






先给出框架:(data+models在文章末都有链接)

word2vec
##W2vSenTest.py##
#Call the word2vec function for word embedding
# 深度学习模型框架
from gensim.models import word2vec
# 分词常用工具
import jieba
# 深度学习框架 包含许多库函数以及基础模型
import torch
from torch.nn.functional import cosine_similarity
s1 = '水果中很多对人有好处,比如苹果'
s2 = '外国手机有很多都不错,比如苹果'
s3 = '水果中很多对人有好处,比如苹果'
s4 = '我喜欢在饭吃不同水果,比如苹果'
# 句子集合
sens = [s1, s2, s3, s4, s1, s2, s3, s4]
# 加载停用词
with open('../data/w2v_stopwords.txt', 'r', encoding='utf-8') as f:
stopwords = [line.strip() for line in f.readlines()]
# 保存所有的词汇
words_all = []
# 文本预处理
for s in sens:
# 利用jieba库给每一句分词
words = jieba.lcut(s)
temp = []
for wd in words:
if wd not in stopwords:
temp.append(wd)
#将每一句变为有效词的列表
words_all.append(temp)
# 调用Word2Vec词向量模型
#Word2Vec(vocab=12(words_all一共有几个不同的词), vector_size=100, alpha=0.025)
#这里的min_count=1,是指忽略所有频率低于这个值的词,目的是关注高频词,由于这里我们只是测试一句,就把所有的词都取到
model = word2vec.Word2Vec(words_all, min_count=1)
vecs = []
for s in words_all:
vs = []
for wd in s:
#将词转变为100维的张量
v = model.wv[wd]
#存下一句话的词的张量vs=[[词1的100维][词2的100维][].....]
vs.append(v)
#vecs存下所有句子的每一句的张量[vs1,vs2,..,vs8]
vecs.append(vs)
all_s = []
#这一步是将句子(假设有n个词)的n*100维张量,统一为1*100维张量,将每一列的值对应相加然后取平均值
for v in vecs:
s1 = []
for i in v:
if len(s1) == 0:
s1 = i
else:
s1 = s1 + i
all_s.append(s1 / len(v))
#计算句子的余弦相似度和欧氏距离
sim1 = cosine_similarity(torch.from_numpy(all_s[0]).view(1, -1),
torch.from_numpy(all_s[1]).view(1, -1))
sim2 = cosine_similarity(torch.from_numpy(all_s[2]).view(1, -1),
torch.from_numpy(all_s[3]).view(1, -1))
odis = torch.nn.PairwiseDistance(p=2)
odis_sen1 = odis(torch.from_numpy(all_s[0]).view(1, -1),
torch.from_numpy(all_s[1]).view(1, -1))
odis_sen2 = odis(torch.from_numpy(all_s[2]).view(1, -1),
torch.from_numpy(all_s[3]).view(1, -1))
print('句子1和句子2的相似度是:{}'.format(sim1.item()))
print('句子3和句子4的相似度是:{}'.format(sim2.item()))
print('句子1和句子2的欧式距离是:{}'.format(odis_sen1.item()))
print('句子3和句子4的欧氏距离是:{}'.format(odis_sen2.item()))
Bert
##BertSenTest.py##
#
import torch
from pytorch_pretrained_bert import BertTokenizer, BertModel
from sklearn.metrics.pairwise import cosine_similarity
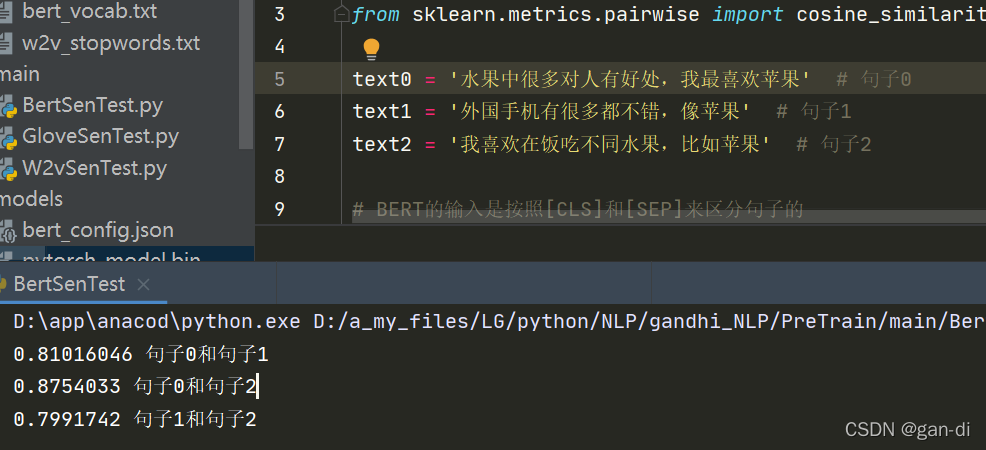
text0 = '水果中很多对人有好处,我最喜欢苹果' # 句子0
text1 = '外国手机有很多都不错,像苹果' # 句子1
text2 = '我喜欢在饭吃不同水果,比如苹果' # 句子2
# BERT的输入是按照[CLS]和[SEP]来区分句子的
marked_text0 = '[CLS]' + text0 + '[SEP]'
#'[CLS]水果中很多对人有好处,比如苹果[SEP]'
marked_text1 = '[CLS]' + text1 + '[SEP]'
marked_text2 = '[CLS]' + text2 + '[SEP]'
tokenizer = BertTokenizer('../data/bert_vocab.txt') # 加载你的预训练字表地址 21128个字
tokenized_text0 = tokenizer.tokenize(marked_text0)
# 将输入按照BERT的处理方式进行分割,(17个)['[CLS]', '水', '果', '中', '很', '多', '对', '人', '有', '好', '处', ',', '比', '如', '苹', '果', '[SEP]']
tokenized_text1 = tokenizer.tokenize(marked_text1)
tokenized_text2 = tokenizer.tokenize(marked_text2)
indexed_tokens = tokenizer.convert_tokens_to_ids(tokenized_text0)
# 将字符映射到id,(17个)[101, 3717, 3362, 704, 2523, 1914, 2190, 782, 3300, 1962, 1905, 8024, 3683, 1963, 5741, 3362, 102]
indexed_tokens1 = tokenizer.convert_tokens_to_ids(tokenized_text1)
indexed_tokens2 = tokenizer.convert_tokens_to_ids(tokenized_text2)
# segment_id是用来区分句子的,这里我们的输入是一句话一句话的输入,所以都标成1即可。
segments_ids = [1] * len(tokenized_text0)
#(17)[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
segments_ids1 = [1] * len(tokenized_text1)
segments_ids2 = [1] * len(indexed_tokens2)
# 将indexed_tokens和segments_ids从列表转换成张量的形式作为输入
tokens_tensor = torch.tensor([indexed_tokens])
segments_tensors = torch.tensor([segments_ids])
tokens_tensor1 = torch.tensor([indexed_tokens1])
segments_tensors1 = torch.tensor([segments_ids1])
tokens_tensor2 = torch.tensor([indexed_tokens2])
segments_tensors2 = torch.tensor([segments_ids2])
# 加载预训练模型地址,该地址下——两个文件分别是bert_config.json,pytorch_model.bin不能改变名字
model = BertModel.from_pretrained('../models')
model.eval() # 这里是验证模型,可以节省很多不必要的反向传播
with torch.no_grad(): # 将输入传入模型,得到每一层的输出信息,
# 这里的encoded_layers为12层,每一层有17(第一,二,三句话有17个字)列表,每一个列表是768维,即12*1*17*768
encoded_layers, _ = model(tokens_tensor, segments_tensors)
with torch.no_grad():
encoded_layers1, _ = model(tokens_tensor1, segments_tensors1)
with torch.no_grad():
encoded_layers2, _ = model(tokens_tensor2, segments_tensors2)
# print(len(encoded_layers))
batch_i = 0 # 因为我们就输入一句话,所以batch的批大小为1,从0开始索引
token_embeddings = []
for token_i in range(len(tokenized_text0)): # 这里是将一句话中每个字符的每一层信息添加到token_embedding集合中
hidden_layers = []
for layer_i in range(len(encoded_layers)):
vec = encoded_layers[layer_i][batch_i][token_i]
#vec 为768维的张量
hidden_layers.append(vec)
#hidden_layers1*12*768
token_embeddings.append(hidden_layers)
#token_embeddings 17*1*12*768
token_embeddings1 = []
for token_i in range(len(tokenized_text1)):
hidden_layers1 = []
for layer_i in range(len(encoded_layers1)):
vec = encoded_layers1[layer_i][batch_i][token_i]
hidden_layers1.append(vec)
token_embeddings1.append(hidden_layers1)
#token_embeddings1 17*1*12*768
token_embeddings2 = []
for token_i in range(len(tokenized_text2)):
hidden_layers2 = []
for layer_i in range(len(encoded_layers2)):
vec = encoded_layers2[layer_i][batch_i][token_i]
hidden_layers2.append(vec)
token_embeddings2.append(hidden_layers2)
#token_embeddings2 17*1*12*768
# 有了一句话的每一层输出信息后,我们可以制定如何去拼接这些信息,这里我们选择将最后四层输出层的信息想加
#得到了17*768维的张量
summed_last_4_layers = [torch.sum(torch.stack(layer)[-4:], 0) for layer in token_embeddings]
summed_last_4_layers1 = [torch.sum(torch.stack(layer)[-4:], 0) for layer in token_embeddings1]
summed_last_4_layers2 = [torch.sum(torch.stack(layer)[-4:], 0) for layer in token_embeddings2]
all_sentence_sdim = [summed_last_4_layers,summed_last_4_layers1,summed_last_4_layers2]
#将17*768 -->1*768,确保不同长度的句子也可以计算相似度
all_sentence_unify = []
for sen in all_sentence_sdim:
sen_value = 0
for i in range(len(sen)):
sen_value += sen[i]
all_sentence_unify.append(sen_value/len(sen))
#计算句子的余弦相似度
print(cosine_similarity(all_sentence_unify[0].reshape(1, -1), all_sentence_unify[1].reshape(1, -1))[0][0], '句子0和句子1')
print(cosine_similarity(all_sentence_unify[0].reshape(1, -1), all_sentence_unify[2].reshape(1, -1))[0][0], '句子0和句子2')
print(cosine_similarity(all_sentence_unify[1].reshape(1, -1), all_sentence_unify[2].reshape(1, -1))[0][0], '句子1和句子2')
运行结果:

资料(data+models)
链接:https://pan.baidu.com/s/1m0Ua95JP-NbcEu9umegAIg
提取码:2933
















 6280
6280











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











