







1、分析目的:
信用卡欺诈的危害性大,如何通过遗忘的交易数据分析出每笔交易是否在正常是分析的主要目的
2、掌握要点:
- 了解逻辑回归分类,以及如何在 sklearn 中使用它;
- 信用卡欺诈属于二分类问题,欺诈交易在所有交易中的比例很小,对于这种数据不平衡的情况,到底采用什么样的模型评估标准会更准确;
- 完成信用卡欺诈分析的实战项目,并通过数据可视化对数据探索和模型结果评估进一步加强了解。
3、构建逻辑回归分类器
逻辑回归,也叫作 logistic 回归。虽然名字中带有“回归”,但它实际上是分类方法,主要解决的是二分类问题,当然它也可以解决多分类问题,只是二分类更常见一些。在逻辑回归中使用了 Logistic 函数,也称为 Sigmoid 函数。
g(z) 的结果在 0-1 之间,当 z 越大的时候,g(z) 越大,当 z 趋近于无穷大的时候,g(z) 趋近于 1。同样当 z 趋近于无穷小的时候,g(z) 趋近于 0。同时,函数值以 0.5 为中心。

在 sklearn 中,使用 LogisticRegression() 函数构建逻辑回归分类器,函数里有一些常用的构造参数:
- penalty:惩罚项,取值为 l1 或 l2,默认为 l2。当模型参数满足高斯分布的时候,使用 l2,当模型参数满足拉普拉斯分布的时候,使用 l1;
- solver:代表的是逻辑回归损失函数的优化方法。有 5 个参数可选,分别为 liblinear、lbfgs、newton-cg、sag 和 saga。默认为 liblinear,适用于数据量小的数据集,当数据量大的时候可以选用 sag 或 saga 方法。
- max_iter:算法收敛的最大迭代次数,默认为 10。
- n_jobs:拟合和预测的时候 CPU 的核数,默认是 1,也可以是整数,如果是 -1 则代表 CPU 的核数。
可以使用 fit 函数拟合,使用 predict 函数预测
4、模型评估指标
之前对模型做评估时,通常采用的是准确率 (accuracy),它指的是分类器正确分类的样本数与总体样本数之间的比例。这个指标对大部分的分类情况是有效的,不过当分类结果严重不平衡的时候,准确率很难反应模型的好坏。
5、精确度和召回率(不平衡数据衡量指标)
数据预测的四种情况:TP、FP、TN、FN。
我们用第二个字母 P 或 N 代表预测为正例还是负例,P 为正,N 为负。
第一个字母 T 或 F 代表的是预测结果是否正确,T 为正确,F 为错误。
所以四种情况分别为:
TP:预测为正,判断正确;
FP:预测为正,判断错误;
TN:预测为负,判断正确;
FN:预测为负,判断错误;
我们知道样本总数 =TP+FP+TN+FN,预测正确的样本数为 TP+TN,
因此准确率 Accuracy = (TP+TN)/(TP+TN+FN+FP)。实际上,对于分类不平衡的情况,有两个指标非常重要,它们分别是精确度和召回率。
- 精确率 P = TP/ (TP+FP),对应上面恐怖分子这个例子,在所有判断为恐怖分子的人数中,真正是恐怖分子的比例。
- 召回率 R = TP/ (TP+FN),也称为查全率。代表的是恐怖分子被正确识别出来的个数与恐怖分子总数的比例。
- F1 作为精确率 P 和召回率 R 的调和平均,数值越大代表模型的结果越好
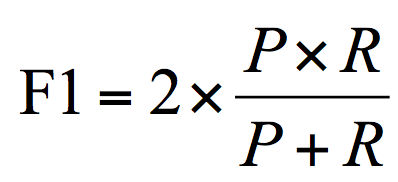
6、案例分析:
1、数据介绍:数据集包括2013年9月份两天内信用卡交易数据,284807笔交易中,有492笔欺诈行为,数据一共包括28个特征,以及对应的交易时间和交易金额,28个特征是按照 PCA变换得到的,字段 class代表 该 笔交易的分类,1代表欺诈,0代表正常。
2、分析目的:针对数据集构建一个用于欺诈分析的分类器,采用逻辑回归。由于欺诈数据只占总数据492/284807=0.172%,因此数据机器不平衡,不能使用准确率来评估模型的好坏,需要使用F1值(综合准确率和召回率)。
3、分析流程:加载数据——准备阶段(探索数据,数据规范化,特征选择,数据集划分)——分类阶段(创建分类器,模型训练,模型评估和可视化展示)
4、具体代码实现:
# -*- coding:utf-8 -*-
# 使用逻辑回归对信用卡欺诈进行分类
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
import itertools
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix, precision_recall_curve
from sklearn.preprocessing import StandardScaler
import warnings
warnings.filterwarnings('ignore')
# 混淆矩阵可视化
def plot_confusion_matrix(cm, classes, normalize = False, title = 'Confusion matrix"', cmap = plt.cm.Blues) :
plt.figure()
plt.imshow(cm, interpolation = 'nearest', cmap = cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation = 0)
plt.yticks(tick_marks, classes)
thresh = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])) :
plt.text(j, i, cm[i 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2318
2318











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









