







 本文通过可视化ResNet模型的浅层和深层特征,理解模型对猫狗图像分类过程。深入学习了类激活热图,展示了如何结合图像和热力图揭示模型关键判断区域。
本文通过可视化ResNet模型的浅层和深层特征,理解模型对猫狗图像分类过程。深入学习了类激活热图,展示了如何结合图像和热力图揭示模型关键判断区域。
文章目录
准备
- 本次使用的数据集依旧是猫和狗,并且用到了上次训练好的模型,详见:https://blog.csdn.net/weixin_45826022/article/details/118662581
- 本次代码在notebook上实现。
可视化中间特征层
为了了解模型是如何进行分类的,我们可以对模型中的卷积层进行可视化,以查看该卷积层提取到了哪些特征。
导入所需的库
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
from torch.nn import functional as F
from torchvision import transforms
import numpy as np
from PIL import Image
from collections import OrderedDict
import cv2
加载训练好模型
model = torch.load('./save/model.pkl').to(torch.device('cpu'))
print(model)
可以看到模型与上次我们设置的一模一样,已经加载成功
ResNet(
(conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(layer1): Sequential(
(0): Bottleneck(
(conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(layer2): Sequential(
(0): Bottleneck(
(conv1): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(3): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(layer3): Sequential(
(0): Bottleneck(
(conv1): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(512, 1024, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(3): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(4): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(5): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(layer4): Sequential(
(0): Bottleneck(
(conv1): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(1024, 2048, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(avgpool): AdaptiveAvgPool2d(output_size=(1, 1))
(fc): Linear(in_features=2048, out_features=2, bias=True)
(softmax): Softmax(dim=-1)
)
加载一张图片
# 从测试集中读取一张图片,并显示出来
img_path = './test/test/607.jpg'
img = Image.open(img_path)
imgarray = np.array(img) / 255.0
plt.figure(figsize=(8,8))
plt.imshow(imgarray)
plt.axis('off')
plt.show()
图片加载成功

- 我们需要将图片处理成模型可以预测的形式
# 将图片处理成模型可以预测的形式
transform = transforms.Compose([
transforms.Resize([224,224]),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
input_img = transform(img).unsqueeze(0)
print(input_img.shape)
torch.Size([1, 3, 224, 224])
定义钩子函数
# 定义钩子函数,获取指定层名称的特征
activation = {} # 保存获取的输出
def get_activation(name):
def hook(model, input, output):
activation[name] = output.detach()
return hook
可视化浅层特征
model.eval()
# 获取layer1里面的bn3层的结果,浅层特征
model.layer1[1].register_forward_hook(get_activation('bn3')) # 为layer1中第2个模块的bn3注册钩子
_ = model(input_img)
bn3 = activation['bn3'] # 结果将保存在activation字典中
print(bn3.shape)
torch.Size([1, 256, 56, 56])
- 可视化结果
# 可视化结果,显示前64张
plt.figure(figsize=(12,12))
for i in range(64):
plt.subplot(8,8,i+1)
plt.imshow(bn3[0,i,:,:], cmap='gray')
plt.axis('off')
plt.show()
可以看出有很多图片都可以分辨出原始图片包含的内容,这说明浅层网络能够提取图像较大粒度的特征

可视化深层特征
# 获取深层的特征映射
model.eval()
# 获取layer4中第3个模块的bn3层输出结果
model.layer4[2].register_forward_hook(get_activation('bn3'))
_ = model(input_img)
bn3 = activation['bn3']
# 绘制前64个特征
plt.figure(figsize=(12,12))
for i in range(64):
plt.subplot(8,8,i+1)
plt.imshow(bn3[0,i,:,:], cmap='gray')
plt.axis('off')
plt.show()
可以发现深层的映射已经不能分辨图像的具体内容,说明更深层的特征映射能从图像中提取更细粒度的特征

可视化图像的类激活热力图
使用类激活热力图,能观察模型对图像识别的关键位置。计算图像类激活热力图需要使用卷积神经网络最后一层网络的输出和其对应的梯度,需要先定义一个新的模型
重新定义一个新的模型
class GradCAM(nn.Module):
def __init__(self):
super(GradCAM, self).__init__()
# 获取模型的特征提取层
self.feature = nn.Sequential(OrderedDict({
name:layer for name, layer in model.named_children()
if name not in ['avgpool','fc','softmax']
}))
# 获取模型最后的平均池化层
self.avgpool = model.avgpool
# 获取模型的输出层
self.classifier = nn.Sequential(OrderedDict([
('fc', model.fc),
('softmax', model.softmax)
]))
# 生成梯度占位符
self.gradients = None
# 获取梯度的钩子函数
def activations_hook(self, grad):
self.gradients = grad
def forward(self, x):
x = self.feature(x)
# 注册钩子
h = x.register_hook(self.activations_hook)
# 对卷积后的输出使用平均池化
x = self.avgpool(x)
x = x.view((1,-1))
x = self.classifier(x)
return x
# 获取梯度的方法
def get_activations_gradient(self):
return self.gradients
# 获取卷积层输出的方法
def get_activations(self, x):
return self.feature(x)
定义获取热力图函数
# 获取热力图
def get_heatmap(model, img):
model.eval()
img_pre = model(img)
# 获取预测最高的类别
pre_class = torch.argmax(img_pre, dim=-1).item()
# 获取相对于模型参数的输出梯度
img_pre[:, pre_class].backward()
# 获取模型的梯度
gradients = model.get_activations_gradient()
# 计算梯度相应通道的均值
mean_gradients = torch.mean(gradients, dim=[0,2,3])
# 获取图像在相应卷积层输出的卷积特征
activations = model.get_activations(input_img).detach()
# 每个通道乘以相应的梯度均值
for i in range(len(mean_gradients)):
activations[:,i,:,:] *= mean_gradients[i]
# 计算所有通道的均值输出得到热力图
heatmap = torch.mean(activations, dim=1).squeeze()
# 使用Relu函数作用于热力图
heatmap = F.relu(heatmap)
# 对热力图进行标准化
heatmap /= torch.max(heatmap)
heatmap = heatmap.numpy()
return heatmap
- 获取热力图
cam = GradCAM()
# 获取热力图
heatmap = get_heatmap(cam, input_img)
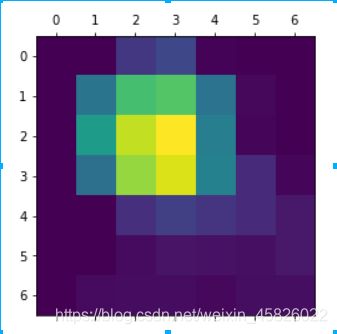
- 可视化热力图
# 可视化热力图
plt.matshow(heatmap)
plt.show()
直接观察热力图,并不能很好的反应原始图像中的哪些内容对图像的分类结果影响更大,所以将热力图与原图进行融合,可以更方便的显示结果
在原图上显示热力图
# 合并热力图和原题,并显示结果
def merge_heatmap_image(heatmap, image_path):
img = cv2.imread(image_path)
heatmap = cv2.resize(heatmap, (img.shape[1], img.shape[0]))
heatmap = np.uint8(255 * heatmap)
heatmap = cv2.applyColorMap(heatmap, cv2.COLORMAP_JET)
grad_cam_img = heatmap * 0.4 + img
grad_cam_img = grad_cam_img / grad_cam_img.max()
# 可视化图像
b,g,r = cv2.split(grad_cam_img)
grad_cam_img = cv2.merge([r,g,b])
plt.figure(figsize=(8,8))
plt.imshow(grad_cam_img)
plt.axis('off')
plt.show()
- 显示结果
merge_heatmap_image(heatmap, img_path)
这样我们可以很直观的看出模型是如何判别该图为狗的,主要是依据狗的头部。

尝试其他的图片
通过修改img_path变量,重新运行代码,我们可以尝试其他的图片,这里展示一部分结果:




















 8435
8435

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









