







目录
Py常用算法技巧
与c++ stl对应结构
https://blog.csdn.net/qq_44514871/article/details/104096128
排序
key参数
a.sort(key=lambda x:x[0])#按每个元素第一位升序排列
重写cmp函数
heapq
构建小顶堆,取出便是堆排序
>>> nums= [2, 3, 5, 1, 54, 23, 132]
>>> heapq.heapify(nums)
>>> nums
[1, 2, 5, 3, 54, 23, 132]
>>>
>>> [heapq.heappop(nums) for i in range(len(nums))]
[1, 2, 3, 5, 23, 54, 132]
>>> nums
[]
#方法二 一个个push构建小顶堆
heap = []
for num in nums:
heapq.heappush(heap, num) # 加入堆
print(heap[0]) # 如果只是想获取最小值而不是弹出,使用heap[0]
heapq.merge合并多个排序后的序列成一个排序后的序列, 返回排序后的值的迭代器。多个有序合并为一个有序列!
>>> num1 = [32, 3, 5, 34, 54, 23, 132]
>>> num2 = [23, 2, 12, 656, 324, 23, 54]
>>> num1.sort()
>>> num2.sort()
>>> num1
[3, 5, 23, 32, 34, 54, 132]
>>> num2
[2, 12, 23, 23, 54, 324, 656]
>>> res = heapq.merge(num1,num2)
>>> list(res)
[2, 3, 5, 12, 23, 23, 23, 32, 34, 54, 54, 132, 324, 656]
需要删除堆中最小元素并加入一个元素,可以使用heapq.heaprepalce() 函数
需要获取堆中最大或最小的范围值,则可以使用heapq.nlargest() 或heapq.nsmallest() 函数,函数还接受一个key参数,用于dict或其他数据结构类型使用
import heapq
nums = [1, 3, 4, 5, 2]
print(heapq.nlargest(3, nums))# 获取最大的三个数
print(heapq.nsmallest(3, nums))# 获取最小的三个数
"""
输出:
[5, 4, 3]
[1, 2, 3]
栈 先进后出队列LifoQueue
from queue import LifoQueue #LIFO队列
lifoQueue = LifoQueue()
lifoQueue.put(1)
lifoQueue.put(2)
lifoQueue.put(3)
print('LIFO队列',lifoQueue.queue)
lifoQueue.get() #返回并删除队列尾部元素
lifoQueue.get()
print(lifoQueue.queue)
优先级队列,每次取最小的一个元素PriorityQueue
rom queue import PriorityQueue #优先队列
priorityQueue = PriorityQueue() #创建优先队列对象
priorityQueue.put(3) #插入元素
priorityQueue.put(78) #插入元素
priorityQueue.put(100) #插入元素
print(priorityQueue.queue) #查看优先级队列中的所有元素
priorityQueue.put(1) #插入元素
priorityQueue.put(2) #插入元素
print('优先级队列:',priorityQueue.queue) #查看优先级队列中的所有元素
priorityQueue.get() #返回并删除优先级最低的元素
双端队列deque ,用在bfs提高效率
字典defaultdict
普通字典dict[element] = xxx,但前提是element字典里,如果不在字典里就会报错。
defaultdict的作用是在于,当字典里的key不存在但被查找时,返回的不是keyError而是一个默认值,返回的是工厂函数的默认值,比如list对应[ ],str对应的是空字符串,set对应set( ),int对应0
from collections import defaultdict
dict1 = defaultdict(int)
dict2 = defaultdict(set)
dict3 = defaultdict(str)
dict4 = defaultdict(list)
dict1[2] ='two'
print(dict1[1])
print(dict2[1])
print(dict3[1])
print(dict4[1])
删除字典
del dict1[“Name”] # 删除键是 Name 的那一行信息,删除一行
dict1.clear() # 清空词典所有信息
del dict1 # 删除词典
访问字典
对字典排序
按照key
按照value
对字典列表排序:如身份证信息
enumerate()函数
enumerate(sequence, [start=0])函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中
可以设置下标起始位置如1
class链表结构定义
#!/usr/bin/env python
#定义一个链表
class Node:
'''
定义节点类
data:数据
_next:下一个数据
'''
def __init__(self,data,_next = None):
self.data = data
self._next = _next
def __repr__(self):
'''
用来定义Node的字节输出
'''
return str(self.data)
class ChainTable(Node):
'''
定义链表
'''
def __init__(self):
self.head = None
self.length = 0
def isEmpty(self):
return (self.length == 0)
def add(self,dataOrNode):
item = None
if isinstance(dataOrNode,Node):
item = dataOrNode
else:
item = Node(dataOrNode)
if not self.head: #若链表的头为空
self.head = item
self.length += 1
else:
node = self.head
while node._next: #当有节点时,新增下一个节点
node = node._next
node._next = item
self.length += 1
def delete(self,index):
if self.isEmpty():
print("链表是空的")
return
if index < 0 or index >= self.length:
print("超出索引长度")
return
#删除第一个节点
if index == 0:
self.head = self.head._next
self.length -= 1
return
#prev为保存前导节点
#node为保存当前节点
#当j与index相等时就
#相当于找到要删除的节点
j = 0
node = self.head
prev = self.head
while node._next and j<index:
prev = node
node = node._next
j += 1
if j == index:#找到节点后将下一个节点覆盖到本节点
prev._next = node._next
self.length -= 1
def update(self,index,data):
if self.isEmpty() or index < 0 or index>=self.length:
print('超出索引长度')
return
j = 0
node = self.head
while node._next and j <index:
node = node._next
j +=1
if j == index:
node.data = data
#查找一个节点
def getItem(self,index):
if self.isEmpty() or index<0 or index >= self.length:
print('超出索引长度')
return
j = 0
node = self.head
while node._next and j<index:
node = node._next
j +=1
return node.data
#从头到尾打印链表
def print_chain(self):
if self.isEmpty():
print('链表为空')
num = []
node = self.head
while node:
num.append(node)
node = node._next
return num
#查找一个节点的索引
def getIndex(self,data):
j = 0
if self.isEmpty():
print('链表为空')
return
node = self.head
while node:
if node.data == data:
return j
node = node._next
j += 1
if j == self.length:
print("%s not found"%str(data))
return
def insert(self,index,dataOrNode):
if self.isEmpty():
print('链表为空')
return
if index < 0 or index >= self.length:
print('超出索引长度')
return
item = None
if isinstance(dataOrNode,Node):
item = dataOrNode
else:
item = Node(dataOrNode)
if index == 0:
item._next = self.head
self.head = item
self.length += 1
return
j = 0
node = self.head
prev = self.head
while node._next and j < index:
prev = node
node = node._next
j += 1
if j == index:
item._next = node
prev._next = item
self.length += 1
def clear(self):
self.head = None
self.length = 0
def __repr__(self):
if self.isEmpty():
return "链表为空"
node = self.head
nlist = ''
while node:
nlist += str(node.data)+' '
node = node._next
return nlist
def __getitem__(self,ind):
if self.isEmpty() or ind <0 or ind>=self.length:
print("超出索引长度")
return
return self.getItem(ind)
def __setitem__(self,ind,val):
if self.isEmpty() or ind<0 or ind>=self.length:
print("超出索引长度")
return
self.update(ind,val)
def __len__(self):
return self.length
chainTable = ChainTable()
for i in range(10):
chainTable.add(i)
print(chainTable.getIndex(1))
print(chainTable.print_chain())
class 图结构
https://blog.csdn.net/qq_41816189/article/details/122788370
注意事项
- 多考虑几组用例,例如全部相同 0 1 负数 等
- 多考虑一下边界问题的处理,用手推一下!
- 最终提交的代码千万不要有其他不应该的输出!!再三检测
- 一定注意range(10) 只遍历0-9 右括号取不到!!!!!!

减少时间开销
- 减少 not in 操作,尽量用下标直接索引a[], 当数组很长时not in 去找很容易超时!!!!
- 结果能打印就打印,不要存在res 最后再打印,减少数组操作
- //2 写成>>1
注意
-
一开始看到数据范围,n=1e5,那么只可以遍历一次for,必须改变思路
-
python语言本身具有大数据和傅里叶乘法优化功能,没有long或者longlong型的数据类型,int类型具有无限精度,可以直接算阶乘、高精度
-
for i in range(1,n) 本身循环就不包括n=1的情况,进不去
-
return 可以直接返回表达式,简化代码量
-
对于走路径、棋盘的题目,如果走过可以置为-1
-
不超过是系统默认的输入
不用考虑一直输入问题
先取余再递推防止超时
有的题目求和,不要直接上来暴力,找公式和规律!! 如数列求和
-
90% 的字符串问题都可以用动态规划解决,并且90%是采用二维数组。
-
填空题如果是穷举的话,在举的时候吧答案打印出来,最终还有重新检验是否符合题意,以防自己条件不全面
- 生成长度为n的数组 vis=[0]*(n+1). (为了对应1-n ,0不用)
思维转换
- 从一个数列中找到两个数之和为n,问一共有多少总方法?
=》利用01背包的思想对于第j个数,只有取和不取的两种可能,只可用1次
=〉dp[i][j]:代表从j个数中选 恰好和为i的方案数
例题 https://www.lanqiao.cn/problems/809/learning/ 质数拆分 - 有几个物品,每个物品无限个,每个物品选任意个,能否凑到某个重量。 类似关键词联想到 完全背包问题变形注意转换方程与01的区别
背包问题是求最大价值,变形问题属性可以是是否01 (凑数问题) - 0到n-1的点到0的距离,每个相邻的点的距离是1 转换成bfs最短路问题!
- 凑数的方案数 记忆化搜索 或者用组合数隔板法
f[k][n]:用前 k 个数凑出 n 的方案数;
- 需要维护一个找最小值的操作,并且进行删除最小值的操作,可以使用堆来操作。可以使用优先队列来写
- 判断是否在一个连通块内 =》 用并查集
- 状态转化方程多试几次表示。如求1-2021带权最短路径
dp[i] #i:结点编号1~2021 #dp[i]:当前结点到结点1的最短路径长度
可以使用的库
math库
itertools 库
bisect 用于有序序列的插入和查找,操作后仍保持有序
- bisect_left函数是新元素会被放置于它相等的元素的前面,而 bisect_right返回的则是跟它相等的元素之后的位置。
insort(seq, item) 把变量 item 插入到序列 seq 中,并能保持 seq 的升序顺序。
bisect查找效率高,建议使用!
用法,必须先对查找的序列拍序 sort()!!!!!
bisect.bisect_left(a,b[i]) 在a序列查找b[i]元素应该在的位置(不存在就后移);如果有相等,会置于它相等的元素的前面,返回相等元素前面的下标
=》可以找到a中有多少数比bi小的数
n-bisect.bisect_right(c,b[i]) 在c序列查找b[i]元素应该在的位置(不存在就后移);如果有相等,会置于它相等的元素的后面,返回相等元素后一个的下标
=》可以找到c中有多少数比bi大的数
- from datetime import *
计算两个日期之间相差几天一定要加1
- from collections import defaultdict
defaultdict 特点是键不存在可以直接赋值,不用讨论是否存在!
用法
>>> p=defaultdict(int)
>>> p
defaultdict(<class 'int'>, {})
>>> p[1]=1
>>> p
defaultdict(<class 'int'>, {1: 1})
- from queue import PriorityQueue #优先队列
越小的优先级越高,会被先取出,根节点先取出
>>>
q=PriorityQueue() #创建数据结构
>>> q.put(2)
>>> q.put(1)
>>> q.qsize()
2
>>> q.get()
1
>>> q.get()
2
总结
from itertools import permutations,combinations
from bisect import bisect_left 数组二分查找,与index区别,不会报错!
from datetime import *#日期题第一步就导入!
from collections import defaultdict,deque
from queue import PriorityQueue,LifoQueue #优先队列 效率比[]块,防止超时
输入输出格式
输入格式
https://blog.csdn.net/zhao2chen3/article/details/120413733
1.接收输入的一串数字,并用列表存放,列表中每个元素是int(注意题干,有时候输入是float)
nums = list(map(int,input().split())) 推荐(注意split先分隔为str)
或者
b = input().split()
nums=[int(i) for i in b] 列表生成器
2.接收二维数组
- 当输入的数据没有间隔开时候的写法
M=[[int(i) for i in input()] for j in range(n)]

- 当输入的数据每个空行间隔开时候
只需要提供行n, 列任意,根据用户输入
mapL = [list(map(int,input().split())) for _ in range(n)]
或者
for i in range(n):
row=list(map(int,input().split()))
mat.append(row)
3,连续输入
a,b=map(int,input().split())
- 把输入的一行行字符串存入矩阵中
for i in range(n):
row=list(map(str,input()))##注意这里不要split()因为每一空格分割,否则会返回[],接收的不是str
g.append(row)
5.分组输入
N,V=map(int,input().split())#N是组数
s=[0 for i in range(N+1)]#对应n组,存储每组的对数
v=[[] for i in range(N+1)]#二维的,每一个[]为同一组
w=[[] for i in range(N+1)]
for i in range(1,N+1):
s[i]=int(input())
for j in range(s[i]):
a,b=map(int,input().split())
v[i].append(a)
w[i].append(b)
接收输入
3 5
2
1 2
2 4
1
3 4
1
4 5
- 三角形输入,为了匹配补全为矩阵(dp搜)
for i in range(1, n + 1):
row = list(map(int, input().split()))
v[i][1:len(row) + 1] = row#注意arr[1,4]不包括4
or 三角形输入,二维列表每个元素都不一样长(dfs搜)
array=[]
for i in range(1,n+1):
array.append(list(map(int,input().split())))
- 接收一维数组,第一个不用从1开始存放n个元素
a[1:n+1] = list(map(int,input().split()))
接收二维数组,外面一圈不用,防止越界,一般搜索时候用!
for i in range(1,n+1):
a[i][1:m+1] = list(map(int,input().split()))#从1行开始1列赋值
- 询问操作
n, m = map(int, input().split())
while m:
M,a,b = input().split()
if M == 'M':
操作。。。。
如果询问的参数不一样,可以先用li存储,然后去截取[0] [1]就行
输出格式
- print(sl[i],end=’ ‘) #end=’ '的作用是输出不换行
- 如果是先输入n代表有几次输入,最后再输出结果,可以把结果暂时append到列表中,最后统一输出
- print()输出之后自带换行,其实print()= print(end = “\n” )。
- 格式化输出
- 小数点后保留n位,但不是四舍五入round(x,n) 建议用格式化输出 .5f
- 格式化输出print(‘%02d:%02d:%02d’%(h,m,s))
时间模版
1、导包:看到日期题,第一步导包:from datetime import *
2、输入:输入起始日st和终止日et。st=date(1949,10,1)
3、遍历:遍历日期,以1天为单位。timedelta(1)
4、判断:满足条件,计数器+1。
5、输出:最后打印计数器的值
st.year 都是int类型
st.month 获得当前日期是第几月
st.day
datetime模块的年最大是9999,可能会报错加到最大,可以用try except处理
| st.isoweekday(...) 返回当前日期是星期几
| Monday == 1 ... Sunday == 7
输入文件
with open('','r') as fp:
for line in fp.readlines():
mat.append(list(line.strip()))#末尾有一个换行 strip掉
进制转换
-
在python中二进制用0b加相应数字来表示,8进制用0o加相应数字来表示,16进制用0x加相应数字来表示
-
bin() oct() hex() int() 内置函数
-
int的两个参数用法,int(s,16) 就是把16进制的s转成10进制的字符串
>>> bin(2) #十进制转换二进制#
'0b10'
>>> bin(0o10) #八进制转换二进制#
'0b1000'
>>> bin(0xf) #十六进制转换二进制#
'0b1111'
#其他进制转换为八进制#
>>> oct(0b101)
'0o5'
>>> oct(0xf)
'0o17'
>>> oct(0o123)
'0o123'
#其他进制转换为十六进制#
>>> hex(0o10)
'0x8'
>>> hex(3)
'0x3'
>>> hex(0b111)
'0x7'
'''
'''
#其他进制转换为十进制#
>>> int(0o10)
8
>>> int(0xf)
15
>>> int(0b10)
2
算数操作
- pow(x,y)表示求解x的y次幂
pow(x,y,z)表示求解x的y次幂对z取余后的结果
-
sum() 求和,对象可以是列表
-
max min() 求最大最小 ,对象可以是列表
- max()中使用key参数!!
l = [1, 2, 3, 4, 2, 3, 4, 6, 7, 3]
print(max(l, key=l.count)) #结果为3
# key参数表明了max函数比较的规则,这里表示在l列表中出现次数最多的数。
# key参数可以是自定义的函数名!,方法,labma表达式,对象比较方法等
#获得一个字符串中出现次数最多的字母
chr=max(string.ascii_lowercase,key=word.count) #注意这里是count函数名
- n//10 扔掉个位 n%10 拿到个位(或者转str再取[])
- 有关于很长的数的操作,一半从后往前操作,倒序操作,再正序输出就是读法
- / 和 %的使用!!!
- float(“-inf”) 无穷小 注意是双引号!
float(“inf”) 无穷大
一般设minx= float(“inf”) - 如果一个数的因子只包含3 5 这个数满足3i*5j==num
- 取出一个数的每一位
sorted(str(x*y)) #取出并从小到大排出
set(str(x))#取出每一位并删除重复的
- 如何判断一个4位数,4个数组均不同?(不同想到唯一,集合set!!!)
len(set(str(x))) == 4
10.避免交换律重复,第二个for循环从i开始
for x in range(1, 999):
for y in range(x, 999):
- 比较=两边用的字符是否一致**(因为数字是无序的不好比较,先排序再比较就可以!!)**
sorted(str(x*y)) == sorted(str(x) + str(y))
- 如果看到1-n不重复组成数组 想到全排列枚举,permutation函数
数论问题
注意:
- 可以从1遍历到一个较大的数,枚举找出所有符合的数据,注意检验!可以存放起来,用index找到其位置
- 全排列
from itertools import permutations #导入全排列函数
for i in per('123456789'):#i=(1, 2, 3, 4, 5, 6, 7, 8, 9)
for i in permutations(range(1,10)): #i=(1, 2, 3, 4, 5, 6, 7, 8, 9)
dfs搜索全排列
- 博弈论(没解决!!!!!)
https://blog.csdn.net/qq_33765907/article/details/51174524 - 组合数
from itertools import combinations #组合数函数
a=[1,2,3,4]
a.sort(reverse=True)#先排序,把最大的放在前面,这样可以减少计算的次数!!!,先选的大值
for i in combinations(a,3): #从a中取3个组合数 i=(4, 3, 2)
组合数求方案
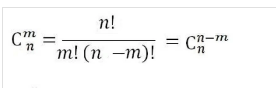
求阶乘
def jiecheng(n):
s=1
for i in range(1,n+1):
s=s*i
return s
在这里插入代码片
可以用来骗分,没有思路的话
-
唯一分解定理:任意一个正整数 X 都可以表示成若干个质数乘积的形式,即 X = p1α1 ∗ p2α2 …… ∗ pkαk
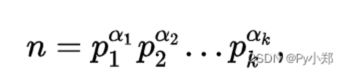
约数个数 = (a1 + 1)(a2 + 1)……(ak + 1)!!!!!!!很重要
n中最多只含有一个大于sqrt(n)的质因子。证明通过反证法:如果有两个大于sqrt(n)的因子,那么相乘会大于n,矛盾。
因此找n的质因子只用遍历到sqrt n (需要特殊考虑最后n>1的情况,此时直接打印最后分解的n 就是那一个大于sqrtn的质因子,如果不是为了优化就遍历到n吧)
#因式分解,分解质因数
def divide(x):
for k in range(2,int(m.sqrt(x))+1):
if x % k == 0:
s = 0
while x % k == 0:
x /= k
s += 1
print(k,s)
if x > 1:
print(int(x),1)#最后如果n还是>1,说明这就是大于sqrt(n)的唯一质因子,输出即可。
- 把n(>2)分解成若干个质数相乘的板子
n=int(input())
i=2#最小的素数
s=[]
while i<=n:#这边可以
if n%i==0:
s.append(i)
n//=i
else:
i+=1
print(s)
100
[2, 2, 5]
- 有时候转化一下思路:
- 把100!看作100个数字相乘,即123…100
- 求一个数的正约数,可以求其素因子,而合因子可以表示为素因子,素因子个数相乘就是正约数 (正约数可以通过质因数来求)=
-
ab=pq
“两个数的乘积等于抄这两个数的最大公约数与最小公倍数的乘积。假设有两个数是a、b,它们的最大公约数是gcd p,最小公倍数是q。那么有这样的关系:ab=pq -
凑数问题、表示问题(裴蜀定理)
最大不能表示出来的数必定有个上界:怎么找???
两个质数凑不到的最大整数
对于任意正整数p,q,且gcd(q,p)=1,【互质的条件,最大公因数是1】则最大无法表示成px+qy(x>=0,y>=0)的数是【pq-q-p】
(对于n>pq-q-p,都可以表示成px+qy;而pq-q-p,就无法表示成px+qy)如果给出的n数不互质,那么就有inf(无穷)多个不能表示
如果给出的n数互质,即gcd(a,b,c,d…)=1,就有 有限个数字不能表示
这里是引用裴蜀定理 ,任意两个数的组合必定是他们gcd的任意两个数的组合必定是他们gcd的倍数,同样可以推广到更多数:如果这些数的gcd是d,那么他们的组合是d的倍数,如果d不是1,那么必然有无限个数无法被组合出来。
#求n个数是否互质
g = a[0]
for i in range(n):
g = math.gcd(g, a[i])
- 找规律问题
1^2+ 22+…p2=(n)(n+1)(2n+1)/2
-
取余数问题、取模问题

一般对每个数取余构成一个新集合B,范围肯定在[0-k-1],如果n个数的余数%k==0 ,这n个数之和也是k的倍数,而且如果前n-1个余数已经枚举出,最后一个余数一定固定,如果要%k的话
i//k i中有几个k,可以拆成几个
i%k i去掉这几个k还剩多少
- 从 k 位置开始, 逐次往后跳 k 步, 根据数学关系可推导出最多跳 n * k / gcd(n, k)
如果 n, k 互质,n * k / gcd(n, k) 相当于 n * k,这个数字可能会非常大。 - 求约数个数、约数
如果 N = p1^c1 * p2^c2 * … *pk^ck
约数个数: (c1 + 1) * (c2 + 1) * … * (ck + 1)
约数之和: (p1^0 + p1^1 + … + p1^c1) * … * (pk^0 + pk^1 + … + pk^ck)
- 欧拉函数

因式分解求质数
"""
基本思想:
求一个数N的欧拉函数,首先要对N进行因式分解(分解质因数),在分解过程中根据下述公式进行计算:
如果 N = p1^c1 * p2^c2 * ... *pk^ck
则 phi(N) = N*(p1-1/p1)*(p2-1/p2)*...*(pk-1/pk)
"""
def phi(x): # O(sqrt(x))
res = x # !!!出错:res应该初始化为x,而不是1
i = 2
while i<=x/i: # 对x进行隐式分解质因子,i从2开始,n中最多只含有一个大于sqrt(n)的质因子
if x%i==0:
res = res/i*(i-1)
while x%i==0:
x = x/i
i += 1
if x>1:#这个x就是大于sqrtn的那个质因子
res = res/x*(x-1)
return int(res) # !!!注意:要准换成整数
if __name__=="__main__":
n = int(input().strip())
for _ in range(n):
a = int(input().strip())
res = phi(a)
print(res)
埃筛法求质数(数据范围很大10^6)
def find_prime(n):
cnt = 0
for x in range(2,n+1):
if is_prime[x]:
cnt += 1
else:
# 是合数,不删合数的倍数 合数一定可以表示为质因子相成,一定是质数的倍数!
continue
for i in range(2*x,n+1,x):
is_prime[i] = False
return cnt
与时间相关
- h = int(time/3600)time里有几个3600 即有几个小时
m = int((time%3600)/60) 取模就是算除了 整数个3600 还剩下多少
s = int((time%3600)%60) - 轮回问题记得用求余 % 不用考虑正负!%不会出现负的
如果不是基准需要调整每次基准第一个
(7+n-2020)%10 #10是区间范围,2020是已知点,+7为了基准
常用写法
- 倒序遍历list
for i range(len(nums)-1,-1,-1): ##注意左闭右开
- 矩阵列数为len(mat[0]) 注意写法
- len(set())==5 保证这五个元素不会相同,互不相同
- q=a.copy() 深拷贝,这样a和q不会互相干扰
- 利用枚举类型增加一个序列进行遍历
for i, element in enumerate(str1 )
比如遍历str 并绑定对应的序号,从0开始!
结合combinations 可以计算每次枚举时候选取元素的下标
for x in combinations(enumerate(nums),2):
#print(x)#((0, 3), (1, 2))
- a[ st: ] 不用考虑最后的索引直接切取出数据,注意括号右边取不到!!
- 求最大值写法
res=0 or -1e9#注意1e9是float 需要int转换
res=max(res,其他)
- 对s取[i,j]区间的数
for i in range(1,len(s)):
for j in range(i,len(s)):#从i开始,避免取到
如果特殊的取固定数目,可以用combinations,但是不会取[i,i] ,需要特处一下
- 如果使用le9 + 7那么会认为是float,有可能取余数产生负数,那么结果就会错误=>所以推荐使用10**9 + 7
- 用例输入是一连串的操作,先存在list中,后序再遍历一个个一起操作
add = [] # 二元组,(插入值,插入坐标)
# 收集插入操作
for i in range(n):
x,c = map(int,input().split())
add.append((x,c))
alls.append(x)
- l.sort() 和l=sorted(l)如果对二维数组排序,只会按前一个元素排序
》[[1, 2], [2, 4], [5, 6], [7, 8], [4, 7]]
[[1, 2], [2, 4], [4, 7], [5, 6], [7, 8]]
14.四舍五入 round 处理浮点数精度问题!(也不一定)
>>> round(2.123123123,4)
2.1231
浮点数运算涉及到精度问题,如果不强制给它保留一定位数的话,会导致点数变多。就比如一个点坐标算完之后是横坐标是1.00000000002,另一个横坐标是1.00000000003,他们纵坐标假设一样的话,这两个点很大概率应该是一个点,因为浮点数运算后几位是不准确的。
-
数组下标[i-n-1] ,访问的是倒序,完全可以带几个初始值看看
-
对字符串统计字母出现的次数
cnt=[0] *26
cnt[ord(word) -ord('a')] +=1
递归思想
- 一致重复处理,直到某一条件(递归出口)
二分思想(什么时候用?)
- 注意自己写的二分和bisect二分查找的区别
bisect 如果元素不存在会返回其应该存在的地方!(如果要加一个判断 not in 肯定会超时!!!直接判断当l不越界时候,a[l]!=x,)
自己写的二分,利用蓝红区域思想!需要考虑l n起始值、对不存在idx进行判断、对越界判断!
例题 AcWing 519. 跳石头 https://www.acwing.com/solution/content/87825/
- 出现最小值最大或最大值最小或求最大值、最小值时,就可以考虑一下二分了,求啥就二分啥
二分注意有界性和单调性
- 快速的找某个数位于第几组第几个位置(索引),当用例很大时候


其中l r 根据题意去定,l可能为0,如果数组不确定多长,把r开很大
前缀和 和 差分
1.差分数组对一段区间整体修改的性质
差分数组前缀和为原数组的性质

贪心思想
1.如果要找三个数之和最大,希望取的数字较大,可以对元素降序排序处理
2. 区间问题对区间的处理
li.sort(key = lambda x:x[1])#按照右端点排序
字母贡献法求值
只用遍历一遍字符串,当范围很大时候
index=ord(s[i])-ord(‘a’)#当前字母的下标
这里的i下标指的是a-z中的下标

str字符串类型常用方法:
-
字符串大小写转化
upper()字符串中字母由小写变为大写
lower()字符串中字母由大写变为小写
capitalize()字符串中字母首字母大写其余小写
title()字符串中字母每个单词的首字母大写其余小写 -
字符串倒序
a=a[: : -1]
a[-5: ] 取字符串后五位
a[:j]取下标0开始到j不包括j -
把数字字符串变成数字,用list存放,方便处理每一位的数
a=str(i)
la=list(map(int,a))
-
如果要对每一个字符串里的字符操作,常把列表化
-
数字和字符转换 ord()返回字符的asciii码值 chr()把数字变成字符
-
eval() 函数用来执行一个字符串表达式,并返回表达式的值
-
str.split(分隔符) 默认以空格分割 ,返回一个列表!
-
更多字符操作函数 https://www.cnblogs.com/lyy135146/p/11655105.html
-
遍历读取指令,判断是字符还是数字L100RLLL
for c in op:
if c.isdigit():
saved_digits.append(c)#不一定要一次性把数字字符加入,每次都append进去,写一个转换的函数,按权位相加
。。。
n = 0
for i in saved_digits:#存放数字字符串的每一位
n *= 10
n += ord(i) - ord('0')#升权位再相加 ord(i) - ord('0')获得数字字符对应的数字
- i.isalpha() 、
list列表类型常用
-
python可以用list实现queue队列
-
s.sort()
默认reverse=False从小到大输出,reverse=True则相反
index.sort(key=(lambda x: len(x)), reverse=True)
关键字key,按照列表长度,从大到小排序注意与sorted内置函数区别开:
list=sorted(intervals, key=lambda x: x[1]) 按照右端点排序

>>> a=[1,3,5,2,9,4,7,8,6,0]
>>> a.sort()
>>> a
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> a=[1,3,5,2,9,4,7,8,6,0]
>>> sorted(a)
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> a
[1, 3, 5, 2, 9, 4, 7, 8, 6, 0]
- s.index(a,start ,end) 查询列表某个元素,注意查询不到不会返回-1!会报错!如果对错误情况有处理的话,不建议用!可以选择范围
所以查找可以用二分bisect.bisect_left(a,item) 如果有序列a中不存在item,也会返回本应该出现的位置下标,不会报错 - s.append() 在最后端添加————用于入队例如bfs
- pop(索引) 弹出列表对应索引元素,相当于删除,默认弹出最后一个;并且会返回弹出的这个数的值
remove(值) 从列表删除值相同的元素,一次只会删1个 - s.insert(index,x) 插入指定索引x
- len(s) 获得长度,元素个数 搭配range(len(s)) 用来遍历
- 把list拼接为字符串 ‘’.join(lsita) 格式转换(字符列表->字符串)
- l.count(x) 计算x出现的次数,并不会直接返回数字
- s = n[-4:] #取后四位
n = n[:-4] #删除后四位
s=s[::-1]#把列表逆序 - 结构赋值注意
for i,j in [[1,0],[-1,0]]:
print(i,j)
1 0
-1 0
- 的
dict字典常用
- 存储方法
r=dict()
for i in range(n):
ts,id=map(int,input().split())
if id not in r.keys(): #如果不存在id,就存放一个id :列表[]
r[id]=[ts]
else:
r[id].append(ts)#该id 已经存在直接加上去,值可以有重复
- 遍历字典
for i in r.keys():#遍历键
3.字典排序方法!
# 字典排序
a = {'a': 3, 'c': 89, 'b': 0, 'd': 34}
# 按照字典的值进行排序
a1 = sorted(a.items(), key=lambda x: x[1])
# 按照字典的键进行排序
a2 = sorted(a.items(), key=lambda x: x[0])
print('按值排序后结果', a1)
print('按键排序后结果', a2)
print('结果转为字典格式', dict(a1))
print('结果转为字典格式', dict(a2))
原理:以a.items()返回的列表[(‘a’, 3), (‘c’, 89), (‘b’,0), (‘d’, 34)]中的每一个元素,作为匿名函数(lambda)的参数,x[0]即用“键”排序,x[1]即用“值”排序;返回结果为新的列表,可以通过dict()函数转为字典格式。
字典列表排序
b = [{'name': 'lee', 'age': 23}, {'name': 'lam', 'age': 12}, {'name': 'lam', 'age': 18}]
b1 = sorted(b, key=lambda x: x['name'])
b2 = sorted(b, key=lambda x: x['age'], reverse=True)
b3 = sorted(b, key=lambda x: (x['name'], -x['age']))
print('按name排序结果:', b1)
print('按age排序结果:', b2)
print('name相同按age降序排列:', b3)
原理:以列表b里面的每一个字典元素作为匿名函数的参数,然后根据需要用键取字典里面的元素作为排序的条件,如x[‘name’]即用name键对应的值来排序。
set集合常用
- set() 函数创建一个无序的 不重复的 元素集 ,
例如把str中重复元素剔除,返回set
>>> set("12")
{'1', '2'}
>>> set("121")
{'1', '2'}
- d1
矩阵操作
- 复制矩阵 c=b.copy() c=b[:]
- 打印矩阵 两个for嵌套、
或用“ ”.join拼接
for i in range(len(Matrix)):
print(" ".join(list(map(str,Matrix[i]))))
- 遍历矩阵
矩阵乘法为例
for i in range(len(A)):遍历每一行
for j in range(len(B[0])): 遍历每一列
for k in range(len(B)): 遍历每一行 ,变化的最快
- 获得单位矩阵E——列表表达式
E = [[1 if i == j else 0 for j in range(n)] for i in range(n)]
- 获得n阶空矩阵,用来存放数值
x = [[0]*n for i in range(n)]
-
在n皇后问题中,因为按行放置,棋盘可以用一维的数组表示path,判断冲突也可以用矩阵标记,dg[i+j] 对角线上的坐标和都是一致的, 副对角线udg[i-j+n] 为了区分不同的副对角线加上n u[j]可以代表第i行的列j
题目https://blog.csdn.net/m0_55148406/article/details/123039702?spm=1001.2014.3001.5502 -
网格遍历的技巧,如n皇后只能向下,不用考虑
上下左右问题,可以用这样处理,提供一个可选择的列表
dxdy=[[1,0],[-1,0],[0,1],[0,-1]] #代表方向:↓ ↑ → ←
每次从该列表中选择一个方向,加上当前坐标求出下一个走到的坐标
走方格时候注意一个边界问题,会有一个边界溢出!即碰到墙壁
- 如果遇到索引越界问题,可以尝试从索引1开始使用,外面留出一圈,即创建矩阵时候把矩阵创建大一圈,让坐标和索引相对应
10.计算距离技巧
d=[[-1] m+1 for i in range(n+1)] d[i][j] 代表距离出发点 11 的距离,默认为负1,这样d11=0 每次找到都加1,找不到就是默认值
- 矩阵的旋转利用zip
#逆时针旋转90°
matrix = list(zip(*matrix))[::-1]
#顺时针旋转90°
matrix = list(zip(*(matrix[::-1])))
算法模版
dfs搜索——搜路径(能用dp不要用dfs)
注意:
- dfs递归函数可以携带参数如sum,比如8皇后求和最大值,每次更新max
比如遍历三角形数组路径最大和,当前走过几次左、右方向下去的
dfs(row,col,left,rihgt,sums) - 出现矩阵、n皇后、路径之类的题目 搜路径数量,方案总数,搜某点路径
dfs模版:
#dfs-模板
def check(参数):
if(满足条件):
return 1
return 0
def dfs(参数):
if (越界不合法情况): ##这个需要考虑,例如碰到墙壁,可以把这个判断逻辑放到check里
return
if (终点边界,输出答案):
return
for (循环枚举所有方案):
if(未被标记):
(标记)
dfs(下一层)
(还原标记)
写法注意:
- dfs搜判断边界条件的一些考虑
是否下一行大于最大行row>n 就false
是否搜半个矩阵,col>row 就false
bfs搜索——搜最短步数
- 当题目说求最短路径,且所有边的长度是1!
- 用deque模拟队列 要用popleft!!!!
- 搜步长最小值,最短路径
- 注意!不是带有上下左右四个方向就是bfs搜!如滑雪问题,要看搜什么
- 灵活变动模版里的参数!是搜路径?记录pre 还是搜最小步数?每次入队携带次数+1
vis=[[0]*n for i in range(n)] #标记列表,用来标记是否搜过
如果搜索的棋盘输入不带分隔,输入的是一串字符串
参数:M:map地图 G:go走过路径
模版
M=[[int(i) for i in input()] for j in range(n)]
G=[['']*m for i in range(n)]#空串方便拼接答案
q=deque([(0,0)])
while q:
x,y=q.popleft()
if x==n-1 and y==m-1:
print(len(G[-1][-1]))
print(G[-1][-1])
break
for i,j,k in [(1,0,'D'),(0,-1,'L'),(0,1,'R'),(-1,0,'U')]:
a,b=x+i,y+j
if 0<=a<n and 0<=b<m and M[a][b]==0:
M[a][b]=1
q.append((a,b))
G[a][b]=G[x][y]+k
dp动态规划
- 当有递推关系、字符串问题、最优解问题、最短最长步数
(bfs先考虑,dp初始化有些很难想到) - 如果每次状态转移只需要 DP table 中的一部分,那么可以尝试用状态压缩来缩小 DP table 的大小
- float(“-inf”) 无穷小 注意是双引号!
float(“inf”) 无穷大
一般设minx= float(“inf”) - 从1开始存储的方法,把索引0空出,方便和dp对应
a = ’ '+input()
a.insert(0,0)
记忆化搜索(dfs配合使用)
当要搜每个点的路径并找最长的路径时使用,f[i,j]记录某个点开始的最长路径,保证不重复搜索!(滑雪问题)
- dp最好初始化为-1,避免方案数为0时少统计
- 一定注意f 的默认值,找一下f肯定确定的值,不然推不出来结果,正序的话
f=[[-1]*(2030) for i in range(10)]
def dfs(k,n):
if f[k][n]!=-1: return f[k][n]
if k==0:
if n==0 : return 1
else: return 0
f[k][n]=0
for i in range(1,n+1):
f[k][n] +=dfs(k-1,n-i)
return f[k][n]
print(dfs(5,2021))
模拟
- 可以定义类来模拟——机器人例如
class Solution:
directon = (1, 0)#表示向前方向 x轴正向
last_coord = [0, 0]#上一点坐标
coord = [0, 0]#走到的当前坐标x,y
def __init__(self):#默认self参数
pass#空语句
def __str__(self):
return str(ch)+" "+str(l) #修改print的打印值
def turn(self, left):#默认左转
def forward(self, dist):#前进
@property#把方法当中属性调用
def dDistance(self):
solution = Solution()#实例化
-
模拟走坐标轴(考虑当前坐标coord与上一坐标lastcoord,转向)
默认directon = (1, 0)#表示向前方向 x轴正向,分左右转讨论

-
d1
其他零散的
求五位数到六位数之间
for i in range(10000,1000000):
生成n阶0矩阵
https://blog.csdn.net/weixin_43303161/article/details/115683927 两种生成方式比较
[[0]*n for i in range(n)]
当打印矩阵问题
若有对角线特点的,可以用abs(i-j) 利用好对角线差值,找规律
斐波那契数列
F1,F2=1,1
for i in range(3,n+1):
F1,F2=F2,(F1+F2)
判断素数、求素数集合
法1 常用 看该数是否可以整除[2,根号i],缩短一半,需要使用math.sqrt() 导包 开方还可以用i**0.5 或者pow
import math
def isPrime(n):
if n <= 1:
return False
for i in range(2,int(math.sqrt(n))+ 1):
if n % i== 0:
return False
return True
法2 跟法1类似,全除了一遍试了,结果是求素数集合
p_nums = [2]
for i in range(3, 10000):
tag = True
for p_num in p_nums://素数只能被1和本身整除,直接用该数除以素数集合每一个看看,没有就是素数
if i % p_num == 0:
tag = False
if tag:
p_nums.append(i)
把字符串n=1234567009 四位一组倒序分割存放到a列表中
while n!='': #倒着读,每四位为一组字符串
if len(n)>=4:
s = n[-4:] #取后四位
n = n[:-4] #删除后四位
a.append(s)
else:
a.append(n)
n = ''
快速幂–矩阵乘法
- 矩阵乘法:
使用zip()函数https://www.jianshu.com/p/7c9dbee3a5b6
zip(*A) 可以把二维矩阵行列互换 ** (*操作就是把外面一层[ (剥开!)**
矩阵乘法原题:https://blog.dotcpp.com/a/84086
def f(A,n,m):
if m == 0:
C = [[1 if i == j else 0 for j in range(n)] for i in range(n)]
else:
C = A[:]
for i in range(m-1):
C = [[sum(a*b for a,b in zip(row,col)) for col in zip(*A)] for row in C]
for i in range(n):
for j in range(n):
print(C[i][j],end=' ')
print()
if __name__ == '__main__':
n,m = map(int,input().strip().split())
A = [[int(j) for j in input().strip().split()] for i in range(n)]
f(A,n,m)
- 的
叶子节点公式

树相关
-
定义
满二叉树:每层都是满的二叉树
完全二叉树:除了最底层节点可能没填满外,其余每层节点数都达到最大值,并且最下面一层的节点都集中在该层最左边的若干位置。 -
两者的深度计算公式
若已知二叉树有n个结点
完全二叉树:depth=[log(2,n)] (向下取整)
满二叉树:depth=log(2,n+1)
depth=int(math.log(n,2))+1#+1是向下取整,但此时根节点的深度1
(如果说定义根节点的深度为0,我们不需要再加一)
- 满二叉树第i层有2^(i-1)个结点
完全二叉树图解
图中有点小错误,深度从1开始,层数和行数相对应,层数就是n,深度如果从0开始,层数从1开始,那么层数11时,深度为10
 3求节点个数
3求节点个数

把一串字符串根据首字母大写分隔
#把一串字符串根据首字母大写来分隔开
#LanQiaoBei
#['Lan', 'Qiao', 'Bei']
def getwords(s,length,w):
i = 0#用来循环
word = ""
while i < length:
if s[i].isupper():#如果当前字符是大写
word = s[i]#临时存储
i += 1#下标移动指向下一位
while i < length and s[i].islower():#判断是否越界 是否是小写字符
word += s[i]#小写就拼接
i += 1
w.append(word)#最终存储在w里
print(w)
快速幂
- 如果要计算一个10^9次方级别的数的pow 使用math.pow会超时!在比赛时候尽量都自己写快速幂
def fpowx(x, n):
res = 1
while n:
if n & 1:
res = res * x
# compute x^2 x^4 x^8
x *= x
n >>= 1
return res
哈夫曼树模版
#哈夫曼树-小明的衣服
from queue import PriorityQueue #优先队列
n=int(input())
a=list(map(int,input().split()))
q=PriorityQueue() #创建数据结构
for i in a:
q.put(i) #入队
cnt=0
while q.qsize()!=1: #队列还有2个数,不到1个数时
a=q.get() #出队
b=q.get() #出队
cnt+=a+b #权值累加
q.put(a+b) #入队
print(cnt)
'''
样例输入:
5
5 1 3 2 1
样例输出:
25
'''
螺旋给矩阵赋值方法
走四个方向,从右往左,从上往下。。。
mat=[[0]*30 for i in range(30)]
cnt=1
top=0
down=29
left=0
right=29
while cnt<=900:
#从左往右
for i in range(left,right+1):
mat[top][i]=cnt
cnt +=1
top+=1
#从上往下
for i in range(top,down+1):
mat[i][right]=cnt
cnt+=1
right -=1
#从右往左
for i in range(right,left-1,-1):#一定注意这边的负向索引遍历,是-1,,这样才能遍历到left不然死循环
mat[down][i]= cnt
cnt+=1
down -=1
#从下往上
for i in range(down,top-1,-1):
mat[i][left]= cnt
cnt+=1
left +=1
埃式筛法
空间换时间
is_prime = [True] * 1000010
def find_prime(n):
cnt = 0
for x in range(2,n+1):
if is_prime[x]:
cnt += 1
else:
# 是合数,不删合数的倍数 合数一定可以表示为质因子相成,一定是质数的倍数!
continue
for i in range(2*x,n+1,x):
is_prime[i] = False
return cnt
最小生成树算法(贪心 并查集)
#模板-并查集
def root(x):#查找→根节点
if x!=p[x]:
p[x]=root(p[x])
return p[x]
def union(x,y):#合并←两节点
if root(x) != root(y):
p[root(y)]=root(x)
def cost(x,y):#计算权值
s=0
while x or y:
if x%10 !=y%10:
s+=x%10+y%10
x//=10
y//=10
return s
#最小生成树
p=[i for i in range(2022)]#p:父节点列表
edge=[(i,j,cost(i,j)) for i in range(1,2022) for j in range(1,2022)]#生成边集合列表
edge.sort(key=lambda x:x[2])#sort:按权值升序排序
cnt,ans=0,0
for i in edge:
if root(i[0])!=root(i[1]) and cnt<2020:#cnt:边数=最大顶点数-1
union(i[0],i[1])
ans+=i[2]
cnt+=1
print(ans)#4046
判断某个数的二进制第i位是1 还是 0
n >> i & 1
并查集模板
模板
def find(x):
if p[x]!=x:
p[x]=find(p[x])
return p[x]
def union(x,y):#合并
if find(x) != find(y):#考虑了只有不在同一个集合才合并!
p[find(y)]=find(x) #让x做y的跟节点,都可以!
#判断两个元素是否在同一个并查集里
find(a)= = find(b)
用并查集判断是否只有一个联通块
首先,把具有联通关系并符合条件的元素加入同一集合
然后统计,联通子图的个数 if p[i] == i cnt++
p[i] == i
如果联通子图个数为1 ,














 1098
1098











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









