






1.为什么要在多线程并发中引入锁?
在多线程并发中引入锁的核心目的是为了解决共享资源竞争和执行顺序不确定性带来的问题。例如我现在有4个线程,每个线程的操作都是对变量a进行++,一共500次。如果不加锁的话,两个线程可能会同时对a进行操作,这时候加入a=10,经过两个线程操作后期望值为12,但是两个线程同时操作的话可能结果就为11(同时加1)。
2.互斥锁和自旋锁
互斥锁在线性运行时,其余线程会让出cpu,进入阻塞状态(其余线程也会先自旋一会,资源未就绪后进入阻塞态)。自旋锁在线程运行时,其余线程会一直自旋检测资源是否就绪,占用cpu
3.CPU缓存架构
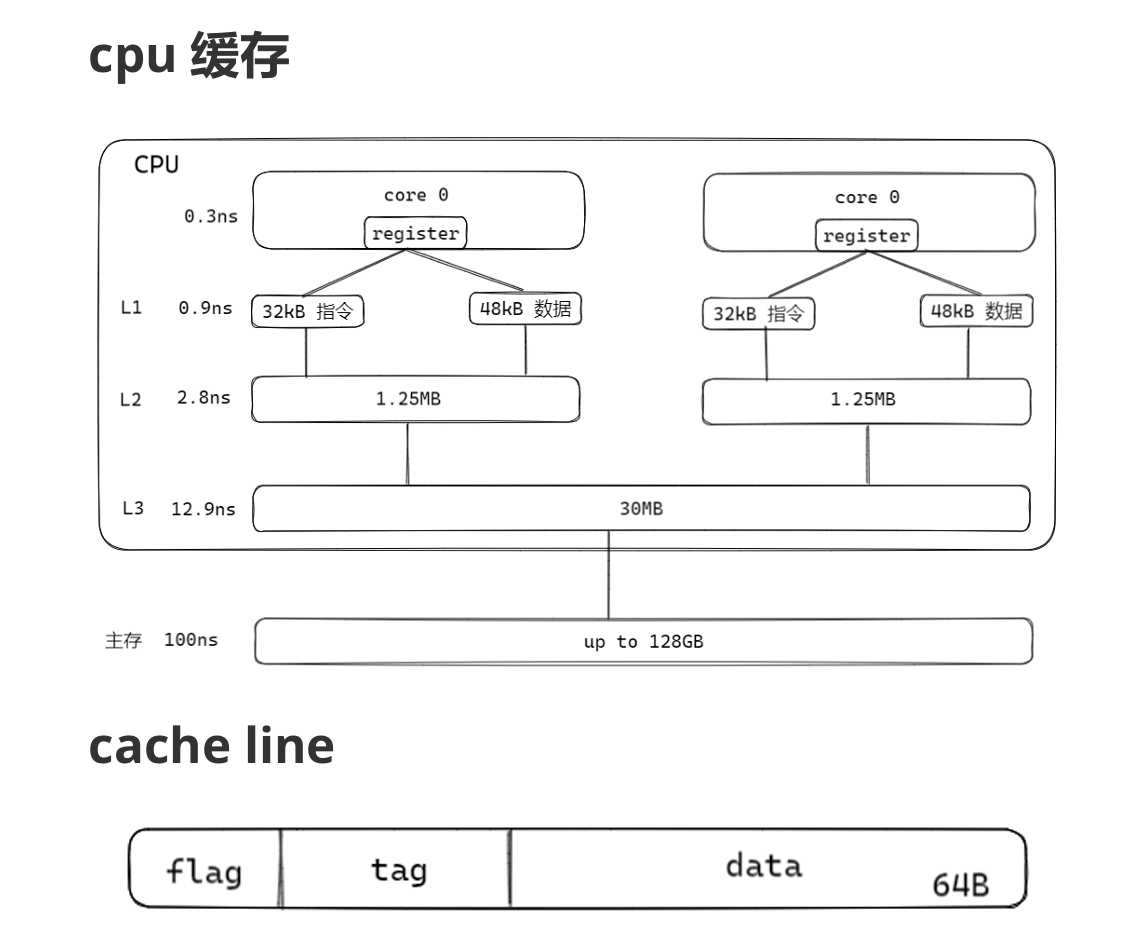
cpu采用多级缓存来解决cpu与内存的速度差异,可以通过预先加载的方式弥补差距。cache line是缓存的最小单位,里面的tag代表的是这个单位是否被加载到缓存内。
4.原子锁的概念
本质:
基于硬件支持的原子操作(如CAS指令)实现,直接依赖CPU指令保证操作的不可分割性
特点:无锁(Lock-Free)设计:无需显式加锁,通过原子指令直接操作共享变量。粒度极细:仅能保护单一变量(如整型、指针)的原子性,无法覆盖复合操作。
5.单核和多核实现原子锁
单核实现原子锁只需要屏蔽中断就可以保证操作指令不被打断,而多核实现原子锁不仅要考虑操作指令不被打断,还需要保证其余指令不去修改相关的内存空间,这就涉及到了缓存一致性的问题
先介绍一下cpu写回(write-back)策略
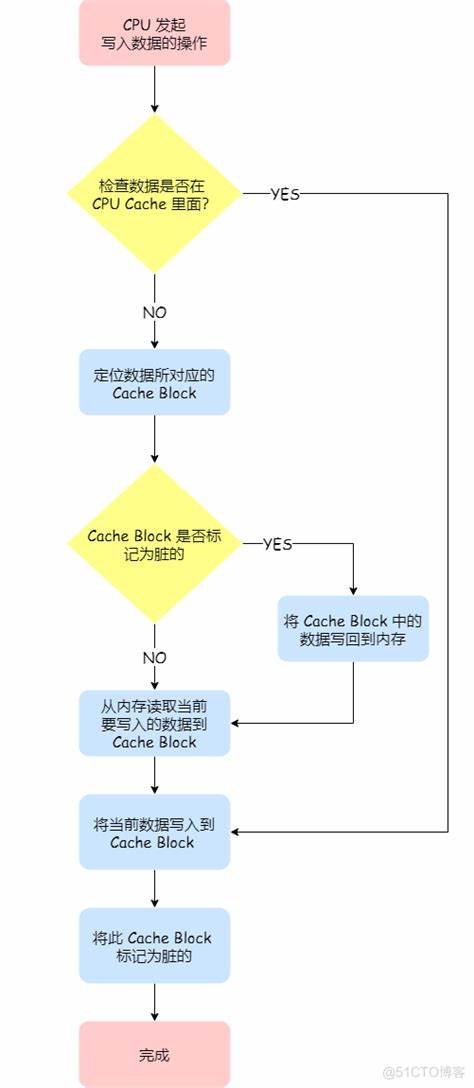
举一个例子:CPU核心A修改共享数据X=42
1. 核心A写入X=42:
- 缓存行(cache block)标记为Modified(脏)。
- 数据未立即写入主内存。
2. 核心B尝试读取X:
- 缓存一致性协议检测到核心A的缓存行状态为Modified。
- 核心A将脏数据写回主内存,并降级缓存行状态为Shared。
- 核心B从主内存加载最新数据。
3. 核心A的缓存行被替换:
- 若状态为Modified,必须先将数据写回内存。
- 缓存行状态变为Invalid。
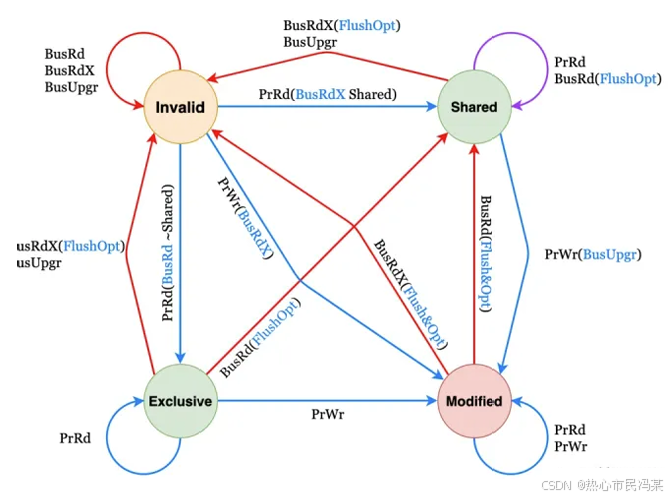
6.MESI协议解决缓存一致性问题
MESI 协议是一个基于失效的缓存一致性协议,支持 write-back 写回缓存的常用协议。主要原理:通过总线嗅探策略(将读写请求通过总线广播给所有核心,核心根据本地状态进行响应)
主要有以下四种状态:
Modified(M):某数据已修改但是没有同步到内存中。如果其他核心要读该数据,需要将该数据从缓存同步到内存中,并将状 态转为 S。
Exclusive(E):某数据只在该核心当中,此时缓存和内存中的数据一致。
Shared(S):某数据在多个核心中,此时缓存和内存中的数据 一致。
Invaliddate(I):某数据在该核心中以失效,不是最新数据。
下图中的事件解析:
PrRd:核心请求从换存块中读出数据;
PrWr:核心请求向缓存块写入数据;
BusRd:总线嗅探器收到来自其他核心的读出缓存请求;
BusRdX:总线嗅探器收到另一核心写⼀个其不拥有的缓存块的 请求;
BusUpgr:总线嗅探器收到另一核心写⼀个其拥有的缓存块的 请求;
Flush:总线嗅探器收到另一核心把一个缓存块写回到主存的请 求;
FlushOpt:总线嗅探器收到一个缓存块被放置在总线以提供给另一核心的请求,和 Flush 类似,但只不过是从缓存到缓存的传输请求。
结合下面这张状态机图来看:
7.原子变量
原子变量的原子操作(如CAS、原子读/写)依赖于硬件支持,而MESI协议为实现这些操作提供了基础。例如,原子操作需要确保操作期间缓存行的独占访问(Exclusive或Modified状态),避免其他核心的干扰,从而保证操作的原子性。原子变量具备原子性,也就是要么全部完成,要么全部未完成。
下面主要介绍一下原子操作中的内存模型。这里所指内存模型对应缓存一致性模型,作用是对同一时间的 读写操作进行排序。在不同的 CPU 架构上,这些模型的具体实 现方式可能不同,但是 C++11 帮你屏蔽了内部细节,不用考虑内存屏障,只要符合上面的使用规则,就能得到想要的效果。 可能有时使用的模型粒度比较大,会损耗性能,当然还是使用各平台底层的内存屏障粒度更准确,效率也会更高,对程序员的功底要求也高。
主要有下面四种:
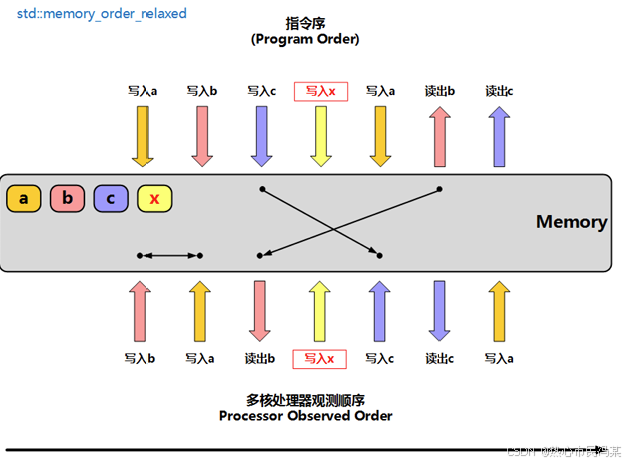
memory_order_relaxed:松散内存序,只用来保证对原子对 象的操作是原子的,在不需要保证顺序时使用;当前线程该原子变量前面和后面的内存读写操作都可以重排:
memory_order_release:释放操作,在写入某原子对象时, 当前线程的任何前面的读写操作都不允许重排到这个操作的后面去(可以认为当前线程前面的读写操作是因,写入这个原子对象是果,不可因果倒置),并且当前线程的所有内存写入都在对同一个原子对象进行获取的其他线程可见;通常与 memory_order_acquire 或 memory_order_consume 配对使用;
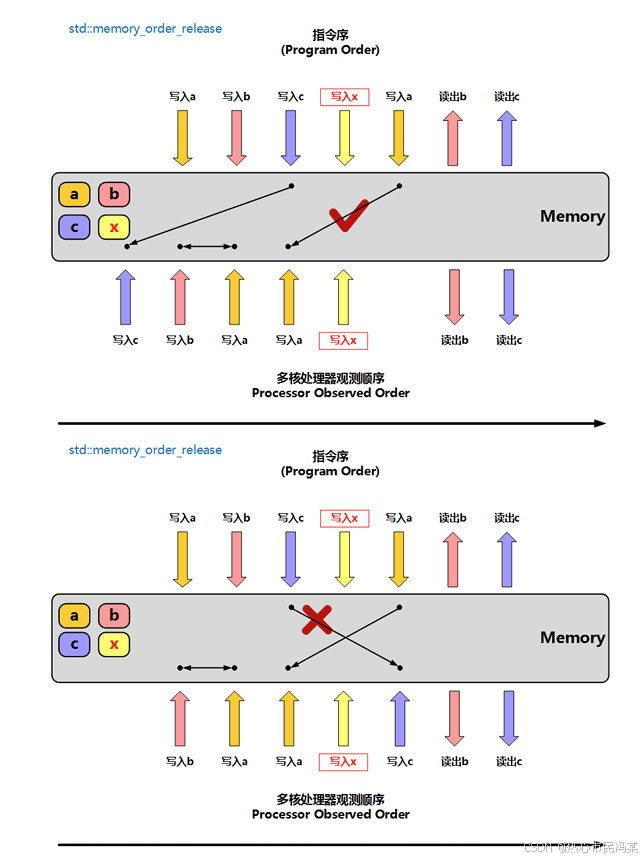
memory_order_acquire:获得操作,在读取某原子对象时, 当前线程的任何后面的读写操作都不允许重排到这个操作的前面去(可以认为写入操作是因、后面的读写操作是果),并且其他线程在对同一个原子对象释放之前的所有内存写入都在当前线程可见;
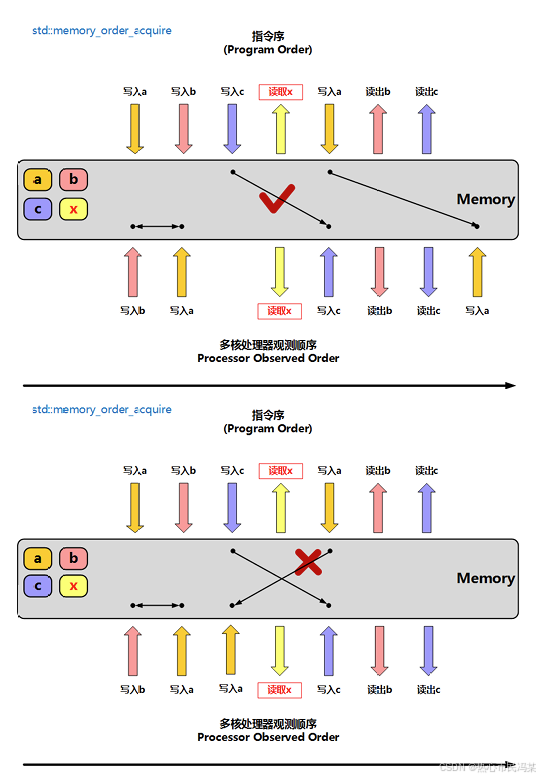
下面来看一个简单的例子:
#include <atomic>
#include <thread>
#include <assert.h>
#include <iostream>
std::atomic<bool> x,y;
std::atomic<int> z;
// 提升效率
void write_x_then_y()
{
x.store(true,std::memory_order_relaxed); // 1
y.store(true,std::memory_order_release); // 2
}
void read_y_then_x()
{
while(!y.load(std::memory_order_acquire)); // 3 自旋,等待y被设置为true
if(x.load(std::memory_order_relaxed)) // 4
++z; // 会不会一定等于 1
}
int main()
{
x=false;
y=false;
z=0;
std::thread a(write_x_then_y);
std::thread b(read_y_then_x);
a.join();
b.join();
std::cout << z.load(std::memory_order_relaxed) << std::endl;
return 0;
}这里a、b线程同时进行,a线程中y变量写入用了memory_order_release操作,b线程中y变量用了memory_order_acquire,这就保证了在b线程中必须先获取到y的写入之后才会触发后面的x获取操作,这就使Z一定为1,如果换成released松散操作的话,cpu可能对两个线程中的指令进行重排,结果可能就不为1了。
0voice · GitHub


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









