







决策树思维导图
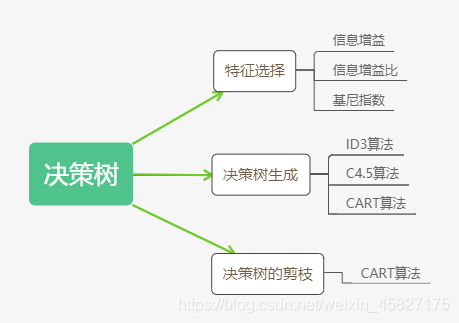
特征选择
特征选择是为了选取具有分类能力的特征,选取准则为信息增益或信息增益比
信息增益
def:特征A对训练数据D的信息增益为g(D,A),定义为集合D的经验熵H(D)和特征A给定条件下D的经验条件熵H(D|A)之差,即
g ( D , A ) = H ( D ) − H ( D ∣ A ) g(D,A)=H(D)-H(D|A) g(D,A)=H(D)−H(D∣A)
其中熵的定义为:
H ( P ) = − ∑ i = 1 n p i l o g 2 p i ( p i = p ( X = x i ) , i = 1 , 2 , 3... ) H(P)=-\sum_{i=1}^{n}p_ilog_2p_i (pi=p(X=x_i),i=1,2,3...) H(P)=−i=1∑npilog2pi(pi=p(X=xi),i=1,2,3...)
熵越大随机变量的不确定性就越大
条件熵的定义为:
H ( Y ∣ X ) = ∑ i = 1 n p i H ( Y ∣ X = x i ) ( p i = p ( X = x i ) , i = 1 , 2 , 3... ) H(Y|X)=\sum_{i=1}^{n}p_iH(Y|X=x_i) (pi=p(X=x_i),i=1,2,3...) H(Y∣X)=i=1∑npiH(Y∣X=xi)(pi=p(X=xi),i=1,2,3...)
当熵和条件熵为数据统计(特别时极大似然估计)得到时,所对应的熵和条件熵称为经验熵和经验条件熵
介绍完熵和条件熵后,我们继续回到信息增益上
一般地,熵与条件熵之差称为互信息,所以信息增益等价于训练数据集中类与特征的互信息
经验熵H(D)表示对数据集D进行分类的不确定性,经验条件熵表示在给定特征A条件下对数据集D进行分类的不确定性,它们的差,即信息增益表示由于特征A而使得对数据集D的分类的不确定性减少的程度
根据信息增益选取特征的方法为:对训练数据集D,计算每个特征的信息增益,选取信息增益最大的那个特征
信息增益比
以信息增益作为划分训练数据集的准则,存在偏向于选择取值较多的特征的问题。利用信息增益比即可矫正该问题
def:信息增益比的定义为信息增益与训练数据集D关于特征A的值的熵之比,即:
g R ( D , A ) = g ( D , A ) H A ( D ) g_R(D,A)=\frac{g(D,A)}{H_A(D)} gR(D,A)=HA
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 768
768











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









