






现着手于一个预训练任务,看了MAE论文的,又看到今年的SiamMAE,但是作者未开源,但是结构并不负责,尝试复现。
SiamMAE是在MAE上做的优化,本人就再MAE基础上做复现任务。
先看下这两个网络结构如下图:
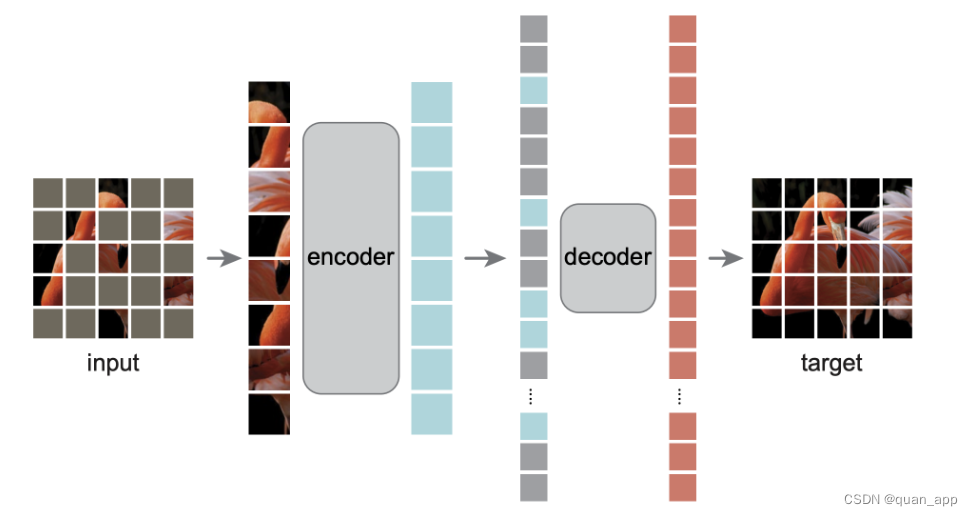
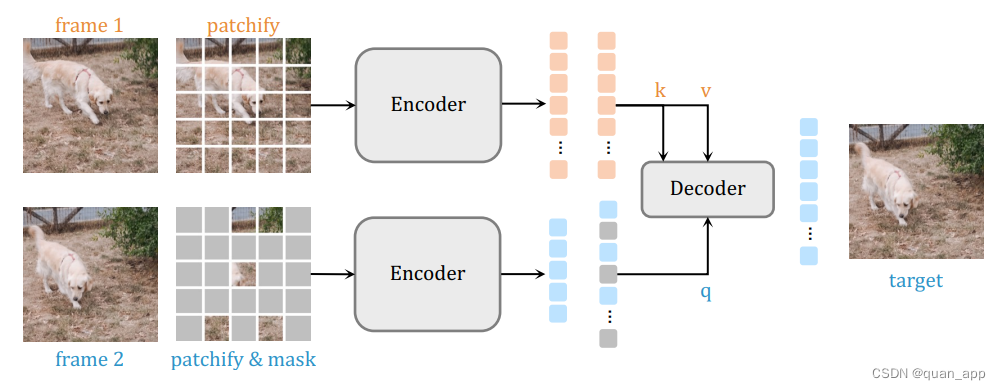
由架构可以看出,SiamMAE相较于MAE在第二分支非常接近,只是Decoder方式有变化。论文中使用的是cross_decoder。接下来,我们就开始吧
1.首先MAE git下来。
2.论文中第一分支和第二分支为视频中两帧前后照片,第一分支和第二分支都采取vit的套路,先patch_embed,MAE代码中也是比较清晰
def forward_features(self, x, mask):
x = self.patch_embed(x)
# cls_tokens = self.cls_token.expand(batch_size, -1, -1)
# x = torch.cat((cls_tokens, x), dim=1)
x = x + self.pos_embed.type_as(x).to(x.device).clone().detach()
B, _, C = x.shape
x_vis = x[~mask].reshape(B, -1, C) # ~mask means visible
for blk in self.blocks:
x_vis = blk(x_vis)
x_vis = self.norm(x_vis)
return x_vis
def forward(self, x, mask):
x = self.forward_features(x, mask)
x = self.head(x)
return x论文中提到使用的是共享权值的encoder,所以此处可直接使用MAE的encoder,由于MAE是单分支的,这里需要更改modeling_pretraining.py代码,将网络中间稍作修改。
def forward(self, m, m_mask, x, mask):
# x_after进入encoder,再线性层拉伸维度
x_after = self.encoder(x, mask) # [B, N_vis, C_e]
x_after = self.encoder_to_decoder(x_after) # [B, N_vis, C_d]
# m_before进入encoder, 再线性层拉伸维度
m_before = self.encoder(m, m_mask)
m_before = self.encoder_to_decoder(m_before)此处带入一个实例,假设我的图片输入为[1, 3, 512, 512],则在encoder后,第一分支输出即为[1, 1024, 768]
我的切窗大小为16*16,即划分32*32=1024个patch, c为16*16*3=768
而第二个分支encoder的输入为未被掩码的patch,这里我没有按照论文的95%掩码率,使用的仍是MAE原始的75%掩码率,即输入256个patch,输出不变,即[1, 256, 768]
3.decoder
在双分支都encoder后,就准备decoder,MAE在进入decoder之前做了线性层改变维度,因为decoder中的输入为384维度,我们之前encoder的输出为768维度。
self.encoder_to_decoder = nn.Linear(encoder_embed_dim, decoder_embed_dim, bias=False)
x_after = self.encoder_to_decoder(x_after)论文中这里的decoder跟mae中的不一样,使用的是cross_self decoder

此处找到了一篇关于这样的文章,并找到了相关代码
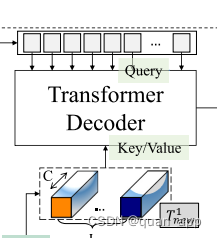
self.transformer_decoder = TransformerDecoder(dim=decoder_embed_dim, depth=decoder_depth,
heads=decoder_num_heads, dim_head=decoder_num_heads, mlp_dim=4*decoder_embed_dim, dropout=0,
softmax=True)
x_full = self.transformer_decoder(x_full, m_before)class TransformerDecoder(nn.Module):
def __init__(self, dim, depth, heads, dim_head, mlp_dim, dropout, softmax=True):
super().__init__()
self.layers = nn.ModuleList([])
for _ in range(depth):
self.layers.append(nn.ModuleList([
Residual2(PreNorm2(dim, Cross_Attention(dim, heads = heads,
dim_head = dim_head, dropout = dropout,
softmax=softmax))),
Residual(PreNorm(dim, FeedForward(dim, mlp_dim, dropout = dropout)))
]))
def forward(self, x, m, mask = None):
"""target(query), memory"""
m = nn.Linear()
for attn, ff in self.layers:
x = attn(x, m, mask = mask)
x = ff(x)
return x这里decoder后会产生[1, 1024, 384]维度的输出,这里我们跟原图label求一下损失,论文中使用的不是MAE的MSE损失函数,改成了L1损失,那么我们也改一下。
loss_func1 = nn.L1Loss()
with torch.cuda.amp.autocast():
# 模型中传入两条路径的两个输入图片,batch_image1为before,batch_image2为after
# bool_pos为before的掩码率为0,bool_masked_pos为after的掩码率为0.75
outputs = model(batch_image1, bool_pos, batch_image2, bool_masked_pos)
loss = loss_func(input=outputs, target=labels)最后我们要训练我们自己的数据集,文章中是图像重建任务,与MAE不同,输入端是两张图片,所以,dataset这边也需要改一下。
在dataset_folder.py中我们新建一个class,继承自ImageFolder,重写get_item方法,这就不多说啦,代码如下:
class customImageFolder(ImageFolder):
#复写image_folder, 返回两张图像
def __init__(self, root, transform=None):
super(customImageFolder, self).__init__(root, transform)
def __getitem__(self, index1):
path1 = self.imgs[index1][0] # 此时的self.imgs等于self.samples,即内容为[(图像路径, 该图像对应的类别索引值),(),...]
label1 = self.imgs[index1][1]
path_name = path1.split('/')
path2 = os.path.join(path_name[0], path_name[1], 'after', path_name[-1])
img1 = self.loader(path1)
img2 = self.loader(path2)
if self.transform is not None:
img1 = self.transform(img1)
img2 = self.transform(img2)
#print(img1, img2, label1, '11111111111111111')
return img1, label1, img2
def __len__(self) -> int:
return len(self.imgs)OK,大功告成,我们就开始训练我们的数据集啦
python run_mae_pretraining.py --data_path data/train/before --mask_ratio 0.75 --model pretrain_mae_base_patch16_224 --batch_size 10 --opt adamw --opt_betas 0.9 0.95 --warmup_epochs 5 --epochs 150 --output_dir output/pretrain_mae_base_patch16_224data_path就是数据集地址,mask_ratio就是掩码率,model就使用了默认的,就先跑个150轮吧,每5轮改变学习率策略。

这就开始训练了!















 3838
3838











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









