







 本文详述了一位管理员在遇到Kubernetes集群中节点频繁出现notready状态,Pod更新延迟以及容器挂死等问题时的排查过程。通过检查资源、日志、Docker容器状态,并最终定位到挂死的异常容器,成功解决了问题。解决方案包括清理异常容器和重启Docker服务。
本文详述了一位管理员在遇到Kubernetes集群中节点频繁出现notready状态,Pod更新延迟以及容器挂死等问题时的排查过程。通过检查资源、日志、Docker容器状态,并最终定位到挂死的异常容器,成功解决了问题。解决方案包括清理异常容器和重启Docker服务。
项目场景:
环境情况:kubeadmin部署的k8s集群,版本1.22.1,docker版本20.10.7
现象: kubectl get pod 发现pod长时间处于containercreating状态/或者kubectl get node时node节点长时间处于notready状态/或者kubectl get node时node节点状态一会儿ready一会儿notready状态之间相互转换/pod长时间不更新状态
过段时间后hz-cs2上的pod状态就会全变terminating
问题描述
问题描述:k8s集群过一段时间就会有节点notready,有时候是一直notready,有时候是一会儿notready一会儿ready状态,有的环境是是ready状态,但piod状态更新很慢,时间估计有5到8分钟状态才更新为Runnning ,看日志硬是找不到原因,百度也找不到解决方案。
1.node节点状态异常,notready
# kubectl get node
# 其中一个node,notready了,尝试重启kubelet均无效果
#重启kubelet: systemctl restart kubelet

2.describe node 一下 看看
# kubectl describe node hz-cs2
#效果如图


从这里看就非常奇怪了,毕竟一般notready状态的原因都是资源问题导致的,咱们这里没有给出任何原因,资源也是充足的
3.在hz-cs2上top看看
# top
# top看一下负载
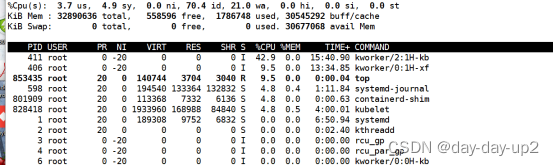
cpu等负载都不高非常正常,这也是这个问题的难点所在。毕竟网上的结论都是说资源负载导致的。真的是我们不一样呀!
4.看看kubelet日志
# journalctl -xeu kubelet
# 日志如图


看到这没有一点关键信息,毕竟这里的runtime status check may not have complet只是表像。百度一下会发现没有符合我们的情况答案。这就难整了。日志给的是表象没有给具体根因
5.把kubelet的日志级别设置为4,或者6
# vim /usr/lib/systemd/system/kubelet.service
# 添加 --v=6 编辑保存
# systemctl daemon-reload
# systemctl restart kubelet
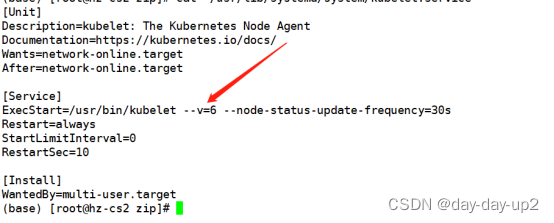
然并卵。kubelet日志还是和4一模一样
6.查阅多方资料后断定是kubelet调用docker超时导致的问题。网上的解决方案众说纷纭。一 一实践后,均无果
7.既然是docker出问题了,那就给个临时解决方案吧:
# systemctl restart docker
8.以上7步骤补充说明,对大部分环境有效。所以强烈建议先不做7.请把7放一下先往下走。Master节点上如果有业务pod有可能重启会导致k8s容器起不来,最后解决起来比较棘手。这里要写的话又是一堆细节要写,我们在此止步
9.追根朔源吧。分析docker日志
# journalctl -xeu docker
徒劳无果,也是一堆表象报错和业务容器报错。让人眼花缭乱,无从下手。
10.docker ps试试看看有没有hang死的容器
# docker ps

正常,docker命令均正常
怀疑人生了,看似是docker问题,却从日志下不了手呀,兄弟们!
11.docker ps -a |grep -vi up看看有没有异常的业务容器
# docker ps -a |grep -vi up

试着清理一下,docker rm f8b1580354b3
# docker rm f8b1580354b3
结果不出所料执行命令:
# docker rm b008f63cc944
# docker inspect b008f63cc944
# docker start b008f63cc944
都hang死了
12.有眉目了,兄弟们,试试将这个hang死的异常容器删除
docker rm b008f63cc944 这条命令肯定是不奏效了
咱们换一种方式删除:
# cd /var/lib/docker/containers
# ls |grep b008f63cc944
# docker start b008f63cc944
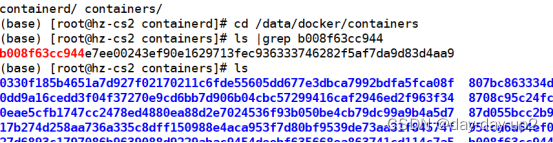
# rm -rf b008f63cc944e7ee00243ef90e1629713fec936333746282f5af7da9d83d4aa9
# cd /var/run/docker/containerd
# ls |grep b008f63cc944
# rm -rf b008f63cc944e7ee00243ef90e1629713fec936333746282f5af7da9d83d4aa9
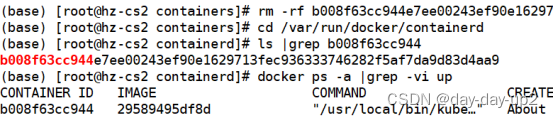
# docker rm -f b008f63cc944
仍然hang死,继续操作
# ps aux |grep b008f63cc944

# ps aux |grep b008f63cc944 |grep -v grep | awk '{print $1 $2}'

# kill -9 802575
# ps aux |grep b008f63cc944 |grep -v grep | awk '{print $1 $2}'
# docker rm -f b008f63cc944
到此处理完毕。
12.到此处理完毕。
# kubectl get node
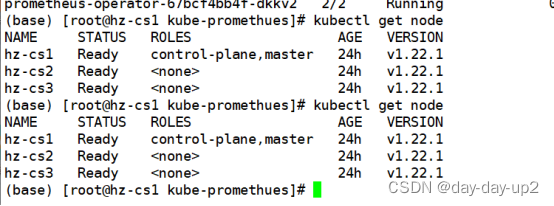
立马就状态正常了
13.kubectl get pod 看看
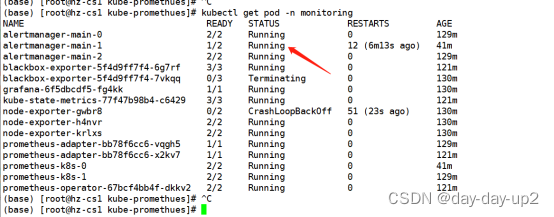
正常了
解决方案:
方案1.做第7步重启docker,暂时不推荐做第7步。对于master结点不一定奏效
方案2.走以上步骤,走一遍。推荐走方案2
点评:
以上为生产实践及个人总结得出的解决方案,网络上对此问题几乎无正确解决方案。纯属原创作品,请大家转载注明出处!
原文地址



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











