')) ┌─toTypeName(CAST('a', 'Enum(\'a\' = 1, \'b\' = 2)'))─┐ │ Enum8('a' = 1, 'b' = 2) │ └─────────────────────────────────────────────────────┘ -
-
Date 年-月-日
-
Date32
-
DateTime 年-月-日 时:分:秒
-
DateTime64 年-月-日 时:分:秒.毫秒
-
Nullable 在绝大多少的基础类型前面加上
nullable来表示该字段可以为空-
CREATE TABLE nullable (`n` Nullable(UInt32)) ENGINE = MergeTree ORDER BY tuple(); INSERT INTO nullable VALUES (1) (NULL) (2) (NULL); SELECT n.null FROM nullable; 结果 ┌─n.null─┐ │ 0 │ │ 1 │ │ 0 │ │ 1 │ └────────┘ CREATE TABLE t_null(x Int8, y Nullable(Int8)) ENGINE TinyLog INSERT INTO t_null VALUES (1, NULL), (2, 3) SELECT x + y FROM t_null ┌─plus(x, y)─┐ │ ᴺᵁᴸᴸ │ │ 5 │ └────────────┘
-
-
uuid
通用唯一标识符 (UUID) 是一个 16 字节的数字,用于标识记录
-
uuid的类型值示例
61f0c404-5cb3-11e7-907b-a6006ad3dba0 在插入时如果不指定uuid则全部填充为0 00000000-0000-0000-0000-000000000000 -
生成uuid
CREATE TABLE t_uuid (x UUID, y String) ENGINE=TinyLog 插入uuid INSERT INTO t_uuid SELECT generateUUIDv4(), 'Example 1' SELECT * FROM t_uuid ┌────────────────────────────────────x─┬─y─────────┐ │ 417ddc5d-e556-4d27-95dd-a34d84e46a50 │ Example 1 │ └──────────────────────────────────────┴───────────┘ 不指定uuid的值 INSERT INTO t_uuid (y) VALUES ('Example 2') SELECT * FROM t_uuid ┌────────────────────────────────────x─┬─y─────────┐ │ 417ddc5d-e556-4d27-95dd-a34d84e46a50 │ Example 1 │ │ 00000000-0000-0000-0000-000000000000 │ Example 2 │ └──────────────────────────────────────┴───────────┘
-
六、函数
-
SUM() 求和
┌─x─┬────y─┐ │ 1 │ 2 │ │ 2 │ ᴺᵁᴸᴸ │ │ 3 │ 2 │ │ 3 │ 3 │ │ 3 │ ᴺᵁᴸᴸ │ └───┴──────┘ 汇总y列的值 SELECT sum(y) FROM t_null_big ┌─sum(y)─┐ │ 7 │ └────────┘ -
groupArray(y) 创建某列的数组
SELECT groupArray(y) FROM t_null_big ┌─groupArray(y)─┐ │ [2,2,3] │ └───────────────┘ -
count()
- 没有传入参数时会计算行数
- 当传入表达式时,会计算该表达式返回非null的次数
-
min()计算最小值
-
max()计算最大值
-
sum()求和(仅用于数字类型)
-
avg()计算算数平均值
- 输入的类型必须是:
x— 输入值,必须是Integer、Float、或Decimal - 返回值:算术平均值,始终为FLOAT64;传入参数为空则为
NaN
- 输入的类型必须是:
-
toDate 函数将纪元时间戳转换为Date对象
例如
SELECT * FROM [数据库.表名] WHERE time_stamp >= toDate(1633193802)
七、远程连接
-
命令
clickhouse-client -h [ip]
八、数据库引擎
-
ATOMIC默认引擎 -
mysql引擎,可以将mysql中的数据表直接复制过来。CREATE DATABASE [IF NOT EXISTS] db_name [ON CLUSTER cluster] ENGINE = MySQL('host:port', ['database' | database], 'user', 'password')
九、表引擎
9.1 🌳 merge tree
9.1.1 merge tree 语法
该引擎用于将大量数据插入表中。数据快速逐部分写入表格,然后在后台应用规则合并部分。这种方法比在插入过程中不断地重写存储中的数据要高效得多。
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1] [TTL expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2] [TTL expr2],
...
INDEX index_name1 expr1 TYPE type1(...) GRANULARITY value1,
INDEX index_name2 expr2 TYPE type2(...) GRANULARITY value2,
...
PROJECTION projection_name_1 (SELECT <COLUMN LIST EXPR> [GROUP BY] [ORDER BY]),
PROJECTION projection_name_2 (SELECT <COLUMN LIST EXPR> [GROUP BY] [ORDER BY])
) ENGINE = MergeTree()
ORDER BY expr
[PARTITION BY expr]
[PRIMARY KEY expr]
[SAMPLE BY expr]
[TTL expr
[DELETE|TO DISK 'xxx'|TO VOLUME 'xxx' [, ...] ]
[WHERE conditions]
[GROUP BY key_expr [SET v1 = aggr_func(v1) [, v2 = aggr_func(v2) ...]] ] ]
[SETTINGS name=value, ...]
-
PARTITION BY分区 选填,表示分区键,用于指定表数据以何种标准进行分区。常见的莫过于按照时间分区了,数据量非常大的时候可以按照天来分区,一天一个分区,这样查找某一天的数据时直接从指定分区中查找即可 -
ORDER BY必填,表示排序键,用于指定在一个分区内,数据以何种标准进行排序。排序键既可以是单个字段,例如ORDER BY CounterID,也可以是通过元组声明的多个字段,例如ORDER BY (CounterID, EventDate)。如果是多个字段,那么会先按照第一个字段排序,如果第一个字段中有相同的值,那么再按照第二个字段排序,依次类推。总之在每个分区内,数据是按照分区键排好序的,但多个分区之间就没有这种关系了。 -
PRIMARY KEY选填,表示主键,声明之后会依次按照主键字段生成一级索引,用于加速表查询。如果不指定,那么主键默认和排序键相同,所以通常直接使用 ORDER BY 代为指定主键,无须使用 PRIMARY KEY 声明。MergeTree 允许主键有重复数据 -
SAMPLE KEY选填,抽样表达式。用于声明数据以何种标准进行采样,注意:如果声明了此配置项,那么主键的配置中也要声明同样的表达式。...... ) ENGINE = MergeTree() ORDER BY (CountID, EventDate, intHash32(UserID)) SAMPLE BY intHash32(UserID) -- 抽样表达式需要配合 SAMPLE 子查询使用,该功能对选取抽样数据十分有用 -- 关于抽样查询,后面会在介绍查询的时候说
9.1.2 merge tree 数据表的存储结构

















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









