







过载保护
假设一种场景,我们去银行办事,大家都知道需要拿号排队,银行每 10 分钟处理 1 个人的业务,而每 10 分钟会进来 2 个人,这样每 10 分钟就会积压一个用户,然后偶数进来的用户还需要多等 10 分钟,从而就会导致每个人的等待时长是 ((n + 1) / 2 - 1 + (n + 1) % 2) * 10。
其中变量 n 为第几个进来的用户。随着 n 越大,等待的时间就越长,如果没有及时制止,银行将永远都是饱和状态。长时间饱和工作状态,银行人员将会很辛苦,从而无法更好服务用户。一般情况下,在银行都会有一定的取号上限或者保安会提示无法再服务了,这就是一个过载的保护,避免因事务积压,导致系统无法提供更好的服务。
以上是一个简单的例子,接下来我们从技术层面介绍过载保护概念,而由于 Node.js 最大的性能损耗又在于 CPU,因此又需要进一步了解什么是 CPU 的过载保护。
1.什么是过载保护
这个词最早出现是在电路方面,在出现短路或者电压承载过大时,会触发电源的过载保护设备,该设备要不熔断、要不跳闸切断电源。
在服务端也是相似的原理,首先我们需要设计一个过载保护的服务,在过载触发时,切断用户服务直接返回报错,在压力恢复时,正常响应用户请求。
2.CPU 过载保护
在 Node.js 中最大的瓶颈在于 CPU,因此我们需要针对 CPU 的过载进行保护。当 CPU 使用率超出一定范围时,进行请求熔断处理,直接报错返回,接下来我们来看下具体的实现原理。
实现方案
在实现方案前,我们需要思考几个关键的问题:
-
获取当前进程所在的 CPU 使用率的方法;
-
应尽量避免影响服务性能;
-
什么时候触发过载,能否减少误处理情况;
-
请求丢弃方法和优先级;
接下来我们看下这几个部分的实现方法。
1.获取 CPU 使用率
Node.js 进程启动后,都会绑定在单核 CPU 上。假设机器有 2 个 CPU 内核,我们只启动了一个进程,那么在没有其他外在因素影响的情况下,Node.js 即使跑满 CPU,也最多只占用了 50% 的总机器的 CPU 利用率。因此这里我需要获取该进程 CPU 使用率。
我们需要获取当前进程下的 CPU 使用情况,而不是整体机器的 CPU,因此需要使用 PS 这个命令,而不是利用 Node.js 本身的 OS 模块。这里我们以 Mac 为例子,其他部分你可以参考 GitHub 源码。
首先我们需要使用一个命令:
$ ps -p ${process.pid} -o pid,rss,vsz,pcpu,comm
这一命令是获取当前 Node.js 进程下的进程信息:
-
pid 是进程 ID;
-
rss 是实际内存占用;
-
vsz 是虚拟内存占用;
-
pcpu 是 CPU 使用率;
-
comm 是进程执行的指令。
在 Linux 或者 Mac 系统中可以直接运行以上命令,查看某些进程的信息。
有了命令后,我们需要在 Node.js 中执行修改命令,并获取执行结果,以下代码就是在 Node.js 执行修改命令的方法。
/**
* @description 使用 ps 命令获取进程信息
*/
async _getPs() {
// 命令行
const cmd = `ps -p ${process.pid} -o pid,rss,vsz,pcpu,comm`;
// 获取执行结果
const { stdout, stderr } = await exec(cmd);
if(stderr) { // 异常情况
console.log(stderr);
return false;
}
return stdout;
}
在上面代码中 exec 是一个经过 util.promisify 处理的方法,而不是 Node.js 原生模块的 exec 方法,处理逻辑如下:
const util = require('util');
const exec = util.promisify(require('child_process').exec);
获取到进程信息后,我们需要将进程信息转化为相应的数据对象,具体方法如下:
/**
* @description 获取进程信息
*/
async _getProcessInfo() {
let pidInfo, cpuInfo;
<span class="hljs-keyword">if</span> (platform === <span class="hljs-string">'win32'</span>) { <span class="hljs-comment">// windows 平台</span>
pidInfo = <span class="hljs-keyword">await</span> <span class="hljs-keyword">this</span>._getWmic();
} <span class="hljs-keyword">else</span> { <span class="hljs-comment">// 其他平台 linux & mac</span>
pidInfo = <span class="hljs-keyword">await</span> <span class="hljs-keyword">this</span>._getPs();
}
cpuInfo = <span class="hljs-keyword">await</span> <span class="hljs-keyword">this</span>._parseInOs(pidInfo);
<span class="hljs-keyword">if</span>(!cpuInfo) { <span class="hljs-comment">// 异常处理</span>
<span class="hljs-keyword">return</span> <span class="hljs-literal">false</span>;
}
<span class="hljs-comment">/// 命令行数据,字段解析处理</span>
<span class="hljs-keyword">const</span> pid = <span class="hljs-built_in">parseInt</span>(cpuInfo.pid, <span class="hljs-number">10</span>);
<span class="hljs-keyword">const</span> name = cpuInfo.name.substr(cpuInfo.name.lastIndexOf(<span class="hljs-string">'/'</span>) + <span class="hljs-number">1</span>);
<span class="hljs-keyword">const</span> cpu = <span class="hljs-built_in">parseFloat</span>(cpuInfo.cpu);
<span class="hljs-keyword">const</span> mem = {
<span class="hljs-attr">private</span>: <span class="hljs-built_in">parseInt</span>(cpuInfo.pmem, <span class="hljs-number">10</span>),
<span class="hljs-attr">virtual</span>: <span class="hljs-built_in">parseInt</span>(cpuInfo.vmem, <span class="hljs-number">10</span>),
<span class="hljs-attr">usage</span>: cpuInfo.pmem / totalmem * <span class="hljs-number">100</span>
};
<span class="hljs-keyword">return</span> {
pid, name, cpu, mem
}
}
在上面代码中,一开始需要根据平台的不同,调用不同的命令来获取进程信息。其他基本上都是一些字符串的处理,没有什么特殊的逻辑。
以上就是一个获取当前进程的相关信息的方法,其中的 usage 就是 CPU 相关的信息,由于还是涉及非常多的逻辑处理和计算,因此我们需要思考如何简化方式,减少对主线程 CPU 性能损耗。
2.性能影响
由于在 Node.js 就只有一个主线程,因此必须严格减少框架在主线程的占用时间,控制框架基础模块的性能损耗,从而将主线程资源更多服务于业务,增强业务并发处理能力。为了满足这点,我们需要做两件事情:
-
只处理需要的数据,因此在第一步获取 CPU 使用率的基础上,我们需要缩减一些字段,只获取 CPU 信息即可;
-
定时落地 CPU 信息到内存中,而非根据用户访问来实时计算。
在第一点上,我们把原来获取的 pid、rss、vsz、comm 全部去掉,只留下 pcpu,然后将逻辑优化。第二点则需要定时设置内存中的 CPU 使用率,这部分代码如下:
async check(maxOverloadNum =30, maxCpuPercentage=80) {
/// 定时处理逻辑
setInterval(async () => {
try {
const cpuInfo = await this._getProcessInfo();
if(!cpuInfo) { // 异常不处理
return;
}
if(cpuInfo > maxCpuPercentage) {
overloadTimes++;
} else {
overloadTimes = 0;
return isOverload = false;
}
if(overloadTimes > maxOverloadNum){
isOverload = true;
}
} catch(err){
console.log(err);
return;
}
}, 2000);
}
上面代码中使用了 setInterval 来实现,每秒执行一次。在代码中的两个参数 maxOverloadNum 和 maxCpuPercentage:
-
maxOverloadNum 表示最大持续超出负载次数,当大于该值时才会判断为超出负载了;
-
maxCpuPercentage 表示单次 CPU 使用率是否大于该分位值,大于则记录一次超载次数。
最后我们再看下应用的地方,如下所示,整个代码在 GitHub 项目的 index.js 文件中。
cpuOverload.check().then().catch(err => {
console.log(err)
});
上面代码主要是调用 check 方法,并且用来捕获异常,避免引起服务器崩溃。
3.概率丢弃
在获取 CPU 值以后,我们可以根据当前 CPU 的情况进行一些丢弃处理,但是应尽量避免出现误处理的情况。比如当前 CPU 某个时刻出现了过高,但是立马恢复了,这种情况下我们是不能进行丢弃请求的,只有当 CPU 长期处于一个高负载情况下才能进行请求丢弃。
即使要丢请求,也需要根据概率来丢弃,而不是每个请求都丢弃,我们需要根据三个变量:
-
overloadTimes,用 o 表示,指 CPU 过载持续次数,该值越高则丢弃概率越大,设定取值范围为 0 ~ 10;
-
currentCpuPercentage,用 c 表示,指 CPU 当前负载越高,占用率越大则丢弃概率越大,这里设定范围为 0 ~ 10,10 代表是最大值 100% ;
-
baseProbability,用 b 表示,是负载最大时的丢弃概率,取值范围为 0 ~ 1。
虽然都是正向反馈,但是三者对结果影响是不同的:
-
overloadTimes 可以看作是直线型,但是影响系数为 0.1;
-
baseProbability 我们也可以看作是直线型;
-
而 currentCpuPercentage 则是一个指数型增长模型。
可以得出一个简单的算法公式,如下所示:
P = (0.1 * o) * Math.exp(c) / (10 * Math.exp(10)) * b
其中 o 取最大值 100,c 取最大值 10,b 为固定值,这里假设为 0.7,那么求出来的最大概率是 0.7 ;那么在 o 为 30,c 为 90 的概率则是 0.19 ,因此会丢弃 19% 的用户请求。
接下来我们先实现该 P 概率公式,代码如下:
/**
* @description 获取丢弃概率
*/
_setProbability() {
let o = overloadTimes >= 100 ? 100 : overloadTimes;
let c = currentCpuPercentage >= 100 ? 10 : currentCpuPercentage/10;
currentProbability = ((0.1 * o) * Math.exp(c) / maxValue * this.baseProbability).toFixed(4);
}
为了性能考虑,我们会将上面的 10 * Math.exp(10) 作为一个 const 值,避免重复计算,其次这个方法是在 check 函数中调用,2 秒处理一次,避免过多计算影响 CPU 性能。然后我们再来实现一个获取随机数的方法,代码如下:
/**
* @description 获取一个概率值
*/
_getRandomNum(){
return Math.random();
}
最后我们在 isAvailable 函数中判断当前的随机数是否大于等于概率值,如果小于概率值则丢弃该请求,大于则认为允许请求继续访问,如下代码所示:
isAvailable(path, uuid) {
if(isOverload) {
if(this._getRandomNum() <= this._getProbability()) {
return false;
}
return true;
}
return true;
}
以上就是判断是否需要丢弃的逻辑。在某些情况下,我们需要做一定的优化,避免一些重要的请求无法触达用户,因此还需要做一些优化级和同一个 uuid 进行优化的策略。
4.优先级处理
这里我们需要考虑 2 个点:
-
优先级问题,因为有些核心的请求我们不希望用户在访问时出现丢弃的情况,比如支付或者其他核心重要的流程;
-
其次对于一个用户,我们允许了该用户访问其中一个接口,那么其他接口在短时间内应该也允许请求,不然会导致有些接口响应成功,有些失败,那么用户还是无法正常使用。
优先级的实现
优先级实现最简单的方式,就是接受一个白名单参数,如果设置了则会在白名单中的请求通过处理,无须校验,如果不在才会进行检查,代码实现如下:
isAvailable(path, uuid) {
if(this.whiteList.includes(path)) {
return true;
}
if(isOverload) {
if(this._getRandomNum() <= currentProbability) {
return false;
}
return true;
}
return true;
}
uuid 处理
这部分稍微复杂一些,首先我们需要考虑时效性,如果存储没有时效会导致存储数据过大,从而引起内存异常问题,其次应该考虑使用共享内存 Redis 方式,因为有可能是多机器部署。这里为了简单化,会使用本地内存的方式,但是也需要考虑上限,超过上限剔除第一个元素,代码实现如下:
isAvailable(path, uuid) {
if(path && this.whiteList.includes(path)) { // 判断是否在白名单内
return true;
}
if(uuid && canAccessList.includes(uuid)){ // 判断是否已经放行过
return true;
}
if(isOverload) {
if(this._getRandomNum() <= currentProbability) {
removeCount++;
return false;
}
}
if(uuid) { // 需要将 uuid 加入放行数组
if(canAccessList.length > maxUser){
canAccessList.shift()
}
canAccessList.push(uuid);
}
return true;
}
以上就实现这个过载模块了,重点要注意的是获取 CPU 使用率的方法、减少性能影响、概率丢弃和优先级处理。接下来我们就实践应用一下,首先我们可以对比下性能影响,在没有应用和应用之后两者的空转性能对比。
实践应用
在下一讲中我们会将 MSVC 框架转化为 Koa 框架接入,这里我们还是以最原始的框架为基础来接入 MSVC。
1.接入 MSVC
首先我们需要在入口文件初始化过载保护模块,并且调用 check 方法,定时获取 CPU 信息,代码如下:
const cpuOverload = new (require('./util/cpuOverload'))();
/**
* 处理 cpu 信息采集
*/
cpuOverload.check().then().catch(err => {
console.log(err)
});
接下来在请求转发处,先进行判断,在进入业务之前就进行拦截处理,代码如下图 1 所示:
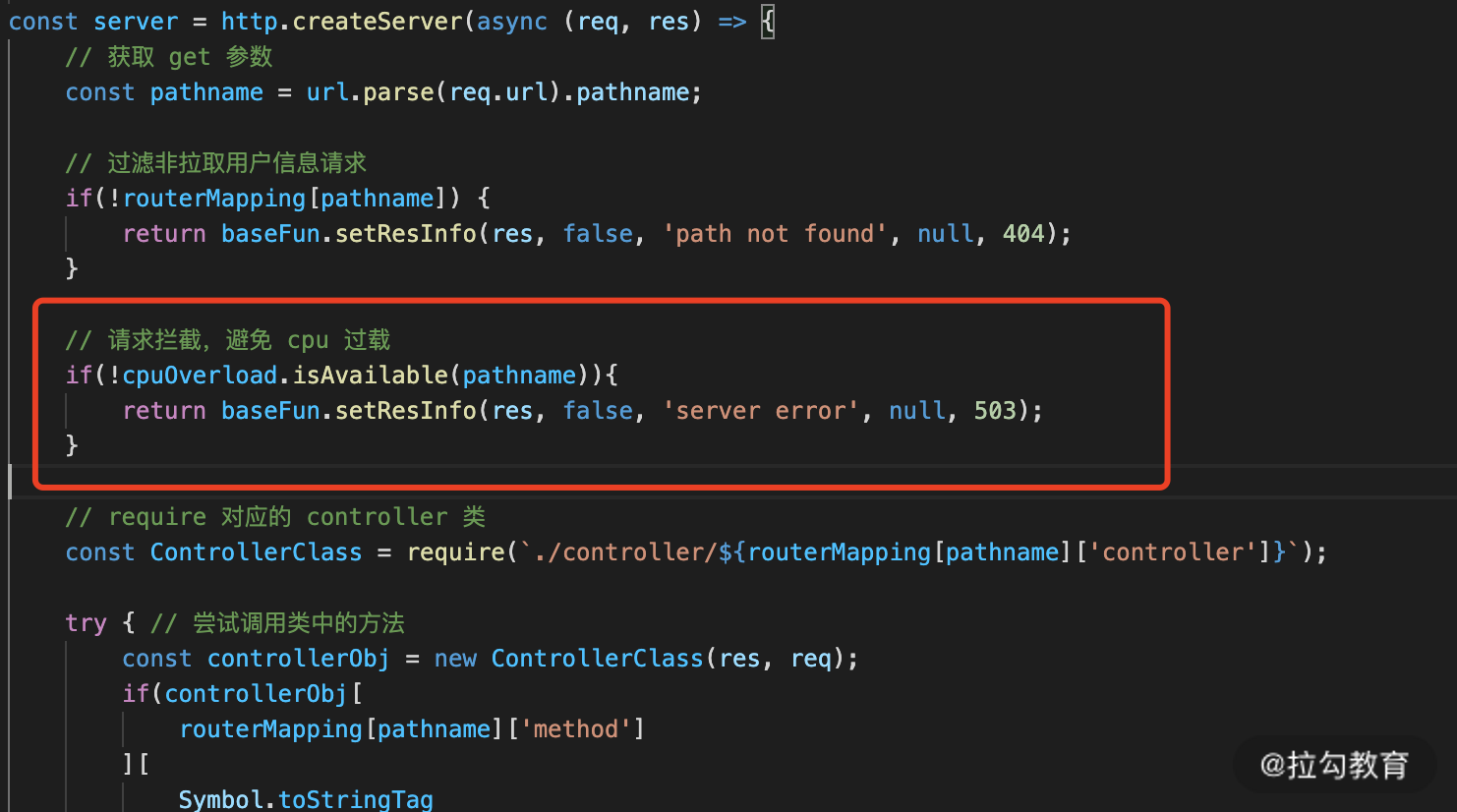
图 1 增加 CPU 过载处理代码图
使用起来比较简单,接下来我们就来看看实际性能对比。
2.性能分析对比
我们对移除 CPU 过载保护代码和加上过载保护逻辑后的压测数据,使用压测工具进行压测,这里你只需要了解 WRK 即可,具体压测工具我们还会在《12 | 性能分析:性能影响的关键路径以及优化策略》中详细介绍。最后我们可以得到如下表格 1 所示的结果。
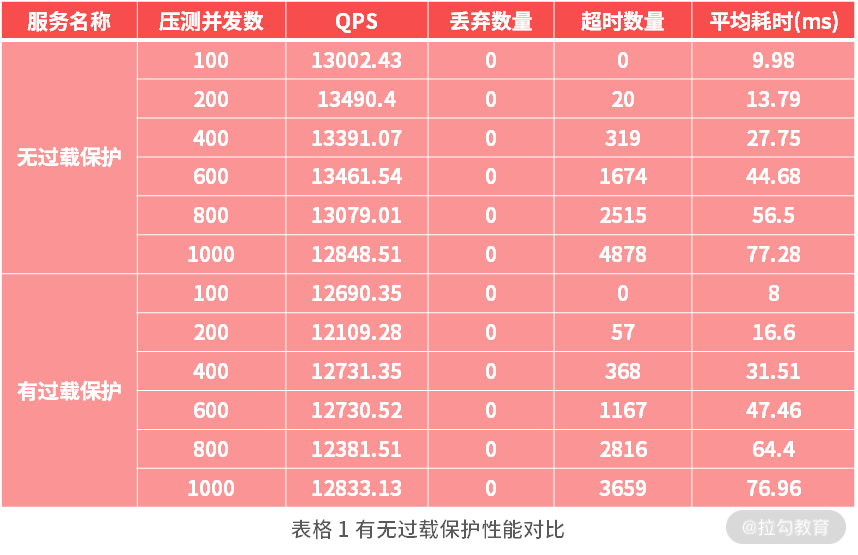
上面的测试数据是在持续时长为 20 秒、CPU 占用大于 98、丢弃概率为 80% 时的测试数据,可以看出,整体上两者并没有多大差距(由于是本机器测试,会有部分误差),那么如果我们将 CPU 占用修改为 80 时,我们可以看下 1000 并发时压测数据,如下所示:
10 threads and 1000 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 71.31ms 4.95ms 189.60ms 90.88%
Req/Sec 1.40k 171.05 2.25k 80.83%
416766 requests in 30.04s, 72.26MB read
Socket errors: connect 0, read 3990, write 0, timeout 0
Non-2xx or 3xx responses: 12779
Requests/sec: 13874.51
你可以看到结果中平均耗时减少了,从原来的 76.96 变成了 71.31,其次增加了 503 的返回量,原来是 0 现在是 12779,在 scoket 超时方面还是基本一致的。因此在实际情况,我们需要根据业务以及机器的配置来选择这几个参数的配置,具体的关系就是我上面所提到的。随着并发越来越高,如果没有负载保护用户的处理时长会越来越长,但是有了负载保护就可以避免雪崩现象,从而保护服务器可以正常地提供服务。















 1973
1973











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









