








 超级会员免费看
超级会员免费看

书接上回,到了可视化的部分,先回顾一下原数据表结构,数据标签包括:公交线路名称、始发站、终点站、行车区间、全程长度、途径站点名、途径站点坐标、途径站点第几站这几个标签,然而做可视化并不需要这么多标签,我选取了line_name、station_name、station_coords和station_sequence,这4个标签;
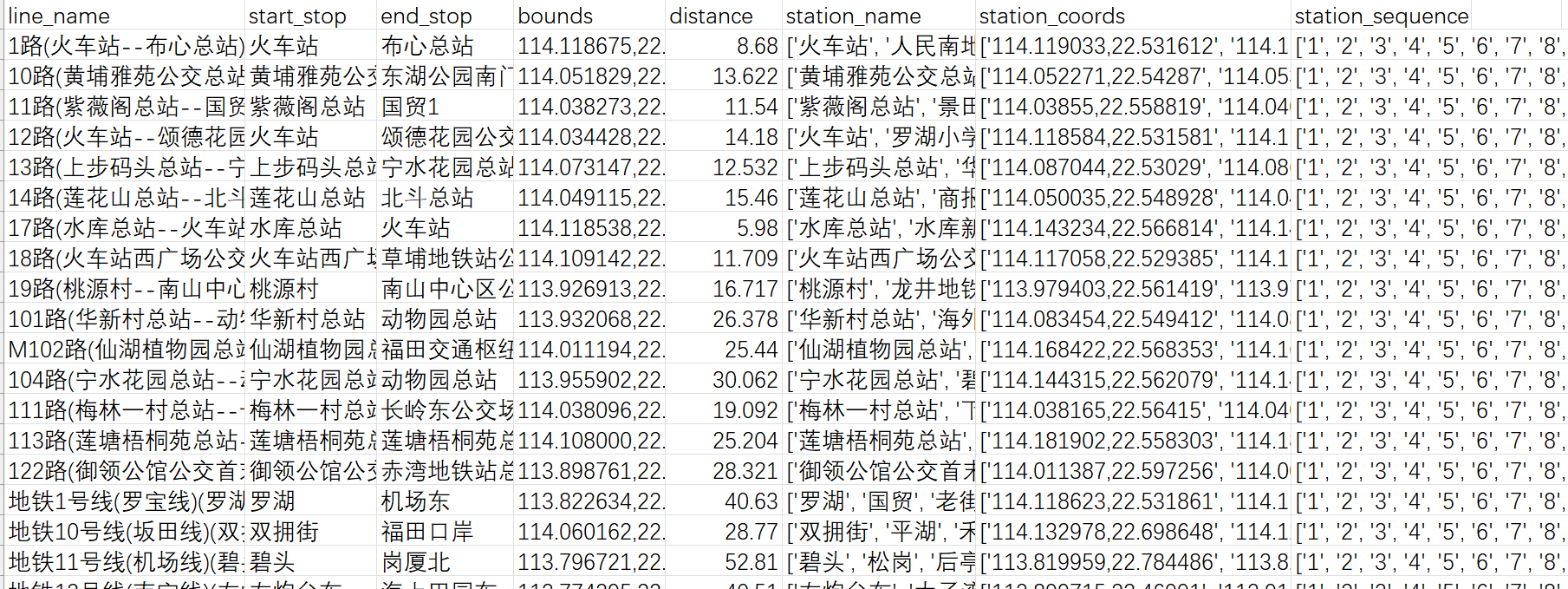
接下来就是从这个csv里面提取这个四个标签,并按一定规则排列,比如说这样;
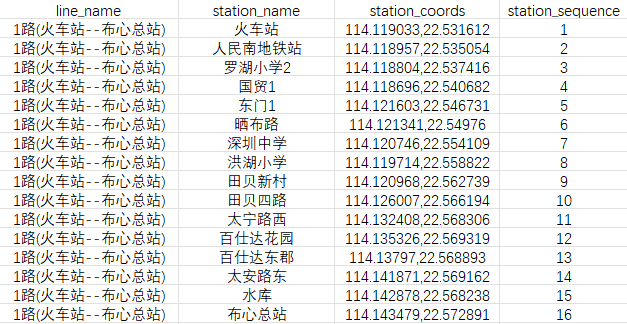
遂写了个小脚本,完整代码如下。PS:读取路径改成自己的,不想加前缀就把文件放在.py下,输出路径也可以改成自己的,不改的话也可以,whatever~
完整代码#运行环境 Python 3.11
import pandas as pd
from ast import literal_eval

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 2256
2256

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











