







MAE—reflacx
问题
问题一 === 对数据集reflacx的了解
reflacx (Reports and Eye-tracking data For Localization of Abnormalities in Chest X-rays) 数据集是一个专门用于医学影像分析的公开数据集,特别是胸部X光片的自动化分析。该数据集提供高质量的X光片影像,并附有详细的医学注释,旨在推动深度学习在医学影像中的应用和发展。
来看一下reflacx.json文件
...
{
"study_id": "34cedb74-d0996b40-6d218312-a9174bea-d48dc033",
"image_path": "files/p18/p18111516/s55032240/34cedb74-d0996b40-6d218312-a9174bea-d48dc033.jpg",
"report": "support apparatus. no pneumothorax. enlarged cardiac silhouette. no pulmonary consolidation or acute airspace disease.",
"reflacx_id": "P102R108387"
},
...
可以看到这个注释文件的标签有study_id、image_path、report、reflacx_id四类。注意我们现在这个任务只需要使用这些图片,image_path就是我们要使用的东西
问题二 === MAE实现的是有监督,还是无监督任务
MAE是一种自监督学习方法
自监督学习是一种无监督学习的变种,它利用数据自身生成的标签来进行训练,而不需要人工标注的数据。这种方法在图像、文本等领域应用广泛,常用于预训练模型,使其在后续的有监督任务(如分类、检测等)中表现更好。MAE通过遮盖输入数据的一部分,然后训练模型重建被遮盖部分,从而学习数据的内部表示。以下是MAE的具体工作流程:
- 数据遮盖:随机遮盖输入数据的一部分。例如,在图像任务中,可以随机遮盖图像的一些区域。
- 编码器:将遮盖后的数据输入编码器,编码器提取剩余部分的特征。
- 解码器:将编码器的输出输入解码器,解码器尝试重建被遮盖的数据部分。
- 损失函数:计算重建部分与原始数据之间的差异(如均方误差,MSE),并反向传播更新模型参数。
通过上述步骤,MAE在训练过程中学习如何从部分数据中恢复整体数据,从而捕获数据的全局特征和结构。
MAE方法最初是在图像领域提出的,例如用于图像分类任务的预训练。在这类任务中,MAE通过遮盖部分图像像素,并训练模型重建被遮盖部分,从而学习图像的有效表示。预训练后的模型可以迁移到下游的有监督任务中,通常能显著提高这些任务的性能。
总的来说,
MAE是一种自监督学习方法,属于无监督学习范畴。通过数据遮盖和重建任务,MAE能够在没有人工标注的情况下学习数据的有效表示。这种方法在需要大量数据预训练的任务中表现尤为突出,可以为后续的有监督任务提供强大的特征表示。
问题三 === 实验流程
- 从github上fork我师兄的项目 (30min)
- 创建一个虚拟环境 (1h)
- 根据模板来编写我们的MAE—reflacx (4h)
- 在集群上运行 (24h)
问题四 === 实验目的
得到自监督的预训练模型参数文件 (XXX.pth)
一、从github上fork我师兄的项目30min(github账号的注册什么的,可以去参考b站)
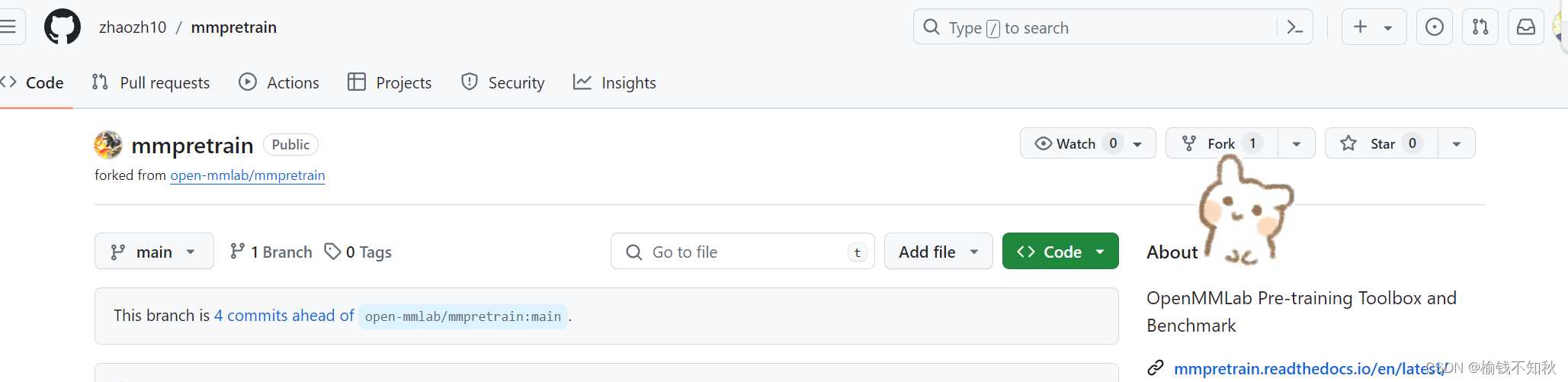
1.1 点开下面这个链接
1.2 看到页面的上方,跟随我们的小兔子fork一下
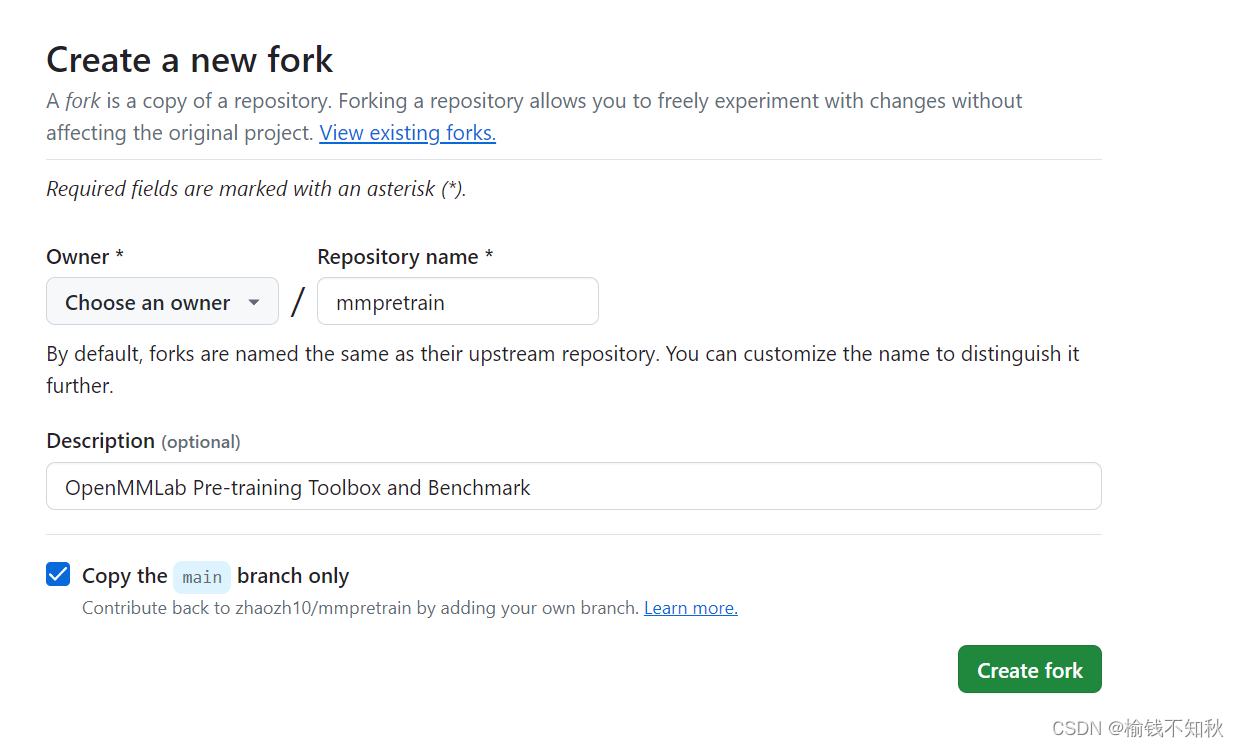
1.3 根据这个指引,填好之后,点击绿色的Create fork
1.4 然后点击右上角自己的头像,点开 Your repositories(你的仓库)
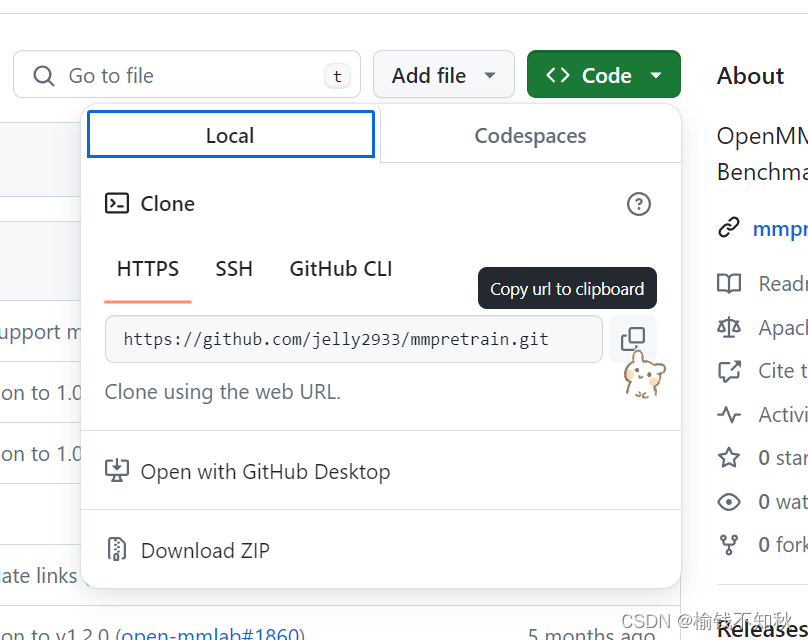
1.5 点击蓝色的mmpretrain项目,然后点击这个绿色的code,点击如下复制键
把这个链接记下来,待会儿要用。
我的是:
https://github.com/jelly2933/mmpretrain.git
二、创建一个虚拟环境 (1h)
2.1 根据下面的链接学习如何创建环境
先看一下所有的操作,2.2会详细地展示
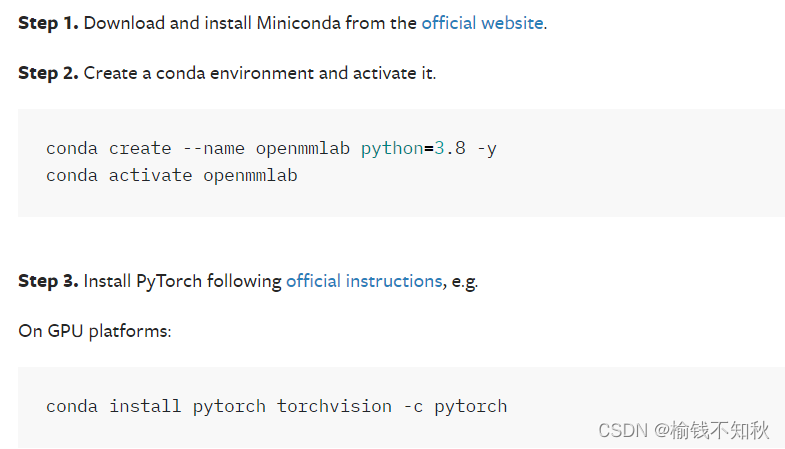
下,先运行一下 cd ~ 回到家目录,然后依次执行下面的命令

- 去B站学习一下安装miniconda,最好是在家目录下创建一个software文件夹,再安装miniconda。
cd ~conda create --name mmlab python=3.10 -yconda activate mmlab- 这里要安装pytorch,有一些讲究,要去官网选择版本
这是我的选择,感觉这个版本还是比较稳定的

pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
要是下载比较慢,可以多试几次,下面是可以加上aliyun镜像的版本,不建议这个,因为可能会下载成cpu版本的,到时候有点麻烦。
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118 -i https://mirrors.aliyun.com/pypi/simple/
6.注意,这里要使用到1.5记下来的链接,把下面的链接替换为你复制的链接
git clone https://github.com/jelly2933/mmpretrain.git
cd mmpretrainpip install -U openmim && mim install -e . -i https://mirrors.aliyun.com/pypi/simple/- 太棒了,你成功创建了mmlab环境,喝口水吧。
三、根据模板来编写我们的MAE—reflacx (3h)
在mmpretrain文件夹下,可以看到超多文件,不要随便改动尤其是别删除,我们根据他给的文件,添加文件,来实现我们的功能。
3.1 读取reflacx数据集
定位到mmpretrain文件夹下
cd ~/mmpretrain/
- 根据下图依此点开mmpretrain -> mmpretrain -> dataset。注意根目录是的mmpretrain
- 先看__init__.py文件
看到白色框框里面的,是我们将“Reflacx”类型的数据做好了注册,等下可以使用dataset_type = “Reflacx”这个语句。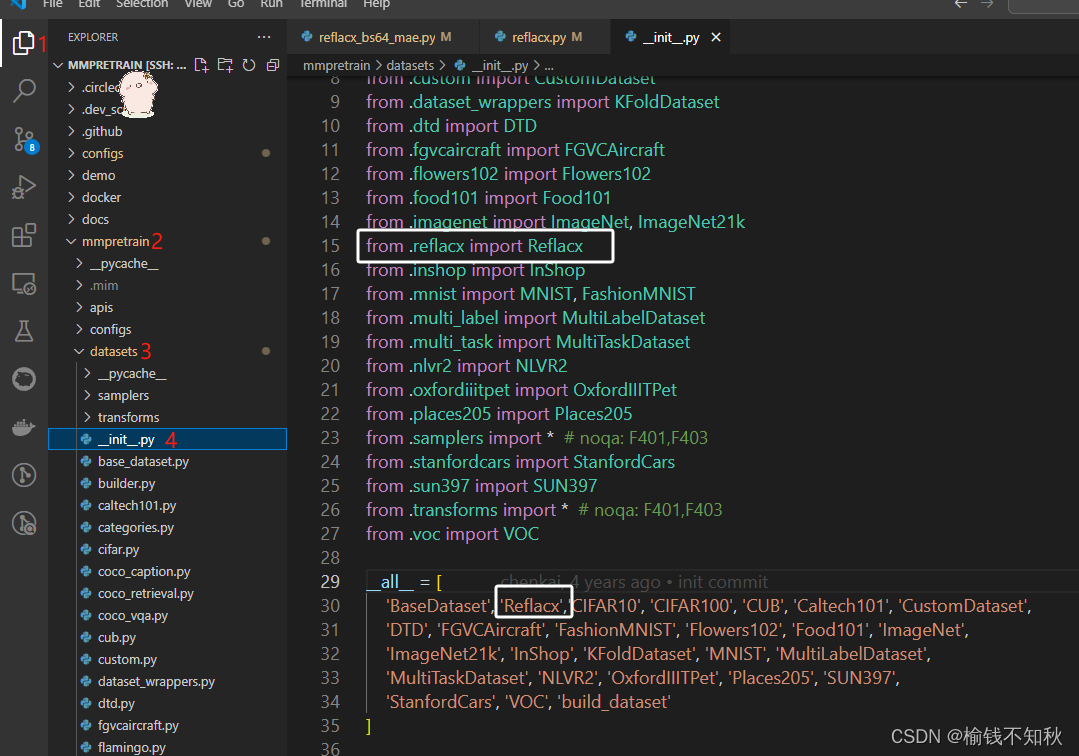
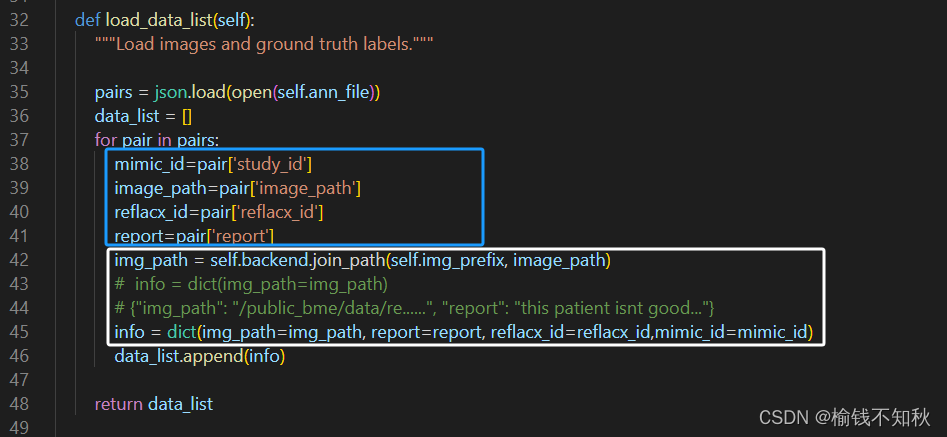
3. 接下来找到reflacx.py
重点关注load_data_list()这个函数,蓝色框里面就是用来读取我们数据的json文件的语句,白色框里是比较关键的读取图片的路径,上面我已经提到MAE是自监督方法,不需要标注信息,这里的info可以只使用绿色的第一句,我们只要获得这个图片就可以。
3.2 编写base文件
根目录是mmpretrain,依此点开configs -> _base_ 。
- datasets文件
- 先点开datasets,创建reflacx_bs64_mae.py文件
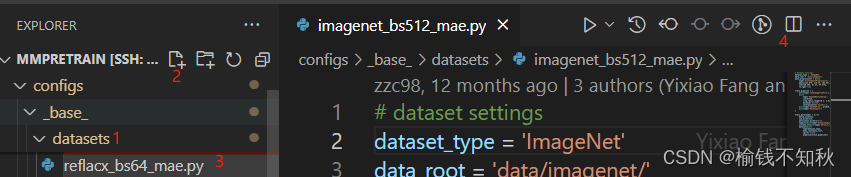
- 找到我们准备模仿的imagenet_bs512_mae.py文件,将imagenet_bs512_mae.py文件copy到reflacx_bs64_mae.py中
第一个白色框是我们根据reflacx改动的,第二个白色框是将batch_size改小一点为64,加载数据的子进程数量num_workers改为4。
黄色框是我们要删除的部分,因为所使用的reflacx数据集并没有划分训练集。
绿色框部分是imagenet数据集的像素均值和标准差,这里我们没有计算reflacx数据集的,是可以计算之后替换掉的部分,或许2.0版本。
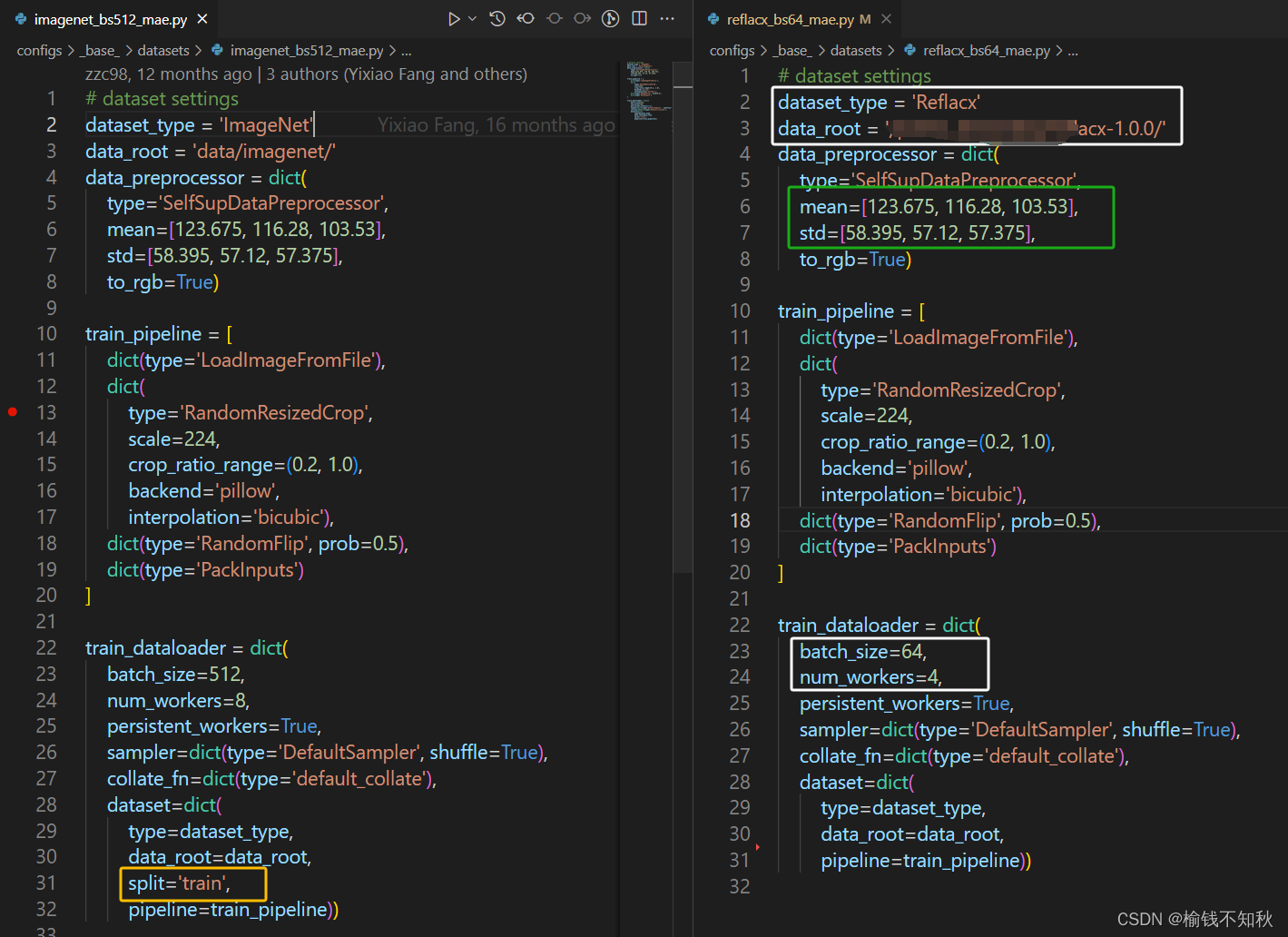
- models文件
- 先点开models,打开mae_vit-base-p16.py文件
黄色框为我们添加的部分,这里要加载一个模型的参数。
- 在bash依次运行
cd ~
mkdir preTrain
cd preTrain
wget https://download.pytorch.org/models/vit_b_16-c867db91.pth
ls

看到这个.pth文件,说明下载好了参数
回到mmpretrain下
cd ~/mmpretrain/
3.接下来就还剩一个文件的编写了,真棒,喝口水吧~
3.3 mae模型文件
根目录是mmpretrain,依此点开configs -> mae 。
-
创建一个mae_vit-base-p16_1xb64-amp-coslr-400e_reflacx.py文件,打开mae_vit-base-p16_8xb512-amp-coslr-400e_in1k.py文件,将里面的内容复制到mae_vit-base-p16_1xb64-amp-coslr-400e_reflacx.py。
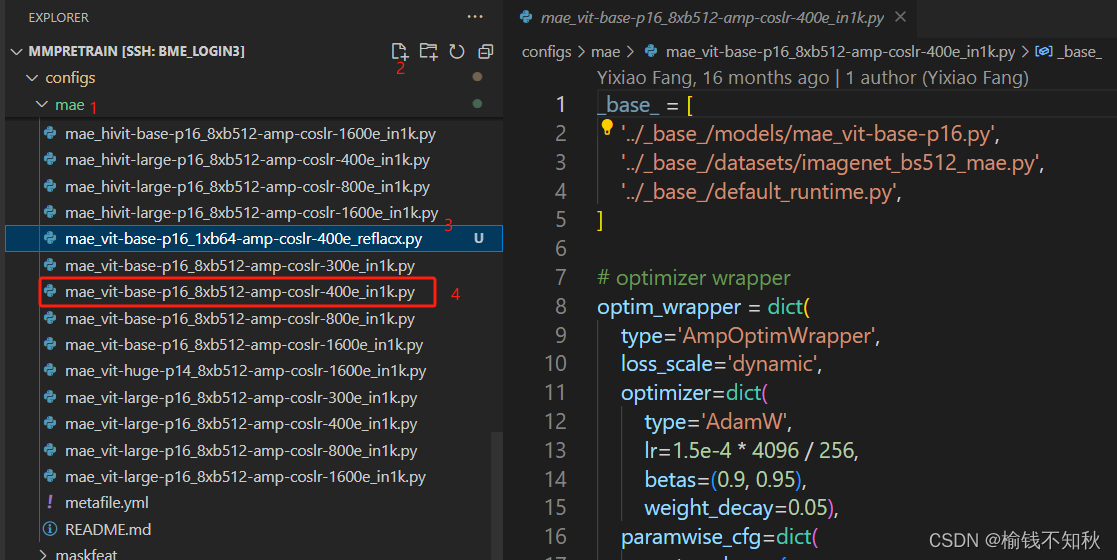
2.同时打开 mae_vit-base-p16_1xb64-amp-coslr-400e_reflacx.py和mae_vit-base-p16_8xb512-amp-coslr-400e_in1k.py第一个白色框,是我们在3.2做的改动,通过datasets/reflacx_bs64_mae.py,我们可以batchsize=64使用reflacx数据集;通过models/mae_vit-base-p16.py我们添加了vit_b_16-c867db91.pth模型参数。
第二个白色框,将学习率改为比较常用的1e-3

白色框是修改为每隔一百轮保存一次模型,最多保存400个模型参数文件,即.pth文件;
每隔10轮打印一次输出信息;
黄色框为删除的部分。
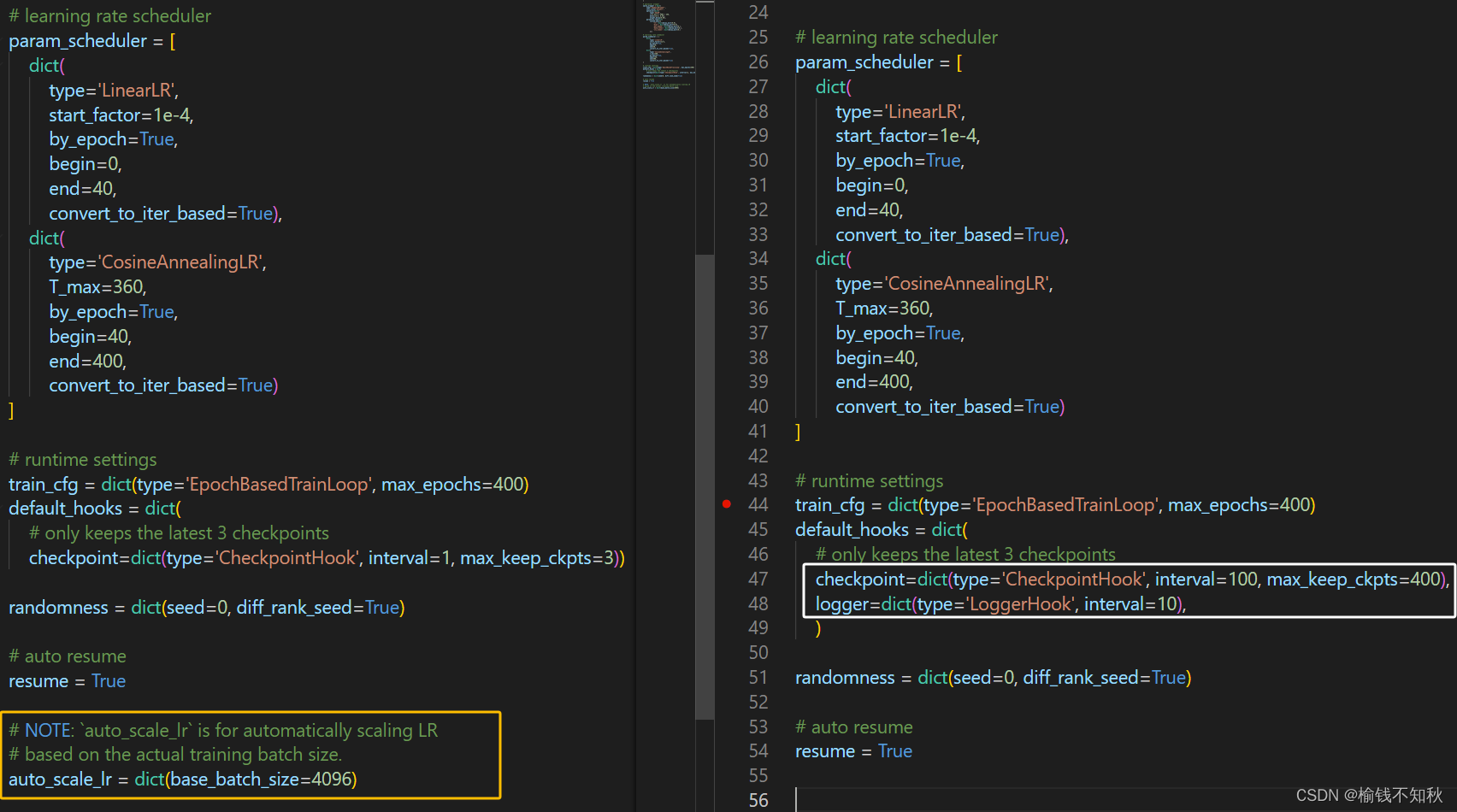 3.到此,要添加的内容就完成了!!
3.到此,要添加的内容就完成了!!
四、在集群上运行 (24h)
根目录是mmpretrain,点开tools 。
4.1 新建.sh文件,slurm集群管理版本
这里命名为bme_train.sh
#!/usr/bin/env bash
#SBATCH -p bme_gpu
#SBATCH --job-name=selfsup_reflacx
#SBATCH --nodes=1
#SBATCH --gres=gpu:1
#SBATCH --mem=64G
#SBATCH --ntasks-per-node=1
#SBATCH --cpus-per-task=4
#SBATCH -t 5-00:00:00
set -x
CONFIG=$1
PY_ARGS=${@:2}
source activate mmlab
nvidia-smi
PYTHONPATH="$(dirname $0)/..":$PYTHONPATH \
python -u tools/train.py ${CONFIG} --launcher="slurm" ${PY_ARGS}
# PYTHONPATH="$(dirname $0)/..":$PYTHONPATH OMP_NUM_THREADS=4 python -u tools/train.py ${CONFIG} --launcher="slurm" ${PY_ARGS}
# PYTHONPATH="$(dirname $0)/..":$PYTHONPATH python -u tools/train.py ${CONFIG} --launcher="slurm" ${PY_ARGS}
# gpu:1
# gpu:NVIDIAA10080GBPCIe:1#
4.2 bash运行
cd ~/mmpretrain
sbatch tools/bme_train.sh configs/mae/mae_vit-base-p16_1xb64-amp-coslr-400e_reflacx.py
4.3 运行中途打印的信息与最后得到的.pth文件
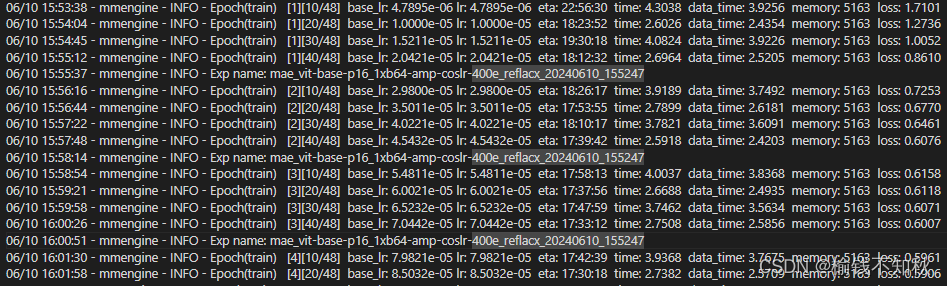

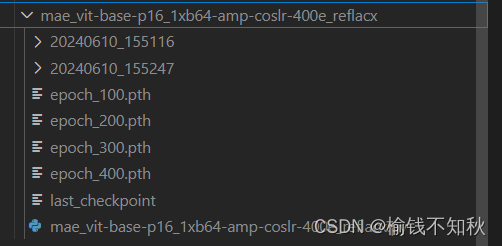
得到的epoch_400.pth可以用作预训练模型参数啦,下一步就是评估这个模型参数。
多多点赞,会变好看!!
















 1298
1298

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











