







 本文详细介绍了xgboost算法的过程,包括模型定义、损失函数、树的复杂度、枚举树结构的贪心法、新叶子的惩罚项以及划分点查找算法。通过对xgboost的深入解析,阐述了如何构建和优化模型以最小化预测误差并控制复杂度。
本文详细介绍了xgboost算法的过程,包括模型定义、损失函数、树的复杂度、枚举树结构的贪心法、新叶子的惩罚项以及划分点查找算法。通过对xgboost的深入解析,阐述了如何构建和优化模型以最小化预测误差并控制复杂度。
xgboost是机器学习集成学习boosting系列算法中的一种。现在具体讲解一下xgboost算法过程推导。
一.xgboost
1.xgboost的原理
xgboost是构造一棵棵树来拟合残差。
1.1定义模型:
- 1.符号定义:

- 2.模型定义
假设我们迭代T轮,意味着我们要生成T棵残差树:
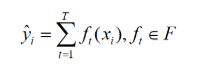
注意:- 1.其实一般来说,前面还要加上一个,但是作者在这里初始化的时候将设置为0,所以不用加了。
- 2.ft(xi)表示的是第t棵残差树对xi的第t轮残差的预测值。
- 3.每一轮残差)树的训练数据是什么呢?假如,yt表示t棵cart残差树的和,也就是最终预测值,y表示x的真实标签,那么第t+1棵树的训练数据就是(x,y-yt)
- 4.F是残差树的函数空间。
- 5.从函数的角度来说,每一个残差树类似一个分段函数。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4128
4128











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









