







数据挖掘
目录
文章目录
一、数据挖掘过程
数据收集 collection -> 数据预处理 preprocessing(特征提取 feature extraction, 清洁 cleaning ,特征选择和转换 selection and transformation)-> 分析性处理(find patterns 模式)
以上三个步骤,根据反馈会重新处理
输出分析结果
1. 数据收集collection
耗时 time consuming
非常重要 critical important
- 传感器sendor
- 调查问卷survey
- 自动收集的文档 auto collected doc
2. 数据预处理 preprocessing
1) Extraction 特征提取
将数据转换能放入算法的形式 format
对算法友好数据形式:
- multidimensional 多维
- time series 时间序列
- semistructured format 半结构化的
2) Cleaning 数据清洗
missing, erroneous
-
一般处理方法: remove, correct
- drop a record 去掉一整行记录
- estimate a missing value 预测如 average
- remove inconsistencies 去掉不兼容的项
-
Missing 处理方法
- discard 丢弃 remove the record 去掉一整行, 可能会丢失一些信息,如唯一的一些数据
- fill the value by hand 重写重测 costly 慢,耗时,且花费,有时候不现实
- set “missing value”
- solve nothing
- 如果原始数据类型是 numerical 那么会造成问题
- replace by mean 平均值取代(对于outliers 边界值不准)
- predict 预测 训练好数据以后,首先预测该值,然后再重新训练
- accept 接受这个缺失的数据 , 让算法自己处理
-
Noisy data 噪声
- random errors scattered 噪声是指随机分布的错误 如:inaccurate recording, data corruption 不正确记录,数据损坏
- 噪声的影响: overfitting 过拟合
- Detecting 噪声检测
- incorrect type 类型不对
- dissimilar 数据的范围与其他的差距太大
- Handing 噪声处理
- manual inspection and removal 手动检查并丢弃
- Clustering and find outlier detection 聚类 可视化 看边界值 特征和instance
- Linear regression 线性回归 可视化
- Ignore value that occur below a certain frequency threshold 忽视出现频率低于某一阈值的数据
- effective misspelling in text 在文章错误拼写上非常有效
- 移除噪声后,可以用处理missing 值的方式处理
-
Redundant values 冗余
- 例子 spam 垃圾邮件,advert 广告
- P ( s p a m ∣ a d v e r t ) = P ( s p a m ∩ a d v e r t ) P ( a d v e r t ) = x / z y / z = x / y P(spam|advert)=\frac{P(spam \cap advert)}{P(advert)}=\frac{x/z}{y/z}=x/y P(spam∣advert)=P(advert)P(spam∩advert)=y/zx/z=x/y
- z z z email 的总数
- 例子 spam 垃圾邮件,advert 广告
3) Selection and transformation 特征选择和转换
- feature pruning 特征修剪 identify and remove irrelevant and redundant features 去除无关的冗余的特征
- scale or trans format 缩放,或者改变形式
小思考 PCA 对特征降维, 可能也是包含在内的
Scaling
[0-1] 缩放到该区间
x
′
=
x
−
min
(
x
)
max
(
x
)
−
min
(
x
)
x'=\frac{x-\min(x)}{\max(x)-\min(x)}
x′=max(x)−min(x)x−min(x)
Gaussian normalisation 高斯正规化
x
′
=
x
−
μ
σ
x'=\frac{x-\mu}{\sigma}
x′=σx−μ
σ
\sigma
σ 是standard deviation 标准方差:
σ
=
∑
1
n
(
x
i
−
μ
)
2
n
−
1
\sigma=\sqrt{\frac{\sum^n_1(x_i-\mu)^2}{n-1}}
σ=n−1∑1n(xi−μ)2
3. Analytical Processing 数据分析处理
- 4 main type of types–sub problem 分类
- association pattern mining 模式挖掘
- clustering 聚类,识别group
- classification predict 预测分类 训练数据带label
- Outlier detection 异常值检测
二、数据
行: objectives aka record, point, case, sample, entity, instance
列:features, attribute, variable, field, characteristic, dimension
特征作用: abstract, learn rules 提取数据点, 学习规则
two general Classes of data 这两个分类是数据的本性 data natural
- nondependency-oriented data 无明显数据依赖关系的数据
- 移除 record 的话,影响不大
- dependency-oriented data
- 例子
- successive measurements不断的数据time serial
- networks
- implicit dependencies 间接依赖
- 传感器收集的温度
- 特殊测量
- time series 时间序列
- discrete sequences and strings 离散值,string
- spatial 空间数据
- spatiotemporal 时+空
- explicit dependencies 直接依赖
- graph or network 图或者网络
- 点代表 objective
- 边表示 objective 之间的关系
- 有向图,无向图
- 特征可能与点有关,也可能与边有关
- graph or network 图或者网络
- 例子
type of data representation 数据类型, 数据表示
- numerical / quantitative 数据
- defined order 有序
- algebraic operations 线性操作
- 挑战
- different ranges 数据区间不同
- categorial/ unordered discrete- valued 类别、无序离散值
- 挑战
- 每个类别都是一个维度dimension
- 挑战
- binary 二元
- text 文本
- list, set, vector, word, letter
三、数据分析性处理
1. Four fundamental problems 四类基本问题
1) association pattern 关联模式
Frequent pattern Mining (binary data set 二元数据)
识别哪些,一起出现,一起不出现
2) classification 预测分类 带标签
3) Clustering 聚类 similarity pattern 相似的模式
unsupervised 非监督学习
4) Outlier detection 异常值检测
2. Linear algebra 线性代数
联想: linear regression 线性回归:确定变量之间的依赖关系
vector represent coordinates 向量代表点
R
d
R^d
Rd d: depth
matrices 矩阵
R
m
×
n
R^{m\times n}
Rm×n
symmetric 对称
asymmetric 非对称
- inner-product, dot product 内积,点乘 X ‾ T Y ‾ = ∑ i = 1 d x i y i \overline{X}^T \overline{Y}=\sum_{i=1}^{d} x_i y_i XTY=∑i=1dxiyi
- outer-product 叉乘 外积 M ‾ ∈ R d × d \overline{M}\in R^{d\times d} M∈Rd×d which M ‾ i , j = x i y i \overline{M}_{i,j} = x_i y_i Mi,j=xiyi
- multiplied 平常的那种乘法
- transpose 转置 ( A ‾ B ‾ ) T = B ‾ T A ‾ T (\overline{A} \overline{B})^T=\overline{B}^T \overline{A}^T (AB)T=BTAT
- Inverse 逆 A ‾ A ‾ − 1 = A ‾ − 1 A ‾ = I \overline{A} \overline{A}^{-1}=\overline{A}^{-1} \overline{A}=I AA−1=A−1A=I
- diagonal 对角线上
- linear independence 线性独立 互不平行即向量互相独立,无法用其他的向量表示其中的一个向量。
- 即,不存在 非全零 λ \lambda λ 使得 0 ‾ = λ 1 X 1 ‾ + . . . . + λ k X k ‾ \overline{0}=\lambda_1 \overline{X_1}+....+\lambda_k \overline{X_k} 0=λ1X1+....+λkXk
- rank 秩:不平行行向量的数量。full-rank 满秩 rank-deficient 秩不足
- 只有满秩可逆
- matrix trace 矩阵的迹 ,sum of diagonal 对角线上的元素的和
- eigenvalues and eigenvectors 特征值,特征向量
- A ‾ X ‾ = λ X ‾ \overline{A}\overline{X}=\lambda \overline{X} AX=λX
- 其中 X ‾ \overline{X} X是一个列向量 X ‾ ∈ R n \overline{X} \in R^n X∈Rn
3. 数学基础
continuous optimisation 连续优化
- unconstrained optimisation 自由优化 :gradient decent 梯度下降
- constrained optimisation 约束优化:Lagrange multipliers 拉格朗日多项式
Gradient decent 梯度下降
- find
m
i
n
X
‾
f
(
X
‾
)
min_{\overline{X} }f(\overline{X})
minXf(X) 找局部最小值
- f ( X ‾ ) f(\overline{X}) f(X) 梯度是 ∇ f = δ f δ X ‾ = ( δ f ( X ‾ ) δ x 1 δ f ( X ‾ ) δ x 2 . . . δ f ( X ‾ ) δ x d ) T \nabla f=\frac{\delta f}{\delta \overline{X}}=(\frac{\delta f(\overline{X})}{\delta x_1} \frac{\delta f(\overline{X})}{\delta x_2}...\frac{\delta f(\overline{X})}{\delta x_d})^T ∇f=δXδf=(δx1δf(X)δx2δf(X)...δxdδf(X))T
- 在x0点的梯度
- 更新
X
‾
i
+
1
=
X
‾
i
−
γ
⋅
(
∇
X
‾
f
)
(
X
‾
i
)
\overline X_{i+1}=\overline X_i-\gamma \cdot(\nabla_{\overline X} f)(\overline X_i)
Xi+1=Xi−γ⋅(∇Xf)(Xi) 在x0点的导数
- γ \gamma γ 是step size 正数 很重要,选择合适的话,会converge找到一个局部最小值
Lagrange multipliers 拉格朗日多项式
- find m i n X ‾ f ( X ‾ ) min_{\overline{X} }f(\overline{X}) minXf(X)
- subject to g ( X ‾ ) = 0 g(\overline X)=0 g(X)=0
- L ( X ‾ , λ ) = f ( X ‾ ) − λ ⋅ g ( X ‾ ) \mathcal{L}(\overline X, \lambda)=f(\overline X)-\lambda\cdot g(\overline X) L(X,λ)=f(X)−λ⋅g(X)
- 找局部求导为 0 的点,对所有这些点,检查是否有符合问题的答案点
基本导数
d
d
x
a
=
0
\frac{d}{dx}a=0
dxda=0
d
d
x
x
a
=
a
⋅
x
a
−
1
\frac{d}{dx}x^a=a\cdot x^{a-1}
dxdxa=a⋅xa−1
d
d
x
e
x
=
e
x
\frac{d}{dx}e^x=e^x
dxdex=ex
d
d
x
l
o
g
(
x
)
=
1
x
,
w
h
e
r
e
(
x
>
0
)
\frac{d}{dx}log(x)=\frac{1}{x}, where (x>0)
dxdlog(x)=x1,where(x>0)
d
d
x
s
i
n
(
x
)
=
c
o
s
(
x
)
\frac{d}{dx}sin(x)=cos(x)
dxdsin(x)=cos(x)
d
d
x
c
o
s
(
x
)
=
−
s
i
n
(
x
)
\frac{d}{dx}cos(x)=-sin(x)
dxdcos(x)=−sin(x)
运算规则 differentiation rules
sum:
(
α
f
+
β
g
)
′
=
α
f
′
+
β
g
′
(\alpha f +\beta g)' =\alpha f'+\beta g'
(αf+βg)′=αf′+βg′
product:
(
f
g
)
′
=
f
′
g
+
f
g
′
(fg)'=f'g+fg'
(fg)′=f′g+fg′
quotient:
(
f
g
)
′
=
f
′
g
−
f
g
′
g
2
(\frac{f}{g})'=\frac{f'g-fg'}{g^2}
(gf)′=g2f′g−fg′
chain: If
f
(
x
)
=
h
(
g
(
x
)
)
,
t
h
e
n
f
′
(
x
)
=
h
′
(
g
(
x
)
)
⋅
g
′
(
x
)
=
d
d
g
(
x
)
h
⋅
d
d
x
g
f(x)=h(g(x)), then f'(x)=h'(g(x)) \cdot g'(x)=\frac{d}{dg(x)}h\cdot \frac{d}{dx}g
f(x)=h(g(x)),thenf′(x)=h′(g(x))⋅g′(x)=dg(x)dh⋅dxdg
Partial derivative偏分
Discrete probability distribution 离散可能性分布
- Bernoulli 伯努利, 二元分布 P ( X = 1 ) = p , a n d P ( X = 0 ) = 1 − p P(X=1)=p, and P(X=0)=1-p P(X=1)=p,andP(X=0)=1−p
- Generalised Bernoulli P ( X = 1 ) = p 1 , a n d P ( X = 2 ) = p 2 , … , P ( X = k ) = p k . ∑ i = 1 k p i = 1 P(X=1)=p_1, and P(X=2)=p_2, \dots ,P(X=k)=p_k. \sum^k_{i=1}p_i=1 P(X=1)=p1,andP(X=2)=p2,…,P(X=k)=pk.∑i=1kpi=1事件发生概率总和为1
- Binomial 二项式分布 X ∼ B ( n , p ) P ( X = k ) = ( k n ) p k ( 1 − p ) n − k X\sim B(n,p) P(X=k)=\left( ^n_k \right)p^{k} (1-p)^{n-k} X∼B(n,p)P(X=k)=(kn)pk(1−p)n−k
- Multinomial 多项分布:k面骰子 n ! π i = 1 k n i ! ⋅ Π i = 1 k p i n i \frac{n!}{\pi ^k_{i=1} n_i! }\cdot \Pi^k_{i=1}p_i^{n_i} πi=1kni!n!⋅Πi=1kpini
4. 处理过程中的情况
1) Over-fitting & Under-fitting 过拟合和欠拟合
Over-fitting
对于二元分类, 0,1 各一半的情况
一般: 90-99% train 的accuracy, 40-60% test
原因和解决办法
- Reduce the flexibility of your model 降低复杂度
- regularisation 正规化
- remove features 移除特征
- Early stopping 提前停止
- 提前停止训练
- More training data 更多数据
- Cross-validation 交叉验证
- 简单交叉验证: 70% 30% 划分训练集和验证集,打乱多次,求平均
- K-fold 交叉验证:分成k份,留一份做验证集,重复k次
- leave-one-out 留一:
Under-fitting
原因和解决办法
-
- Not converged
- more iterations 迭代更多次
-
- Feature space too small/inadequate 特征空间不足或者太小
- more/better features 实施更多、好 特征
-
- Train data is bad/ noisy/ missing 训练集 不好,有噪声,有缺失
- cleanse/re-annotate train data 修改,清洗训练数据
-
- Algorithm not good
- select a different training algorithm 改算法
四、分类器评估 evaluation
- absolute goodness 绝对的好,即使在wild 数据上表现也很好
- relative goodness 相对的好,在test data 上表现的好
Numerous measures 线性测量方式 - Confusion(error) Matrix 混淆矩阵
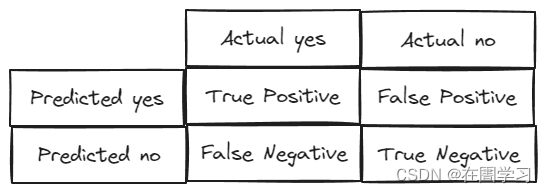
- accuracy 准确性 T P + T N a l l \frac{TP+TN}{all} allTP+TN 预测正确的比例 the correct ratio
- precision 精度 T P T P + F P \frac{TP}{TP+FP} TP+FPTP 预测为真当中有多少是正确的
- recall 召回率 T P a l l P \frac{TP}{all P} allPTP 真实是yes当中,有多少比例是检测出来了,一般疾病预测用
- F-score 2 1 P r e s i o n + 1 r e c a l l \frac{2}{\frac{1}{Presion}+\frac{1}{recall}} Presion1+recall12
- multiple classes 多分类
- precision, recall 定义类似
- F-score : mean of the F-score for each class 单独求,然后取平均值
未完待续















 5137
5137











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











