







jdk、jre、jvm
jdk:首先我们编写java代码我们直接通过.txt文本也是可以进行编写java代码,但是我们需要怎么去运行呢,这就需要javac,就是java编译器,通过java编译器把java文件编译为字节码文件,然后在通过jvm运行我们的代码
jre:jre里面是包括了jvm还有java编译器,所以一般客户电脑上我们就需要安装jre就可以了
jvm:jvm为java虚拟机,jvm就是来执行java编译器编译完成后的字节码文件的。
==、equals、hashCode
==:
1.判断基础类型时比较的是值是否相等
2.判断引用类型时比较的是引用地址是否相等
equls:
1.在不重写的前提上判断的是引用地址是否相等(和==功能类似)
2.重写hashcode和equals以后判断的是值是否相等
hashcode:
在java程序中任何对象都可以调用的自己的hashcode,相当于对象的身份证,按道理这世界上应该不会有身份证相同的情况,但是java做不到那么绝对,但是我们还是可以通过hashcode来进行判断
2个hashcode不相同的对象,两个对象肯定是不同的对象
2个hashcode相同的对象,不代表这两个对象就是同一个对象,也有可能是两个对象
分布式ID生成方式
1.UUID
2.数据库自增ID
3.Redis
4.雪花算法Snowflake:1.所生成的ID按时间递增2.整个分布式系统不会有重复的ID
String、StringBuffer,StringBuilder
从长度方面说:
String一旦创建好,值是不能进行改变的,如果去改变他,他会重新创建一个对象
StringBuffer:值可以改变通过append()方法 线程安全的
StringBuilder:值可以改变通过append()方法 线程不安全的 在单线程的情况下使用StringBuilder效率更高
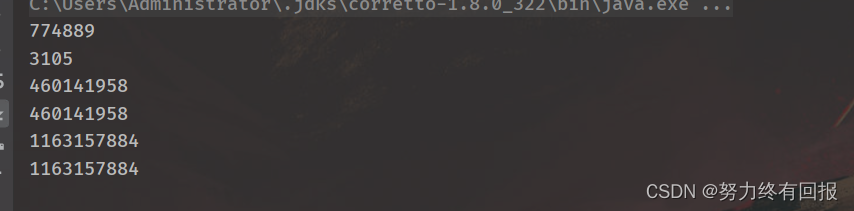
public static void main(String[] args) {
//重新赋值会新建对象
String a="张三";
System.out.println(a.hashCode());
a="ab";
System.out.println(a.hashCode());
//StringBuffer无论append多少hashcode都是一样
StringBuffer sbf=new StringBuffer();
sbf.append("1");
System.out.println(sbf.hashCode());
sbf.append("2");
System.out.println(sbf.hashCode());
//StringBuilder无论append多少hashcode都是一样
StringBuilder sbd=new StringBuilder();
sbd.append("1");
System.out.println(sbd.hashCode());
sbd.append("2");
System.out.println(sbd.hashCode());
}
ApplicationContext和BeanFactory的区别
beanfactory是spring里面非常核心的组件,他可以生产bean,维护bean。ApplicationContext里面是继承了beanFactory所以说ApplicationContext拥有beanfactory所有的特点和功能,并且还继承了EnvironmentCapable,
MessageSource,ApplicationEventPublisher等接口,所以ApplicationContext可以获取系统环境变量,国际化等这是beanfactory所不具备的
ArrayList和LinkedList的区别
首先ArrayList的底层为数组,LinkedList的底层为链表
由来他们底层的数据结构不同,所以说应用的场景有所区别,ArrayList比较适合随机查找,LinkedList更适合删除和添加。
LinkedList还可以当成队列使用,他底层是继承了Deque接口
B树和B+树的区别,为什么mysql要使用B+树
B树的特点:
节点排序。
一个节点可以存储多个元素,并且多个元素也排好序
B+树的特点:
拥有B树的特点
叶子节点之间是有指针的
叶子节点存储了所有的元素,并且都排好序了
mysql为什么要使用b+树,mysql里面索引使用的是b+树,因为索引是用来提供更快查询速度的,通过b+树的排序的特点所以可以提供查询效率。而且使用b+树可以更好的提升全表扫描和指定范围条件的查找的sql语句。
CopyOnWriteArrayList
首先我们应该了解什么是CopyOnWriteArrayList
其实这个底层也是一个数组,这个CopyOnWriteArrayList的特点是,当我们进行写操作的时候,这个会新建一个数组(会上一把锁,为了反正在并发的情况下写的数据丢失这种情况),读的时候不会,感觉就有点像读写分离。当写操作完成以后会把新数组重新指向为原来的那个数组。适合读操作远远大于写操作的时候。
hashMap和hashTable
相同点:
1.都是通过key value的存储方式
2.都是java.util包下的
3.负载因子都是0.75
4.部分方法都系统 比如 put remove get等
不同点:
1.hashmap是线程不安全的,hashtable是线程安全的(通过put方法点击底层可以看见 hashmap没有用synchronized修饰 hashtable使用synchronized修饰)
2.hashmap可以允许null hashtable不允许存储null(通过put方法可以发现hashtable校验了里面的值如果为null会抛出空指针异常)














 1091
1091











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









