







前馈神经网络
第一章 机器学习是什么
第二章 深度学习是什么
第三章 前馈神经网络
`
前言
通常我们说的前馈神经网络有两种:一种叫 Back Propagation Networks———反向传播网络(以下简称BP网络),一种叫RBF Network——径向基函数神经网络。Propagation 的含义是传播,所以也叫作反向传播神经网络。
一、网络结构
BP 网络是所有的神经网络中结构最为单纯的一种。
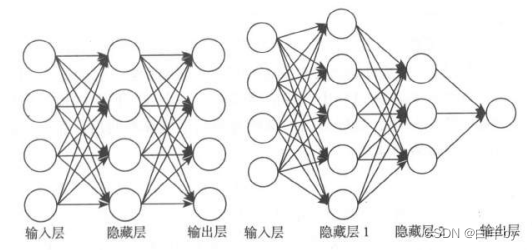
一般习惯上我们喜欢把网络画成“左边输人,右边输出”的结构,一个向量从左边进人,经过网络的运算从右边产生一个输出结果。就像上面这样,当然前馈神经网络的结构不是一种固定的,上面这两个图只是随意列出来了两种。
第一个神经网络有2层,每层4个节点。第二个神经网络和它相比也是大同小异,区别是层数不同:多了一个隐藏层;另外,每一层的神经元数量也不同——一层5个,一层3个,而且最后的输出层只有一个神经元。这些都是与第一个神经网络的不同之处,但它们也都是前馈神经网络。你别看节点数目不一样而且不对称——反正没人规定过这种网络必须对称。这些并不是“问题”,神经网络本身就有很多种设计模式,并且会在不同的模式下产生不同的训练效果和运用特点。
神经网络有一个不太好理解的地方就是它的组成结构太复杂,“元件”太多——一层一层的神经元,会使得模型看上去很不直观。那好,我们就创造一个最简单的BP网络结构吧。把这一个网络研究明白了,再复杂的网络也就不在话下了。

就2层,我们说过输人层不算,隐藏层算1层,输出层算1层,一共2层。
x我们也让它最简单化,就一个维度——一个实数。
隐藏层h和输出层o这两层都是z=wx+b和f(z)的组合。那么这个“网络"(应该叫“线”更恰当)一旦输入了x和y之后,它就可以开始训练过程了。
二、梯度下降
性回归的学习过程。虽然我们没办法得到一个解析解来找到这个极值的位置,但通过迭代不断学习,可以逼近这个模型设置中待定系数w和b的最佳值位置。
首先我们初始化一个w。和一个b。随便是什么实数都可以,反正带进到
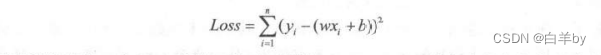
中都是可以输出某一个Loss。值的,这个时候的(wo。,b。,Loss。)就会出现在整个“碗壁”上的某个位置,而且这个位置很可能离我们要找到的碗底还差得很远很远。
所谓的“收敛”就是逐步逼近想要的那个值的过程,那显然在准确度相当的情况下收敛快的方法会更受欢迎一些。对于梯度下降法中有这么多维度的选择,例如z=x, y)就有两个维度,什么更新原则收敛速度会最快呢,有方法可循吗?
有的,在一个三维空间中,在山顶上往山脚下前进,如果想要最快的话,那就是沿着最陡哇的方向去走了。这里有一个名词叫做梯度,记做:
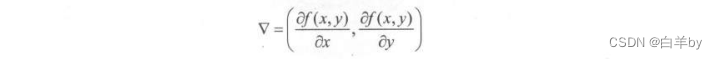
形式上是两个方向上的偏导数,每次如果进行更新的时候就用n去乘两个方向上的偏导数各自完成自己的更新量:
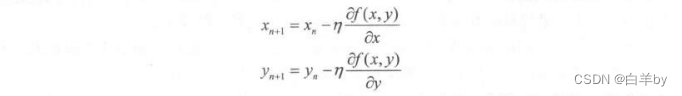
如果变量很多,比如不是只有x和y,而是有1000个变量,例如1000个w怎么办?也是一样的,把它们表示成为
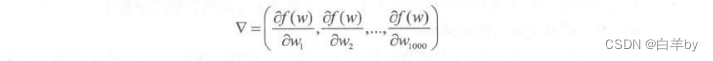
再去各自乘以n就可以了,得到:
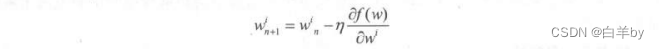
w的上标i表示第几个w,w的下标n和n+1表示迭代的次数,在这个例子里也就是一次迭代对1000个w分别做更新的含义。
到这里我们就基本已经理解了梯度下降法(最速梯度下降法)在多元凸函数上更新所经历的步骤和原理。那么如何解决训练问题呢?我想你已经心里明白了八九分了,只要能够
把残差Loss 函数描述成待定的若干个w所描述的凸函数——Loss(w),那么就可以用梯度下降法,用最快的方法更新w的各个维度,最后满足Loss(w)找到极值点的位置就算是大功告成了。
三、 损失函数
损失函数这个叫法确实非常形象,你想啊,你费了半天劲儿做了个拟合,本身是为了让它和你想要得到的那个真实结果一致,结果中间有差距了,那还不是损失啊?问题是怎么让损失变小,最好是没有损失,只要损失能消灭了那就算是圆满了。
在深度学习中的损失函数其实是不一而足的,每种损失函数在当初诞生的时候都是有一些客观环境和理由的。但不管是哪种损失函数,都有这样几个特点。
特点一:恒非负。
都说是损失了,最圆满的情况就是没损失,或者说损失为0,但凡有一点拟合的偏差那就会让损失增加。所以损失函数都是恒非负的,否则也无法出现合理的解释了。
特点二:误差越小函数值越小。
这个性质也是非常重要的,如果函数定义的不好,优化起来没有方向或者逻辑过于复杂,那对于问题处理显然是不利的。谁愿意没事给自己找个逻辑解释绕脖子的方法来解决问题啊,是不?
特点三:收敛快。
这个性质没有那么关键。收敛快的意思就是指在我们优化这个损失函数Loss 的迭代过程中需要让它比较快地逼近极小值,逼近函数值的低点。同等情况下一个钟头能得到解那绝对没必要花三个钟头,好的损失函数的定义会让这个训练时间在一定程度上缩短的。不过这个条件不能算是必要条件,因为它只要不影响正确性,慢一点其实也不能算作“错误”。这是个锦上添花的属性,大家心里有个数就行了。
本文参考文献:《白话讲深度学习与Tensorflow》高扬、卫峥 著















 162
162











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









