






筛选问题
问题:要根据时间的小时选取出一定时间范围内的数据
解决思路:通过pandas库中的loc()函数筛选出符合要求的数据
例:

要求选出在8-9点的数据,这里我们只需要将时间的小时数分割出来,保留为8和9的数据即可完成筛选
df['时间']= pd.to_datetime(df['时间'],errors='coerce')#将excel表中的时间转化成datatime型
df['小时'] = df['时间'].dt.hour.fillna(0).astype("int")#在表中添加一行小时数,从时间中切割出来
运行结果:
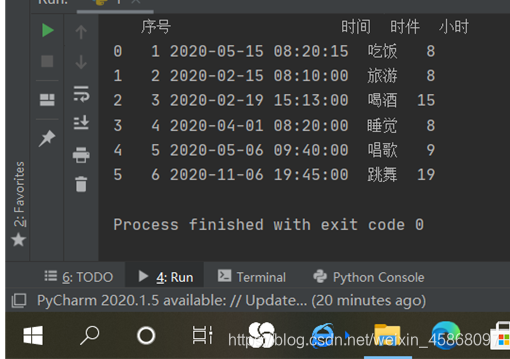
其实用df[‘时间’].dt.hour就可以实现切割出时间,其他类似dt.(year,month,day等)均可,前提是将时间类型转化成datatime类型,因为.dt.只能对datatime型进行处理,即不转化不能使用该方法。
#选出符合要求的数据
def month_rersev(a):
return a == 8 or a == 9
df = df.loc[df['小时'].apply(month_rersev)]#将表中按照符合要求的数据选出来
运行结果:

根据该列中时间数据分割出小时,再用loc()函数进行筛选,筛选到此已经完成了。
但是如何将修改后的符合要求的数据存储到表格中?接下来是存储过程中可能出现的小问题。
保存为新的excel表格
保存为新的excel表格我选择用.to_excel(‘路径.表名.xlsx’)函数,直接保存为一个新的excel表格,但是会出现不符合要求的情况,如,将前面运行结果的个数的序号也存入表格,时间存入之后显示为#号。
解决方案:
with pd.ExcelWriter(r'D:\data\biao6.xlsx',engine='openpyxl',datetime_format='YYYY/MM/DD HH:mm:ss')as writer:
df.drop('小时',axis=1).to_excel(writer,index=False)
这里使用ExcelWriter函数来规范化输入excel表格的日期时间格式,同时删掉前面为了筛选数据生成的‘小时’那列。
运行结果:

这里时间的输入依旧是#号,经过判断可知为单元格宽度不够导致显示全为#号,这里通过代码对单元格宽度进行设置
wb=load_workbook(r"D:\data\biao7.xlsx")
for sheetname in wb.sheetnames:
ws=wb[sheetname]
# 调整列宽
ws.column_dimensions['B'].width= 20
wb.save(r"D:\data\biao7.xlsx")#这里路径一定要和之前一样,要不然保存到其他地方去了
运行结果:

完整代码:
import pandas as pd
from openpyxl import load_workbook
from datetime import datetime
#选出符合要求的数据
def month_rersev(a):
return a == 8 or a == 9
df = pd.read_excel(r"D:\data\biao1.xlsx")
df['时间']= pd.to_datetime(df['时间'],errors='coerce')#将excel表中的时间转化成datatime型
df['小时'] = df['时间'].dt.hour.fillna(0).astype("int")#在表中添加一行小时数,从时间中切割出来
df = df.loc[df['小时'].apply(month_rersev)]
with pd.ExcelWriter(r'D:\data\biao7.xlsx',engine='openpyxl',datetime_format='YYYY/MM/DD HH:mm:ss')as writer:
df.drop('小时',axis=1).to_excel(writer,index=False)
wb=load_workbook(r"D:\data\biao6.xlsx")
for sheetname in wb.sheetnames:
ws=wb[sheetname]
# 调整列宽
ws.column_dimensions['B'].width= 20
wb.save(r"D:\data\biao7.xlsx")
参考博客:https://blog.csdn.net/weixin_39927799/article/details/111287345















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









