







数据挖掘
目录
文章目录
分类器
- 经典分类器
- 多分类
- KNN
- Naive bayes 朴素贝叶斯
- 二元分类binary
- Perceptron 感知器
- logistic regression 逻辑回归
- 使用逻辑函数sigmoid g ( z ) = 1 1 + e − z g(z)=\frac{1}{1+e^{-z}} g(z)=1+e−z1对可能性处理
- 原始 P ( Y ∣ X ) = w T x + b P(Y|X)=w^Tx+b P(Y∣X)=wTx+b
- P ( Y ∣ X ) = 1 1 + e − w T x + b P(Y|X)=\frac{1}{1+e^{-w^Tx+b}} P(Y∣X)=1+e−wTx+b1
- 多分类
Perceptron 感知器 二元分类算法
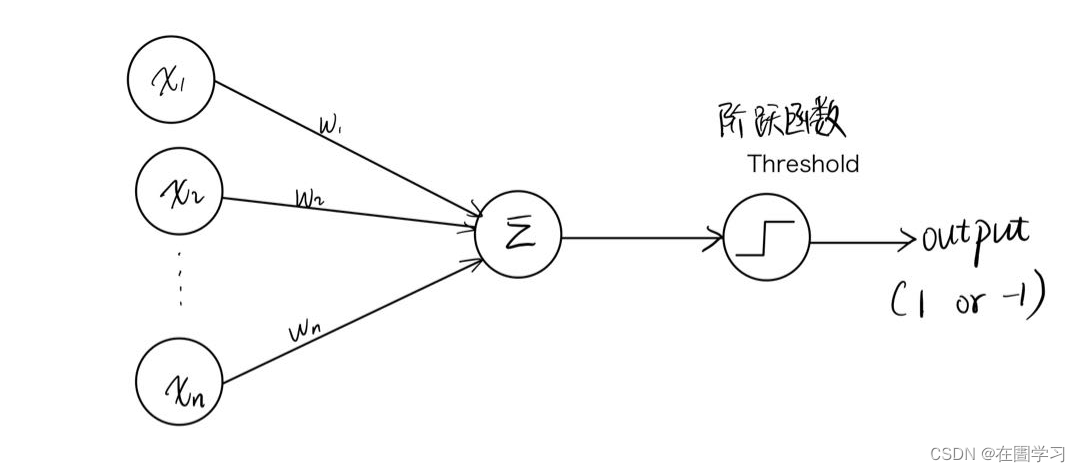
基本模型
a = ∑ i = 1 d w i x i = W ‾ T X ‾ a=\sum^d_{i=1}w_i x_i =\overline W^T \overline X a=∑i=1dwixi=WTX
-
bias: 偏差
a = W ‾ T X ‾ + b a=\overline W^T \overline X+b a=WTX+b 另一种表达形式 a = ∑ i = 0 d w i x i = W ‾ T X ‾ a=\sum^d_{i=0}w_i x_i =\overline W^T \overline X a=∑i=0dwixi=WTX from i=0从i 为0开始, w 0 = b w_0=b w0=b -
Training 训练
- when it is misclassified( y ⋅ a ≤ 0 y\cdot a \leq 0 y⋅a≤0)
- update b = b + y b=b+y b=b+y
- w i = w i + y ⋅ x i w_i=w_i+y\cdot x_i wi=wi+y⋅xi --for i in range (1,d)
-
features 感知器特征
- online algorithm 在线算法,一个一个处理训练数据(batch leaning 相反)
- error driven 错误驱动,参数只在分类错误时更新
-
training dataset randomly 训练集最好是打乱的数据
-
hyperparameter 超参
- 人选的参数,不由算法控制,靠经验
- MaxIter 迭代次数,感知器的超参
-
HyperPlane 超平面,决策边界 n 维空间,n-1维超平面
- X ‾ : W ‾ T X ‾ + b = 0 {\overline X:\overline W^T \overline X+b=0} X:WTX+b=0
-
限制:只能分类线性 linear separability
- non-linearly separable case: 环,月
环,月分类,DBScan表现比较好
- non-linearly separable case: 环,月
-
可找到超平面,即线性可分
-
决策边界,被最后一个训练数据影响
-
对于训练中的权重向量(weight verctors)取平均(averaged perceptron algorithm)
Use Binary classifier as Multiclass classifier 二元分类器用作多元
two strategies 两个策略
- One vs one
- 握手准则所以需要比较 1 2 k ⋅ ( k − 1 ) \frac{1}{2}k\cdot (k-1) 21k⋅(k−1)次 选投票最多的
- 缺点:break ties 瓶颈 投票数相同
- One vs rest
- 选分类模型 最高分
- y = a r g m a x i ∈ { 1 , 2 , . . . , k } A i ( X ‾ ) y=argmax_{i\in \{1,2,...,k\}}A_i(\overline X) y=argmaxi∈{1,2,...,k}Ai(X)
损失函数 Loss function
未完待续















 3592
3592











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











