







 本文介绍了机器学习中的集成学习算法stacking和blending的原理。stacking通过k折交叉验证生成元特征,而blending则采用holdout方法,将训练集分为两部分。stacking过程复杂但更稳健,而blending虽然简单,但可能因数据量少和过拟合问题而不够稳定。
本文介绍了机器学习中的集成学习算法stacking和blending的原理。stacking通过k折交叉验证生成元特征,而blending则采用holdout方法,将训练集分为两部分。stacking过程复杂但更稳健,而blending虽然简单,但可能因数据量少和过拟合问题而不够稳定。
机器学习中集成学习算法,stacking和blending
一.原理
1.stacking
stacking是k折交叉验证,元模型的训练数据等同于基于模型的训练数据,该方法为每个样本都生成了元特征,每生成元特征的模型不一样(k是多少,每个模型的数量就是多少);测试集生成元特征时,需要用到k(k fold不是模型)个加权平均;
2.blending
blending是holdout方法,直接将训练集切割成两个部分,仅10%用于元模型的训练;
二.stacking过程解读
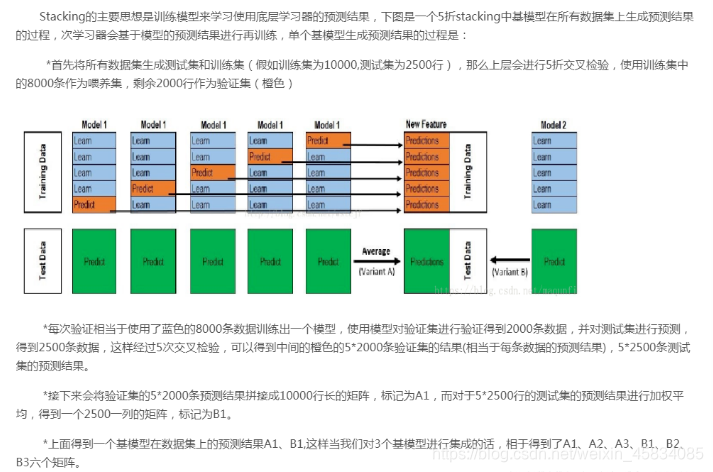
三.优劣
1.stacking

2.blending
1.比stacking简单(因为不用进行k次的交叉验证来获得stacker feature)
2.避开了一个信息泄露问题:generlizers和stacker使用了不一样的数据集
3.在团队建模过程中
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1143
1143

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









