import numpy as np
import pandas as pd
import sklearn
import matplotlib as mlp
import seaborn as sns
import re, pip, conda
import matplotlib.pyplot as plt
from sklearn.ensemble import RandomForestRegressor as RFR
from sklearn.tree import DecisionTreeRegressor as DTR
from sklearn.model_selection import cross_validate, KFold
所以在增量学习当中,已经训练过的结果会被保留。对于随机森林这样的 Bagging 模型来说,这意味着之前的数据训练出的树会被保留,新数据会训练出新的树,新旧树互不影响。对于逻辑回归、神经网络这样不断迭代以求解权重
w
w
w 的算法来说,新数据训练时
w
w
w 的起点是之前的数据训练完毕之后的
w
w
w。
当算法是回归算法、且模型衡量指标是 MSE 时,模型的泛化误差可以有如下定义:
泛化误差
=
偏
差
2
+
方差
+
噪
音
2
=
b
i
a
s
2
+
v
a
r
i
a
n
c
e
+
n
o
i
s
e
2
\begin{aligned} 泛化误差 &= 偏差^2 + 方差 + 噪音^2 \\ &= bias^2 + variance + noise^2 \end{aligned}
泛化误差=偏差2+方差+噪音2=bias2+variance+noise2
以随机森林为例,假设现在随机森林中含有
n
n
n 个弱评估器(
n
n
n 棵树),任意弱评估器上的输出结果是
X
i
X_i
Xi,则所有这些弱评估器输出结果的方差可以被表示为 Var(
X
i
X_i
Xi)。
假设现在我们执行回归任务,则森林的输出结果等于森林中所有树输出结果的平均值,因此森林的输出可以被表示为
X
ˉ
=
∑
X
i
n
\bar{X} = \frac{\sum{X_i}}{n}
Xˉ=n∑Xi,因此随机森林输出结果的方差可以被表示为Var(
X
ˉ
\bar{X}
Xˉ),也可以写作 Var(
∑
X
i
n
\frac{\sum{X_i}}{n}
n∑Xi)。
在数学上我们很容易证明:
当森林中的树互相独立时,Var(
X
ˉ
\boldsymbol{\bar{X}}
Xˉ) 永远小于 Var(
X
i
\boldsymbol{X_i}
Xi)
为了完成这个证明,我们需要几个定理:
Var(A + B) = Var(A) + Var(B),其中 A 和 B 是相互独立的随机变量。
Var(aB) = a
2
^2
2Var(B),其中 a 是任意常数。
假设任意树输出的方差 Var(
X
i
X_i
Xi) =
σ
2
\sigma^2
σ2,则有:
V
a
r
(
X
ˉ
)
=
V
a
r
(
1
n
∑
i
=
1
n
X
i
)
=
1
n
2
V
a
r
(
∑
i
=
1
n
X
i
)
=
1
n
2
(
V
a
r
(
X
1
)
+
V
a
r
(
X
2
)
+
.
.
.
+
V
a
r
(
X
n
)
)
=
1
n
2
n
σ
2
=
σ
2
n
\begin{aligned} Var(\bar{X}) &= Var\left(\frac{1}{n}\sum_{i=1}^{n}X_i\right)\\ &= \frac{1}{n^2}Var\left(\sum_{i=1}^{n}X_i\right)\\ &= \frac{1}{n^2} \left( Var(X_1) + Var(X_2) + ... + Var(X_n) \right)\\ &= \frac{1}{n^2}n\sigma^2\\ &= \frac{\sigma^2}{n} \end{aligned}
Var(Xˉ)=Var(n1i=1∑nXi)=n21Var(i=1∑nXi)=n21(Var(X1)+Var(X2)+...+Var(Xn))=n21nσ2=nσ2
当
n
n
n 为正整数、且弱评估器之间相互独立时,必然有 Var(
X
ˉ
\bar{X}
Xˉ) 永远小于 Var(
X
i
X_i
Xi),这是随机森林的泛化能力总是强于单一决策树的根本原因。
r = np.array([-1,-1,-1,1,1,1,1])#-1,1(r ==1).sum()#4(r ==-1).sum()#3
因此,当弱评估器的方差是 Var(
X
i
X_i
Xi)时,随机森林分类器的方差可以写作 Var(
f
(
X
ˉ
)
f(\bar{X})
f(Xˉ)),其中
f
(
z
)
f(z)
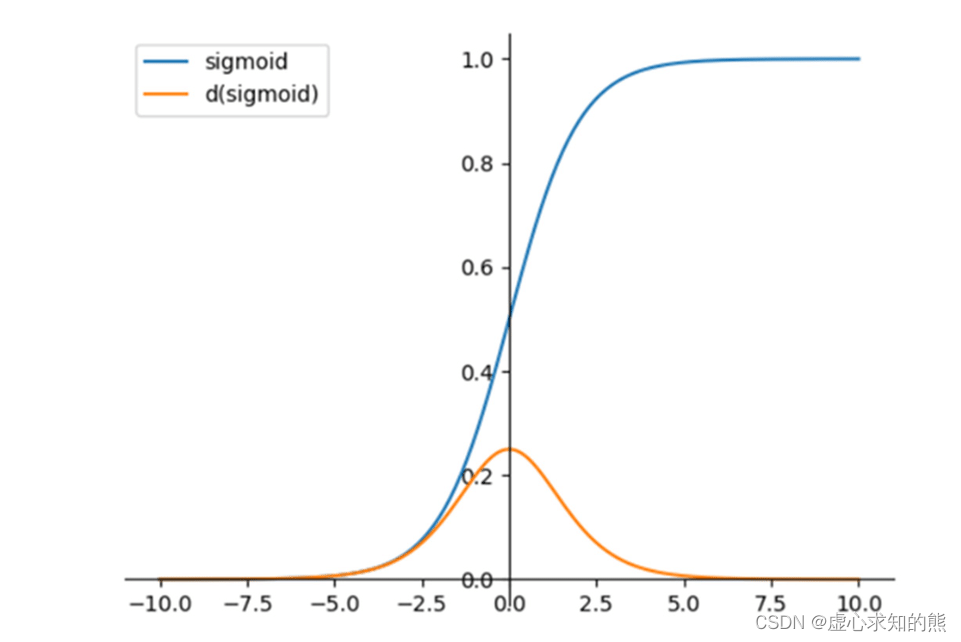
f(z) 就是 sigmoid 函数,
X
ˉ
\bar{X}
Xˉ 是所有弱评估器的分类结果的均值。在数学上我们也很容易证明:
当森林中的树互相独立,且
f
(
x
)
f(x)
f(x)为sigmoid函数时,Var(
f
(
X
ˉ
)
\boldsymbol{f(\bar{X})}
f(Xˉ))永远小于Var(
X
i
\boldsymbol{X_i}
Xi)
当
f
(
x
)
f(x)
f(x) 为二阶可导函数时,根据泰勒展开我们可以有:
Var[f(A)]
≈
\approx
≈ (f’E[A]))
2
∗
^2 *
2∗Var[A]
其中 A 为任意随机变量,f’ 为函数
f
(
x
)
f(x)
f(x) 的一阶导数。
假设任意树输出的方差 Var(
X
i
X_i
Xi) =
σ
2
\sigma^2
σ2,则有:
V
a
r
(
f
(
X
ˉ
)
)
≈
f
′
(
E
[
X
ˉ
]
)
2
∗
V
a
r
[
X
ˉ
]
=
f
′
(
E
[
X
ˉ
]
)
2
∗
σ
2
n
\begin{aligned} Var(f(\bar{X})) &\approx f'(E[\bar{X}])^2 * Var[\bar{X}]\\ &= f'(E[\bar{X}])^2 * \frac{\sigma^2}{n} \end{aligned}
Var(f(Xˉ))≈f′(E[Xˉ])2∗Var[Xˉ]=f′(E[Xˉ])2∗nσ2
根据回归类算法的推导,我们很容易可以得到
V
a
r
[
X
ˉ
]
=
σ
2
n
Var[\bar{X}] = \frac{\sigma^2}{n}
Var[Xˉ]=nσ2,因此上式的后半部分一定是小于
σ
2
\sigma^2
σ2 的。
同时,式子的第一部分是 sigmoid 函数一阶导数的平方,sigmoid 函数的一阶导数的取值范围为 [0,0.25],因此无论
E
[
X
ˉ
]
E[\bar{X}]
E[Xˉ] 是怎样的一个值,该式子的前半部分一定是一个位于范围 [0,0.0625] 的数。一个小于 1 的数乘以
σ
2
n
\frac{\sigma^2}{n}
nσ2 必然会得到小于
σ
2
\sigma^2
σ2 的数。
因此 Var(
f
(
X
ˉ
)
\boldsymbol{f(\bar{X})}
f(Xˉ)) 永远小于 Var(
X
i
\boldsymbol{X_i}
Xi)。相似的数学过程可以被推广至多分类,我们使用 softmax 函数/多对多方式来处理随机森林的结果。
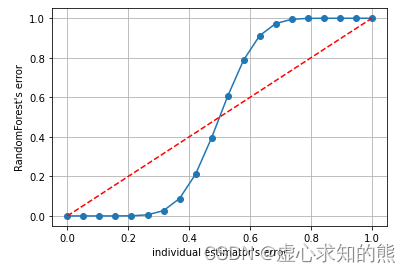
假设单独一棵决策树在样本 i 上的分类准确率在0.8上下浮动,那一棵树判断错误的概率大约就有 0.2(ε),那随机森林判断错误的概率(有 13 棵及以上的树都判断错误的概率)是:
e
r
a
n
d
o
m
_
f
o
r
e
s
t
=
∑
i
=
13
25
C
25
i
ε
i
(
1
−
ε
)
25
−
i
=
0.000369
e_{random\_forest} = \sum_{i=13}^{25}C_{25}^{i}\varepsilon^{i}(1-\varepsilon)^{25-i} = 0.000369
erandom_forest=i=13∑25C25iεi(1−ε)25−i=0.000369
import numpy as np
from scipy.special import comb
np.array([comb(25,i)*(0.2**i)*((1-0.2)**(25-i))for i inrange(13,26)]).sum()#0.00036904803455582827
import numpy as np
x = np.linspace(0,1,20)
y =[]for epsilon in np.linspace(0,1,20):
E = np.array([comb(25,i)*(epsilon**i)*((1-epsilon)**(25-i))for i inrange(13,26)]).sum()
y.append(E)
plt.plot(x,y,"o-")
plt.plot(x,x,"--",color="red")
plt.xlabel("individual estimator's error")
plt.ylabel("RandomForest's error")
plt.grid()
plt.show()


























 1135
1135

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











