







ElasticSearch中什么是分片什么是副本
分片是ElasticSearch中最小的工作单元,之所以会分片是因为当一个索引中数据量太大时会影 响ES的检索效率,所以把一个大的索引拆成几个部分每个部分就是一个分片,当所有分片组合在一块时就是一个完整的索引数据。当在创建索引时不仅可以指定索引的分片数,还可以指定每个分片的副本数,副本不仅可以起到备份数据提高系统可靠性的作用还可以参与检索,计算数据,从而提高整体的检索效率;
1.默认情况下创建一个索引默认一个分片,一个副本;
2.创建索引时指定分片数及副本数(创建后分片数不能修改,副本数可以动态修改);
3.原则上分片和副本不要放在同一个节点上,避免一个节点宕机后分片和副本数据都丢失(ES默认会
异地存放分片和副本);
创建索引并指定该索引的分片数及副本数
# 创建名为"users"的索引指定该索引有3个分片,每个分片各有一个备份数
PUT /users
{
"settings":{
"number_of_shards":3,
"number_of_replicas":1
}
}更新索引的副本数
# 将"users"索引的副本数重创建时的1扩展为2
PUT /users/_settings
{
"number_of_replicas":2
}什么是“故障转移”(ES如何应对故障)
“故障转移”当集群只有一个节点时,分片和副本都在同一个节点上当系统发生故障时分片和副
本数据都会丢失,当新加入一个节点时,此时集群中有两个节点ES会自动将分片和副本重新
分配到这两个节点中,且遵循分片和副本异地保存(分片和副本不在同一个节点),此时当其中
某个节点宕机后,因分片和副本数据是异地保存所以ES仍然能正常提供服务;
什么是“水平扩容”提高吞吐量
“水平扩容”当正在运行中的ES应用“存储”或“计算”等资源紧张时,可以通过新增节点加入到集群中,当集群有了新节点加入时ES会自动将分片和副本重新分配到各个节点。假如原node1节点有10个分片,10个副本,现新加入节点后原node1节点所承载的分片数和副本数势必会减少,节点所承受的数据减少了,后续执行检索所消耗的资源也就相应减少了;
集群节点数与分片数副本数关系
假如集群中每个节点只存储1个分片,或者只存储一个副本,当集群节点数大于副本数加分片数
那么就有节点存储不到数据,这样就造成了服务器资源浪费,假如我们想扩容节点数超过副本
数加分片数,且多出来的节点也能存储数据提高系统吞吐量应该怎么做?
分片数在创建索引时就指定好且后续不能修改,分片的数目实际上确定的是这个“索引”最大能存储多少数据,但是“读”操作搜索和返回数据可以同时被分片或副本所处理,所以当你拥有越多的副本数时也将拥有越高的吞吐量。所以既然分片数目调整不了,但我们可以动态的调整“副本”数量。我们可以按需伸缩集群,在运行时动态调整我们的副本数;
路由计算与分片控制
什么是路由计算?(ES写入一条数据流程)
在ES集群中有多个节点,当写入一条数据时这条数据应该写在哪个节点的分片上?
路由计算规则:
# 路由计算规则
ES数据存储节点位置 = hash(id)%分片数
# 说明:
往ES写入数据时若没指定id,则ES会自动为这条数据生成一个id唯一键,当然你也可以在写入这条数据时为这条数据指定id;什么是分片控制?(ES查询数据流程)
用户可以访问任何一个节点获取数据,被访问的这个节点称之为协调节点,用户获取数据时并不一定是重协调节点上去获取的如果协调节点压力大,协调节点会把请求转发到其它节点去获取数据(负载均衡),一般分片控制采用的是“轮询机制”去找协调节点;
ElasticSearch集群数据写入流程

ElasticSearch集群数据写入流程:
1.客户端连接Node1节点(也可以连接任意节点);
2.提交写入请求至集群时根据数据的id进行Hash模以分片数得到数据存储的分片节点位置, 并进行“倒排索引”的建立;
3.将数据转发至计算出的分片节点并存储;
4.分片数据存储完毕后将数据发往分片对应“副本”节点进行存储;
5.“副本”所在节点数据存储完毕后反馈给分片节点,分片节点最终响用户存储完成;
ElasticSearch集群查询数据流程

ElasticSearch集群检索数据流程:
1.客户端发送请求到集群;
2.协调节点将“张三”进行分词,在“倒排索引”中分别获取到各单词的存储位置;
3.假如“张三”分词后的分片数据存放在P0分片;
4.此时协调节点并不一定重P0分片中取数据,协调节点会找到P0分片所有的“副本”,协调节点轮询分 片和所对应的所有副本节点看哪个节点资源压力小就重哪个节点上取数据达到一个“负载均衡”的 目的;
5.关于查询,计算,排序的这些数据都是落地在具体的节点分别去计算处理的,假如有多个节点同时在 并行处理这些数据,当有节点处理完成后将数据反馈给协调节点,当所有节点数据处理完毕后协 调节点收到所有的数据再进行一次整体的检索关联度排序等操作,最终将处理完成的数据反馈给 客户端;
正排索引&倒排索引
什么是正排索引?
| id(索引) | content(内容) |
| 1001 | My name is ZhangSan |
在传统关系型数据库中往往都是一个ID对应一行记录,我们把一个ID对应一行记录去检索数据的方式称为正向索引;假如我们要检索conten字端中包含"name"的数据,此时需要使用LIKE模糊查询的方式去检索数据,使用LIKE模糊查询会进行全表扫描速度是非常的慢;
什么是倒排索引?
| content(内容) | id(索引) |
| My | 1001 |
| name | 1001 |
| is | 1001 |
| Zhang | 1001 |
| San | 1001 |
倒排索引通过分词策略形成的“文字”,“单词”,“文章”之间的映射关系与词典顺序,我们称之为“倒排索引”;
将内容(关键词)与索引做绑定,假如还是检索content字段包含“name”的数据,此时在“倒排索引”表查询到name对应的索引为1001,则我们通过检索1001即可获取到“My name is ZhangSan”这条数据;
ElasticSearch写入记录耗时计算规则
规则:主分片延迟 + 并行写入副本的最大延迟
ES数据写入后才能被检索,如果把写入和检索看做一个整体去执行,写入耗时越久那么整体执行的时间也就越久;首先根据路由计算出数据存储在哪个节点的分片上;数据写入分片后再并行将数据写入到该分片的所有“副本”中;所以副本数并不是越多越好,因为副本越多出现写入某个副本耗时越长的概率越高;但在实际生产过程中往往都是选择牺牲效率(“写入耗时”)来保证数据安全性(“多个副本”);
ElasticSearch如何保证数据安全性(如何保证数据不会丢失)
ElasticSearch IK 分词器&配置扩展词典&配置远程扩展词典
IK分词器下载地址:https://github.com/medcl/elasticsearch-analysis-ik
记录写入时与记录查询时选择的分词粒度应一致;
基于数据库远程热更新词库
配置IK分词器
将下载好的IK分词器解压放入ES的plugins文件夹即可;注意ES与IK分词器有版本对应关系,若 版本对应不上启动ES会出现闪退问题;
ES两种分词粒度:
ik_max_word:对文本做最细粒度拆分
ik_smart:对文本做最粗粒度拆分
# 对文本做细粒度拆分
GET /_analyze
{
"text":"中国人你好",
"analyzer":"ik_max_word"
}
响应:
{
"tokens": [
{
"token": "中国人",
"start_offset": 0,
"end_offset": 3,
"type": "CN_WORD",
"position": 0
},
{
"token": "中国",
"start_offset": 0,
"end_offset": 2,
"type": "CN_WORD",
"position": 1
},
{
"token": "国人",
"start_offset": 1,
"end_offset": 3,
"type": "CN_WORD",
"position": 2
},
{
"token": "你好",
"start_offset": 3,
"end_offset": 5,
"type": "CN_WORD",
"position": 3
}
]
}
# 对文本做粗粒度拆分
GET /_analyze
{
"text":"中国人你好",
"analyzer":"ik_smart"
}
# 响应
{
"tokens": [
{
"token": "中国人",
"start_offset": 0,
"end_offset": 3,
"type": "CN_WORD",
"position": 0
},
{
"token": "你好",
"start_offset": 3,
"end_offset": 5,
"type": "CN_WORD",
"position": 1
}
]
}
配置扩展词典
为什么配置扩展词典:
当IK分词器中词典满足不了需求时(无法对“网络热词”进行准确拆词),我们希望对于某些特定的词按照我们的规则来分词,这时就需要我们自定义“扩展词典”;
如下:
“弗雷尔卓德”作为一个名词应该不能再进行分词,然而IK分词器不知道,故将其拆分成一个个单独的词;
# IK分词器无法知道这是一个完整的名词,故只有将这个名称分拆为一个个单词
GET /_analyze
{
"text":"弗雷尔卓德",
"analyzer":"ik_max_word"
}
响应:
{
"tokens": [
{
"token": "弗",
"start_offset": 0,
"end_offset": 1,
"type": "CN_CHAR",
"position": 0
},
{
"token": "雷",
"start_offset": 1,
"end_offset": 2,
"type": "CN_CHAR",
"position": 1
},
{
"token": "尔",
"start_offset": 2,
"end_offset": 3,
"type": "CN_CHAR",
"position": 2
},
{
"token": "卓",
"start_offset": 3,
"end_offset": 4,
"type": "CN_CHAR",
"position": 3
},
{
"token": "德",
"start_offset": 4,
"end_offset": 5,
"type": "CN_CHAR",
"position": 4
}
]
}配置“扩展词典”
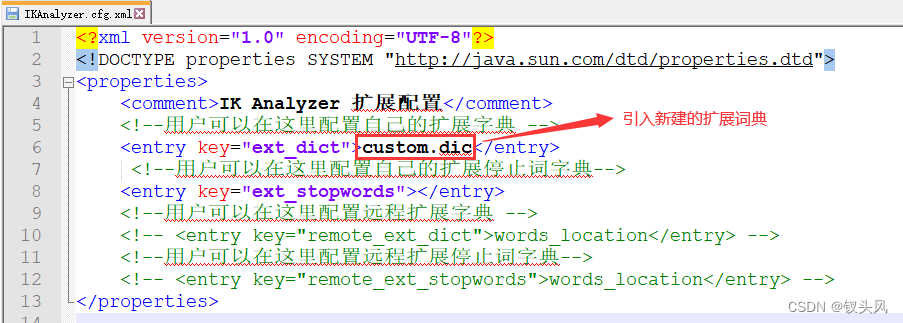
1.进入IK文件夹
2.进入config目录下新建custom.dic词典文件
3.进入custom.dic词典文件写入新的扩展词汇(例如:“弗雷尔卓德”)
4.进入config目录下的IKAnalyzer.cfg.xml文件,引入我们新建的扩展词典文件
5.重启ElasticSearch

再次测试对“弗雷尔卓德”名词的分词效果
# 自定义扩展词典后,再次检索“弗雷尔卓德”
GET /_analyze
{
"text":"弗雷尔卓德",
"analyzer":"ik_max_word"
}
响应:
{
"tokens": [
{
"token": "弗雷尔卓德",
"start_offset": 0,
"end_offset": 5,
"type": "CN_WORD",
"position": 0
}
]
}注意:
此方式在“扩展词典”中每次添加新的词汇需重启ES服务器才生效;故在生产环境中不推荐此种方式;














 1667
1667











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









