







SDP 2021@NAACL LongSumm 科学论⽂⻓摘要生成任务 第一名
前言

失踪人口回归!
因为期末 + 春节的原因,断更了好久。2月份去了网易的人工智能实验室实习,做的自然语言处理实习生。因为之后有个项目是和文本生成相关,老板让我去参加个学术会议比赛熟悉下。然后就选了SDP 2021@NAACL Longsumm Task,我和另一个实习生一起奋战了一个月最后成功代表网易人工智能实验室拿到排行榜第一名的成绩。我们的SBAS模型比第二名各项指标都高出了0.02。
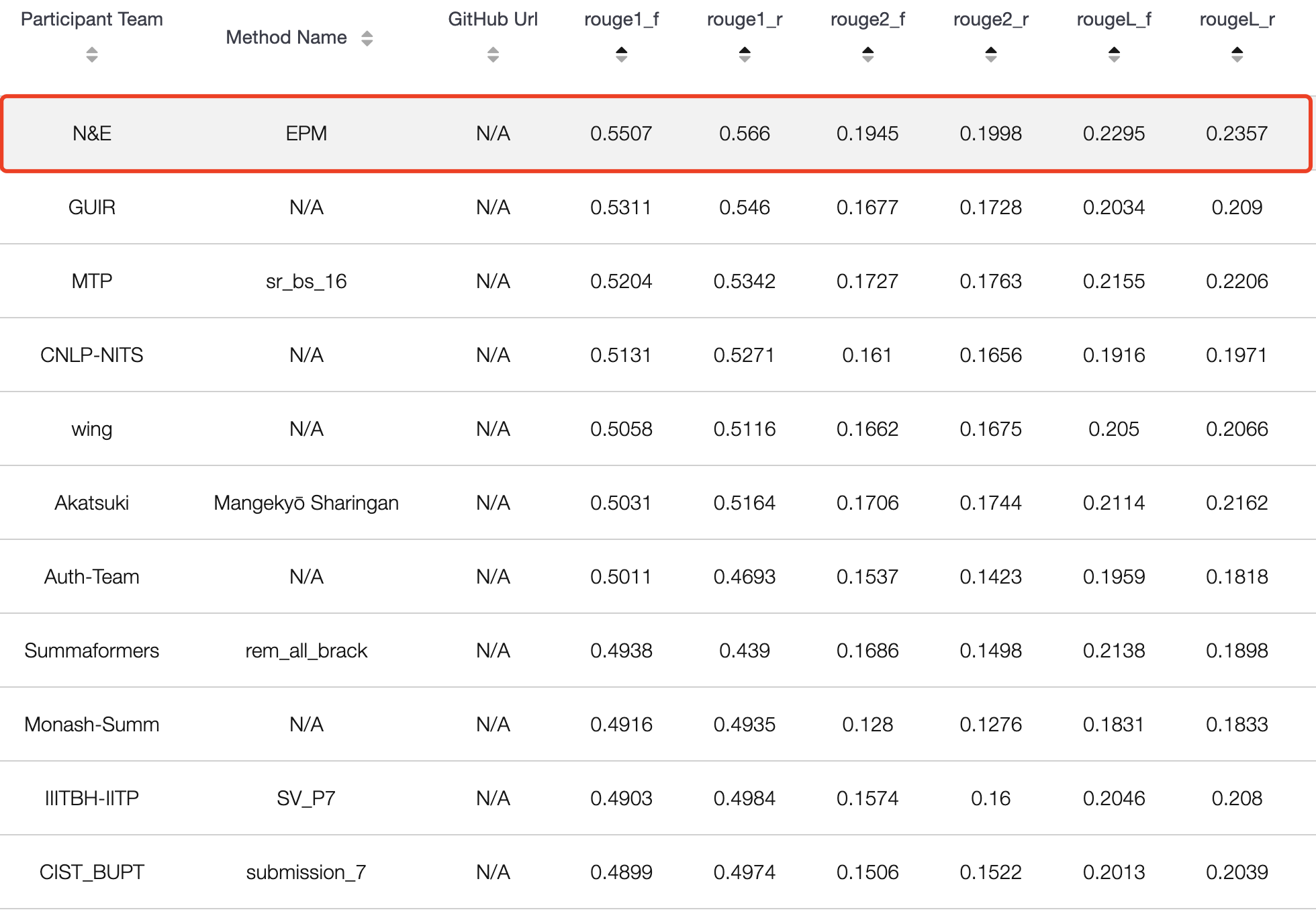
任务介绍
问题描述
- Most of the work on scientific document summarization focuses on generating relatively short summaries. Such a length constraint might be appropriate when summarizing news articles but it is less adequate for scientific work. In fact, such a short summary resembles an abstract and cannot cover all the salient information conveyed in a given scientific text. Writing longer summaries requires expertise and a deep understanding in a scientific domain, as can be found in some researchers blogs.
- To address this point, the LongSumm task opted to leverage blog posts created by researchers in the NLP and Machine learning communities that summarize scientific articles and use these posts as reference summaries.
- 简单来说就是给长论文生成类似于博客的长摘要,我们可以将其归结为长输入长输出的摘要任务,这个任务的难点就在于与我们平时接触的新闻摘要等摘要任务不同,科学论文博客摘要的字数更长而且有一定结构化,并且要求模型对文章进行充分的理解。
数据展示
- Abstractive Summaries: The corpus for this task includes a training set that consists of 1705 extractive summaries, and 531 abstractive summaries of NLP and Machine Learning scientific papers.
- 生成摘要数据来自于网络上一些研究人员针对某篇科学论文的博客内容共531个样本,文章长度在3000-12000字,摘要长度在200-1500字。
{
"id": "79792577",
"blog_id": "4d803bc021f579d4aa3b24cec5b994",
"summary": [
"Task of translating natural language queries into regular expressions ...",
"Proposes a methodology for collecting a large corpus of regular expressions ...",
"Reports performance gain of 19.6% over state-of-the-art models.",
"Architecture LSTM based sequence to sequence neural network (with attention) Six layers ...",
"Attention over encoder layer.",
"...."
],
"author_id": "shugan",
"pdf_url": "http://arxiv.org/pdf/1608.03000v1",
"author_full_name": "Shagun Sodhani",
"source_website": "https://github.com/shagunsodhani/papers-I-read"
}
- Extractive summaries: The extractive summaries are based on video talks from associated conferences (Lev et al. 2019 TalkSumm) while the abstractive summaries are blog posts created by NLP and ML researchers.
- 抽取摘要数据来自于学术会议中的video talks,每篇文章提供前30句摘要,平均990字。
Title: A Binarized Neural Network Joint Model for Machine Translation
Url: https://doi.org/10.18653/v1/d15-1250
Extractive summaries:
0 23 Supertagging in lexicalized grammar parsing is known as almost parsing (Bangalore and Joshi, 1999), in that each supertag is syntactically informative and most ambiguities are resolved once a correct supertag is assigned to every word.
16 22 Our model does not resort to the recursive networks while modeling tree structures via dependencies.
23 19 CCG has a nice property that since every category is highly informative about attachment decisions, assigning it to every word (supertagging) resolves most of its syntactic structure.
24 14 Lewis and Steedman (2014) utilize this characteristics of the grammar.
27 16 Their model looks for the most probable y given a sentence x of length N from the set Y (x) of possible CCG trees under the model of Eq.
28 38 Since this score is factored into each supertag, they call the model a supertag-factored model.
30 58 ci,j is the sequence of categories on such Viterbi parse, and thus b is called the Viterbi inside score, while a is the approximation (upper bound) of the Viterbi outside score.
31 19 A* parsing is a kind of CKY chart parsing augmented with an agenda, a priority queue that keeps the edges to be explored.
48 37 As we will see this keeps our joint model still locally factored and A* search tractable.
50 11 We define a CCG tree y for a sentence x = ⟨xi, .
… …
模型尝试
这篇博客重点阐述模型迭代过程以及最终解决方案,对于数据的转换、处理,模型尝试与对比实验等方法可以在之后的论文中获取。
抽取模型尝试
DGCNN抽取模型
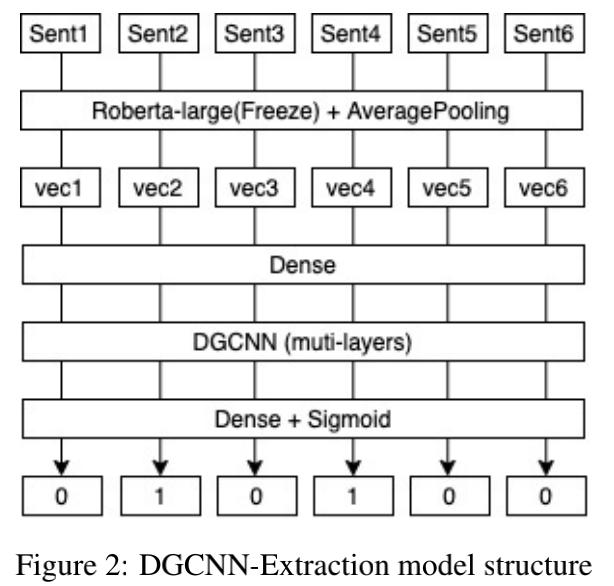
- DGCNN模型大家应该比较熟悉,灵感来自苏神。我们利用Roberta-large作为句子的特征提取器,将论文分句后进行特征转换,每篇论文截取前400个句子。之后我们通过DGCNN对句子之间的特征进行提取,对每个句子作一个二分类来判断该句子是否为重要摘要。DGCNN的优势在于能同时处理文章的全部句子,通过句子之间的关系以及位置来辅助判断该句子的重要性。
- 模型融合&#x
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2912
2912











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









