









深度学习基础知识梳理|包括函数及参数解释以及网络构建等流程
一、函数及参数介绍
1.ReLU函数及参数介绍
- nn.ReLU()函数默认inplace 默认是False

- inplace = False 时,不会修改输入对象的值,而是返回一个新创建的对象,所以打印出对象存储地址不同,类似于C语言的值传递
- inplace = True 时,会修改输入对象的值,所以打印出对象存储地址相同,类似于C语言的址传递
- inplace = True ,会改变输入数据的值,节省反复申请与释放内存的空间与时间,只是将原来的地址传递,效率更好
参考链接: https://blog.csdn.net/manmanking/article/details/104830822
二、深度学习网络模型及结构的处理
1.网络冻结:冻结某些层、某些参数,用于模型微调
- 有两个步骤:1.找到需要冻结的层的参数,将其
.requires_grad属性设置为False,冻结参数。 2.设置优化器,仅传入不冻结的参数,即.requires_grad属性为True的参数。 - 节省显存:不将不更新的参数传入optimizer
提升速度:将不更新的参数的requires_grad设置为False,节省了计算这部分参数梯度的时间
#模型实例化
model = Dense121FineTune(spatial_dims=3,in_channels=2,out_channels=3,module_load_path=model_load_path).to(device)
print(model)##打印网络的结构
##方法一
#遍历网络,获取每一层的名字和参数值,requires_grad:规定是否进行梯度计算
#仅计算classifier.out.weight,classifier.out.bias的参数值,参数值不需要计算梯度的requires_grad设置为False
#此处可以依据实际情况根据网络层的名字等进行.requires_grad的属性设置,比如需要冻结的网络层名字存在列表中,遍历列表进行设置,根据实际需求有很多判断方式~
for name,value in model.named_parameters():
if name=='classifier.out.weight' or name =='classifier.out.bias':
value.requires_grad = True
else:
value.requires_grad = False
##方法二
#i:第i个参数,param:第i个参数的值
for i,param in enumerate(model.parameters()):
print(f'i={i},para={param.requires_grad}')
#一共363个参数classifier.out.weight和classifier.out.bias是最后两个参数,可在方法一的遍历中打印名字print(name)知道参数名
if i<362:
param.requires_grad = False
###配置一下优化器,仅对requires_grad=True的参数进行优化
optimizer = torch.optim.Adam(filter(lambda p : p.requires_grad, model.parameters()), lr=1e-5, weight_decay=0)
#冻结指定层的预训练参数:
net.feature[26].weight.requires_grad = False
# 冻结整个网络
for param in self.model.parameters():
param.requires_grad = False
- 还有一种冻结方法是使用torch.no_grad(),参考链接: pytorch 两种冻结层的方式,这种方法我还没深入研究,感兴趣的麻友们可以试试~ 有什么问题也欢迎大家一起研究讨论~
#这种方式只需要在网络定义中的forward方法中,将需要冻结的层放在 torch.no_grad()下。
class xxnet(nn.Module):
def __init__():
....
self.layer1 = xx
self.layer2 = xx
self.fc = xx
def forward(self.x):
with torch.no_grad():
x = self.layer1(x)
x = self.layer2(x)
x = self.fc(x)
return x
①模型权重冻结:一些情况下,我们可能只需要对模型进行推断,而不需要调整模型的权重。通过调用model.eval(),可以防止在推断过程中更新模型的权重。with torch.no_grad(): # 禁用梯度计算以加快计算速度。
②训练完train_datasets之后,model要来测试样本了。在model(test_datasets)之前,需要加上model.eval(). 否则的话,有输入数据,即使不训练,它也会改变权值。这是model中含有batch normalization层所带来的的性质。
eval()时,pytorch会自动把BN和DropOut固定住,不会取平均,而是用训练好的值。不然的话,一旦test的batch_size过小,很容易就会被BN层导致生成图片颜色失真极大。eval()在非训练的时候是需要加的,没有这句代码,一些网络层的值会发生变动,不会固定,你神经网络每一次生成的结果也是不固定的,生成质量可能好也可能不好。
③何时用model.eval() :训练完train样本后,生成的模型model要用来测试样本。在model(test)之前,需要加上model.eval(),否则的话,有输入数据,即使不训练,它也会改变权值。这是model中含有BN层和Dropout所带来的的性质。在eval/test过程中,需要显示地让model调用eval(),此时模型会把BN和Dropout固定住,不会取平均,而是用训练好的值。
④何时用with torch.no_grad():无论是train() 还是eval() 模式,各层的gradient计算和存储都在进行且完全一致,只是在eval模式下不会进行反向传播。而with torch.no_grad()则主要是用于停止autograd模块的工作,以起到加速和节省显存的作用。它的作用是将该with语句包裹起来的部分停止梯度的更新,从而节省了GPU算力和显存,但是并不会影响dropout和BN层的行为。若想节约算力,可在test阶段带上torch.no_grad()。
⑤with torch.no_grad() 主要是用于停止autograd模块的工作,以起到加速和节省显存的作用。它的作用是将该with语句包裹起来的部分停止梯度的更新,从而节省了GPU算力和显存,但是并不会影响dropout和BN层的行为。如果不在意显存大小和计算时间的话,仅仅使用model.eval()已足够得到正确的validation/test的结果;而with torch.no_grad()则是更进一步加速和节省gpu空间(因为不用计算和存储梯度),从而可以更快计算,也可以跑更大的batch来测试。
2.网络层的删除:删除任意层、后几层
- 删除任意层:两种方法:①使用关键字del删除层②将层设置为空层
自定义一个简单的网络结构为例子
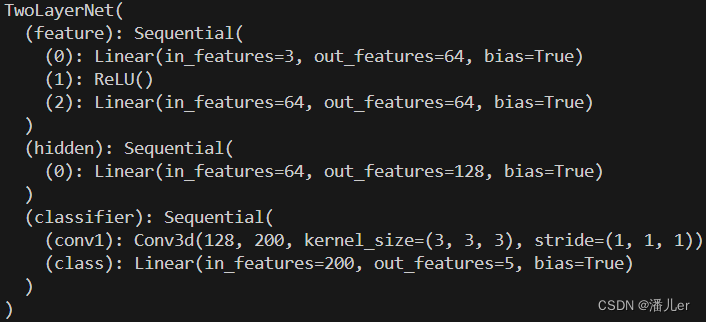
方法一:使用关键字del删除任意层
model = TwoLayerNet(in_channels=3,out_channels=5)
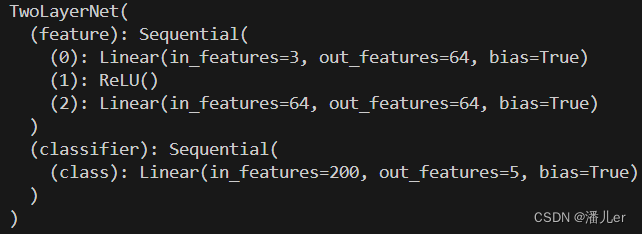
del model.hidden
print(model)
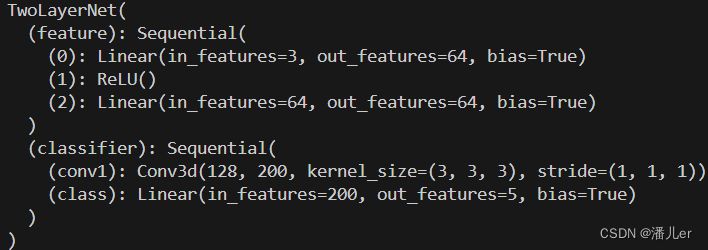
del model.classifier.conv1#也可用列表索引的形式 del model.classifier[1]
print(model)
下列结果图分别是 删除模型中的hidden层,删除模型中classifier层中的conv1
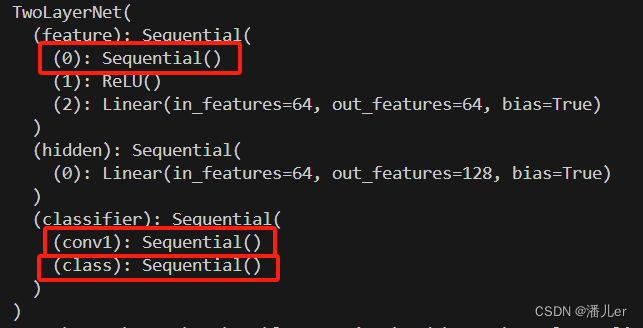
方法二:将层设置为空
model = TwoLayerNet(in_channels=3,out_channels=5)
model.feature[0] = nn.Sequential()
model.classifier[1]=nn.Sequential()#可以用列表索引的形式选择要删除的层
model.classifier.conv1 = nn.Sequential()#可以用名字 选择要删除的层
print(model)
- 删除最后几层或连续几层
model.feature = model.feature[:-2]
#也可用这句model.feature = nn.Sequential(*list(model.feature.children())[:-2])
print(model)
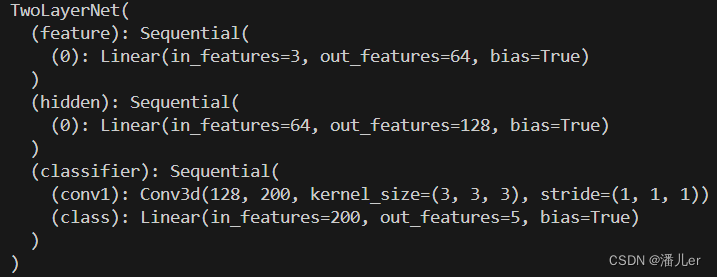
3.模型保存、存储及模型加载
会区分多个GPU的模型存储和加载与单个GPU模型存储和加载的区别
3.1 存储格式和存储内容
- 一个PyTorch模型主要包含两个部分:模型结构和权重
- 模型是继承nn.Module的类,权重的数据结构是一个字典(key是层名,value是权重向量)
- 存储也由此分为两种形式:存储整个模型(包括结构和权重),和只存储模型权重
from torchvision import models
model = models.resnet152(pretrained=True)
save_dir = './resnet152.pth'
# 保存整个模型
torch.save(model, save_dir)
# 保存模型权重
torch.save(model.state_dict, save_dir)
PyTorch存储模型主要采用pkl,pt,pth三种格式。对于PyTorch而言,pt, pth和pkl三种数据格式均支持模型权重和整个模型的存储,因此使用上没有差别
3.2 单卡和多卡模型存储区别
PyTorch中将模型和数据放到GPU上有两种方式——.cuda()和.to(device)
- 第一种.cuda()方式
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0' # 如果是多卡改成类似0,1,2
model = model.cuda() # 单卡
model = torch.nn.DataParallel(model).cuda() # 多卡
- 第二种.to(device)方式
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") # 多GPU时可指定起始位置/编号
if torch.cuda.device_count() > 1: # 检查电脑是否有多块GPU,如果有多块,则将模型分布在多GPU上
model = nn.DataParallel(model) # 将模型对象转变为多GPU并行运算的模型
model.to(device) # 把模型移动到GPU上
多卡模型保存后的网络层名称多了module.
 单卡模型的网络名称 单卡模型的网络名称
|
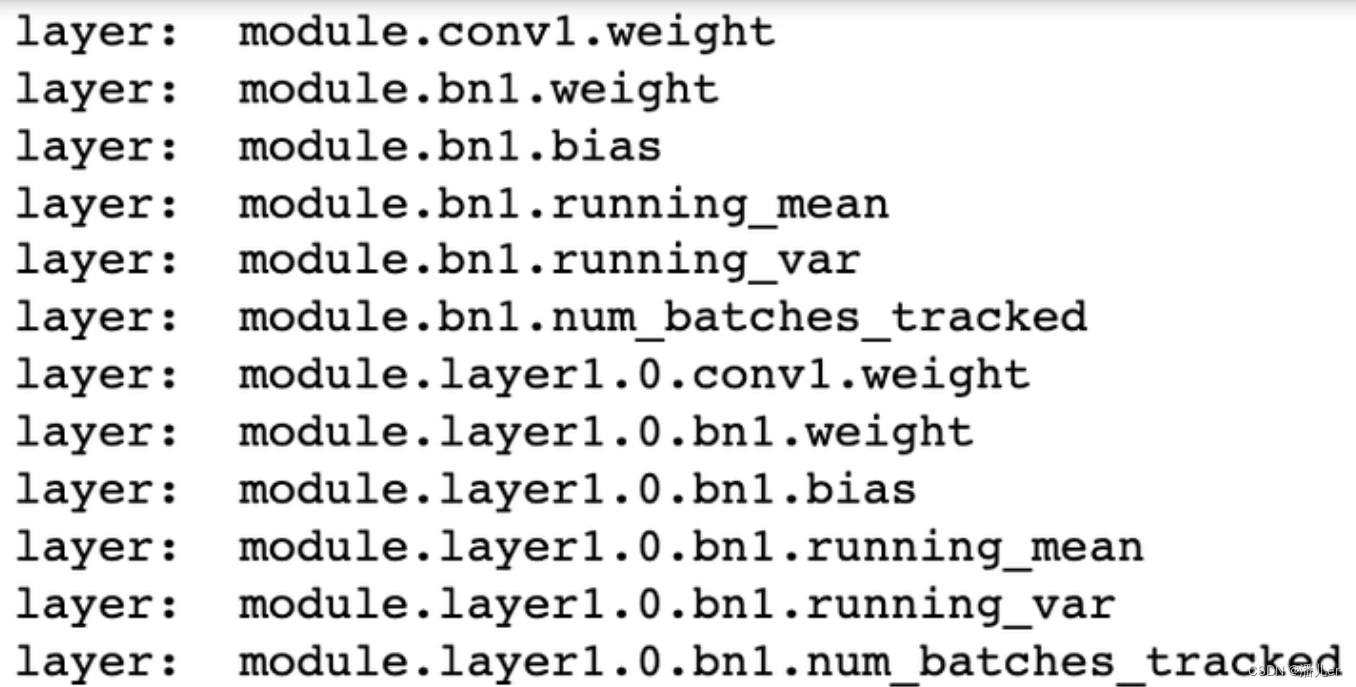 多卡模型的网络名称 多卡模型的网络名称
|
3.3 单卡/多卡模型保存和加载分类讨论
3.3.1 单卡保存+单卡加载
import os
import torch
from torchvision import models
os.environ['CUDA_VISIBLE_DEVICES'] = '0' #这里替换成希望使用的GPU编号
model = models.resnet152(pretrained=True)
model.cuda()
save_dir = 'resnet152.pt' #保存路径
# 保存+读取整个模型
torch.save(model, save_dir)
loaded_model = torch.load(save_dir)
loaded_model.cuda()
# 保存+读取模型权重
torch.save(model.state_dict(), save_dir)
loaded_model = models.resnet152() #注意这里需要对模型结构有定义
loaded_model.load_state_dict(torch.load(save_dir))
loaded_model.cuda()
3.3.2 单卡保存+多卡加载
这种情况的处理比较简单,读取单卡保存的模型后,使用nn.DataParallel函数进行分布式训练设置即可(相当于3.3.1代码中.cuda()替换一下):
import os
import torch
from torchvision import models
os.environ['CUDA_VISIBLE_DEVICES'] = '0' #这里替换成希望使用的GPU编号
model = models.resnet152(pretrained=True)
model.cuda()
# 保存+读取整个模型
torch.save(model, save_dir)
os.environ['CUDA_VISIBLE_DEVICES'] = '1,2' #这里替换成希望使用的GPU编号
loaded_model = torch.load(save_dir)
loaded_model = nn.DataParallel(loaded_model).cuda()
# 保存+读取模型权重
torch.save(model.state_dict(), save_dir)
os.environ['CUDA_VISIBLE_DEVICES'] = '1,2' #这里替换成希望使用的GPU编号
loaded_model = models.resnet152() #注意这里需要对模型结构有定义
loaded_model.load_state_dict(torch.load(save_dir))
loaded_model = nn.DataParallel(loaded_model).cuda()
3.3.3 多卡保存+单卡加载
这种情况下的核心问题是:如何去掉权重字典键名中的"module",以保证模型的统一性。
- 对于加载整个模型,直接提取模型的module属性即可:
import os
import torch
from torchvision import models
os.environ['CUDA_VISIBLE_DEVICES'] = '1,2' #这里替换成希望使用的GPU编号
model = models.resnet152(pretrained=True)
model = nn.DataParallel(model).cuda()
# 保存+读取整个模型
torch.save(model, save_dir)
os.environ['CUDA_VISIBLE_DEVICES'] = '0' #这里替换成希望使用的GPU编号
loaded_model = torch.load(save_dir).module
- 对于加载模型权重,有以下几种思路:
方法一: 保存模型时保存模型的module属性对应的权重,这样保存下来的模型参数就和单卡保存的模型参数一样了,可以直接加载。也是比较推荐的一种方法。 去除字典里的module麻烦,往model里添加module简单
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0,1,2' #这里替换成希望使用的GPU编号
import torch
from torchvision import models
save_dir = 'resnet152.pth' #保存路径
model = models.resnet152(pretrained=True)
model = nn.DataParallel(model).cuda()
# 保存权重
torch.save(model.module.state_dict(), save_dir)
方法二: 遍历字典去除module
from collections import OrderedDict
os.environ['CUDA_VISIBLE_DEVICES'] = '0' #这里替换成希望使用的GPU编号
loaded_dict = torch.load(save_dir)
new_state_dict = OrderedDict()
for k, v in loaded_dict.items():
name = k[7:] # module字段在最前面,从第7个字符开始就可以去掉module
new_state_dict[name] = v #新字典的key值对应的value一一对应
loaded_model = models.resnet152() #注意这里需要对模型结构有定义
loaded_model.state_dict = new_state_dict
loaded_model = loaded_model.cuda()
##使用replace操作去除module.
loaded_model = models.resnet152()
loaded_dict = torch.load(save_dir)
loaded_model.load_state_dict({k.replace('module.', ''): v for k, v in loaded_dict.items()})
3.3.4 多卡保存+多卡价值
由于是模型保存和加载都使用的是多卡,因此不存在模型层名前缀不同的问题。但多卡状态下存在一个device(使用的GPU)匹配的问题,即保存整个模型时会同时保存所使用的GPU id等信息,读取时若这些信息和当前使用的GPU信息不符则可能会报错或者程序不按预定状态运行。具体表现为以下两点:
读取整个模型再使用nn.DataParallel进行分布式训练设置
这种情况很可能会造成保存的整个模型中GPU id和读取环境下设置的GPU id不符,训练时数据所在device和模型所在device不一致而报错。
读取整个模型而不使用nn.DataParallel进行分布式训练设置
这种情况可能不会报错,测试中发现程序会自动使用设备的前n个GPU进行训练(n是保存的模型使用的GPU个数)。此时如果指定的GPU个数少于n,则会报错。在这种情况下,只有保存模型时环境的device id和读取模型时环境的device id一致,程序才会按照预期在指定的GPU上进行分布式训练。
相比之下,读取模型权重,之后再使用nn.DataParallel进行分布式训练设置则没有问题。因此多卡模式下建议使用权重的方式存储和读取模型:
import os
import torch
from torchvision import models
os.environ['CUDA_VISIBLE_DEVICES'] = '0,1,2' #这里替换成希望使用的GPU编号
model = models.resnet152(pretrained=True)
model = nn.DataParallel(model).cuda()
# 保存+读取模型权重,强烈建议!!
torch.save(model.state_dict(), save_dir)
loaded_model = models.resnet152() #注意这里需要对模型结构有定义
loaded_model.load_state_dict(torch.load(save_dir)))
loaded_model = nn.DataParallel(loaded_model).cuda()
如果只有保存的整个模型,也可以采用提取权重的方式构建新的模型:
# 读取整个模型
loaded_whole_model = torch.load(save_dir)
loaded_model = models.resnet152() #注意这里需要对模型结构有定义
loaded_model.state_dict = loaded_whole_model.state_dict
loaded_model = nn.DataParallel(loaded_model).cuda()
另外,上面所有对于loaded_model修改权重字典的形式都是通过赋值来实现的,在PyTorch中还可以通过"load_state_dict"函数来实现。因此在上面的所有示例中,我们使用了两种实现方式。
loaded_model.load_state_dict(loaded_dict)
3.4 其他参数的保存和读取
在深度学习项目里,有时候我们不仅仅需要保存模型的权重,还需要保存一些其他的参数,比如训练的epoch数、训练的loss,优化器的参数,动态调整学习策略的参数等等。这些参数可以通过字典的形式保存在一个文件里,然后在读取模型时一起读取。这里我们以下方代码为例:
torch.save({
'model': model.state_dict(),
'optimizer': optimizer.state_dict(),
'lr_scheduler': lr_scheduler.state_dict(),
'epoch': epoch,
'args': args,
}, checkpoint_path)
这些参数的读取方式也是类似的:
checkpoint = torch.load(checkpoint_path)
model.load_state_dict(checkpoint['model'])
optimizer.load_state_dict(checkpoint['optimizer'])
lr_scheduler.load_state_dict(checkpoint['lr_scheduler'])
epoch = checkpoint['epoch']
args = checkpoint['args']
——————————————————————————————————————————————
模型及参数保存和加载,参考:
pytorch模型保存和读取
pytorch模型保存和加载
——————————————————————————————————————————————















 1122
1122

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









