import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib. pyplot as plt
from ML_basic_function import *
所谓算法库或者算法包,其实就是指封装了一系列可以执行机器学习算法建模相关功能的函数和类的程序模块,其功能调用方法和此前我们自定义的 ML_basic_function.py 文件类似。 当然,对于不同的编程语言和运行环境,其实有对应不同的算法库或算法包,例如在 R 语言中,就有数以万计的针对不同算法的一个个独立的算法包,比较有名的诸如提供分类模型建模功能支持的 rpart 包、提供聚类算法建模功能的 cluster 包等等。 尽管这些分门别类的包在每一项(类)具体算法建模过程中都能提供非常专业的功能支持,但由于这些算法包是由不同的团队/个人来进行的开发和维护,包的使用方法和维护相同都各不相同,这就使得一个使用 R 语言的算法工作者在日常工作中至少需要和几十个算法包打交道。 并且由于各个包相对独立,使得算法工作者需要时刻关注各包的更新情况及兼容方法(如果需要的话),这些都在无形之中对使用 R 语言进行机器学习建模造成了一定的阻碍。 虽然Python也是开源语言,但或许是吸取了 R 语言的前车之鉴(Python 比 R 诞生更晚),也或许是拥有了更完整的科学计算库 SciPy,Python 数据科学的一些核心功能都由一些更加统一和规范的第三方库来提供,例如科学计算库 NumPy、表格数据分析包 Pandas,以及机器学习算法库 Scikit-Learn。 Scikit-Learn 项目简介 Scikit-Learn 最早是由 David Cournapeau 等人在 2007 年谷歌编程之夏(Google Summer of Code)活动中发起的一个项目,并与 2010 年正式开源,目前归属 INRIA(法国国家信息与自动化研究所)。 项目取名为 Scikit-Learn,也是因为该算法库是基于 SciPy 来进行的构建,而 Scikit 则是 SciPy Kit(SciPy 衍生的工具套件)的简称,而 learn 则不禁让人联系到机器学习 Machine Learning。 因此,尽管 Scikit-Learn 看起来不如 NumPy、Pandas 短小精悍,但其背后的实际含义也是一目了然。 经过数十年的发展,Scikit-Learn 已经成为目前机器学习领域最完整、同时也是最具影响力的算法库,更重要的是,该项目拥有较为充裕的资金支持和完整规范的运作流程,以及业内顶级的开发和维护团队,目前以三个月一个小版本的速度在进行更新迭代。 Scikit-Learn 官网与中文社区 作为非营利性组织维护的开源项目,我们可以从 https://scikit-learn.org/stable/ 网址登陆 Scikit-Learn 项目官网。 值得一提的是,对于大多数流行的开源项目,官网都是学习的绝佳资源。而对于 Scikit-Learn 来说尤其是如此。要知道,哪怕是顶级开源项目盛行的当下,Scikit-Learn 官网在相关内容介绍的详细和完整程度上,都是业内首屈一指的。 无论是 Scikit-Learn 的安装、更新,还是具体算法的使用方法,甚至包括算法核心原理的论文出处以及算法使用的案例,在 Scikit-Learn 官网上都有详细的介绍。 国内的 Scikit-Learn 中文社区,充其量只能作为外文技术内容翻译的一个参考,而无法作为技术解释和技术学习的核心内容。因此,围绕 Scikit-Learn 的内容查阅,我们更推荐直接访问外文官网。 接下来,我们围绕 Scikit-Learn 官网的基本架构与核心功能进行介绍,并同时介绍关于 Scikit-Learn 的基本安装与使用方法。 进入 Scikit-Learn 官网,首先看到的是功能导航栏、sklearn 基本情况介绍以及几个核心功能跳转链接。
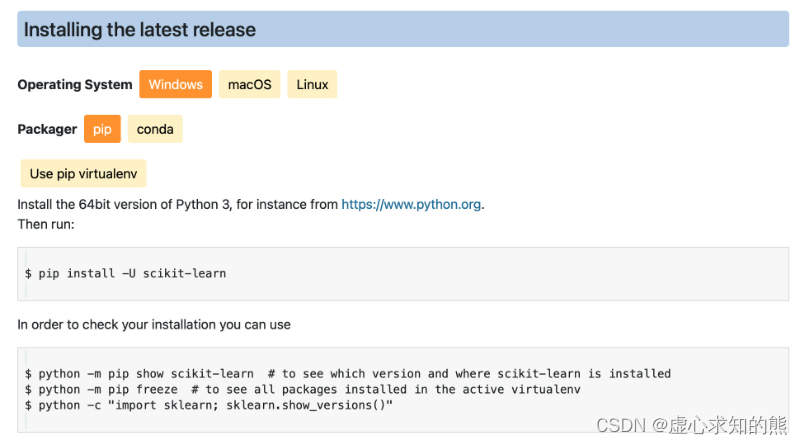
关于核心信息部分,我们能够看到 Scikit-Learn 作为开源项目的基本申明,以及该开源项目所遵循的 BSD 协议。 当然比较重要的一点是,sklearn 是构建在 NumPy、SciPy 和 matplotlib 上的相关申明,后面我们会看到,sklearn 中核心能够处理的对象类型就是 NumPy 当中的数组(array)。 同时,sklearn 中的诸多数学计算过程也都是基于 SciPy 中的相关功能来进行的实现。 接下来核心介绍功能导航栏的相关功能。 首先是关于 Scikit-Learn 的安装方法,我们可以在 Install 内进行查看:
该页面主要介绍了关于 sklearn 在不同平台下、使用不同工具的安装方法。 如果是首次安装 sklearn,可参考上述代码在命令行中进行安装。 官网还指出,可以通过后面的代码查看 sklearn 的安装情况,其中第一行是查看目前安装的 sklearn 版本以及安装位置,第二行代码是查看安装好的第三方库(在当前虚拟环境下),第三行代码则是查看当前已经安装好的 sklearn 版本。 当然,该页面还细心的给出了虚拟环境不同版本第三方包冲突后的解决方案,以及 sklearn 的包的依赖包的安装方法,包括新版 sklearn 所需基础依赖包的版本号等。 另外,该页面还给出了新版 sklearn 的 Mac M1 版本的包的安装方法,由此可见 sklearn 官网内容的详细程度。 当然,对于通过 Anaconda 安装 Python 的小伙伴来说,sklearn 包已经在安装 Anaconda 的过程中安装好了,并且不同平台的 Anaconda 就已经自带了能够在对应平台运行的 sklearn 包,我们可以直接通过下述语句进行 sklearn 版本的查看: import sklearn
sklearn. __version__
pip install - - upgrade sklearn
作为功能完整算法库,sklearn 不仅提供了完整的机器学习建模功能支持,同时也提供了包括数据预处理、模型评估、模型选择等诸多功能。 支持以 Pipelines(管道)形式构建机器学习流,而基于 Pipeline 和模型选择功能甚至能够衍化出 AutoML(自动机器学习)的相关功能,也就是现在所谓的 Auto-sklearn。 不过在开始阶段,我们还是需要从 sklearn 的基础功能入手进行学习,然后循序渐进、逐步深化对工具的理解和掌握。 sklearn 核心对象类型:评估器(estimator) 很多功能完整的第三方库其实都有各自定义的核心对象类型,如 NumPy 中的数组(Array)、Pandas 中的 DataFrame、以及 PyTorch 中的张量(tensor)等。 这些由第三方库定义的数据结构实际上都是定义在源码中的某个类,在调用这些对象类型时实际上都是在实例化对应的类。而对于 sklearn 来说,定义的核心对象类型就是评估器。 我们可以将评估器就理解成一个个机器学习模型,而 sklearn 的建模过程最核心的步骤就是围绕着评估器进行模型的训练。 同样,围绕评估器的使用也基本分为两步,其一是实例化该对象,其二则是围绕某数据进行模型训练。 接下来,我们就尝试调用 sklearn 中的线性回归评估器(模型)来进行线性回归建模实验。 首先是准备数据,我们还是以此前定义的、基本规律满足
y
=
2
x
1
−
x
2
+
1
y=2x_1-x_2+1
y = 2 x 1 − x 2 + 1
np. random. seed( 24 )
features, labels = arrayGenReg( delta= 0.01 )
features
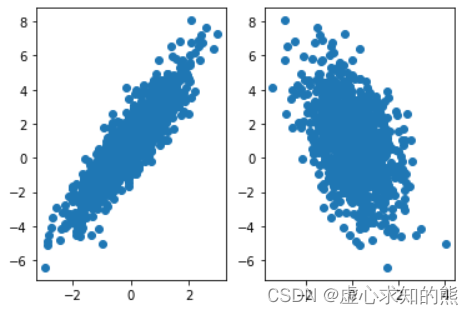
plt. subplot( 121 )
plt. plot( features[ : , 0 ] , labels, 'o' )
plt. subplot( 122 )
plt. plot( features[ : , 1 ] , labels, 'o' )
然后,尝试调用 sklearn 中的线性回归评估器,这里需要知道的是,sklearn 其实是分模块存储不同评估器的类或者常用函数的。 比如 sklearn 中的线性回归评估器 LinearRegression 实际上是在 sklearn 包中的 linear_model 模块下,因此调用该评估器其实会有以下三种方法: (1) 方法一:直接导入 sklearn,然后在 sklearn 里面的 linear_model 模块内查询 LinearRegression 评估器。 import sklearn
sklearn. linear_model. LinearRegression
(2) 方法二:直接导入 sklearn 内的 linear_model 模块,然后在 linear_model 模块内查询 LinearRegression 评估器。 from sklearn import linear_model
linear_model. LinearRegression
(3) 方法三:直接导入 LinearRegression 评估器,然后即可直接查询 LinearRegression 评估器。 from sklearn. linear_model import LinearRegression
LinearRegression
默认情况下,我们采用第三种方法导入评估器。 需要知道的是,导入评估器实际上就相当于是导入了某个模块(实际上是某个类),但要使用这个评估器类,还需要对其进行实例化操作才能进行后续的使用,类的实例化过程会有可选参数的输入,当然也可以不输入任何参数直接实例化该类的对象: model = LinearRegression( )
注意,此时 model 就是 LinearRegression 类的一个实例化对象,而这个 model 对象,其实就是一个线性回归模型。 当然,刚被实例化后的模型实际上还是一个未被训练的模型,即此时的 model 其实是一个包含了若干个(暂时不确定)参数、并且参数取值待定的模型。 接下来,我们需要输入上述数据对该模型进行训练。需要注意的是,此时我们无需在输入的特征矩阵中加入一列全都是 1 的列: X = features[ : , : 2 ]
y = labels
model. fit( X, y)
fit 方法是 LinearRegression 类中的一个至关重要的方法,同时也是 sklearn 中代表模型的评估器都具有的方法,当 fit 方法执行完后,即完成了模型训练。 此时 model 就相当于一个参数个数、参数取值确定的线性方程。而这些包括参数取值在内的所有模型信息,我们都可以通过调用 model 对象当中的一些属性来查看,例如:
model. coef_
model. intercept_
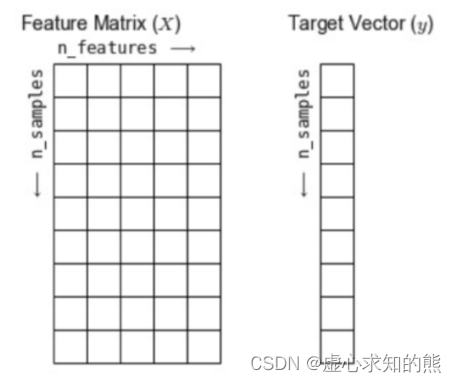
至此,我们就完成了模型训练过程。 这里需要特别强调的是,sklearn 默认接收的对象类型是数组,即无论是特征矩阵还是标签数组,最好都先转化成 array 对象类型再进行输入。 此外,sklearn 还能够处理 array-like 的数据,例如和数组形式相同的列表,但并不建议这么做。 同时,在 sklearn 中,我们往往以称特征矩阵为 Features Matrix,称特征数组为 Target Vector,并且以
n
s
a
m
p
l
e
s
n_{samples}
n s am pl es
n
f
e
a
t
u
r
e
s
n_{features}
n f e a t u res
np. linalg. lstsq( features, labels, rcond= - 1 ) [ 0 ]
接下来,我们还可以利用该模型进行数值预测,我们就将模型应用于训练数据进行预测,可以使用 model 中的 predict 方法进行预测,同样,该方法也是 sklearn 中所有评估器类的一个方法: model. predict( X) [ : 10 ]
y[ : 10 ]
通过对比,我们不难发现发现,模型整体预测效果较好。当然,在借助 sklean 进行建模的时候,我们也可以借助 sklearn 提供的模型评估函数来进行模型最终效果的评估,而这些实用函数,就是 sklearn 算法库中第二类重要的对象类型。 sklearn 中的实用函数 接下来,我们尝试调用 sklearn 中的 MSE 计算函数,对上述建模结果进行模型评估。 值得注意的是,这些调用的对象不再是评估器(类),而是一个个单独的函数。函数的调用过程不需要进行实例化,直接导入相关模块即可:
from sklearn. metrics import mean_squared_error
mean_squared_error( model. predict( X) , y)
l = model. coef_. flatten( ) . tolist( )
l. extend( model. intercept_. tolist( ) )
l
w = np. array( l) . reshape( - 1 , 1 )
w
MSELoss( features, w, y)
至此,我们即完成了调用 sklearn 进行建模的简单流程,当然,在更进一步加入数据预处理、数据集切分以及模型结果验证等步骤之前,我们需要讨论几个至关重要的影响模型建模过程的核心问题: 模型实例化与超参数设置 上述调用 sklearn 进行的机器学习建模,不仅代码简单、而且过程也非常清晰,这些其实全都得益于 Scikit-Learn 对各评估器都设置了较为普适的初始默认参数所导致。 我们知道,每个模型的构建过程其实都会涉及非常多的参数和超参数,参数的训练过程稍后讨论,此处先讨论关于 sklearn 中模型超参数的设置方法。 所谓超参数 ,指的是无法通过数学过程进行最优值求解、但却能够很大程度上影响模型形式和建模结果的因素。 例如线性回归中,方程中自变量系数和截距项的取值是通过最小二乘法或者梯度下降算法求出的最优解,而例如是否带入带入截距项、是否对数据进行归一化等,这些因素同样会影响模型形态和建模结果,但却是“人工判断”然后做出决定的选项,而这些就是所谓的超参数。 而 sklearn 中,对每个评估器进行超参数设置的时机就在评估器类实例化的过程中。 首先我们可以查看 LinearRegression 评估器的相关说明,其中 Parameters 部分就是当前模型超参数的相关说明: LinearRegression?
Name Description fit_intercept 是否构建带有截距项的线性方程,默认为True normalize 是否进行归一化处理(6.2节进行详细介绍) copy_X 建模时是否带入训练数据的副本 n_jobs 设置工作时参与计算的CPU核数
不难发现,这些都是影响建模过程、并且需要人工决策的选项,而这些超参数可以在实例化过程中进行设置,例如我们创建一个不包含截距项的线性方程模型: model1 = LinearRegression( fit_intercept= False )
model1
model1. get_params( )
通过输入模型对象,我们就可以查看该评估器超参数取值情况(默认参数取值不显示),或者可以直接使用 get_params 方法查看模型参数。 而对于一个已经实例化好的评估器,我们都可以通过 set_params 来对其进行参数修改,如果是已经训练好的模型,该方法不会抹去之前训练结果,但会影响下次训练流程。 model1. set_params( fit_intercept= True )
model. set_params( fit_intercept= False )
model. coef_
model. intercept_
model. fit( X, y)
model. coef_, model. intercept_
我们可以简单评估器调用过程过程中各操作的代码意义和建模意义对比如下: 操作步骤 代码意义 建模意义 评估器实例化 类在进行实例化时设置初始属性 对模型进行超参数设置
值得注意,超参数的设置方法和参数不同,一个模型的参数形式基本根据模型的计算规则就能确定,而一个模型包含几个超参数,其实是因模型而异、因工具而异的。 例如,对于 sklearn 来说,我们可以通过 n_jobs来设置参与计算的CPU核数,而在 Spark 中则是通过配置文件中的配置选项来分配每个任务的计算资源,不需要在算法执行过程中设置该超参数。 但无论如何,sklearn 中的超参数设计一定是一整套最符合 sklearn 设计理念以及模型运行方式的超参数,我们在实例化模型的过程中必须谨慎的选择模型超参数,以达到最终模型训练的预期。 不过 sklearn 非常人性化的一点是,尽管大多数模型多有非常多的超参数(线性回归除外),但 sklearn 都对其设置了一套非常普适的默认值,从而使得在很多场景下,在无需特别关注的一些超参数的取值上,我们都能够直接使用默认值带入进行建模。 其实,我们还可以给出超参数的一个更加“广义”的定义:只要是影响模型建模过程的因素都是超参数,例如选取哪种优化方法、甚至是选取哪种算法进行建模,如果需要,我们都可以将其视作超参数,而不仅限于评估器中给出的这些。 当然,如果要围绕这些超参数进行探讨,则需要更多的理论判别依据与实现工具。不过就模型选择来说,其实已经有一些框架能够实现模型的自动选择(不仅是模型自动调参,而是自动对比模型性能进而进行模型选择)。 不过尽管在定义上,参数与超参数是严格不同的,但很多场景下我们也不会对其进行严格区分,比如在实例化评估器的过程中,我们也更多的称其为“进行参数设置”。 需要注意的是,此处线性方程中的 normalize 并不是此前介绍的归一化方法,而是一种用每一行数据除以每一行数据的 l1 范数或者 l2 范数的方法,这种方法会在稍后进行介绍。 此外,我们还能够在类的说明中查阅关于模型对象在训练完后的相关属性,注意,这些属性只有当模型训练完毕后才能调用查看,对于线性方程来说,模型训练后可查看如下属性: Name Description coef_ 线性方程自变量系数 rank_ 特征矩阵的秩 singular_ 特征矩阵的奇异值 intercept_ 线性方程截距项的系数
model. rank_
model1. rank_
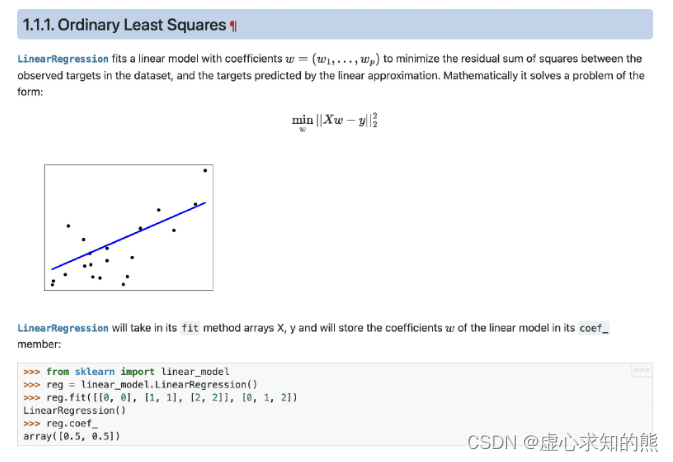
sklean 中线性回归评估器返回结果(属性)实际上就是 np.linalg.lstsq 完整返回的四个结果。 此外,关于评估器的说明文档,还包含了一些相关模型和类的使用实例,同学们可以根据实际需求自行查阅。 训练过程使用的参数求解方法 根据此前的讨论,我们知道,实现线性回归参数计算的方法有很多种,我们可以通过最小二乘法进行一步到位的参数求解,同时也能够通过梯度下降进行迭代求解,而 sklearn 是采用哪种方式进行求解的呢? 需要知道的是,这个问题其实至关重要,它不仅影响了 sklearn 中该算法的执行计算效率,同时也决定了该算法的很多建模特性,例如,如果是采用最小二乘法进行的参数求解,则面临特征矩阵拥有多重共线性时,计算结果将变得不再可靠。 要详细了解训练过程的参数求解方法,就需要回到官网中查阅评估器的相关说明。而 LinearRegression 评估器的相关说明,在 sklearn 官网说明的六大板块(稍后会进行详细介绍)中的 Regression 板块中。
在该模块的 1.1.1.Ordinary Least Squares 中,就是关于 LinearRegression 评估器的相关说明。 从标题就能看出,sklearn 中是通过普通最小二乘法来执行的线性方程参数求解。接下来详细介绍关于 sklearn 中算法解释部分的内容排布。 首先,对于任何一个评估器(算法模型),说明文档会先介绍算法的基础原理、算法公式(往往就是损失函数计算表达式)以及一个简单的例子,必要时还会补充算法提出的相关论文链接,带领用户快速入门。
紧接着,说明文档会对算法的某些特性进行探讨(往往都是在使用过程中需要注意的问题),例如对于普通最小二乘法,最大的问题还是在于特征矩阵出现严重多重共线性时,预测结果会出现较大的误差。 然后,说明文档会例举一个该算法的完整使用过程,也就是穿插在说明文档中的 example。再然后,说明文档会讨论几个在模型使用过程中经常会比较关注的点,对于线性回归,此处列举了两个常见问题,其一是非负最小二乘如何实现,以及最小二乘法的计算复杂度。
对于上述问题,有如下解释。 首先是关于非负最小二乘法,其实本质上就是约束线性方程建模结果中所有参数取值都为正数,以满足某些需求场景;另外关于最小二乘法的复杂度,根据上述说明不难看出,最小二乘法计算复杂度为
O
(
n
s
a
m
p
l
e
s
n
f
e
a
t
u
r
e
s
2
)
O(n_{samples}n^2_{features})
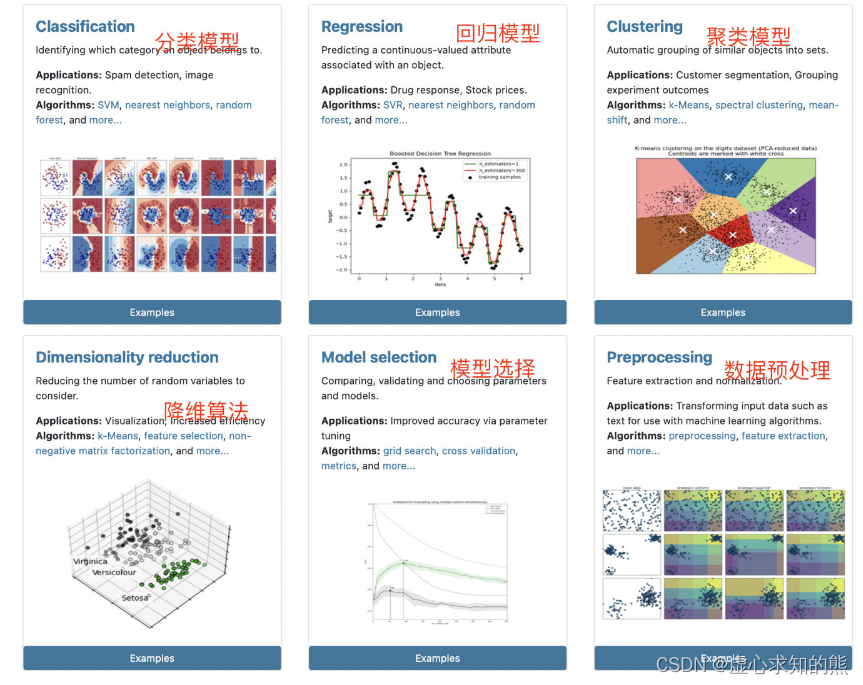
O ( n s am pl es n f e a t u res 2 ) 不难看出,sklearn 官网说明文档非常细致并且非常完整,如果稍加对比,相比目前流行的深度学习框架或者分布式计算框架,sklearn 的说明文档可以说是内容最详细、布局最合理、对初学者用户最友好的官网没有之一。 不过,若要完全参照 sklearn 进行学习,还是会面临一些“问题”。 首先是 API 查询与检索的问题,尽管sklearn官网对所有的评估器进行了六大类的分类、并且将所有的 API 进行了整理并提供了索引的入口,但对于大多数初学者来说,如何快速的找到所需要的评估器和函数,仍然还是一个亟待解决的问题。对此,我们将进行关于 Scikit-Learn 的内容分布于查找的相关介绍。 此外,由于 sklearn 非常完整,包含了目前大多数机器学习算法和几乎全部经典机器学习算法,这也导致 sklearn 中尽管看起来算法种类繁多,但并不是所有算法都有非常广泛的用途,如果是围绕 sklearn 进行算法学习,需要有选择的进行针对性学习。 其三,尽管 sklearn 包含了算法的损失函数和一些基本原理,但限于篇幅,其实 sklearn 的算法解释文档并未对算法的基本原理进行详细介绍,若要深入原理层面进行学习,则还需要额外补充学习材料。 其四,当然也是尤其需要注意的一点,sklearn 为了内置接口的统一性和运算的高效性,很多算法其实都是在原机器学习算法上进行了微调,也就是 sklearn 的实现过程和原始算法的设计流程略微存在区别,这些区别会在后续算法内容学习中逐渐接触到。 不过无论如何,作为一个算法工具迅速定位和查找我们所需的模型(评估器)和函数、以及其他相关内容,都是掌握这门工具之必须,接下来我们就围绕 sklearn 官网的内容布局进行介绍。 sklearn 的六大功能模块 首先,从建模功能上进行区分,sklearn将所有的评估器和函数功能分为六大类,分别是分类模型(Classification)、回归模型(Regression)、聚类模型(Clustering)、降维方法(Dimensionality reduction)、模型选择(Model selection)和数据预处理六大类。
其中分类模型、回归模型和聚类模型是机器学习内主流的三大类模型,其功能实现主要依靠评估器类,并且前两者是有监督学习、聚类模型属于无监督学习范畴。 当然,sklearn 中并未包含关联规则相关算法,如 Apriori 或者 FP-Growth,这其实一定程度上和 sklearn 只能处理 array-like 类型对象有关。而后三者,降维方法、模型选择方法和数据预处理方法,则多为辅助建模的相关方法,并且既有评估器也有实用函数。 值得一提的是,上述六个功能模块的划分其实是存在很多交叉的,对于很多模型来说,既能处理分类问题、同时也能处理回归问题,而很多聚类算法同时也可以作为降维方法实用。 不过这并不妨碍我们从这些功能入口出发,去寻找我们需要的评估器或实用函数。例如线性回归对用评估器可从 Regression 进入进行查找,而对用模型评估指标,由于评估指标最终是指导进行模型选择的,因此模型评估指标计算的实用函数的查找应该从 Model selection 入口进入,并且在 3.3 Metrics and scoring: quantifying the quality of predictions 内。 User Guide:sklearn 所有内容的合集文档 此外,我们可以在最上方的 User Guide 一栏进入 sklearn 所有内容的合集页面,其中包含了 sklearn 的所有内容按照使用顺序进行的排序。如果点击左上方的 Other versions,则可以下载 sklearn 所有版本的 User Guide 的 PDF 版本。
API:按照二级模块首字母排序的接口查询文档 如果想根据评估器或实用函数的名字去查找相关 API 说明文档,则可以点击最上方的 API 一栏进入到根据二极模块首字母排序的 API 查询文档中。 其中二级模块指的是类似包含线性回归的 linear_model 模块或者包含 MSE 的 metrics 模块。
关于源码的阅读 阅读开源算法框架的源码,其实是很多高阶算法工程师自我提升的必经之路。 尽管 sklearn 中出于代码运行速度考虑,有部分算法是用 cython 重写了,但目前大多数代码都在朝着代码可读性和易用性方向发展(降低协作门槛),因此大部分模块的代码还是相对不难读懂的。 不过在初中级阶段、尤其是以调用评估器建模为主的情况下,还是应以熟练掌握常用评估器和实用函数、以及其背后的实现原理为核心进行学习。 以上就是关于 sklearn 官网的整体内容布局介绍,接下来,我们将继续围绕调库建模这一目标,进一步探索与尝试使用更多的 sklearn 中的相关功能。



























 1134
1134











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











