







 本文介绍了一种爬取城市公交线路的方法,包括线路名称、起止点及经纬度坐标,并展示了如何利用Python进行数据抓取与坐标转换,最后讨论了数据可视化的多种方式。
本文介绍了一种爬取城市公交线路的方法,包括线路名称、起止点及经纬度坐标,并展示了如何利用Python进行数据抓取与坐标转换,最后讨论了数据可视化的多种方式。
前言
查询所在城市所有的公交线路,填入linename数组中(本文只以深圳市68线路为例演示
深圳公交线路查询:深圳公交查询_深圳公交车线路查询_深圳公交地图 - 深圳公交网 (其他城市把拼音处修改即可
城市线路汇总
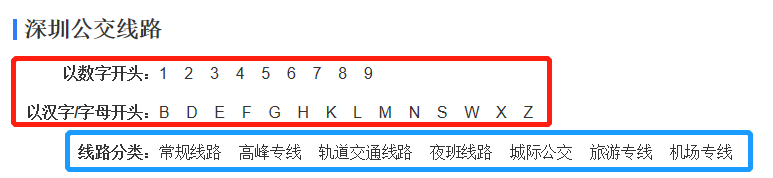
以数字开头 + 以汉字/字母开头 = 线路分类,要获取城市所有线路,只需要选择爬取其中一个即可。文末附件可爬取某城市的所有线路
由于高德的数据是用的gcj02坐标系,文中的transfer.py文件是为了将点坐标的坐标系改为更通用的wgs84坐标系,没有这个需求也可以不转换。

代码
2020年7月更新:发现接口已经失效了,我就不修改了,给大家找了一个其他博主的[点击此处跳转],亲测可行
'''
date: 2019.4
detail : 获取某城市某路公交车的线路图
warning:接口已失效
'''
# _*_ coding:utf-8 _*_
import requests
import json
import time
import sys
sys.path.append('D:/坐标系转换') #导入不在同一文件夹下的py文件
import transfer # 导入transfer.py文件
def BusLines(buslist):
busname = buslist['key_name'] #线路名
buslinename = buslist['name'] #线路名+起终点
print(buslinename)
fromname = buslist['front_name'] #起点
terminalname = buslist['terminal_name'] #终点
x = buslist['xs'].split(',')
y = buslist['ys'].split(',')
busPoint = []
for i in range(len(x)):
lng,lat = transfer.gcj02_to_wgs84(float(x[i]),float(y[i])) # 转换为wgs84坐标系
linetmp = str(round(lng,6)) + "," + str(round(lat,6))
busPoint.append(linetmp)
return busPoint
if __name__ == '__main__':
linename=['68路']
for i in range(len(linename)):
city = "440300" #深圳
zoom = "11"
busNum = linename[i]
url="https://www.amap.com/service/poiInfo?query_type=TQUERY&pagesize=20&pagenum=1&qii=true&cluster_state=5&need_utd=true&utd_sceneid=1000&div=PC1000&addr_poi_merge=true&is_classify=true&zoom="+ zoom +"&city="+city+"&geoobj=114.235102%7C22.569015%7C114.276323%7C22.603105&keywords="+busNum
response = requests.get(url)
data = json.loads(response.text)
if data['data']['message']=="Successful." and data['data']['busline_list']:
buslists = data['data']['busline_list']
buslist = buslists[0]
buslines = BusLines(buslist)
files = open('./公交线路' + busNum + '.txt','w')
for i in range(len(buslines)):
files.writelines(buslines[i]+'\n')
files.close()结果
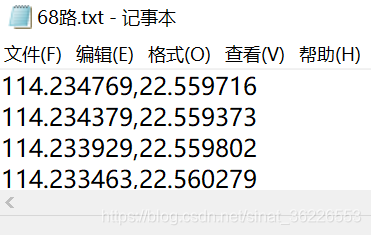
单条路线可视化
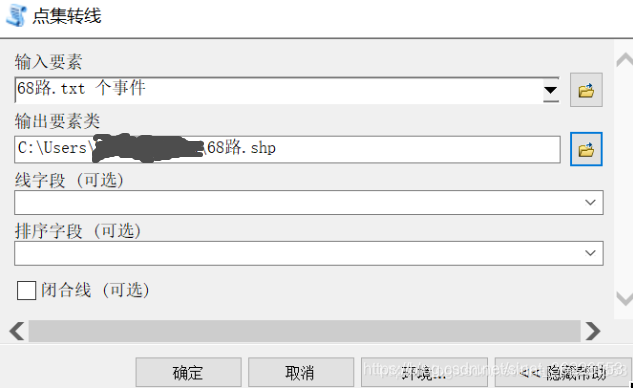
1.打开ArcGIS,选择菜单栏【文件】-【添加数据】-【添加XY数据】

2.工具箱【数据管理工具】-【要素】-【点集转线】
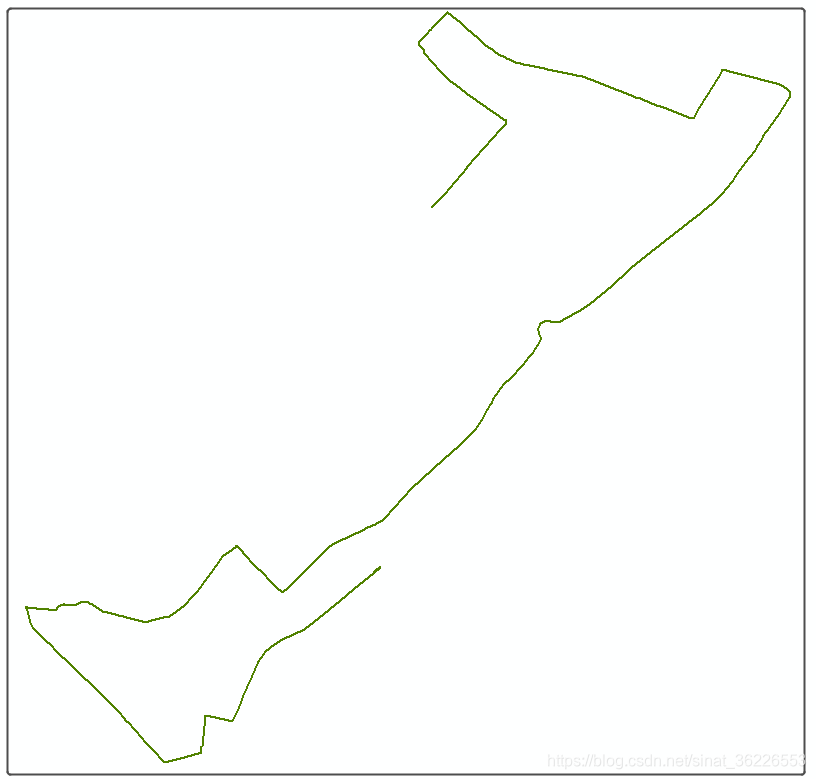
3.最终结果
4.在全国公交线路城市列表查询结果是否可靠
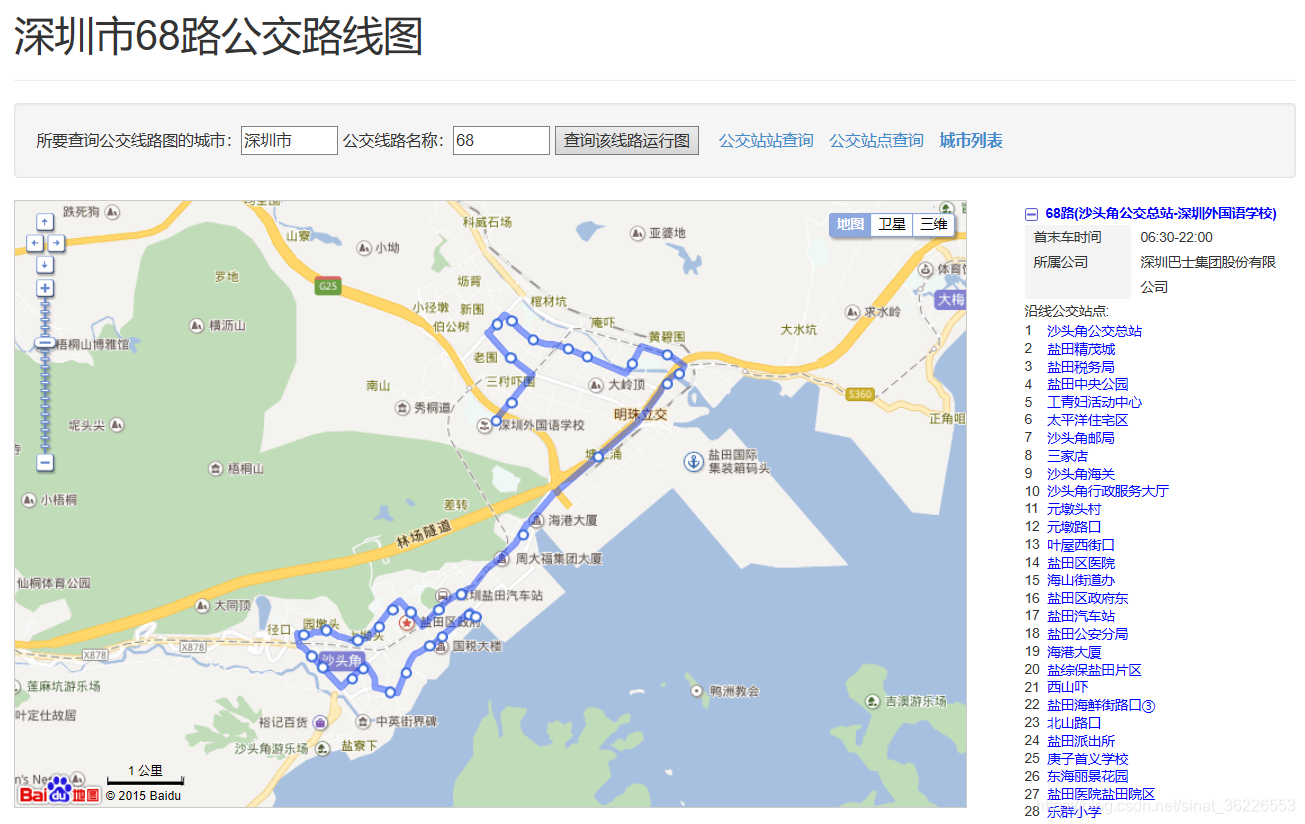
多条路线可视化
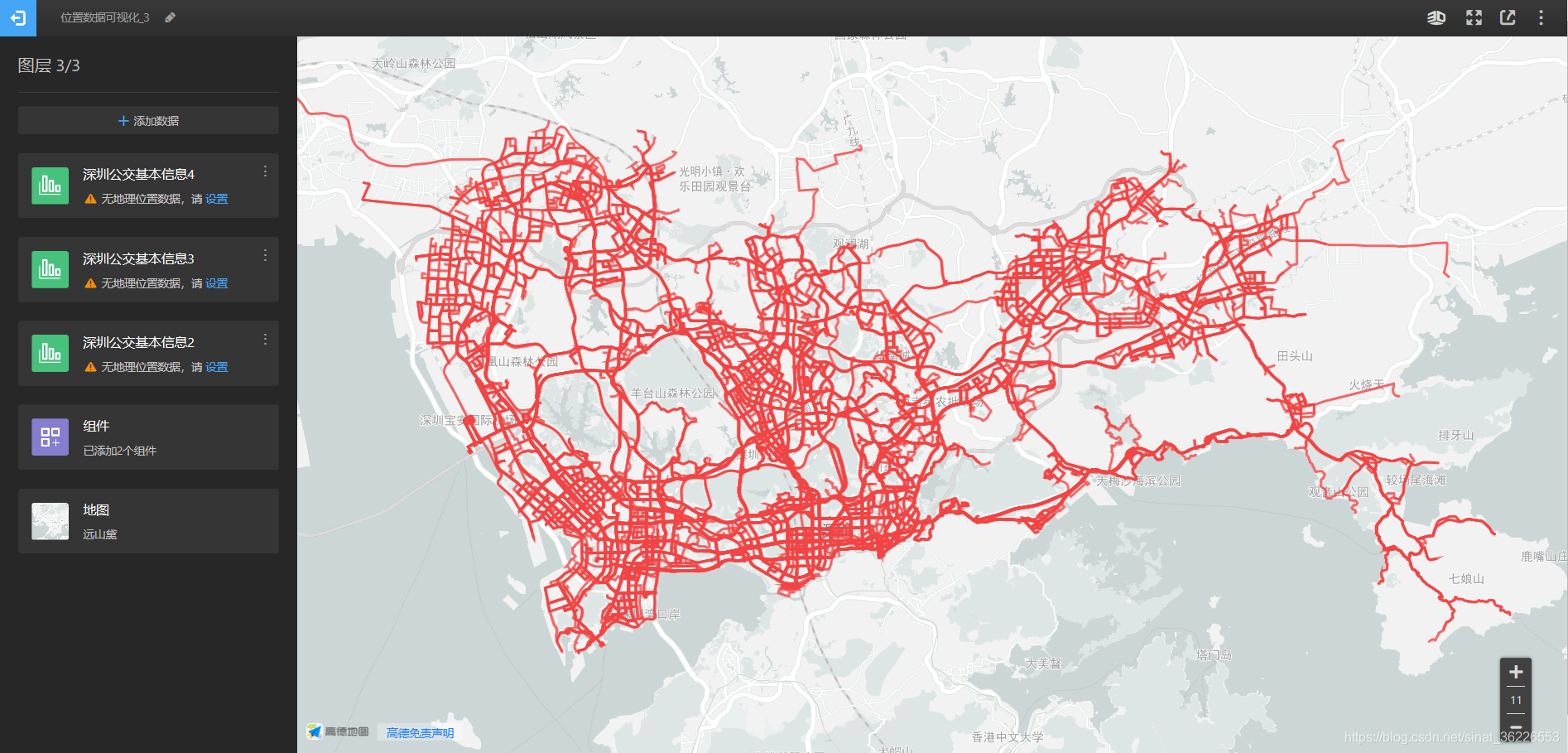
2020年7月更新:尝试了上面博主的代码结合自己抓取的公交线路,确实可行,抓取的数据如图

下载资源:北上广深公交路线文本数据(.csv)
之前只用了一条线做可视化,所以一下就通过ArcGIS做出图来。但想了半天这种格式的多条线数据得用什么可视化/GIS软件来做,结果发现高德就提供了这样的工具:高德开放平台 | Map Lab(唯一的缺点是单个文件不能超过5M,我抓取的深圳公交数据有10M左右,只能拆成几部分加载了,最多3个图层,那文件就不能超过15M了。
如果要用ArcGIS的话,参照这个方法[链接]。但数据处理有点麻烦,或者在爬取的时候就按geojson格式输出,这样很多平台都可以可视化 [ csv/excel 数据转为Geojson 格式数据 ]。
2020年8月更新:高德开放平台使用起来还是有点局限,比如北京公交路线数据大于15M,那用这个方法就不能全部展示。可以选择修改输出格式,按WKT格式进行组织,如多点构成的线数据 LINESTRING(0 0, 10 10, 20 25, 50 60),然后通过QGIS就能生成矢量数据(下图用于举例说明。
//for i in range(len(b)):
// tmp=re.split("[,]",b[i])
// if len(res)==0:
// res=res+"["+tmp[0]+","+tmp[1]+"]"
// else:
// res=res+",["+tmp[0]+","+tmp[1]+"]"
for i in range(len(b)):
tmp=re.split("[,]",b[i])
if len(res)==0:
res=res+"linestring("+tmp[0]+" "+tmp[1]
else:
res=res+","+tmp[0]+" "+tmp[1]
res = res + ")"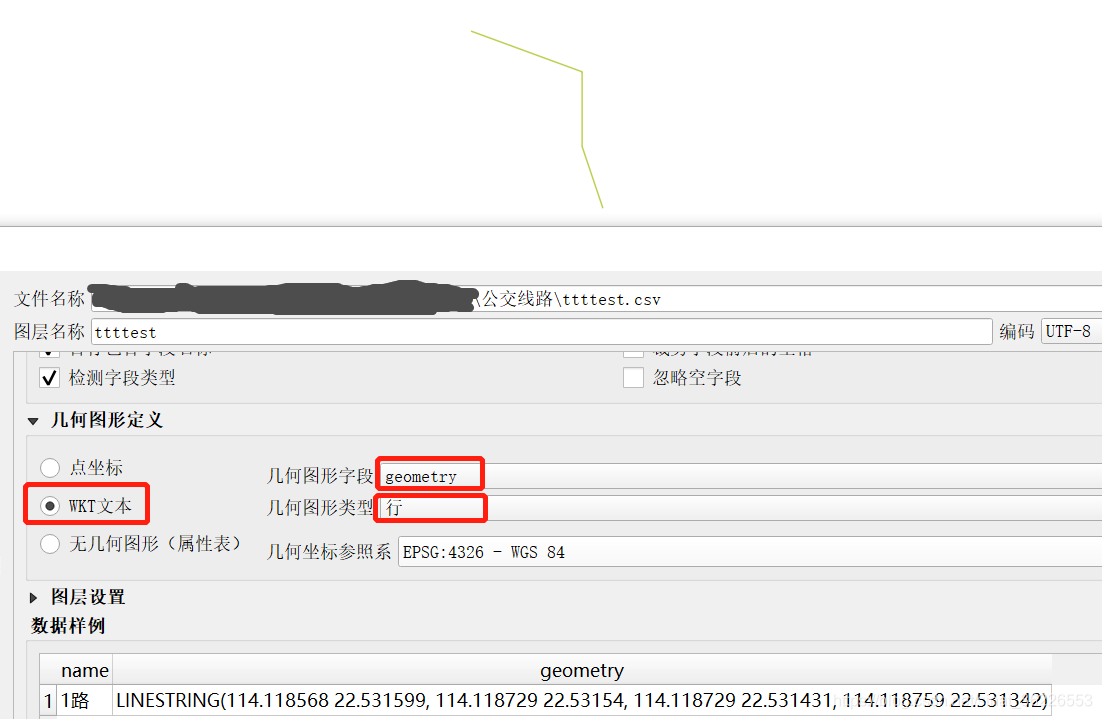
附件
2020年7月更新:该代码是从8684网站上抓取某城市所有公交线路。之后如果网站的结构变了,就需要修改代码了,但一般不会大改。抓取的是以数字开头 + 以汉字/字母开头的公交线路
'''
date: 2020.7
detail: 抓取某城市所以公交线路,如1路、10路...
'''
# -*- coding: utf-8 -*-
import requests ##导入requests
from bs4 import BeautifulSoup ##导入bs4中的BeautifulSoup
import os
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36 SE 2.X MetaSr 1.0'}
all_url = 'http://shenzhen.8684.cn' ##开始的URL地址【填写】
start_html = requests.get(all_url, headers=headers)
Soup = BeautifulSoup(start_html.text, 'lxml')
all_list = Soup.find_all('div',class_='list')
all_Num = all_list[0].find_all('a') # 数字开头
all_Word = all_list[1].find_all('a') # 字母/拼音开头
Network_list = []
# 数字开头公交
for a in all_Num:
href = a['href'] #取出a标签的href 属性
html = all_url + href
second_html = requests.get(html,headers=headers)
Soup2 = BeautifulSoup(second_html.text, 'lxml')
all_cc = Soup2.find('div',class_='cc-content').find_all('div')[-1]
all_xNum = all_cc.find_all('a')
for a2 in all_xNum:
title = a2.get_text() #取出a1标签的文本
Network_list.append(title)
# 字母开头公交
for b in all_Word:
href = b['href'] #取出a标签的href 属性
html = all_url + href
second_html = requests.get(html,headers=headers)
Soup3 = BeautifulSoup(second_html.text, 'lxml')
all_cc2 = Soup3.find('div',class_='cc-content').find_all('div')[-1]
all_xWord = all_cc2.find_all('a')
for b2 in all_xWord:
title = b2.get_text() #取出a1标签的文本
Network_list.append(title)
# 定义保存函数,将运算结果保存为txt文件
def text_save(content,filename,mode='a'):
file = open(filename,mode,encoding='utf-8')
for i in range(len(content)):
file.write(str(content[i])+',')
print("\r已输出{}公交车".format(content[i]),end='')
file.close()
# 输出处理后的数据
text_save(Network_list,'深圳公交线路.txt'); #【填写】
下载资源:北上广深公交线路文本数据(.txt)

















 2274
2274

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









