







文章目录
一、并查集概述
- 并查集代码很短,思维精巧,在面试和比赛当中是一种很常用的数据结构。
1. 定义
- 并、查、集,这个三个字,其中前面两个字都是动词,第三个字是个名词。
- 集就是集合,就是将一堆元素没有顺序地摆放在同一个地方。
- 因此并查集的本质就是对集合进行操作。
- 并查集是一种树型的数据结构,用于处理一些不相交集合的合并及查询问题。常常在使用中以森林来表示。
2. 作用
- (1) 将两个集合合并。
- (2) 询问两个元素是否在一个集合当中
3. 主要操作
- 初始化:把每个点所在集合初始化为其自身。通常来说,这个步骤在每次使用该数据结构时只需要执行一次,无论何种实现方式,时间复杂度均为 O(N) 。
- 查找:查找元素所在的集合,即根节点。
- 合并:将两个元素所在的集合合并为一个集合。通常来说,合并之前,应先判断两个元素是否属于同一集合,这可用上面的查找操作实现。
二、并查集思想
1. 暴力做法
- 对于如下图所示的两个集合,如果我们要判断H和A是否在同一个集合中,我们需要遍历A所在的集合,并逐一判断当前节点是否是H节点,直到最后遍历完整个蓝色集合,才能判断出H节点不在这个集合中。
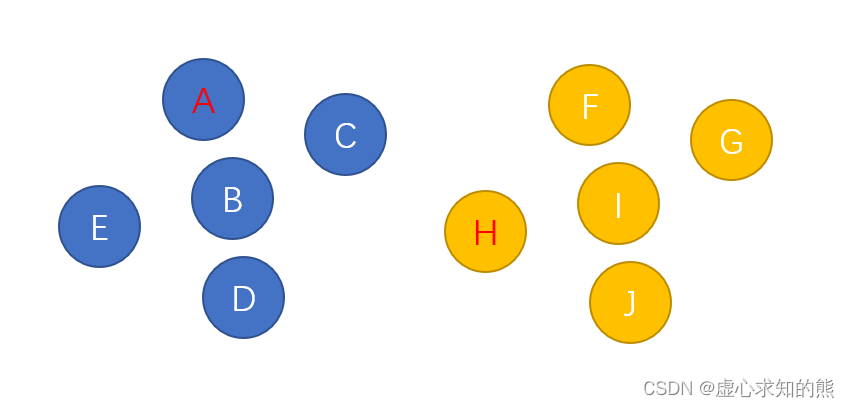
- 同样的,如果我们需要合并两个集合,就需要遍历整个黄色的集合,将里面的节点一个一个加入到蓝色集合中。两者都是 O(N) 的时间复杂度。
- 暴力做法一般是用来给我们提供优化的思路,整体比较简单易想,因此便不过多叙述。
2. 并查集做法
- 在我们生成集合的时候,就人为地将集合中的元素之间创建某种关联。那么查询和合并的操作将会省时很多。形成如下图的结构:
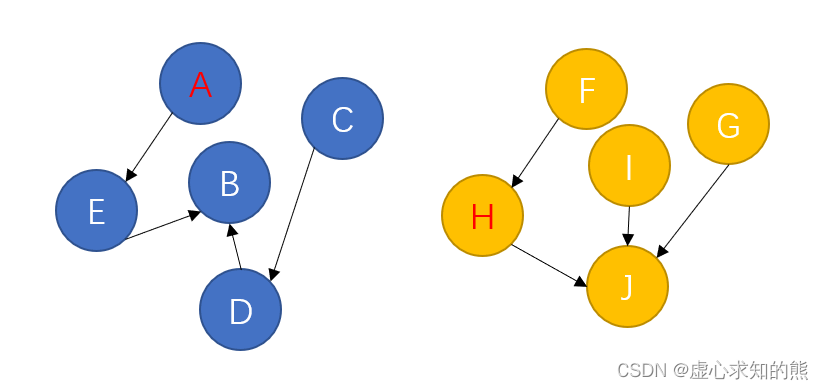
- 对结构进行优化,我们可以发现这两个结构其实就是一个树。会形成近乎 O(1) 的时间复杂度。
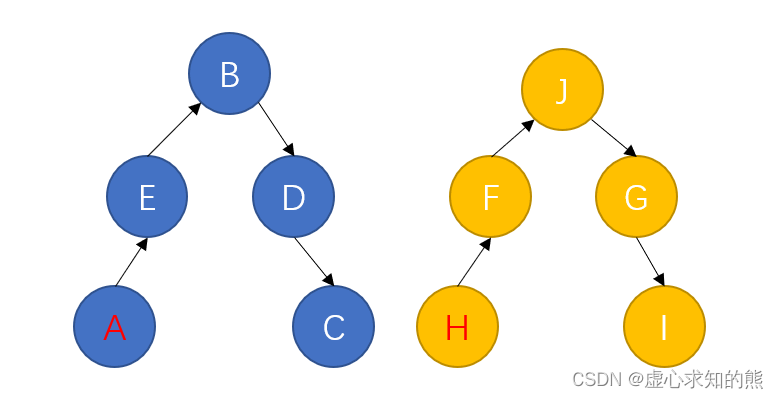
- 对于每一个点,我们都存储一下他的父节点是谁,当我们想求某个点是否属于集合当中,也就是查询操作时,就可以根据这个点的父节点是不是根节点,如果不是,就继续向上查找,直到找到根节点为止,根节点的编号就是整个集合的编号。因此,可以用这种方式快速进行查询操作。
- 那么,便会产生如下问题:
- (1) 如何判断是不是根节点? 答:if ( p[x] == x ) 。
- (2) 如何求 x 的集合编号? 答:while ( p[x] != x) x = p[x] 。
- (3) 如何合并两个集合? 答:将一个树根节点的父节点设为另一个树。即:px 是 x 的集合编号,py 是 y 的集合编号,使得 p[x] = y 。
3. 并查集优化
3.1 路径压缩
- 思想:每次查找时,如果路径较长,则修改信息,以便下次查找的时候速度更快。
- 实现:(1) 找到根节点。(2) 修改查找路径上的所有节点,将他们都指向根节点。
3.2 按秩合并(使用较少)
- 很多人有一个误解,就是认为并查集经过路径压缩优化之后,并查集是只有两层的一颗树,其实不是的。因为路径压缩只在查找的时候进行,也只压缩一条路径,所有并查集的最终结构仍然可能是比较复杂的。
- 思想:应该把简单的树往复杂的树上合并,即把树的深度小的树合并到树的深度大的树中,这样合并之后,每个元素到根结点的距离变成的元素个数最少。
- 实现:用 rank[ ] 数组来记录每个根结点对应的树的深度(如果不是根结点,则 rank 中的元素大小表示的是以当前结点作为根结点的子树的深度);一开始,把所有元素的 rank 设为 1 ,即自己就为一颗树,且深度为 1 ;合并的时候,比较两个根结点,把 rank 较小者合并到较大者中去。
4. 并查集实现详见例题——合并集合
三、并查集例题——合并集合
题目描述
一共有 n 个数,编号是 1∼n,最开始每个数各自在一个集合中。
现在要进行 m 个操作,操作共有两种:
M a b,将编号为 a 和 b 的两个数所在的集合合并,如果两个数已经在同一个集合中,则忽略这个操作。Q a b,询问编号为 a 和 b 的两个数是否在同一个集合中。
输入格式
第一行输入整数 n 和 m。
接下来 m 行,每行包含一个操作指令,指令为 M a b 或 Q a b 中的一种。
输出格式
对于每个询问指令 Q a b,都要输出一个结果,如果 a 和 b 在同一集合内,则输出 Yes,否则输出 No。
每个结果占一行。
数据范围
1 ≤ n,m ≤ 1e5
输入样例
4 5
M 1 2
M 3 4
Q 1 2
Q 1 3
Q 3 4
输出样例
Yes
No
Yes
具体实现
1. 实现思路
- 见上文。
2. 代码注解
- p[N] 是父节点数组。
- p[i] = i 所有节点一开始赋值给自己。
- int find (int x) 返回 x 的祖宗节点,包含路径压缩。
- p[find(a)] = find(b) a 的祖宗节点的父节点等于 b 的祖宗节点,把 a 节点对应集合合并到 b 节点对应集合。
- if (find(a) == find(b)) 如果 a 和 b 的祖宗节点一样的话,就说明在同一个集合里面。
3. 实现代码
#include <bits/stdc++.h>
using namespace std;
const int N = 100010;
int p[N];
int find (int x)
{
if (p[x] != x)
{
p[x] = find(p[x]);
}
return p[x];
}
int main()
{
int n, m;
cin >> n >> m;
for (int i = 1; i <= n; i ++ )
{
p[i] = i;
}
while (m -- )
{
char op[2];
int a, b;
cin >> op >> a >> b;
if (*op == 'M')
{
p[find(a)] = find(b);
}
else
{
if (find(a) == find(b))
{
puts("Yes");
}
else
{
puts("No");
}
}
}
system("pause");
return 0;
}
四、并查集例题——连通块中点的数量
题目描述
给定一个包含 n 个点(编号为 1∼n)的无向图,初始时图中没有边。
现在要进行 m 个操作,操作共有三种:
C a b,在点 a 和点 b 之间连一条边,a 和 b 可能相等;Q1 a b,询问点 a 和点 b 是否在同一个连通块中,a 和 b 可能相等;Q2 a,询问点 a 所在连通块中点的数量;
输入格式
第一行输入整数 n 和 m。
接下来 m 行,每行包含一个操作指令,指令为 C a b,Q1 a b 或 Q2 a 中的一种。
输出格式
对于每个询问指令 Q1 a b,如果 a 和 b 在同一个连通块中,则输出 Yes,否则输出 No。
对于每个询问指令 Q2 a,输出一个整数表示点 a 所在连通块中点的数量。
每个结果占一行。
数据范围
1 ≤ n,m ≤ 1e5
输入样例
5 5
C 1 2
Q1 1 2
Q2 1
C 2 5
Q2 5
输出样例
Yes
2
3
具体实现
1. 样例模拟
- 首先,有5个点:1 ,2 ,3 ,4 ,5 。
- 将 1 和 2 之间连一条边。
- 询问 1 和 2 是否在一个连通块当中,显然是的,返回 YES。
- 询问 1 所在的连通块中点的数量,显然是 2 个点,1 和 2 。
- 将 2 和 5 之间连一条边 。
- 询问 5 所在连通块中点的数量,显然是 3 个点,1、2、3 。
2. 实现思路
- 前两个操作与上一个例题 合并集合 是一样的,这里只需要考虑第三个,如何统计连通块当中点的个数。
- 对每一个集合当中点的数量初始化为 1 。
- 为了便于统计,只认为根节点集合当中点的数量是有意义的。
- 当 a 集合插入到 b 集合当中时,就是 size[b] = size[b] + size[a] 。
3. 代码注解
- size[N] 表示每一个集合当中点的数量,一开始均为 1 ,只统计根节点的。
- 在我们执行 C 步骤时,就进行判断 if (find(a) == find(b)) { continue; } 如果 a 和 b 已经在一个集合里面了,就不要执行后面的步骤了。
4. 实现代码
#include <bits/stdc++.h>
using namespace std;
const int N = 100010;
int p[N];
int cont[N];
int find (int x)
{
if (p[x] != x)
{
p[x] = find(p[x]);
}
return p[x];
}
int main()
{
int n, m;
cin >> n >> m;
for (int i = 1; i <= n; i ++ )
{
p[i] = i;
cont[i] = 1;
}
while (m -- )
{
char op[5];
int a, b;
cin >> op;
if (op[0] == 'C')
{
cin >> a >> b;
if (find(a) == find(b))
{
continue;
}
cont[find(b)] = cont[find(b)] + cont[find(a)];
p[find(a)] = find(b);
}
else if (op[1] == '1')
{
cin >> a >> b;
if (find(a) == find(b))
{
puts("Yes");
}
else
{
puts("No");
}
}
else
{
cin >> a;
cout << cont[find(a)] << endl;
}
}
system("pause");
return 0;
}
五、并查集例题——食物链(较难)
题目描述
动物王国中有三类动物 A,B,C,这三类动物的食物链构成了有趣的环形。
A 吃 B,B 吃 C,C 吃 A。
现有 N 个动物,以 1∼N 编号。
每个动物都是 A,B,C 中的一种,但是我们并不知道它到底是哪一种。
有人用两种说法对这 N 个动物所构成的食物链关系进行描述:
第一种说法是 1 X Y,表示 X 和 Y 是同类。
第二种说法是 2 X Y,表示 X 吃 Y。
此人对 N 个动物,用上述两种说法,一句接一句地说出 K 句话,这 K 句话有的是真的,有的是假的。
当一句话满足下列三条之一时,这句话就是假话,否则就是真话。
- 当前的话与前面的某些真的话冲突,就是假话;。
- 当前的话中 X 或 Y 比 N 大,就是假话。
- 当前的话表示 X 吃 X,就是假话。
你的任务是根据给定的 N 和 K 句话,输出假话的总数。
输入格式
第一行是两个整数 N 和 K,以一个空格分隔。
以下 K 行每行是三个正整数 D,X,Y,两数之间用一个空格隔开,其中 D 表示说法的种类。
若 D=1,则表示 X 和 Y 是同类。
若 D=2,则表示 X 吃 Y。
输出格式
只有一个整数,表示假话的数目。
数据范围
1 ≤ N ≤ 50000
0 ≤ K ≤ 100000
输入样例
100 7
1 101 1
2 1 2
2 2 3
2 3 3
1 1 3
2 3 1
1 5 5
输出样例
3
具体实现
1. 样例分析
- 输入 N = 100 和 K = 7 ,表示,一共有 100 动物,要对 7 句话进行判断。
- 第一句话: 第 101 个动物和第 1 个动物是同类,我们只有 100 个动物,显然是假话。
- 第二句话: 表示 1 吃 2 。
- 第三句话: 表示 2 吃 3 。
- 第四句话: 表示 3 吃 3 ,显然是假话。
- 第五句话: 表示 1 和 3 是同类,与前面 1 吃 2 ,2 吃 3 矛盾,为假话。
- 第六句话: 表示 3 吃 1 。
- 第七句话: 表示 5 和 5 是同类。
- 所以输出 3 。
2. 实现思路
- 1 吃 2,2 吃 3, 3 吃 1,构成一个环形。
- 我们需要确定每个点和根节点的关系,就可以任意两个点之间的关系。
- 由于 3 种动物相互循环被吃,因此,我们用每个点到根节点的距离,来表示他和根节点的关系。
- 如果某个点到根节点的距离是 1 ,意思是他可以吃根节点。可以通过 % 3 = 1 来表示。
- 如果某个点到根节点的距离是 2 ,意思是他被根节点吃。 可以通过 % 3 = 2 来表示。
- 如果某个点到根节点的距离是 3 ,意思是他和根节点是同类。 可以通过 % 3 = 0 来表示。
3. 代码注解
- p[N] 父节点数组。
- d[N] 到根节点距离数组 。
- t 表示询问种类,0表示同类,1表示吃的关系 。
- p[i]=i 初始化,一开始每个点都是独立的,自己是自己的父节点
- 在并查集函数当中:
- int u = p[x] u记录旧的父节点。
- p[x] = find(p[x]) 路径压缩,新父节点变成根节点了。
- d[x] += d[u] x到新父节点的距离等于x到旧父节点的距离加上旧父节点到根节点的距离。
4. 实现代码
#include <bits/stdc++.h>
using namespace std;
const int N=50010;
int n,m;
int p[N]; // 父节点数组
int d[N]; // 到根节点距离数组
int find(int x)
{
if(p[x]!=x)
{
int u = p[x]; // u记录旧的父节点
p[x] = find(p[x]); // 路径压缩,新父节点变成根节点了
d[x] += d[u]; // x到新父节点的距离等于x到旧父节点的距离加上旧父节点到根节点的距离
}
return p[x];
}
int main()
{
cin>>n>>m;
for(int i=1;i<=n;i++)
{
p[i]=i; //一开始每个点都是独立的,自己是自己的父节点
}
int res=0;
while(m--)
{
int t;//t表示询问种类,0表示同类,1表示吃的关系
int x;
int y;
cin>>t>>x>>y;
if(x>n||y>n)
{
res++;
}
else
{
int px=find(x),py=find(y);
if(t==1)
{
if(px==py&&(d[x]-d[y])%3!=0)
{
res++;
}
else if(px!=py)
{
p[px]=py;
d[px]=d[y]-d[x];
}
}
else
{
if(px==py&&(d[x]-d[y]-1)%3!=0)
{
res++;
}
else if(px!=py)
{
p[px] = py;
d[px] = d[y] + 1 - d[x];
}
}
}
}
cout<<res<<endl;
system("pause");
return 0;
}
















 1613
1613











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











