







 该博客介绍了如何在PyTorch中从零开始实现一个简单的循环神经网络(RNN)。内容包括定义网络参数、初始化状态、前向传播函数以及RNN模型的构建。示例代码中展示了如何处理one_hot编码问题,以及张量转置的正确方法。此外,还给出了模型的训练输入数据和输出的形状。
该博客介绍了如何在PyTorch中从零开始实现一个简单的循环神经网络(RNN)。内容包括定义网络参数、初始化状态、前向传播函数以及RNN模型的构建。示例代码中展示了如何处理one_hot编码问题,以及张量转置的正确方法。此外,还给出了模型的训练输入数据和输出的形状。
在8.5节的循环神经⽹络的从零开始实现中
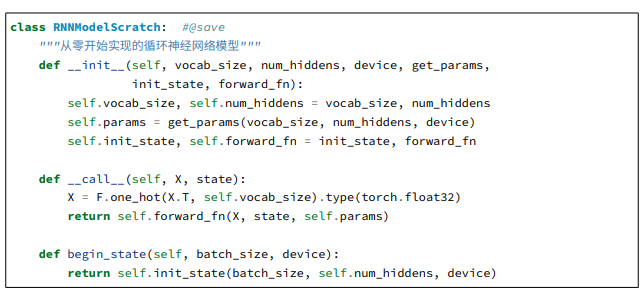
这个地方封装进行one_hot编码时候会报错- ‘Tensor’ object has no attribute ‘T’
应该是笔误或者版本迭代的问题,实际上pytorch并不支持直接用.T进行张量的转置,常用的方法有
tensor.t() or tensor.transpose(dim1,dim2)
更改后的整个RNN的从零实现的完整代码:
import math
import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
import numpy as np
batch_size, num_steps = 32, 35
train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps)
X = torch.arange(10).reshape((2, 5))
def get_params(vocab_size, num_hiddens, device):
num_inputs = num_outputs = vocab_size
def normal(shape):
return torch.randn(size=shape, device=device) * 0.01
# 隐藏层参数
W_xh = normal((num_inputs, num_hiddens))
W_hh = normal((num_hiddens, num_hiddens))
b_h = torch.zeros(num_hiddens, device=device)
# 输出层参数
W_hq = normal((num_hiddens, num_outputs))
b_q = torch.zeros(num_outputs, device=device)
# 附加梯度
params = [W_xh, W_hh, b_h, W_hq, b_q]
for param in params:
param.requires_grad_(True)
return params
def init_rnn_state(batch_size, num_hiddens, device):
return (torch.zeros((batch_size, num_hiddens), device=device),)
def rnn(inputs, state, params):
# `inputs`的形状:(`时间步数量`, `批量⼤⼩`, `词表⼤⼩`)
W_xh, W_hh, b_h, W_hq, b_q = params
H, = state
outputs = []
# `X`的形状:(`批量⼤⼩`, `词表⼤⼩`)
for X in inputs:
H = torch.tanh(torch.mm(X, W_xh) + torch.mm(H, W_hh) + b_h)
Y = torch.mm(H, W_hq) + b_q
outputs.append(Y)
return torch.cat(outputs, dim=0), (H,)
class RNNModelScratch: #@save
"""从零开始实现的循环神经⽹络模型"""
def __init__(self, vocab_size, num_hiddens, device, get_params, init_state, forward_fn):
self.vocab_size, self.num_hiddens = vocab_size, num_hiddens
self.params = get_params(vocab_size, num_hiddens, device)
self.init_state, self.forward_fn = init_state, forward_fn
def __call__(self, X, state):
X = F.one_hot(X.t(), self.vocab_size).type(torch.float32)
return self.forward_fn(X, state, self.params)
def begin_state(self, batch_size, device):
return self.init_state(batch_size, self.num_hiddens, device)
num_hiddens = 512
net = RNNModelScratch(len(vocab), num_hiddens, d2l.try_gpu(), get_params,init_rnn_state, rnn)
state = net.begin_state(X.shape[0],d2l.try_gpu())
Y, new_state = net(X.to(d2l.try_gpu()), state)
print(Y.shape)

















 7496
7496

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









