






目录
JDK1.6 之后的 synchronized 底层做了哪些优化?
synchronized 和 volatile 有什么区别?
synchronized 和 ReentrantLock 有什么区别?
三大工具类 CountDownLatch、 CyclicBarrier、Semaphore
并发包
我们通常所说的并发包也就是java.util.concurrent及其子包,集中了Java并发的各种基础工具类,具体主要包括几个方面:
1.提供了比synchronized更加高级的各种同步结构,包括CountDownLatch、CyclicBarrier、Semaphore等,可以实现更加丰富的多线程操作。比如利用Semaphore作为资源控制器,限制同时进行工作的线程数量。
2.各种线程安全的容器,比如最常见的ConcurrentHashMap、有序的ConcurrentSkipListMap,或者通过类似快照机制,实现线程安全的动态数组CopyOnWriteArrayList等。
3.各种并发队列实现,如各种BlockingQueue实现,比较典型的ArrayBlockingQueue、SynchorousQueue或针对特定场景的PriorityBlockingQueue等。
什么是悲观锁?
- 悲观锁总是假设最坏的情况,认为共享资源每次被访问的时候就会出现问题(比如共享数据被修改),所以每次在获取资源操作的时候都会上锁,这样其他线程想拿到这个资源就会阻塞直到锁被上一个持有者释放。也就是说,共享资源每次只给一个线程使用,其它线程阻塞,用完后再把资源转让给其它线程。像 Java 中synchronized和ReentrantLock等独占锁就是悲观锁思想的实现。
- 高并发的场景下,激烈的锁竞争会造成线程阻塞,大量阻塞线程会导致系统的上下文切换,增加系统的性能开销。并且,悲观锁还可能会存在死锁问题,影响代码的正常运行。
什么是乐观锁?
- 乐观锁总是假设最好的情况,认为共享资源每次被访问的时候不会出现问题,线程可以不停地执行,无需加锁也无需等待,只是在提交修改的时候去验证对应的资源(也就是数据)是否被其它线程修改了(具体方法可以使用版本号机制或 CAS 算法)。
- 在 Java 中java.util.concurrent.atomic包下面的原子变量类(比如AtomicInteger、LongAdder)就是使用了乐观锁的一种实现方式 CAS 实现的。
- 高并发的场景下,乐观锁相比悲观锁来说,不存在锁竞争造成线程阻塞,也不会有死锁的问题,在性能上往往会更胜一筹。但是,如果冲突频繁发生(写占比非常多的情况),会频繁失败和重试,这样同样会非常影响性能,导致 CPU 飙升
· 悲观锁通常多用于写比较多的情况下(多写场景,竞争激烈),这样可以避免频繁失败和重试影响性能,悲观锁的开销是固定的。不过,如果乐观锁解决了频繁失败和重试这个问题的话(比如LongAdder),也是可以考虑使用乐观锁的,要视实际情况而定。
· 乐观锁通常多于写比较少的情况下(多读场景,竞争较少),这样可以避免频繁加锁影响性能。不过,乐观锁主要针对的对象是单个共享变量(参考java.util.concurrent.atomic包下面的原子变量类)
如何实现乐观锁?
乐观锁一般会使用版本号机制或 CAS 算法实现
版本号机制
一般是在数据表中加上一个数据版本号 version 字段,表示数据被修改的次数。当数据被修改时,version 值会加一。当线程 A 要更新数据值时,在读取数据的同时也会读取 version 值,在提交更新时,若刚才读取到的 version 值为当前数据库中的 version 值相等时才更新,否则重试更新操作,直到更新成功。
CAS 算法
CAS 是一个原子操作,底层依赖于一条 CPU 的原子指令。
CAS 涉及到三个操作数:
- V:要更新的变量值(Var)
- E:预期值(Expected)
- N:拟写入的新值(New)
当且仅当 V 的值等于 E 时,CAS 通过原子方式用新值 N 来更新 V 的值。如果不等,说明已经有其它线程更新了 V,则当前线程放弃更新。
乐观锁存在哪些问题?
1、ABA 问题
- 如果一个变量 V 初次读取的时候是 A 值,并且在准备赋值的时候检查到它仍然是 A 值,那我们就能说明它的值没有被其他线程修改过了吗?很明显是不能的,因为在这段时间它的值可能被改为其他值,然后又改回 A,那 CAS 操作就会误认为它从来没有被修改过。这个问题被称为 CAS 操作的 "ABA"问题。
- ABA 问题的解决思路是在变量前面追加上版本号或者时间戳。JDK 1.5 以后的 AtomicStampedReference 类就是用来解决 ABA 问题的,其中的 compareAndSet() 方法就是首先检查当前引用是否等于预期引用,并且当前标志是否等于预期标志,如果全部相等,则以原子方式将该引用和该标志的值设置为给定的更新值
- 循环时间长开销大
CAS 经常会用到自旋操作来进行重试,也就是不成功就一直循环执行直到成功。如果长时间不成功,会给 CPU 带来非常大的执行开销。
3、只能保证一个共享变量的原子操作
CAS 只对单个共享变量有效,当操作涉及跨多个共享变量时 CAS 无效。但是从 JDK 1.5 开始,提供了AtomicReference类来保证引用对象之间的原子性,你可以把多个变量放在一个对象里来进行 CAS 操作.所以我们可以使用锁或者利用AtomicReference类把多个共享变量合并成一个共享变量来操作
synchronized 关键字
如何使用 synchronized
synchronized 关键字的使用方式主要有下面 3 种:
- 修饰实例方法
- 修饰静态方法
- 修饰代码块
synchronized 底层原理了解吗?
在JVM中,对象是分成三部分存在的:对象头、实例数据、对其填充
对象头是synchronized实现锁的基础,因为synchronized申请锁、上锁、释放锁都与对象头有关。对象头主要结构是由Mark Word 和 Class Metadata Address 组成,其中Mark Word存储对象的hashCode、锁信息或分代年龄或GC标志等信息,Class Metadata Address是类型指针指向对象的类元数据,JVM通过该指针确定该对象是哪个类的实例。
JDK1.6 之后的 synchronized 底层做了哪些优化?
JDK1.6 对锁的实现引入了大量的优化,如偏向锁、轻量级锁、自旋锁、适应性自旋锁、锁消除、锁粗化等技术来减少锁操作的开销。
锁主要存在四种状态,依次是:无锁状态、偏向锁状态、轻量级锁状态、重量级锁状态,他们会随着竞争的激烈而逐渐升级。注意锁可以升级不可降级,这种策略是为了提高获得锁和释放锁的效率。
synchronized 和 volatile 有什么区别?
- · volatile 关键字是线程同步的轻量级实现,所以 volatile性能肯定比synchronized关键字要好 。但是 volatile 关键字只能用于变量而 synchronized 关键字可以修饰方法以及代码块 。
- · volatile 关键字能保证数据的可见性,但不能保证数据的原子性。synchronized 关键字两者都能保证。
- · volatile关键字主要用于解决变量在多个线程之间的可见性,而 synchronized 关键字解决的是多个线程之间访问资源的同步性
ReentrantLock
ReentrantLock 是什么?
- ReentrantLock 实现了 Lock 接口,是一个可重入且独占式的锁,和 synchronized 关键字类似。不过,ReentrantLock 更灵活、更强大,增加了轮询、超时、中断、公平锁和非公平锁等高级功能
- ReentrantLock 里面有一个内部类 Sync,Sync 继承 AQS(AbstractQueuedSynchronizer),添加锁和释放锁的大部分操作实际上都是在 Sync 中实现的。Sync 有公平锁 FairSync 和非公平锁 NonfairSync 两个子类
公平锁和非公平锁有什么区别?
- 公平锁 : 锁被释放之后,先申请的线程先得到锁。性能较差一些,因为公平锁为了保证时间上的绝对顺序,上下文切换更频繁。
- 非公平锁:锁被释放之后,后申请的线程可能会先获取到锁,是随机或者按照其他优先级排序的。性能更好,但可能会导致某些线程永远无法获取到锁
synchronized 和 ReentrantLock 有什么区别?
1、两者都是可重入锁
可重入锁 也叫递归锁,指的是线程可以再次获取自己的内部锁。比如一个线程获得了某个对象的锁,此时这个对象锁还没有释放,当其再次想要获取这个对象的锁的时候还是可以获取的,如果是不可重入锁的话,就会造成死锁。
2、synchronized 依赖于 JVM 而 ReentrantLock 依赖于 API
- synchronized 是依赖于 JVM 实现的,前面我们也讲到了 虚拟机团队在 JDK1.6 为 synchronized 关键字进行了很多优化,但是这些优化都是在虚拟机层面实现的,并没有直接暴露给我们。
- ReentrantLock 是 JDK 层面实现的(也就是 API 层面,需要 lock() 和 unlock() 方法配合 try/finally 语句块来完成),所以我们可以通过查看它的源代码,来看它是如何实现的。
3、ReentrantLock 比 synchronized 增加了一些高级功能

可中断锁和不可中断锁有什么区别?
- 可中断锁:获取锁的过程中可以被中断,不需要一直等到获取锁之后 才能进行其他逻辑处理。ReentrantLock 就属于是可中断锁。
- 不可中断锁:一旦线程申请了锁,就只能等到拿到锁以后才能进行其他的逻辑处理。 synchronized 就属于是不可中断锁。
ReentrantReadWriteLock
ReentrantReadWriteLock 是什么?
ReentrantReadWriteLock 实现了 ReadWriteLock ,是一个可重入的读写锁,既可以保证多个线程同时读的效率,同时又可以保证有写入操作时的线程安全
共享锁和独占锁有什么区别?
ReentrantReadWriteLock 适合什么场景?
由于 ReentrantReadWriteLock 既可以保证多个线程同时读的效率,同时又可以保证有写入操作时的线程安全。因此,在读多写少的情况下,使用 ReentrantReadWriteLock 能够明显提升系统性能。
线程持有读锁还能获取写锁吗?

读锁为什么不能升级为写锁?

StampedLock 是什么?
StampedLock 是 JDK 1.8 引入的性能更好的读写锁,不可重入且不支持条件变量 Conditon。

ThreadLocal 简介
- ThreadLocal 给每个线程都创建了一个自己内部的副本变量,且其它线程不可访问,那就不存在多线程间共享的问题。
- 最终的变量是放在了当前线程的 ThreadLocalMap 中,并不是存在 ThreadLocal 上,ThreadLocal 可以理解为只是ThreadLocalMap的封装,传递了变量值。
- 每个Thread中都具备一个ThreadLocalMap,而ThreadLocalMap可以存储以ThreadLocal为 key ,Object 对象为 value 的键值对。
ThreadLocal 内存泄露问题是怎么导致的?
- ThreadLocalMap 中使用的 key 为 ThreadLocal 的弱引用,而 value 是强引用。所以,如果 ThreadLocal 没有被外部强引用的情况下,在垃圾回收的时候,key 会被清理掉,而 value 不会被清理掉。这样一来,ThreadLocalMap 中就会出现 key 为 null 的 Entry。假如我们不做任何措施的话,value 永远无法被 GC 回收,这个时候就可能会产生内存泄露。
- ThreadLocalMap 实现中已经考虑了这种情况,在调用 set()、get()、remove() 方法的时候,会清理掉 key 为 null 的记录。使用完 ThreadLocal方法后最好手动调用remove()方法
线程池
为什么要用线程池?

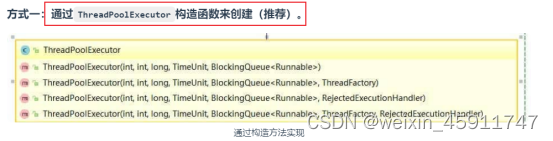
如何创建线程池?

为什么不推荐使用内置线程池?
- 更加明确线程池的运行规则,规避资源耗尽的风险
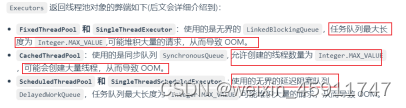
线程池常见参数有哪些?如何解释?


线程池的饱和策略有哪些?

线程池常用的阻塞队列有哪些?

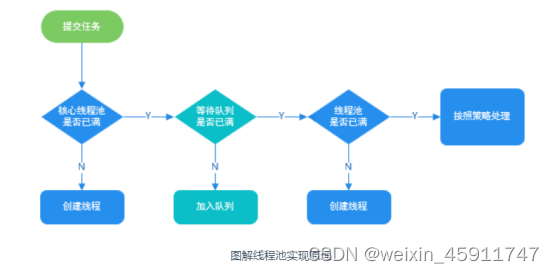
线程池处理任务的流程了解吗?

如何设定线程池的大小?

execute和submit
execute()用于提交不需要返回值的任务,所以无法判断任务是否被线程池执行成功
submit()用于提交需要返回值的任务。线程池会返回一个future类型的对象,通过future对象可以判断任务是否执行成功,并且可以通过future的get()方法获取返回值,get()会阻塞当前线程直到任务执行完成。
使用get(long timeout,TimeUnit unit)会阻塞当前线程一段时间后立即返回,这时有可能任务没有执行完
关闭线程池
调用shutdown或shutdownNow方法,原理:遍历线程池中的工作线程,然后逐个调用线程的interrupt方法来中断线程,所以无法响应中断的任务可能永远无法终止
shutdownNow先将线程池状态设置为STOP,然后尝试停止所有正在执行或暂停任务的线程,并返回等待执行任务的列表
shutdown只是将线程池的状态设置成SHUTDOWN状态,然后中断所有没有正在执行任务的线程
只要用两个关闭方法的任意一个,isShutdown就会返回true,当所有任务关闭后,才表示线程池关闭成功,这时调用isTerminaed会返回true
Future 类有什么用?
Future 类获取到耗时任务的执行结果,FutureTask相当于对Callable 进行了封装,管理着任务执行的情况,存储了 Callable 的 call 方法的任务执行结果
AQS
AQS 是什么?
抽象队列同步器,主要用来构建锁和同步器,使用 AQS 能简单且高效地构造出应用广泛的大量的同步器,比如我们提到的 ReentrantLock,Semaphore,其他的诸如 ReentrantReadWriteLock,SynchronousQueue等等皆是基于 AQS 的。
AQS 的原理是什么?
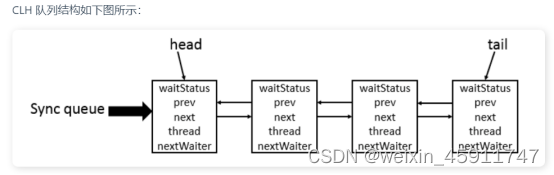
- AQS 核心思想是,如果被请求的共享资源空闲,则将当前请求资源的线程设置为有效的工作线程,并且将共享资源设置为锁定状态。如果被请求的共享资源被占用,那么就需要一套线程阻塞等待以及被唤醒时锁分配的机制,这个机制 AQS 是用 CLH 队列锁 实现的,即将暂时获取不到锁的线程加入到队列中。
- CLH(Craig,Landin,and Hagersten) 队列是一个虚拟的双向队列(虚拟的双向队列即不存在队列实例,仅存在结点之间的关联关系)。AQS 是将每条请求共享资源的线程封装成一个 CLH 锁队列的一个结点(Node)来实现锁的分配。在 CLH 同步队列中,一个节点表示一个线程,它保存着线程的引用(thread)、 当前节点在队列中的状态(waitStatus)、前驱节点(prev)、后继节点(next)
- AQS 使用 int 成员变量 state 表示同步状态,通过内置的 线程等待队列 来完成获取资源线程的排队工作。
- 以 ReentrantLock 为例,state 初始值为 0,表示未锁定状态。A 线程 lock() 时,会调用 tryAcquire() 独占该锁并将 state+1 。此后,其他线程再 tryAcquire() 时就会失败,直到 A 线程 unlock() 到 state=0(即释放锁)为止,其它线程才有机会获取该锁。当然,释放锁之前,A 线程自己是可以重复获取此锁的(state 会累加),这就是可重入的概念。但要注意,获取多少次就要释放多少次,这样才能保证 state 是能回到零态的。
- 再以 CountDownLatch 以例,任务分为 N 个子线程去执行,state 也初始化为 N(注意 N 要与线程个数一致)。这 N 个子线程是并行执行的,每个子线程执行完后countDown() 一次,state 会 CAS(Compare and Swap) 减 1。等到所有子线程都执行完后(即 state=0 ),会 unpark() 主调用线程,然后主调用线程就会从 await() 函数返回,继续后余动作。
Semaphore 有什么用?
synchronized 和 ReentrantLock 都是一次只允许一个线程访问某个资源,而Semaphore(信号量)可以用来控制同时访问特定资源的线程数量。
Semaphore 的原理是什么?
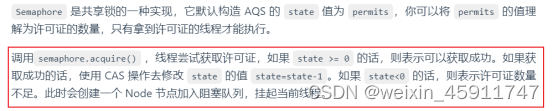

CountDownLatch 有什么用?
- CountDownLatch 允许 count 个线程阻塞在一个地方,直至所有线程的任务都执行完毕。
- CountDownLatch 是一次性的,计数器的值只能在构造方法中初始化一次,之后没有任何机制再次对其设置值,当 CountDownLatch 使用完毕后,它不能再次被使用。
CountDownLatch 的原理是什么?

用过 CountDownLatch 么?什么场景下用的?

CyclicBarrier 有什么用?
CyclicBarrier 的字面意思是可循环使用(Cyclic)的屏障(Barrier)。它要做的事情是:让一组线程到达一个屏障(也可以叫同步点)时被阻塞,直到最后一个线程到达屏障时,屏障才会开门,所有被屏障拦截的线程才会继续干活
CyclicBarrier 的原理是什么?
CyclicBarrier 内部通过一个 count 变量作为计数器,count 的初始值为 parties 属性的初始化值,每当一个线程到了栅栏这里了,那么就将计数器减 1。如果 count 值为 0 了,表示这是这一代最后一个线程到达栅栏,就尝试执行我们构造方法中输入的任务。
三大工具类 CountDownLatch、 CyclicBarrier、Semaphore
















 126
126











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









