






1,首先搭建一个Springboot项目准备一个测试服务器
2,引入pom
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
他其中包括一些其他的包如果有冲突可以给他把冲突包去掉
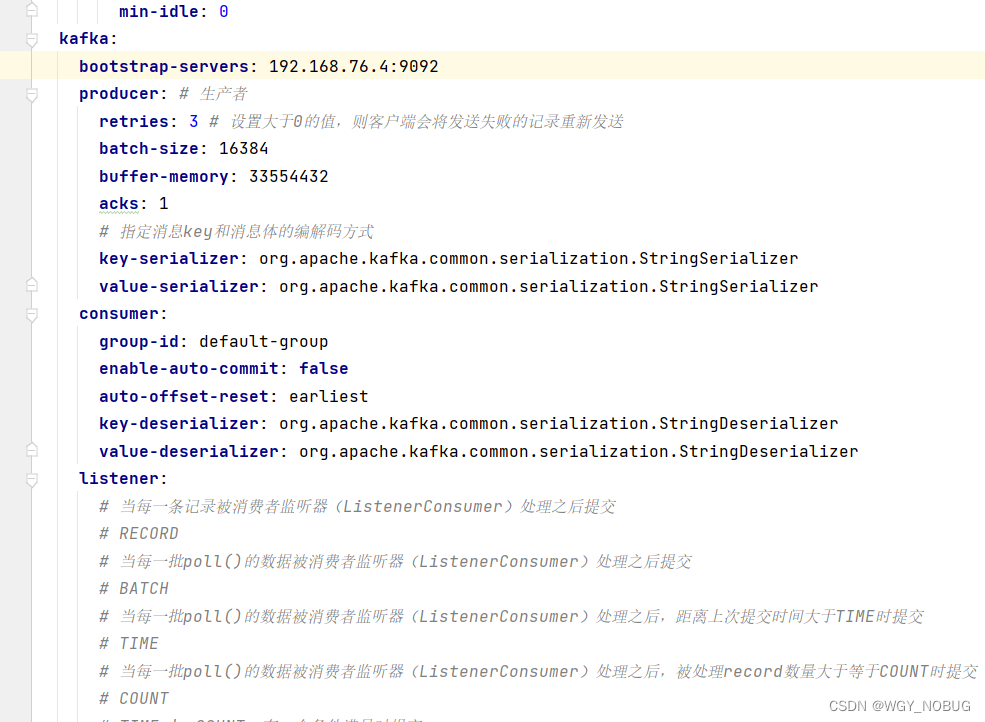
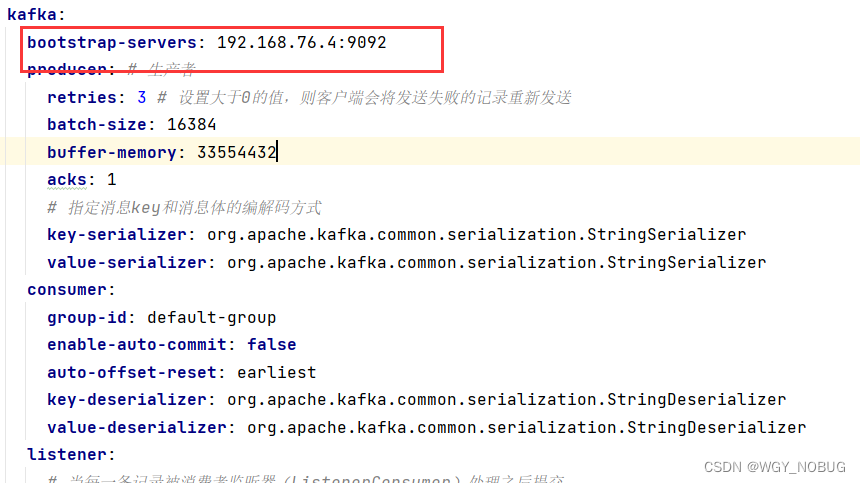
3,yml文件的配置:(如果有其他需求配置可百度kafka配置)
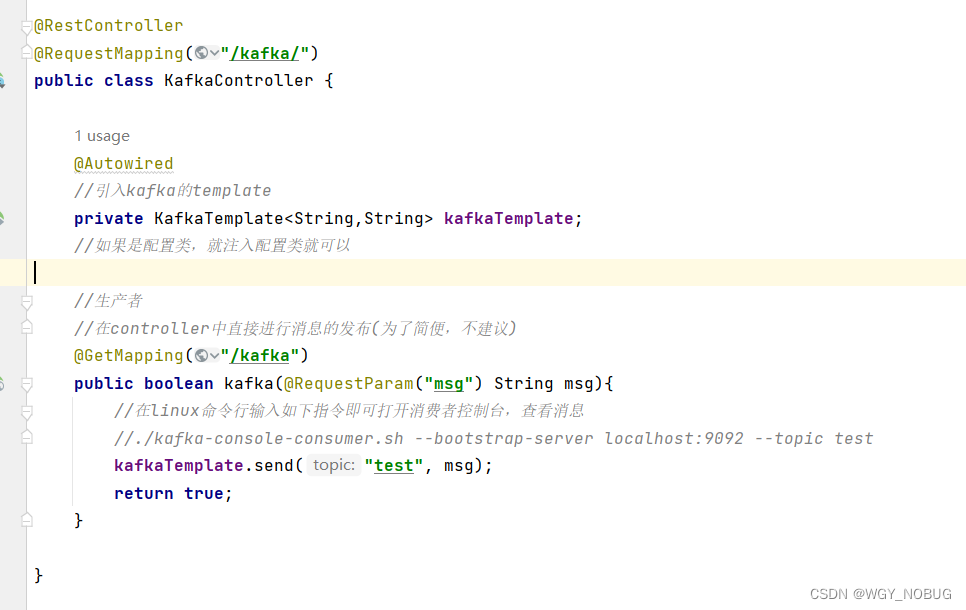
4,配置完成后就可以开始写生产者发送消息了,根据业务场景一般都会封装成方法然后调用不建议controller直接发送
4.1,首先引入kafka的template就像redis一样首相要有一个template才可继续,如果是自定义配置类也可以引入配置类进行操作,
KafkaTemplate<String,String> kafkaTemplate;
4.2,然后通过template的接口进行消息发送
如图:
5,有生产者就有消费者接下来写消费者:
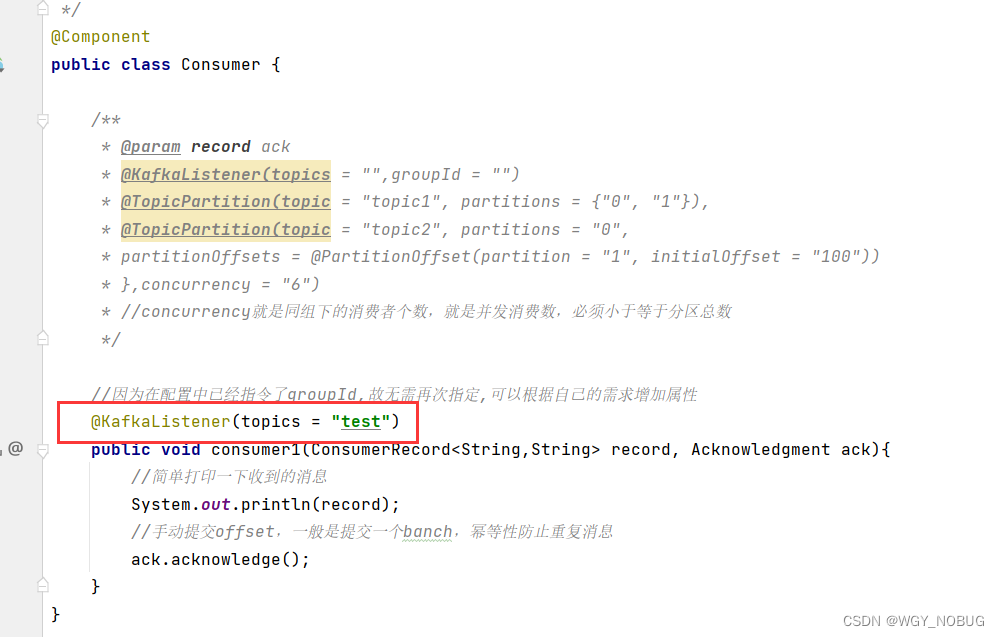
**注意点:**红框内的注解里面的topics是什么?(如果想查看更多配置请百度)
他就是主题名通过主题名找到对应的主题进行消息消费,也有分组的组名
groupid就是组名,看图:
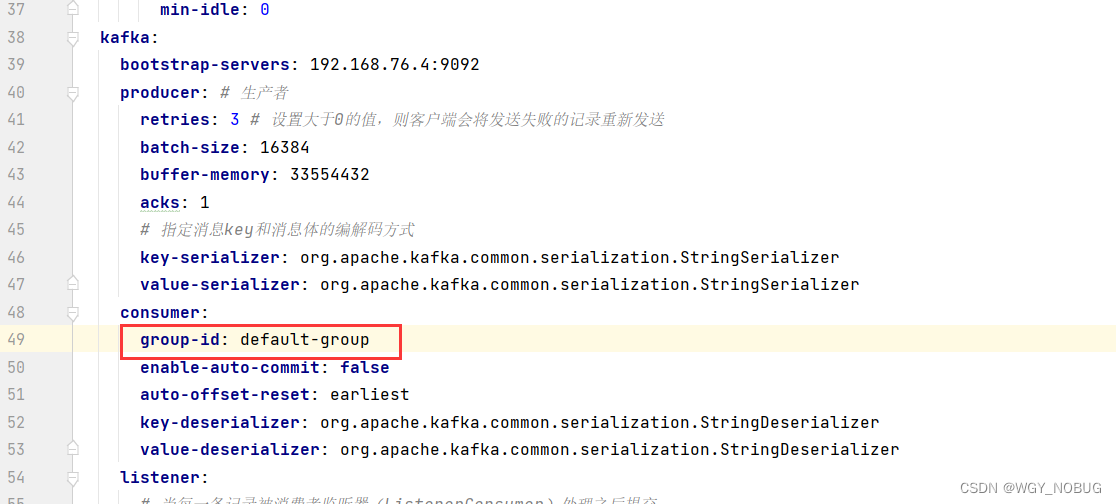
这个消息发送到哪里了:当然是这里配置的服务器了
打开linux会发现消息发送,并且消费成功

6,例子写到这里突然感觉似曾相识,这不和mq给我的是一个感觉吗,他们两个有什么区别?
kafka目前做数据分析,聚合,采集,流处理用的比较多所以明白了他的吞吐量为什么大了吗
1) 在架构模型方面,
Rabbitmq遵循AMQP协议。rabbitmq的代理由交换、绑定和队列组成,其中交换和绑定构成消息的路由密钥;客户端生产者通过连接通道与服务器通信,消费者从队列中获取消息以供消费(长连接,队列中的消息将被推送到消费者端,消费者循环从输入流中读取数据)。Rabbitmq以经纪人为中心;有一个消息确认机制。
kafka遵循一般的MQ结构,以制片人、经纪人和消费者为中心。消息的消费信息保存在客户端消费者上,消费者根据消费点从代理中批量提取数据;没有消息确认机制。
2) 在吞吐量方面,
Rabbitmq在吞吐量方面略低于卡夫卡。他们的出发点不同。Rabbitmq支持可靠的消息传递,支持事务,不支持批处理操作;根据存储可靠性的要求,存储可以是内存或硬盘。
kafka的吞吐量很高。它采用消息批处理和零拷贝机制。数据的存储和采集是本地磁盘的顺序批处理操作。它具有o(1)复杂性和消息处理的高效率。
3)在可用性方面,
rabbitMQ支持miror的,当主出现故障时,miror接管。
kafka的经纪人支持待机模式。
4)在集群负载均衡器方面,
rabbitMQ的负载平衡器需要单独的负载平衡器来支持。
Kafka使用zookeeper管理集群中的broker和consumer,可以向zookeeper注册主题;通过zookeeper的协调机制,生产者保存相应主题的broker信息,可以随机或轮询的方式发送给broker;并且生产者可以基于语义指定片段,消息被发送到代理的片段。
















 5672
5672











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











