






 本文详述了正则表达式的概念、用途、工具和使用方法,涵盖元字符、字符类、限定符、正则表达式的分组、向前和向后查找等核心内容。通过实例解析了正则表达式的各种应用场景,旨在帮助读者掌握这一强大的文本处理工具。
本文详述了正则表达式的概念、用途、工具和使用方法,涵盖元字符、字符类、限定符、正则表达式的分组、向前和向后查找等核心内容。通过实例解析了正则表达式的各种应用场景,旨在帮助读者掌握这一强大的文本处理工具。
文章目录
正则表达式
一、正则表达式概述
文本无处不在,web页面,商业文档,电子邮件内容,代码都由文本组成。
所有文本组合到一起就构成了可以通过正则表达式进行匹配的字符序列
面对大量文档需要更新时候,高效的查找手段尤为重要。正则表达式可以实现多种有用文本处理形式的自动化
1.1 定义
正则表达式是一种 由具有特殊含义和功能的字符或字符组合组成的,来匹配文本中的字符序列的*字符模式*。
只能在其他语言或应用程序中使用
1.2 作用
- 查找重复单词
- 检测Web表单的输入
- 转换日期格式
- 发现拼写错误
- 为URL添加链接
本质作用:
判断一个字符序列是否与一个模式相匹配源数据可以是全部匹配或者部分匹配也可以(只能比模式多不能比之少,少则不匹配)
正则表达式在源数据中,对模式中所有部分都找到了相应的匹配项,也就得到了匹配项正则表达式可用
元字符,字符类,交替选择
正则表达式的模式中各个组件必须一次性,一股气全部匹配上才算匹配成功,成功后进入下一轮的匹配
正则表达式对于数据源中匹配当前组件的下一个字符(a) 不匹配当前组件的情况,会进入下一个组件对a的匹配
- 查找文本块
- 替换文本块
- 测试文本块
1.3 使用过的正则表达式
- 文件处理软件,Word,WPS
- 命令行
- 在线搜索
1.4 正则表达式学习困难
-
语法神秘简洁
元字符:在正则表达式模式中具有特殊含义的字符或字符组合 -
空格问题,对空格的修改可能会导致正则表达式含义的改变
-
没有统一的标准定义正则表达式的语法
-
各种实现之间的差别,实现不规范
-
不同环境下的字符含义不同
-
支持语法的不同版本也会提供不同版本的正则表达式功能
-
一个问题没有标准答案,灵活
-
使用正则表达式的目的,要操作的源数据内容,对源数据的了解程度,所定义模式的精确程度
1.5 支持正则的编程语言
1.6 替换大量文本
二、正则表达式工具和使用方法
2.1 正则表达式工具
2.2 基于语言和平台的工具
2.3 ★★★ 使用正则表达式的分析方法
-
自然语言表达说明意图
表明意图的关键在于
对要匹配的内容给出足够精确的定义,这么做的前提是需要对数据源及其可能内容要掌握清楚。对要匹配的内容(
匹配结果)要做出准确判断,限定清楚,定语准确 -
考虑数据源及其可能的内容
对要应用正则表达式的数据源进行认真考量,
对想要匹配的内容在数据源中所出现的各种情况进行考虑,最后定下合适的正则表达式。 -
可用的正则表达式选项
当遇到一个适合使用正则表达式来解决的问题时,就需要仔细考虑一下当前可用的正则表达式工具都有哪些。
要仔细区分程序员的编辑器对正则表达式的支持和程序员的编辑器可能支持的语言对正则表达式的支持。
-
考虑灵敏度和特殊性
-
创建适当的正则表达式
-
对除了简单的正则表达式之外的正则表达式给予说明
以交互方式使用正则表达式时(Microsoft Word),说明正则表达式的意义不大。
对于索要查找问题定义特别复杂的正则表达式,需要考虑加上说明。
-
希望用正则表达式做什么?
多加说明,切不可敷衍了事;对正则表达式的说明需要及时更新,否则就放弃掉
-
想选择什么匹配?
尽可能恰如其分地表达出想要匹配什么字符模式
-
不想选择什么匹配?
对数据源和要创建的正则表达式模式理解的越充分,在注释中添加的说明也会越具体明确
-
-
使用空白区域保持正则表达式说明的清晰
利用空白区域来区分正则表达式中每个组件的注释内容,使注释内容更加清晰。
正则表达式的每个组件都有自己独立的注释,因而可以有效消除或避免多义性
-
测试正则表达式的结果
三、简单的正则表达式(限定符,表示限定要匹配字符出现的次数)
3.1 匹配单个字符
如果要匹配一个特定的字母字符或者数字,那么只需使用由相应的字符或者数字组成的模式即可。
L

-
匹配连续的字符序列
使用正则表达式通常是匹配一个字符序列而不仅仅是一个单独的字符
在
L中,使用正则表达式引擎的默认形式,即不会指出字符(或字符序列)出现的次数,这种情况下,引擎假使模式字符(或字符序列)恰好出现一次。rr
【工作原理】
模式
rr告诉正则表达式引擎应匹配小写的字符r,如果第1次匹配成功,那么再尝试匹配下一个字符。如果第2个字符也是小写的 r,那么表示全部匹配成功。
如果在匹配第1个字符时失败了,会测试下一个字符是不是小写的 r。如果不是小写的r,匹配失败。然后,重新根据正则表达式模式中的第1个r来开始下一轮匹配。
-
元字符简介
截至目前为止,见到的模式(
L,rr)都是不变的直接量字符,含义就是匹配字符本身而元字符可以是
一个单独的字符,或者是一对字符(前一个通常是反斜杠),并且具有不同于其直接量字符的含义- 匹配’ABC123’数字部分
\d\d\d或[0-9][0-9][0-9]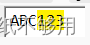
\d/[0-9]:表示数字0~9,不表示反斜杠后跟一小写字母d。一个元字符通常会匹配一类字符 -
匹配不同的字符序列
常见的任务是
查找直接指定的单个字符及一个字符序列DOR\d\d\d//DOR[0-9][0-9][0-9]
3.2 ?匹配可选字符
如果想要匹配单个直接量字符出现0次或者1次,即怎么才能匹配一个可选的字符,需要使用?来表示前面的字符块是可选的。块表示问号之前的模式,可以是单个或多个(不同的)字符,可以是更加复杂的正则表达式结构。
-
colou?r
-
colou?r'?s?'?=

上述模式的全部可选部分都可以存在命中
3.3 * + 其他限量操作符
-
*:表示相关的模式出现0次或者多次(>=1)。一个或一组字符是可选的,但也可能会出现多次。ABC[0-9]*
-
+:如果只能确定一个或一组字符至少存在一次,但也不排除该(组)字符出现多次的可能性,这就需要+。+ 操作符:匹配一次或多次前面的块怎么确定匹配的结束
ABC[0-9]+
【总结】
| 限定符 | 含义 |
|---|---|
| ? | 匹配0或1次 |
| * | 匹配 > = 0 |
| + | 匹配 > =1 |
可以通过在正则表达式模式中简单地
重复一个字符来表达要匹配的重复字符
3.4 大括号语法——限定匹配次数
使用一种大括号语法来精确地指定要匹配的次数
-
{ n } 语法
ABC[0-9][0-9][0-9] //上下等价 ABC[0-9]{3}使用大括号语法来指定最少和最多的次数
-
{ n,m } 语法
使用大括号语法可以让开发者使用 三类限量操作符无法实现 的
限定匹配次数,见下例: -
{ 0 , m } 语法
指定最少匹配零次(
由开始大括号后面的第一位数字指定)而最多匹配m次(由第二个数字指定,与指定最少次数的数字之间以逗号分隔,且位于结束的大括号前面){0,1}: 与?含义相同{0,3}: 最少匹配零次,最多匹配三次 -
{ n,m }
最小匹配次数说明符不一定是0,但不能超过最大出现次数说明符
-
{ n, }
有时候
需要匹配无限次,可以通过忽略大括号中的最大出现次数说明符来达到指定无限次的目的
四、元字符和修饰符
元字符:用于传达非自身含义的字符
修饰符:用于修饰如何应用正则表达式
4.1 正则表达式的元字符
4.1.1 字符和位置
This is a simple sentence
见上处文本,在第一个字符T之前还存在一个位置,元字符中部分可以匹配位置,关于匹配位置而不匹配字符的元字符将在第6部分介绍。
对于位于字符序列中字符之间的位置(单词内部的位置)对开发者意义不大,对字符串开始处,结尾处以及一个字符序列的开始和结尾处更感兴趣,会有专门的元字符来表示这些位置。
4.1.2 句点(.)元字符
句点元字符是适用范围最广的一个元字符,可以匹配任何字母字符(不论大小写),也可以匹配数字
-
匹配可变的零件编号:匹配第4个字符是一个大写的C而第5和第6个字符是数字的零件编号
.{3}C[0-9]{2}
-
匹配句点直接量:匹配文本中的一个句点
\.
如果 . 元字符存在,就不能把句点作为一个直接量字符在模式中来匹配目标文档中的一个句点。
想要匹配句点,
使用反斜杠进行转义
4.1.3 \w 元字符
\w 只匹配英文字母字符(A~Z或a~z)、数字和下划线
\w{3}:匹配三个连续是“单词”字符

\w < = > [A-Za-z0-9_]
4.1.4 \W 元字符
\W元字符用于匹配\w 元字符不匹配的字符。
\W元字符匹配任何非ASCII字母字符、非数字以及非下划线字符。
\W

4.1.5 数字和非数字(\d,\D)
正则表达式的诸多实现中,大都使用字符来表示数字或者非数字
\d表示数字
\D表示非数字
\d < = > [0-9]
在不支持\d的情况下,使用如下方法:
交替选择
(0|1|2|3|4|5|6|7|8|9)使用字符类
[0123456789]//[0-9]
4.2 空白和非空白元字符(\s,\S,\t,\n)
正则表达式的实现提供了几个字符,用来匹配其中一些或者全部可能出现的空白字符。
-
\s 元字符
能够
匹配任何单个的空白字符具体就是:
一个空格符、一个制表符或一个换行符 -
\S元字符:
匹配任何非空白字符 -
\t 元字符:
匹配一个制表符 -
\n元字符:
匹配一个换行符,匹配按回车键时向文本文件中添加的那个字符 -
转义字符:如果要让它匹配对应的直接量字符,则必须要对它进行转义。(\\ )
-
查找反斜杠:
\\
4.3 修饰符
- 全局搜索
- 不区分大小写的搜索
五、字符类
5.1 字符类概述
字符类是一些字符的无序组合,正则表达式模式可以从这个组合中挑选出一个字符来完成匹配。如果对于当前要匹配的字符而言,字符类中指定的任何字符都不能与之匹配,则该字符类匹配失败。
当字符类不带有关联的限定时,字符类只会指定其中一个字符用于匹配。
Sm[yi]th
//Smith 或 Smyth
pe[aei]r
// pear peer peir
//per不行
-
问题定义:匹配一个大写的A,后跟一个大写的B,后跟一个数字1或者一个数字2,后跟另外一个数字的情况。
AB[12]\d
5.1.1 在两个字符中选择
使用字符类进行简单二选一,也可以使用圆括号实现相同效果。
-
问题定义V1:
匹配一个大写的C或者一个大写的D,其后跟任何数量的连续ASCII小写字母字符
[CD][a-z]+
-
问题定义V2:
匹配一个大写的C或者一个大写的D,后跟任何数量的连续ASCII小写字母字符,再后跟一个逗号
[CD][a-z]+,//(C|D)[a-z]+,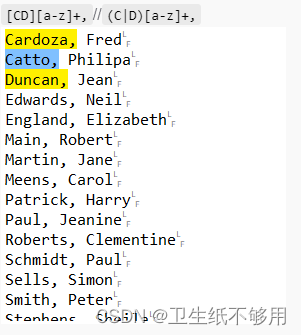
5.1.2 对字符类应用限定符
字符类中的字符只能有一个参与匹配
[AB]{2}[12][0-9]:连续匹配A或B两次
-
在字符类中使用\b元字符
\b在字符类内部表示一个回格符;在字符类外部表示一个词边界有一类元字符,在字符类内部和外部具有不同的含义
-
选择方括号直接量
在定义字符类时我们使用的是
[和]元字符,因此,不能同时使用他们来匹配自身直接量如果想选择其中的任何一个方括号字符,必须要对相应的方括号字符
进行转义。转义,其简单的含义就是在方括号前面放一个反斜杠字符。
5.2 在字符类中使用范围
在字符类中使用范围不仅使得模式更加简洁,而且可以避免罗列字符的错误
[A-Za-z] <=> [abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ]
简化成
[A-z]是不行的,有些非字母字符(如方括号)的位置处于大写的Z后面和小写的a前面。
5.2.1 字母字符范围
问题定义:要匹配right/sight/tight
[rst]ight//[r-t]ight
模式[r-t]是一个字符类:其中r是字符类中的一个直接量字符,而后面的连字符是一个表示范围的元字符,最后的t也是一个直接量字符。
-
慎用
[A-z]在 ASCI 和 Unicode字符集中,大写和小写的字母字符并不是连续存在的
-
字符类中的数字范围
问题定义:匹配一个直接量字符#,后跟六个连续的字符,其中每个字符都以0~15(十进制)的十六进制数—— 即0~F(十六进制)来表示。
[ADFG][BXGE][0-9]{3}
-
十六进制数字
\#[0-9a-fA-F]{6}
-
IP地址
问题定义:匹配13个数字后跟一个句点字符,后跟13个数字,后跟一个句点字符,后跟13个数字,后跟一个句点字符,最后跟13个数字。
[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}
存在匹配到无效IP的问题
问题定义—— 待解决
- 一位数:匹配[0-9]
- 两位数:[1-9][0-9]
- 三位数:
- 1[0-9][0-9]
- 2[0-4][0-9]
- 25[0-5]
5.2.2 反转字符类的范围
通过使用某些工具可以编写出符合反转的字母或数字顺序的范围。
但是不同的产品或语言在处理这种语法时存在不一致问题,所以不建议使用
5.2.3 潜在的范围陷阱
[.-/]
上述字符类作用是匹配分隔符,但是,实际会被解释为从句点到正斜杠的范围
如果不想让连字符表示范围,那么连字符应该作为字符类中的第一个字符
[-./]
5.2.4 查找HTML中的标题元素
<h[1-6]>
5.3 字符类中元字符的含义
5.3.1 ^ 元字符(取反)
^元字符(也称为脱字符),是字符类中左方括号后面的第一个字符时,表示的是方括号中指定的任何字符都不能匹配的情况。
5.3.2 - 元字符(范围)
在字符类中用连字符表示范围。
在字符类中使用直接量连字符的最常见的方式是将连字符作为左方括号的第一个字符
5.4 对字符类取反
[^A-F]:匹配一个不在A~F范围内的字符
组合正负(取反的)字符类
问题定义:匹配字符A和E-Z
问题定义:匹配字符A-Z,但不包括B-D
[A-Z&&[^B-D]]
5.5 POSIX字符类
POSIX方法使用一种命令来表示很多有用的字符类,其语法具有地域性,这里仅介绍
[:alunm] <=> [A-Za-z0-9]
六、字符串、行和词边界
位置元字符可以明确指定要匹配的字符序列的位置
- ^ 元字符:匹配一个字符串或一行的开始位置
- $ 元字符:匹配一个字符串或一行结束位置
- \< 和 \> 元字符:分别匹配一个单词的开始和结束位置
- \b 元字符:匹配一个单词的边界(出现在一个单词的开始或结束位置)
6.1 字符串、行和词边界
与特定位置的字符序列匹配的元字符特别有用
6.1.1 ^ 元字符
^ 元字符:直接匹配位于一行或一个字符串开始位置之后的目标字符
测试数据:‘The Thespian Theatre opens at 19:00’
The:The,Thespian,Theatre
^The:The
当把^元字符用于字符类之外时,它就
失去了在字符类内部作为第一个字符时所具有的取反的含义。
正则表达式从文件第一个字符之前的位置开始查找匹配项,进行下一轮匹配时候,发现当前位置不在测试文本中的第一个字符之前,即匹配失败,只有一处匹配上。
6.1.2 ^ 元字符 和 多行模式
前面的例子不用担心 ^元字符 是会与测试文本的开始处匹配,还是会与每一行的开始匹配
只有在一行文本的情况下,这两个概念指的是同一个位置
不同的工具和语言,可以修改^元字符的行为,让其匹配每行的开始位置,或者只匹配测试文本中第一行的开始位置
各编程语言对多行模式的实现效果不同,具体问题具体分析
6.1.3 $ 元字符
$元字符:指定出现在一个文件结束位置或文件中一行结束位置之前的字符序列
the$

正则表达式引擎尝试将$元字符与测试文本中第一个小写的e后面的位置进行匹配。而该位置不是这个测试字符串的结尾,所以匹配失败。由于模式中的一个组件匹配失败,所以整个模式也匹配失败。
-
多行模式下的$元字符
元字符的匹配行为在多行模式下也会发生变化,并非所有工具或语言都支持多行模式下使用 元字符的匹配行为在多行模式下也会发生变化,并非所有工具或语言都支持多行模式下使用 元字符的匹配行为在多行模式下也会发生变化,并非所有工具或语言都支持多行模式下使用元字符
多行模式下使用$元字符匹配
直接位于Unicode换行符之前的位置。art$
-
同时使用^和$元字符
同时使用^和$元字符可以用于
查找由要找的字符组成的行问题定义:匹配一行的开始位置,后跟直接量字符串 A、B和C,后跟三个数字,最后跟一个行结尾的位置或者一个字符串结尾的位置。
^ABC[0-9]{3}$
-
匹配空白行
组合使用
^$可以匹配空白行 -
处理美元表示的金额
-
重温IP地址的例子
6.2 词
文字处理程序识别不同语言的文本是不现实的
6.3 识别词边界
可以用两个位置来定义词边界
- 构成一个单词的字符序列的开始位置
- 构成一个单词的字符序列的结束位置
6.3.1 \< 语法
< 元字符用于识别位于一个词开始位置的词边界。它的前面是一个非字母字符(比如,一个空格符)或者是一行的开始位置。
6.3.2 \> 语法
\> 元字符 表示位于一个字母字符序列结尾处的词边界。换句话说,它匹配词结尾处的词边界。
6.3.3 \b 语法
\b 元字符既可以用于匹配位于词开始处的词边界也可以用于匹配词结尾处的词边界
\bA和\<A效果一致,含义不同
前者:匹配一个词开始处或结尾处的词边界,并且后跟一个大写的 A。
后者:匹配词开始处的词边界,并且后跟一个大写的A。
后跟一个字母字符的词边界一定是一个位于词开始处的词边界
\B 元字符匹配一个非词边界的位置。
6.3.4 不常见的词边界字符
七、正则表达式中的圆括号
- 圆括号分组
- 对字符和元字符组使用限定符
- 匹配直接量开闭圆括号字符
- 在正则表达式中提供二中择一或多种选项
- 使用捕获或非捕获圆括号
- 使用反向引用
7.1 使用圆括号分组
圆括号可以分组字符序列,如何分组则取决于要完成的操作任务
【NOTE】圆括号里面不要有空白符,否则会被当作字符序列的一部分处理
向正则表达式中加入()可以实现分组
7.1.1 圆括号和限定符
圆括号的一个基本语法是对字符或元字符进行分组,可以对括号内的字符组合使用限定符
(A[0-9]){2}:匹配A后跟一个数字两次
7.1.2 匹配圆括号直接量
\(Home\):转义匹配()
7.1.3 美国电话号码的例子
\([0-9]{3}\) [0-9]{3}-[0-9]{4}
测试数据:(123) 123-4567
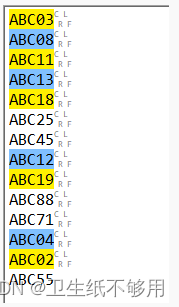
7.2 交替选择
圆括号另一个重要作用表示可选择性,使用圆括号和 | 元字符
匹配ABC01~ABC19
ABC(0|1)[0-9]
7.2.1 在多个选项中做出选择
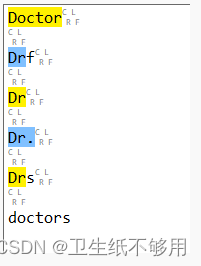
(Doctor|Dr\.?)//(Doctor|Dr\.|Dr)
7.2.2 错误 匹配的交替行为
当选项是不同长度字符序列,而较短的字符序列位于左侧,同时较短的选项又被较长的选项所包含时尤为突出。
(a|ab):

(ab|a):

7.3 捕获圆括号
与位于圆开括号和圆闭括号之间的模式匹配的内容都会被捕获。
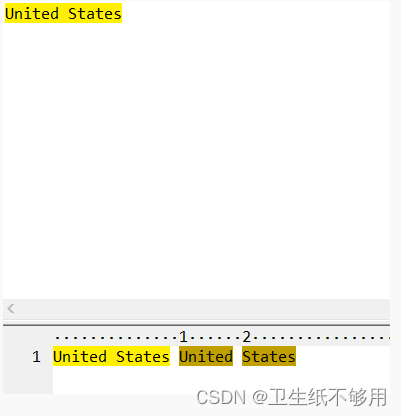
7.3.1 捕获组的编号
变量的编号会按照模式中圆开括号出现的位置依次进行。
(United)(States)
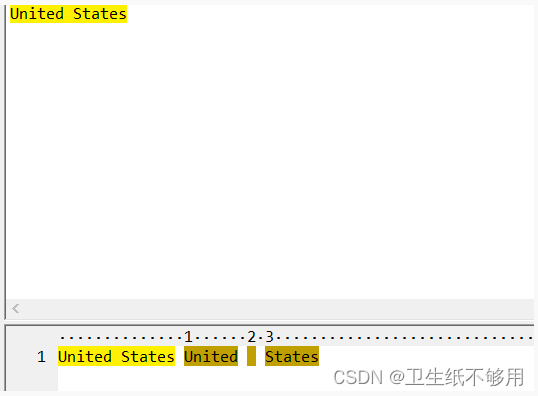
(United)( )(States)
7.3.2 使用嵌套的圆括号时的编号
匹配 ‘A22 33’
((\w(\d{2}))(()(\d{2})))
所创建的其他变量中则保存着与测试文本各个部分对应的值
7.3.3 命名的组
在python中可以创建命名的组,具体语言用到具体查阅
7.4 非捕获的圆括号
对非捕获圆括号的另一种称呼是仅分组的圆括号(或非捕获组)
测试数据如下:
Doctor Firstname LastName
Dr FirstName LastName
Dr. FirstName LastName
1、(Doctor|Dr.|Dr)(\s\w{1,}\s)(\w{1,})
模式(Doctor|Dr.|Dr):创建了组$1并捕获到Doctor或缩写形式
模式(\s\w{1,}\s):创建了组$2并捕获到一个空格符,医生的名字,另一个空格符。
模式(\w{1,}):创建了组$3并捕获到了医生的姓
创建非捕获圆括号的模式如下:
(?:the-non-captured-content)
2、(Doctor|Dr.|Dr)(?:\s\w{1,}\s)(\w{1,})
模式(\s\w{1,}\s)不会捕获包含名字的组内容
非捕获组使得模式看起来复杂,却能减少要处理的组数,使得编程相对容易;
并且有一定的效率提升
7.5 反向引用
捕获圆括号常见用法是将其用于反向引用
测试数据:
Paris in the the spring.
The theoretical viewpoint is of little value here.
I view the theoretical viewpoint as being of little value here.
I think that that is often overdone.
This sentence contains contains a doubled word or two two.
Fear fear is a fearful thing.
Writing successful programs requires that the the programmer fully understands the problem to be solved.
([A-Za-z]+) +\1
\1是一个反向引用第一对捕获圆括号中的内容的模式(就是将前面的捕获组内容再次匹配一次,通过数字来指定相应的组号)

上面匹配结果存在的问题:
第三行 theoretical仅部分匹配,第五行This sentence单词不同,这里的模式匹配的仅是字符序列而并非单词,想要匹配单词需加上词边界符
\<([A-Za-z]+)\> +\<\1\>
八、向前查找和向后查找
反向引用是对文本相关部分进行等同测试或检查的一种特殊形式。
通过反向引用可以测试一个字符序列在测试文本中是否曾经出现过,并且可以将上次出现的字符序列用于某些特殊的目的。
根据某个字符序列的后面或前面是什么来决定是否匹配这个字符序列,可以排除非必要的匹配。
双向查找向前查找+向后查找
向前查找:肯定式向前查找,否定式向后查找
向后查找:肯定式向后查找,否定式向后查找
-
使用向前和向后查找的情形
-
肯定式和否定式向前查找使用方法
-
肯定式和否定式向后查找使用方法
8.1 向前和向后查找原因
查找要求更高,更抽象
| 元字符 | 含义 |
|---|---|
| (?:…) | 非捕获组 |
| (?=…) | 肯定式向前查找 |
| (?!..) | 否定式向前查找 |
| (?<=…) | 肯定式向后查找 |
| (?<!..) | 否定式向后查找 |
只需记住向前查找,向后查找在对应的向前查找的元字符上面加上
<
8.2 向前查找
向前查找根据要匹配的字符序列后面存在一个特定的字符序列(肯定式向前查找)或者不存在一个特定的字符序列(否定式向前查找)来决定是否匹配
理解向前查找的关键在于:出现在指定匹配项之后的字符序列不会被正则表达式返回
问题定义:匹配两个连续的字母字符,这两个字母字符位于一行的开始并且其后跟两个数字。
^[A-Za-z]{2}(?=\d\d)

(?=\d\d)告诉正则表达式必须检查随后的字符序列,只有当后面的字符序列中存在\d\d表示的两个数字时,才能匹配这两个字母字符
AB1虽然想要匹配的AB可以匹配的上,但是因为1无法匹配上后置条件,所以整体无法被匹配上
8.2.1 肯定式向前查找
肯定式向前查找是指在要匹配的字符序列后面必须存在某些字符序列的条件约束下完成匹配过程
对于同样的匹配结果经常会有多种使用向前查找方法。
问题定义:匹配States中的State
State(?=s)//(?=States)State
前者是匹配字符序列State,但它后面必须跟一个小写的s;
后者是查找一个后跟字符序列States的位置,如果位置存在,则匹配字符序列State
案例:
-
肯定式向前查找——Star Training示例
问题定义:匹配字符序列Star,其后跟一个Training
Star(?= Training)

-
肯定式向前查找——根据同一个句子的后面匹配
肯定式向前查找能在同一个句子中查找两个单词
问题定义:匹配字符序列sentence,并且在同一个句子中还跟有字符序列sequence.
sentence(?=.*sequence.*\.)
8.2.2 否定式向前查找
否定式向前查找是指在要匹配的字符序列后面不存在某些字符序列的附加条件约束下完成的匹配过程。
问题定义:匹配字符序列S、t、a和r,但这个字符序列后面不能紧跟一个空格符和另一个字符序列T、r、a、i、 n、i、n和g。
Star(?! Training)

8.3 肯定式向前查找的例子
需要测试一个文档并从中找出某些文本,同时在其后还存在其他一些文本。
8.3.1 在同一个文档中使用肯定式向前查找
问题定义:测试文档中是否提到Microsoft SQL Server,而文档后面是否也提到MySQL数据库。
SQL Server(?:.*MySQL)

8.3.2 插入单引号
匹配之后,进行replace
8.4 向后查找
向后查找测试的是一个要匹配的字符序列前面有(肯定式查找)或者没有(否定式查找)另外一个字符序列
8.4.1 肯定式向后查找
肯定式向后查找是对匹配的一个限定条件。即:只有当向后查找中包含的模式位于要匹配的模式之前时,该模式才会匹配。
测试数据:
Mr.Hyde and Dr.Jekyll are characters in a famous novel
(?<=Dr.)Jekyll
((?<=Mr. )|(?<=Mister ))Hyde
无论是向前还是向后查找,首先匹配要匹配的字符序列,然后再匹配前置或者后置条件里的组件模式
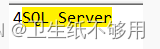
8.4.2 否定式向前查找
只有当向后查找模式匹配的字符序列没有出现在要匹配的模式之前时,该模式才会匹配。
(?<!5)SQL Server
8.5 如何匹配位置
组合使用向前查找和向后查找可以匹配位置
测试数据:
This is Andrews book
问题定义:
匹配一个前面是字符序列is后跟空格符,后面是字符序列Andrew 的位置
(?<=is) (?=Andrew)
另一种组合使用向前和向后查找的方法是为大数添加逗号
为大数添加逗号的过程,本质是匹配数字间的位置并以逗号替换该位置的过程
为1234添加逗号:
(?<=\d)(?=\d\d\d)匹配位置后,点击replace即可添加逗号
九、正则表达式的灵敏度和特殊性
- 灵敏度,特殊性
- 评估在Max灵敏度和特殊性时应该投入的时间和精力
- 使用正则表达式取得灵敏度和特殊性平衡
- 数据源细节影响灵敏度和特殊性
9.1 灵敏度和特殊性
灵敏度是匹配模式的能力
特殊性是把模式选择的字符序列限定为所要选择的字符序列的能力
灵敏度:
可以用实际找到的匹配项中的正确匹配项数除以在匹配全部相关字符序列的情况下应该找到的匹配项总数来表示
特殊性:
可以用实际找到的匹配项中的正确匹配项数除以找到的匹配项总数来表示
灵敏度越高,则表明找到的真正匹配项数量越接近要找的全部匹配项
特殊性越高,则表明找的匹配项中正确的匹配项越多
【重要】
区分二者关键在于区分正确的个数 找到的个数 要找的个数
灵敏度=正确的/要找的 越高,表达式越敏感
特殊性=正确的/找到的 越高,表达式越具有针对性
【译者理解】
灵敏度是从量的角度衡量品牌目标的完成情况
特殊性是从质的角度衡量匹配目标的完成情况
9.1.1 极端灵敏度和糟糕特殊性
9.1.2 电子邮件的例子
9.1.3 替换连字符的例子
9.2 灵敏度和特殊性的平衡
9.3 元字符如何影响灵敏度和特殊性
9.4 了解数据、灵敏度和特殊性
影响灵敏度和特殊性的一个关键性问题就是对要应用正则表达式的数据的了解程度
-
灵敏度MAX
知道要匹配的字符序列的所有变体 -
特殊性MAX
使正则表达式尽可能地具体或者说更具有针对性
仔细考虑所有想匹配的情况,并构造适当的模式从而从结果中排除那些不想要的字符序列
9.5 重新分析Star Training Company的例子
十、说明和调试正则表达式
正则表达式:
- 很难编写
- 很难读懂
- 很难维护
10.1 说明正则表达式
10.1.1 问题定义
问题定义是记录设计正则表达式过程中想法的关键
复杂的问题,最好记录下你不想匹配的问题定义
10.1.2 代码注释
注释要有意义,对代码功能做的详尽解释
在解决问题的时候,存在某种方法不适用,这也应该记录下来,并解释不适用的原因
















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











