










nnUNetv2训练流程——环境配置、数据集构建、数据处理、训练、推理
概要
整体流程说明
环境配置
数据集文件构建
数据格式化
数据预处理
数据训练
数据推理
注意点
概要
nnUNetv2初使用,分享内容包括:环境配置、数据集文件构建、数据格式化、数据预处理、数据训练、数据推理
整体流程说明
1.环境配置
①可以使用以前的conda环境,也可新建仅用于nnunet的新环境
conda create -n your_env_name python=x.x
②安装nnUNetv2
用作标准化基线、开箱即用的分割算法或使用预训练模型运行推理:
pip install nnunetv2
用作集成框架(这将在您的计算机上创建 nnU-Net 代码的副本,以便您可以根据需要进行修改):
git clone https://github.com/MIC-DKFZ/nnUNet.git
cd nnUNet
pip install -e .
③安装隐藏层,hiddenlayer 使 nnU-net 能够生成 它生成的网络拓扑图,非必要安装
pip install --upgrade git+https://github.com/FabianIsensee/hiddenlayer.git
2.数据集文件结构构建
①新建文件夹DATASET

②进入DATASET,新建三个文件夹nnUNet_preprocessed、nnUNet_raw、nnUNet_results
 ③环境变量配置
③环境变量配置
nnU-Net 需要一些环境变量,以便它可以知道原始数据、预处理数据和训练数据的位置。根据操作系统的不同,这些环境变量需要以不同的方式进行设置(本文操作系统Linux & MacOS)。
找到并进入.bashrc文件,并进入编辑模式
vim .bashrc
在文件底部添加数据集文件路径
export nnUNet_raw="/media/fabian/nnUNet_raw" #nnUNet_raw文件路径
export nnUNet_preprocessed="/media/fabian/nnUNet_preprocessed"#nnUNet_preprocessed文件路径
export nnUNet_results="/media/fabian/nnUNet_results" #nnUNet_results文件路径
保存并退出
最后更新文件
source .bashrc
说明:上述环境变量配置方法属于永久配置,若临时配置,只需在运行nnunet时,执行添加数据集文件路径的命令即可
3.数据集格式化
nnUNet_raw文件夹存放不同分割任务的文件夹,对应不同数据集
 ①数据集文件夹格式:
①数据集文件夹格式:
数据集Dataset001_BrainTumour中存放的是训练集(imagesTr)、训练集标注(labelsTr)、测试集(imagesTs)、dataset.json文件(包含数据集Dataset001_BrainTumour的元数据)

②训练数据存放格式(imagesTr):
imagesTr的文件结构是img_XXX_XXXX.nii.gz
XXX:数据序号(与labelsTr中的序号对应) XXXX:数据的通道
如CT数据,单一通道,则所有数据都是0000
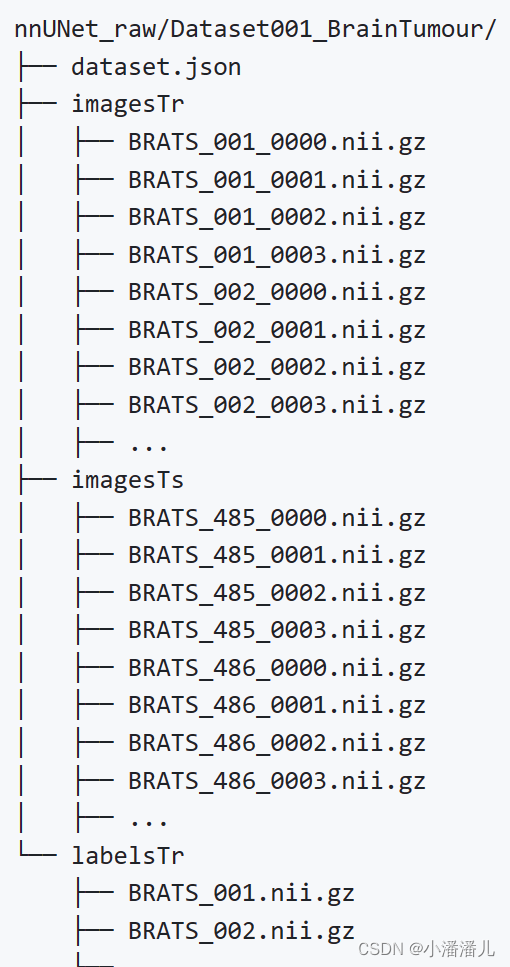
③测试数据文件格式同训练数据(imagesTs)
④训练集标注存放格式(labelsTr):
img_XXX.nii.gz
XXX:数据序号(与imagesTr中的序号对应),见②中的图片。
④dataset.json文件:包含 nnU-Net 训练所需的元数据。
{
"channel_names": { # formerly modalities
"0": "T2",
"1": "ADC"
},
"labels": {
"background": 0,
"PZ": 1,
"TZ": 2
},
"numTraining": 32,
"file_ending": ".nii.gz"
"overwrite_image_reader_writer": "SimpleITKIO" # optional! If not provided nnU-Net will automatically determine the ReaderWriter
}
4.数据预处理
nnUNetv2_plan_and_preprocess -h #查看帮助
nnUNetv2_plan_and_preprocess -d 001 --verify_dataset_integrity
- 001:数据集ID,对应Dataset001_BrainTumour
- 数据处理好后会放在nnUNet_preprocessed/Dataset001_BrainTumour 下
5.模型训练
nnUNetv2_train DATASET_NAME_OR_ID UNET_CONFIGURATION FOLD #[其他选项,参见 -h]
- DATASET_NAME_OR_ID:数据集ID
- UNET_CONFIGURATION:选择训练网络(2d、3d_fullres、3d_lowres、3d_cascade_fullres)
- FOLD :指定要训练的 5 折交叉验证中的哪一个折数,0-4表示单个折数,all和5表示5折一起训练
eg: nnUNetv2_train 001 3d_fullres 1 #(表示使用001这个数据集,模型用3d_fullres,训练第一折)
可使用后台不挂断运行,即使关闭终端,训练也不会终止,后台运行相关内容见链接: Linux——nohup命令详解
nohup nnUNetv2_train 003 3d_lowres 0 >output.txt 2>&1 &
还可指定不同GPU训练五折交叉验证中的不同折
CUDA_VISIBLE_DEVICES=0 nnUNetv2_train 001 2d 0 # 在GPU0上训练第0折
CUDA_VISIBLE_DEVICES=1 nnUNetv2_train 001 2d 1 # 在GPU1上训练第1折
CUDA_VISIBLE_DEVICES=2 nnUNetv2_train 001 2d 2 # 在GPU2上训练第2折
6.模型推理
推理命令
nnUNetv2_predict -i INPUT_FOLDER -o OUTPUT_FOLDER -d DATASET_NAME_OR_ID -c CONFIGURATION --save_probabilities
# nnUNetv2_predict -h 查看更多参数解析
- INPUT_FOLDER:测试数据地址
- OUTPUT_FOLDER:分割结果存放地址
- DATASET_NAME_OR_ID:数据集ID
- CONFIGURATION:使用的什么架构,2d or 3d_fullres or 3d_cascade_fullres等,这里训练用的什么就写什么
- save_probabilities:将预测概率与需要大量磁盘空间的预测分段掩码一起保存。
默认情况下,推理将通过交叉验证的所有 5 个折叠作为一个整体来完成(根据5个模型得到一个结果)。我们强烈建议您使用全部 5 折。因此,在运行推理之前必须训练所有 5 个折叠。
要想每个模型分开得到结果,就加参数-f all,或者只为某一折出结果,就加参数-f 2(得到 fold 2 的结果)
举例得到fold2的结果
nnUNetv2_predict -i ${nnUNet_raw}/Dataset002_xijunxing/imagesTs -o output -d 002 -c 3d_lowres -f 2
# ${nnUNet_raw} 之前设置的环境变量,nnUNet_raw的地址,不会这种方法,可以直接把文件夹的绝对路径写出来
链接: 评估推理参考
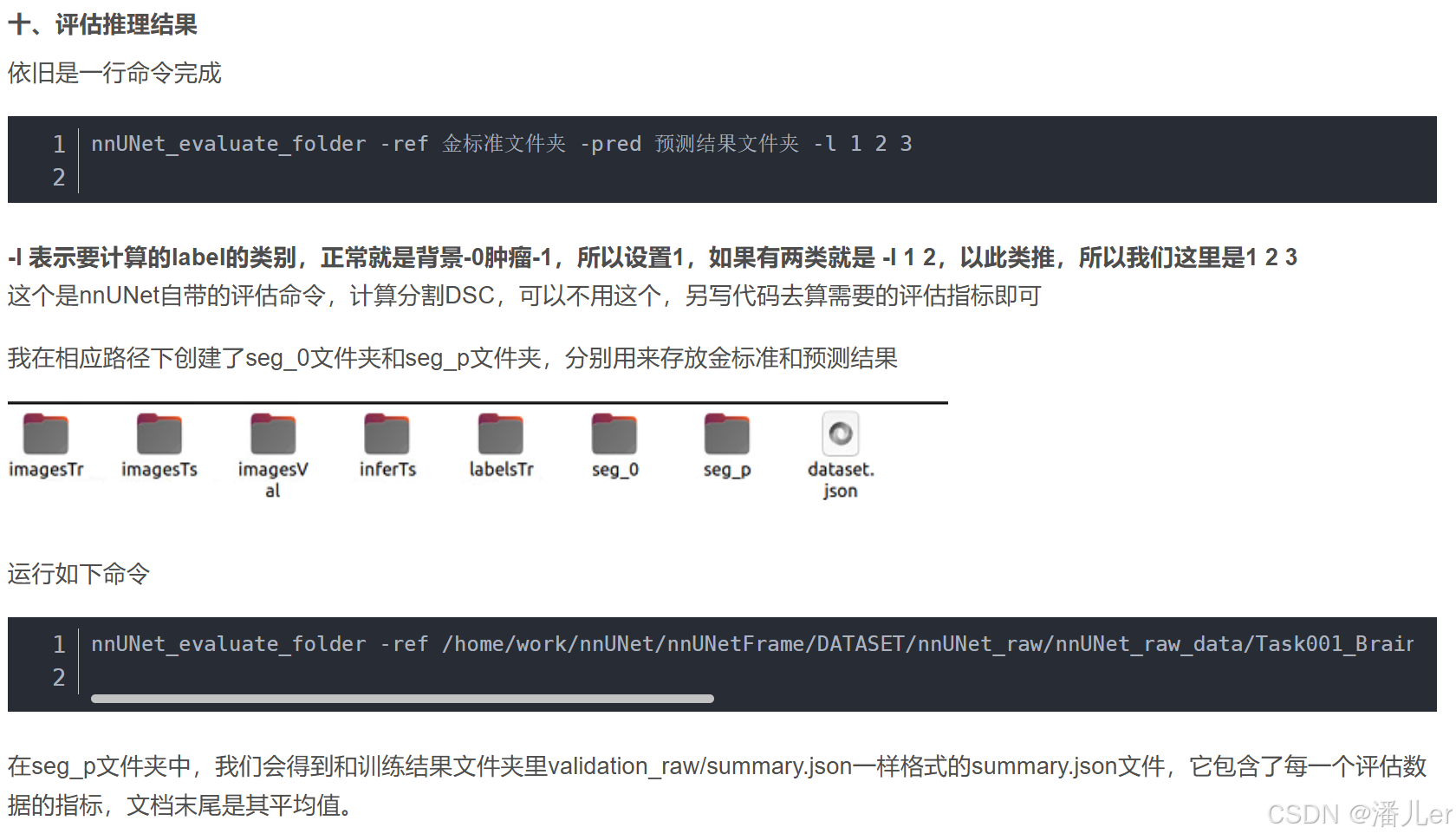
注意点说明
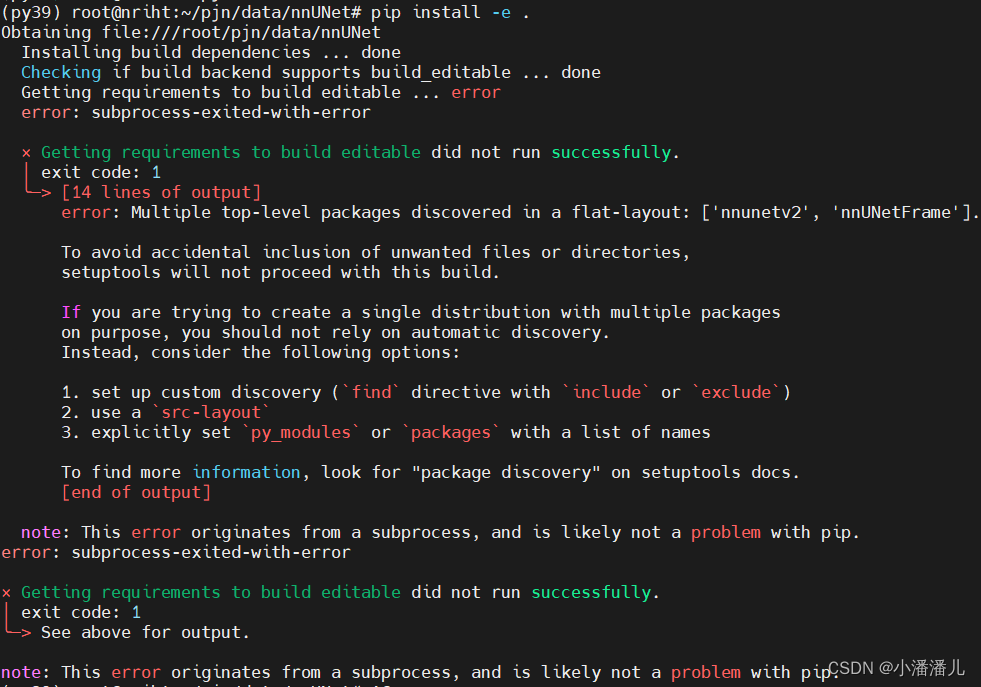
1.如果想把数据集文件创建在nnUNet代码文件夹中,一定要完成环境配置之后进行,否则在环境配置中使用 pip install -e . 时会报错。
2.nnUNetv2和torch版本问题
问题描述:当执行训练命令后,出现下图错误:NVIDIA驱动版本太老。
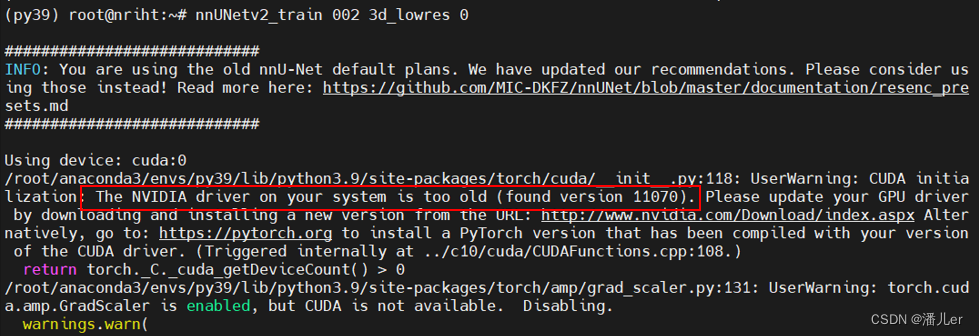
问题分析:博主服务器支持cuda<=11.7。实际不是cuda版本太老,而是torch和cuda版本不对应的问题。
查找并安装对应的torch:torch和cuda版本对应关系
cuda11.7支持torch版本是2.0.1。卸载原来的torch,重新安装后,训练正常。
另外:在安装新版本torch的时候,报错如下,但未影响安装。博主安装了nnUNetv2的版本是2.4,需要torch>=2.1,但使用2.0也正常训练了模型。

温馨提示:若在2024.4.27日之后安装nnUNetv2且安装时未指定版本,默认安装的是最新版,最好使用torch>=2.1。也可指定版本安装,nnUNetv2<=2.3版本的,均支持torch2.0。

















 782
782

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









