






 该文详细介绍了如何使用Python进行数据可视化,以鸢尾花数据集为例,展示了16种不同类型的关系图和6种统计分析图,包括箱型图、小提琴图、散点图、直方图、热力图、平行坐标图等,并涉及正态分布检验、回归图的绘制。此外,还提供了数据预处理步骤,将目标值转换为易于理解的鸢尾花品种。
该文详细介绍了如何使用Python进行数据可视化,以鸢尾花数据集为例,展示了16种不同类型的关系图和6种统计分析图,包括箱型图、小提琴图、散点图、直方图、热力图、平行坐标图等,并涉及正态分布检验、回归图的绘制。此外,还提供了数据预处理步骤,将目标值转换为易于理解的鸢尾花品种。
背景描述
数据分析中离不开对数据的相关性分析,并且需要把这些相关性进行可视化(绘图),以方便人们对各种特征属性之间呈现出来的相关性有更直接、清晰的感知和理解,提升数据的价值和数据挖掘的效益。本文以“鸢尾花数据集”为基础,主要关注于各种关系图的绘制,以及统计分析的数据可视化,提供和展示了16种关系图及6种统计分析图和回归图的方法(详见以下目录)。
由于从sklearn中获取的“鸢尾花”数据集中,目标值(iris.target)是“0”和“1”,这种类型的数据方便实现“机器学习”的建模,但是在数据绘图中不利于理解,因此我们会把数据集中的目标值与鸢尾花的品种(species)进行关联,转换为新的数据集,以获取更好的可视化结果。
目录
第一部分:鸢尾花数据集的获取、转换并保存为csv文件
第二部分:关系图
1. 箱型图
2. 小提琴图 -- violinplot()
3. 分簇散点图
4. 散点图 与 relplot()函数 (附时间序列图示例)
5. 散点矩阵图
6. 直方图矩阵
7. 密度图
8. 直方密度线图
9. 热力图及半角热力图(半三角)
10. 平行坐标图
11. 多变量联合分布图 -- pairplot() 函数
12. 多组分类重叠密度图 -- joy plot() 函数
13. 联合分布图 -- jointplot() 函数
第三部分:统计分析图表及回归图
1. 检验是否符合正态分布 -- p_test, Skewness(), Kurtosis()的计算
2. 正态概率分布图
3. 正态分布图 -- norm.pdf() 函数的计算与绘制
4. 回归图 -- lmplot() 函数
5. 回归图 -- regplot() 函数
6. 回归图 -- lmplot() 函数
示例代码(Python代码):
第一部分:鸢尾花数据集的获取与转换
**鸢尾花数据集(Iris数据集)**是一类多重变量分析的数据集。数据集包含150个数据样本,分为3类,每类50个数据,每个数据包含4个属性。通过花萼长度,花萼宽度,花瓣长度,花瓣宽度4个属性可以预测鸢尾花卉属于(Setosa,Versicolour,Virginica)三个种类中的哪一类。原数据集的目标值(iris.target)是“0”和“1”,但在数据可视化展示的时候,为了更清晰容易地理解数据的分类,我们需要将数据集中的目标值与鸢尾花的品种连接起来,即:把数据集中的编号"iris.target"与鸢尾花的品种连接,转换为新的数据集。
import numpy as np
import pandas as pd
import sklearn
from sklearn import datasets
# 从sklearn中获取鸢尾花数据集,并转换为DataFrame
iris = datasets.load_iris()
dataset = pd.DataFrame(iris.data, columns=iris.feature_names)
# 或:更新特征列的名称,如“sepal_length”
# columns = [x.strip("(cm)").strip().replace(" ", "_") for x in iris.feature_names]
# dataset = pd.DataFrame(iris.data, columns=columns)
dataset["target"]= iris.target
# 对数据集中的目标值进行鸢尾花品种的转换
dict_species = dict(zip(np.array([0, 1, 2]), iris.target_names,))
# dict_species
dataset["speices"] = dataset["target"].map(dict_species)
# 将整理好的数据集以csv文件的形式保存下来,也可以保存为Excel 文件
outputfile = r"d:/iris.csv"
dataset.to_csv(outputfile)
dataset.info()

保存下来的csv文件
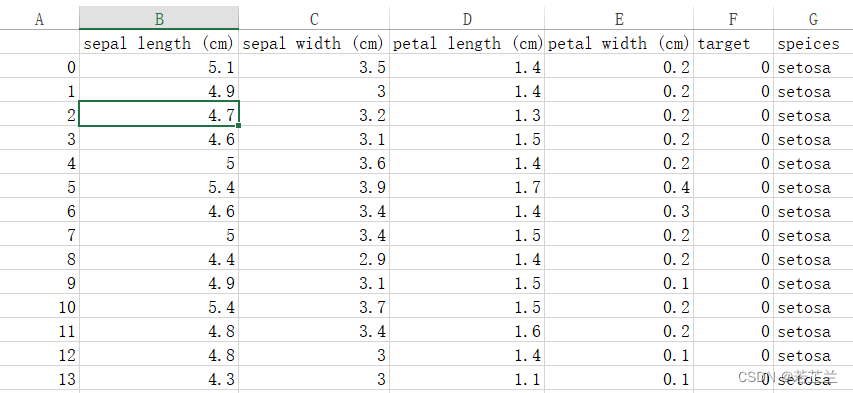
第二部分:关系图的绘制
1. 箱型图
# 1.1 绘制箱型图 -- 根据不同类别的数据绘制箱型图
data = dataset.drop(columns=["species"])
plt.boxplot(data, labels=data.columns, showmeans=True)
plt.show()
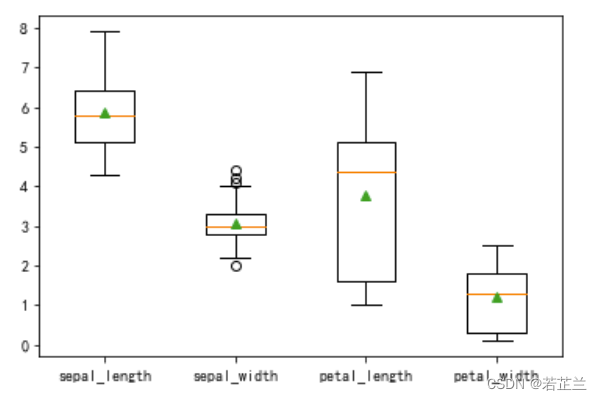
# 1. 2 绘制箱型图 -- 按鸢尾花的品种展示花萼长度和花瓣长度
fig, axes = plt.subplots(1, 2, figsize=(10, 5))
sns.boxplot(x="species", y="sepal_length", data=dataset, ax=axes[0])
sns.boxplot(x="species", y="petal_length", data=dataset, ax=axes[1])
plt.show()
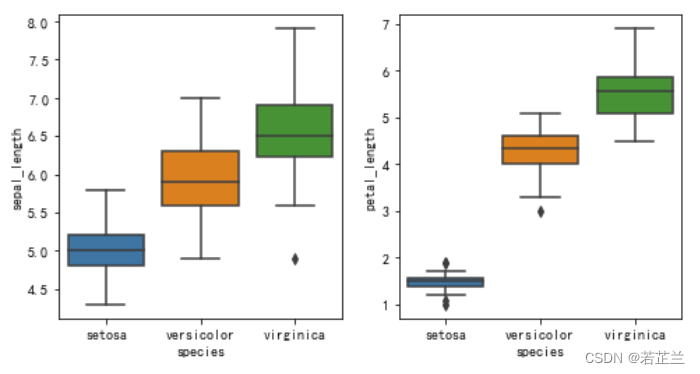
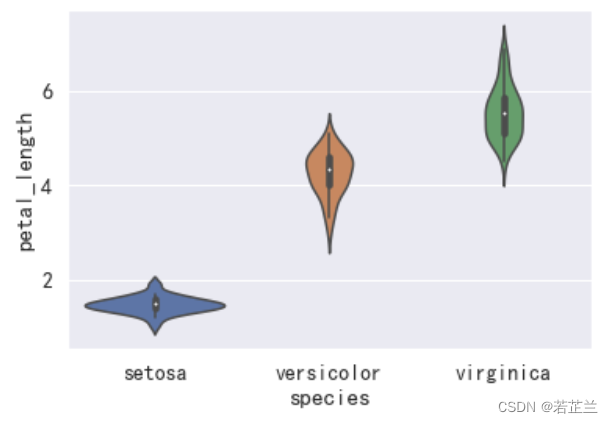
2. 小提琴图 – violinplot() 函数
# 绘制小提琴图
import seaborn as sns
sns.violinplot(x="species", y="petal_length", data=dataset)
plt.show()
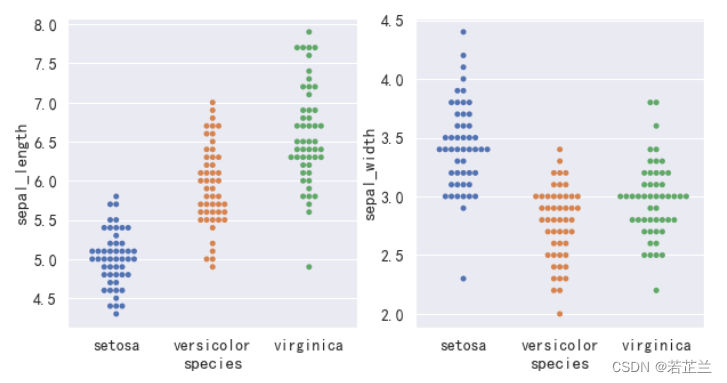
3. 分簇散点图
# 分簇散点图
fig, axes = plt.subplots(1, 2, figsize=(10, 5))
sns.swarmplot(x="species", y="sepal_length", data=dataset, ax=axes[0])
sns.swarmplot(x="species", y="sepal_width", data=dataset, ax=axes[1])
plt.show()
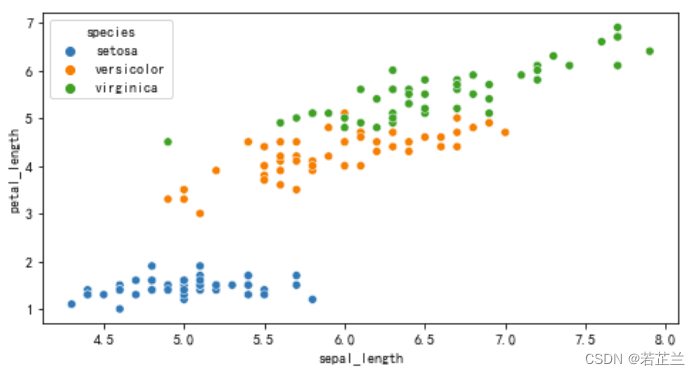
4. 散点图
# 4.1 绘制散点图
fig = plt.subplots(1, 1, figsize=(8, 4))
sns.scatterplot(x="sepal_length", y="petal_length", hue="species", data=dataset)
plt.show()
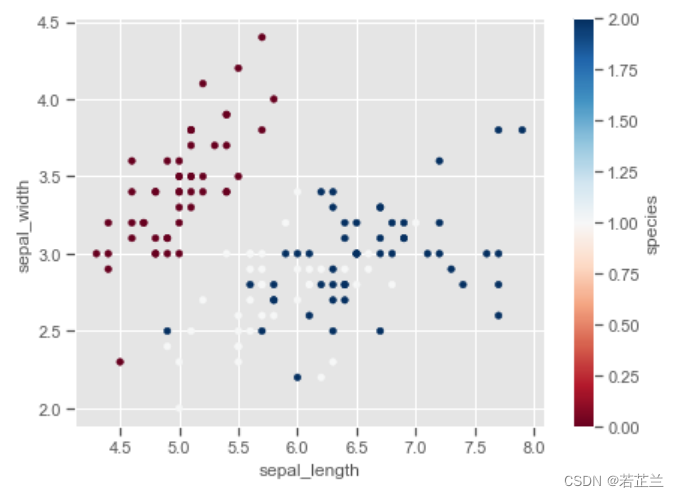
# 4.2 散点图 -- 以颜色条区分类别
plt.style.use("ggplot")
plt.figure(figsize=(7, 5))
cmap = plt.cm.get_cmap("RdBu")
sc = plt.scatter(x=dataset["sepal_length"], y=dataset["sepal_width"], c=iris.target, s=20, cmap=cmap)
bar = plt.colorbar(sc)
bar.set_label("species")
plt.xlabel("sepal_length")
plt.ylabel("sepal_width")
plt.show()
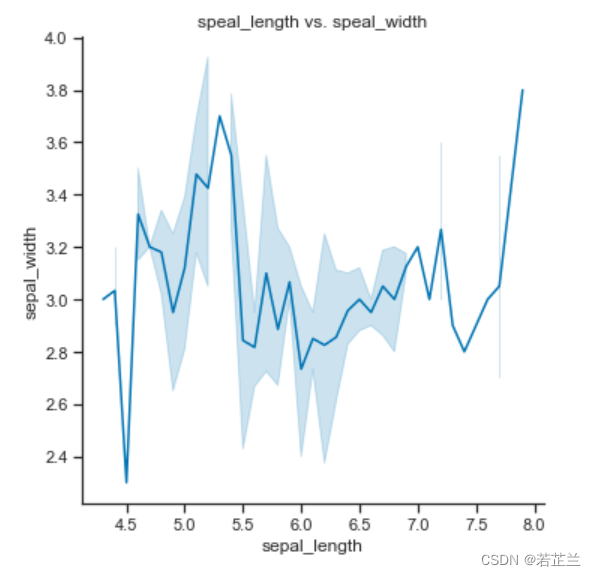
# 4.3 relplot()函数 -- 设置kind="line"
import seaborn as sns
sns.set(style="ticks", palette="colorblind", color_codes=True)
sns.relplot(x = "sepal_length", y="sepal_width", data=dataset, kind="line")
plt.title("speal_length vs. speal_width")
plt.show()
# 4.4 relplot()函数 -- 设置kind="scatter"
sns.relplot(x ="sepal_length", y="sepal_width", data=dataset)
plt.title("speal_length vs. speal_width (scatter)")
plt.show()
# 4.5 relplot()函数 -- 设置kind="scatter",并通过hue参数做类别区分
sns.set(style="darkgrid", palette="muted", color_codes=True)
sns.relplot(x="sepal_length", y="sepal_width", hue="species",
size="species", sizes=(50, 120), style="species", data=dataset)
plt.title("speal_length vs. speal_width (by species)")
plt.show()
# 4.6 replot()函数绘制时间序列图的示例(本示例是样品的序列号)
sns.set(style="whitegrid", palette="muted", color_codes=True)
sns.relplot(x=dataset.index, y="sepal_length", data=dataset,
hue="species", style="species", kind="line")
plt.title("sepal_length by index")
plt.show()
5. 散点矩阵图
# 5.1 绘制散点图矩阵示例
import seaborn as sns
sns.set(style="ticks")
sns.pairplot(dataset, vars=["sepal_length", "petal_length"])
plt.show()
# 5.2 设定hue参数以区分不同的种类
import seaborn as sns
sns.set(style="ticks")
sns.pairplot(dataset, vars=["sepal_length", "petal_length"], hue="species")
plt.show()
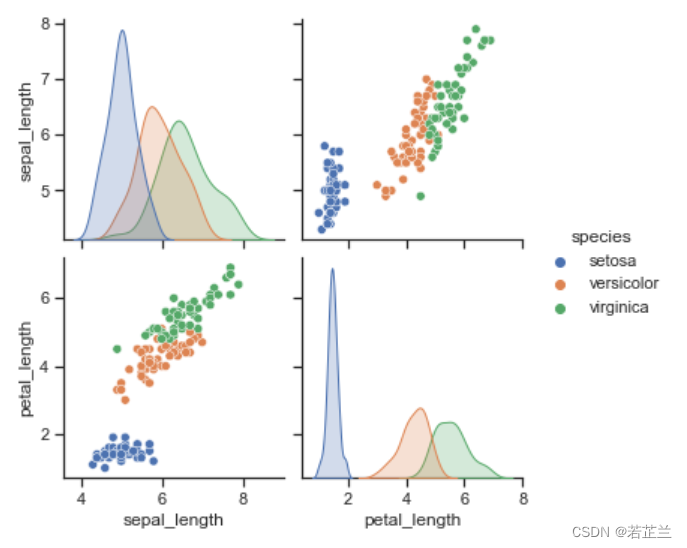
6. 直方图矩阵
# 绘制直方图矩阵 -- 对数据集中的所有特征属性绘制直方图
dataset.hist(sharex=True)
plt.show()
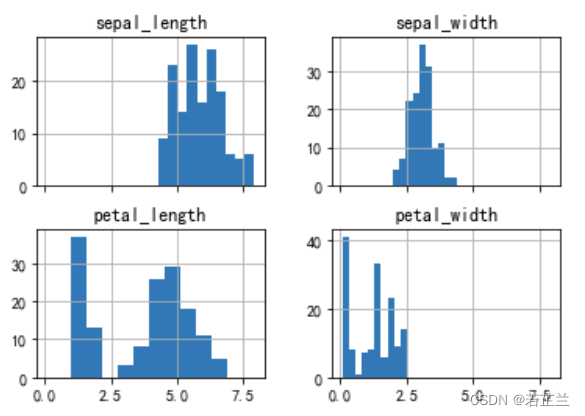
7. 绘制密度图
# 绘制密度图 -- 整个数据集
dataset.plot(kind="kde")
plt.show()
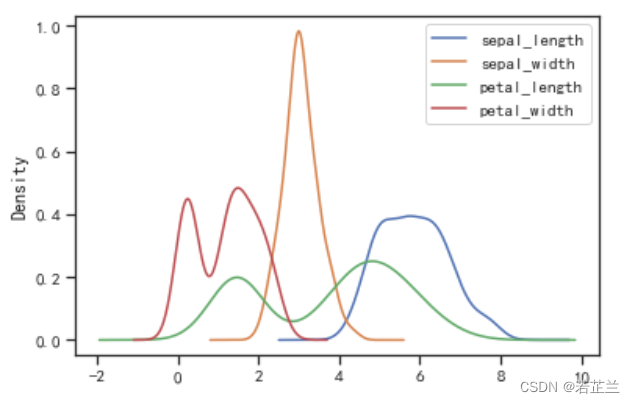
8. 直方密度线图
# 绘制直方密度线图 -- 并按不同品种分别呈现sepal_length数据的分布情况
import seaborn as sns
# kde: 是否显示数据分布曲线,默认为False
sns.displot(x="sepal_length", data=dataset, bins=20, kde=True, hue="species")
plt.show()
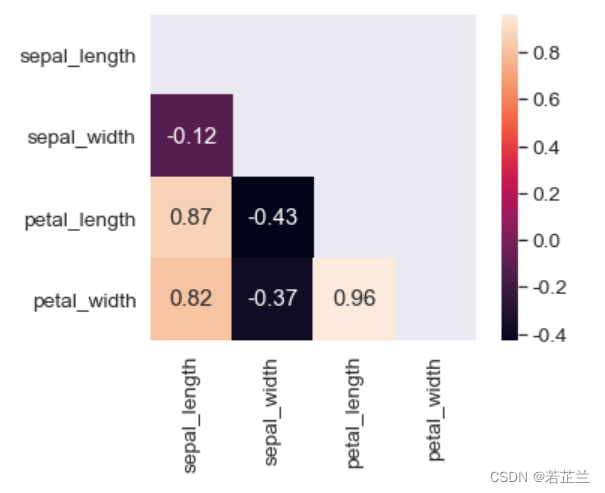
9. 热力图以及半角热力图
# 9.1 绘制热力图
data = dataset.drop(columns=["target"])
corrmat = data.corr()
k = 4
# 排序:根据相关性程度从大到小进行排序(选定1个特征属性作为对照)
cols = corrmat.nlargest(k, "sepal_length")["sepal_length"].index
cm = np.corrcoef(data[cols].values.T)
sns.set(font_scale=1.25)
hm = sns.heatmap(cm, cbar=True, annot=True, square=True, fmt=".2f", annot_kws={"size": 10},
yticklabels=cols.values, xticklabels=cols.values)
plt.show()
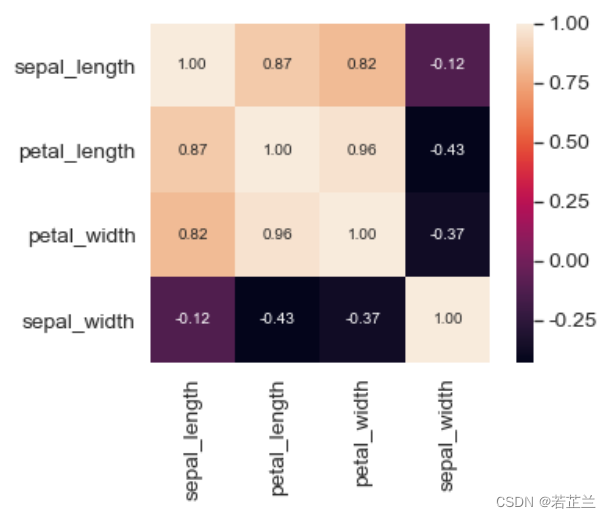
# 9.2 构建半角热力图:方法一
corrmat = data.corr()
mask = np.ones_like(corrmat)
num = 4
mask[np.tril_indices(num)] = 0. # 上三角被屏蔽
# mask[np.triu_indices(num)] = 0. # 下三角被屏蔽
sns.heatmap(corrmat, cbar=True, square=True, fmt=".2f", mask=mask,
annot=True, yticklabels=cols.values, xticklabels=cols.values)
plt.show()
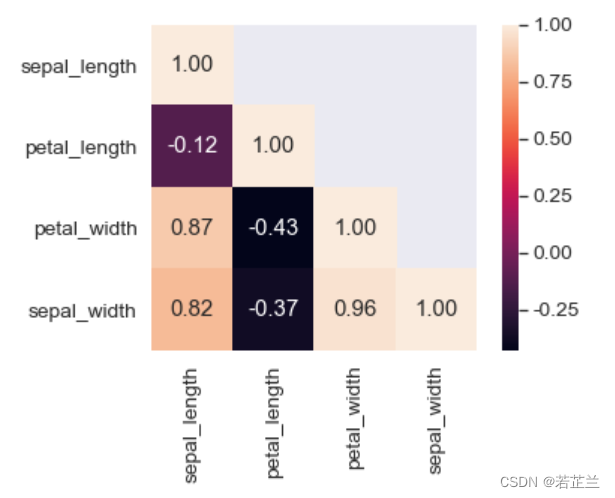
# 9.3 构建半角热力图:方法二
corrmat = data.corr()
mask = np.zeros_like(corrmat)
# 将mask的对角线及以上设置为True
mask[np.triu_indices_from(mask)] = True
sns.heatmap(corrmat, mask=mask, square=True, annot=True, fmt="0.2f")
plt.show()
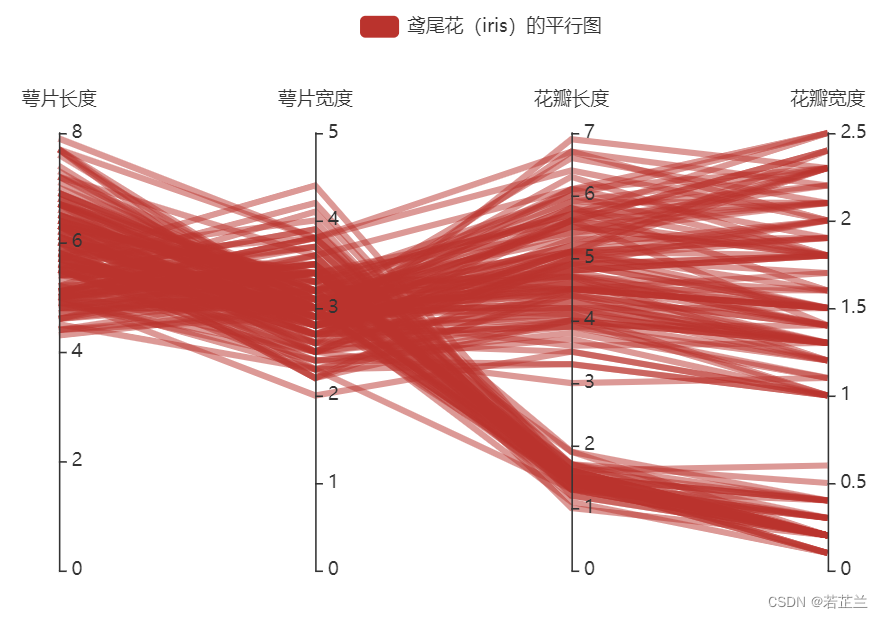
10. 平行坐标图
平行坐标图(Paralllel Coordinates Plot) 是对于具有多个属性的一种可视化方法,可解决在维度增加时,散点矩阵变得不太有效的问题。在平行坐标图中,数据集的一行数据在平行坐标图中用一条折线表示,纵向是属性,横向是属性类别。安装方法:pip install pyecharts
# 绘制数据的平行坐标图示例
from pyecharts.charts import Parallel
import pyecharts.options as opts
import seaborn as sns
import numpy as np
data_ = np.array(dataset[["sepal_length", "sepal_width", "petal_length", "petal_width"]]).tolist()
parallel_axis = [{"dim": 0, "name": "萼片长度"},
{"dim": 1, "name": "萼片宽度"},
{"dim": 2, "name": "花瓣长度"},
{"dim": 3, "name": "花瓣宽度"}]
parallel = Parallel(init_opts=opts.InitOpts(width="600px", height="400px"))
parallel.add_schema(schema=parallel_axis)
parallel.add("鸢尾花(iris)的平行图", data=data_, linestyle_opts=opts.LineStyleOpts(width=4, opacity=0.5))
parallel.render_notebook()
11. 多变量联合分布图 – pairplot() 函数
11.1 以散点图的形式循环展示数据属性之间的相关性
# 11.1:绘制以散点图的形式展示数据属性之间的相关性
import seaborn as sns
plt.figure(figsize=(10, 8), dpi=80)
plot_setting = dict(s=80, edgecolor="white", linewidth=2.5)
sns.pairplot(dataset, kind="scatter", hue="species", plot_kws=plot_setting)
plt.show()
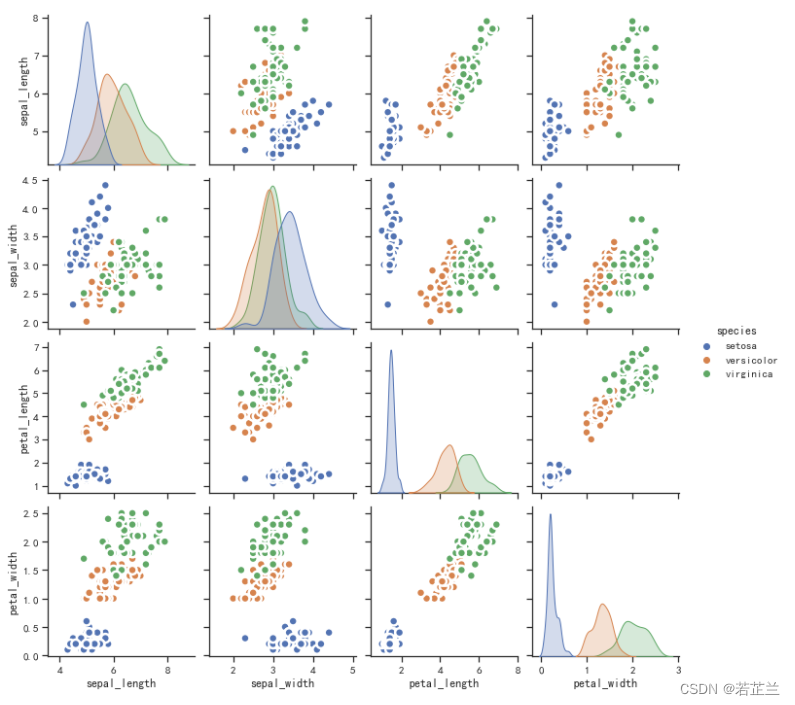
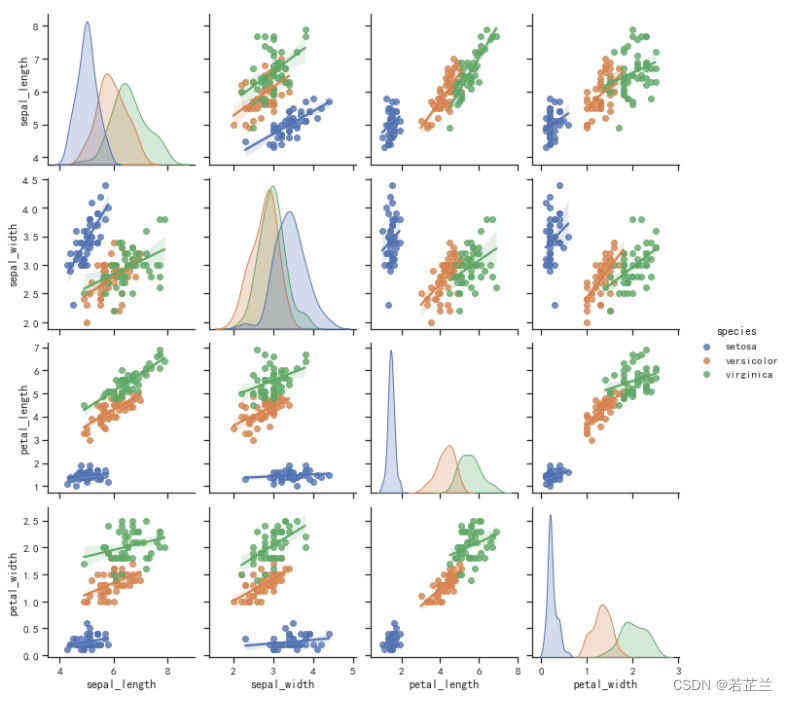
11.2 以回归线的方式循环展示数据属性之间的相关性
# 11.2:绘制以回归线的方式循环展示数据属性之间的相关性
plt.figure(figsize=(10, 8), dpi=80)
sns.pairplot(dataset, kind="reg", hue="species")
plt.show()
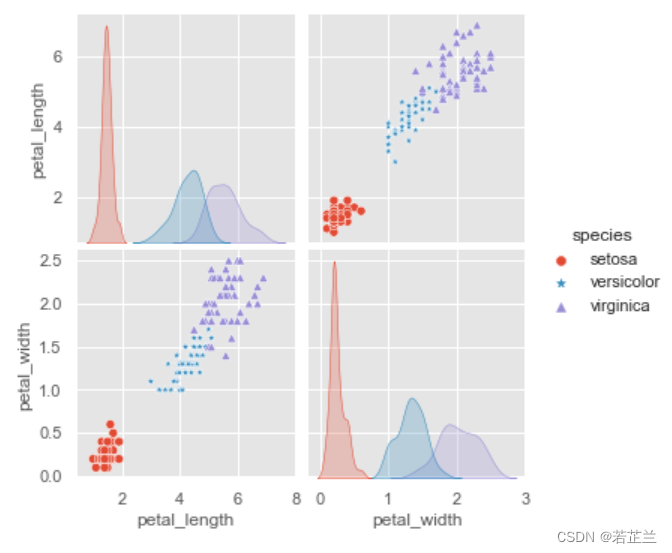
# 11.3 绘制2个特征属性的关系,并以颜色和符合区分不同的类别
plt.style.use("ggplot")
sns.pairplot(data=dataset[["petal_length", "petal_width", "species"]],
hue="species", markers=["o", "*", "^"])
plt.show()
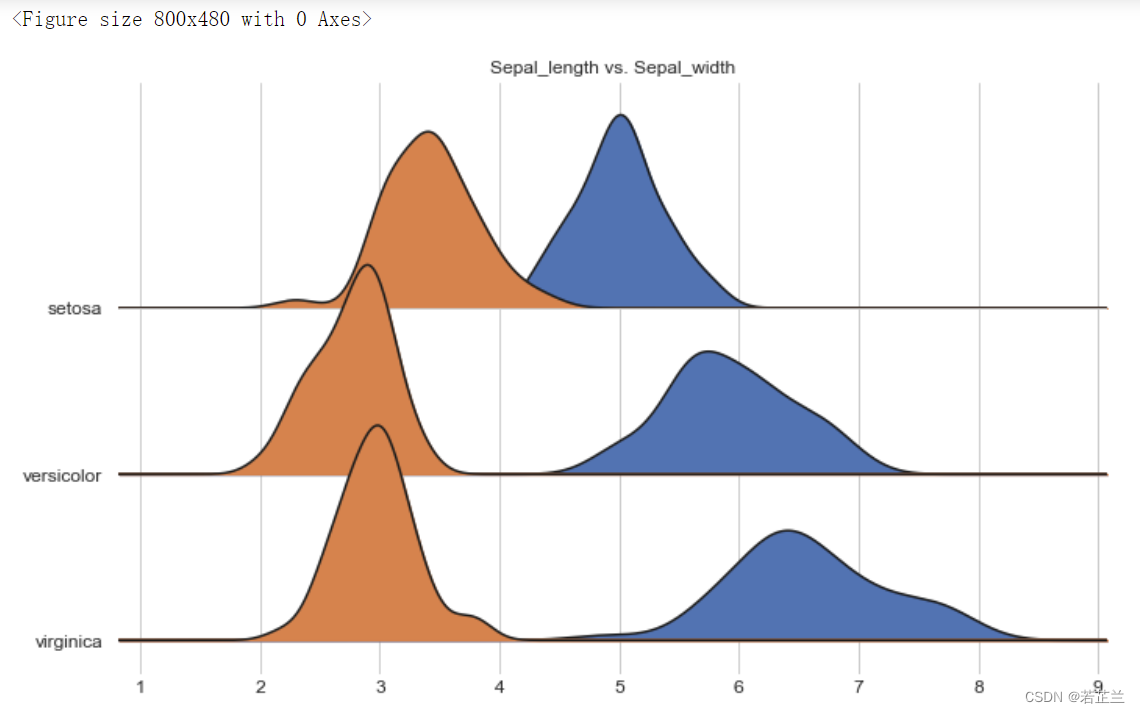
12. 多组分类重叠密度图 – Joyplot() 函数
多组分类重叠密度图(Joy plot)又称为“峰峦图”,是一种可视化大量分组数据的方法,通过部分堆叠、重叠的密度图来展示不同类别的密度曲线折叠状况,直观地在一个维度上呈现和比较不同组别数据的分布。
安装方法:pip install joyplot
# Joy Plot
import joypy
plt.figure(figsize=(10, 6), dpi=80)
fig, axes = joypy.joyplot(dataset, column=["sepal_length", "sepal_width"], by="species", figsize=(10, 6),
grid=True, title="Sepal_length vs. Sepal_width")
plt.show()
13. 联合分布图 – jointplot() 函数
# 13.1 联合分布图 -- jointplot()
sns.set(style="darkgrid", palette="muted", color_codes=True)
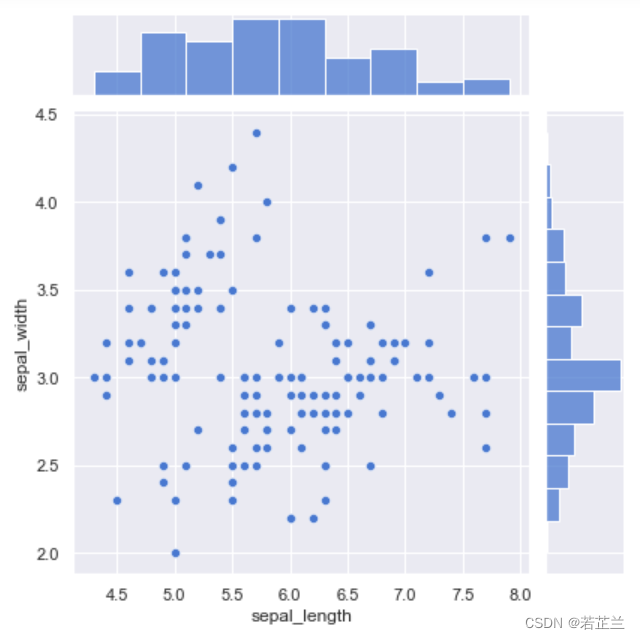
sns.jointplot(x="sepal_length", y="sepal_width", data=dataset)
plt.show()
# 13.2 联合分布图 使用hue参数来区分不同的类别
sns.set(style="darkgrid", palette="muted", color_codes=True)
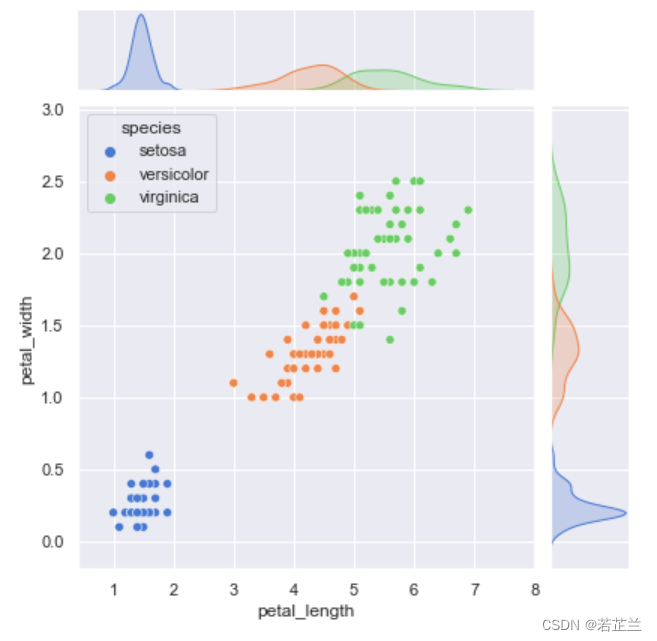
sns.jointplot(x="petal_length", y="petal_width", hue="species", data=dataset)
plt.show()
第三部分:统计分析图表及回归图
1. 检验是否符合正态分布 – p_test, Skewness(), Kurtosis()的计算
# 1.1 检查是否属于正态分布及偏度(Skewness)和峰度(Kurtosis)
print("偏度(Skewness): %f" % dataset["sepal_length"].skew())
print("峰度(Kurtosis): %f" % dataset["sepal_length"].kurt())
# 在统计学中,峰度(Kurtosis)衡量实数随机变量概率分布的峰态。
# 峰度高就意味着方差增大是由低频度的大于或小于平均值的极端差值引起的。

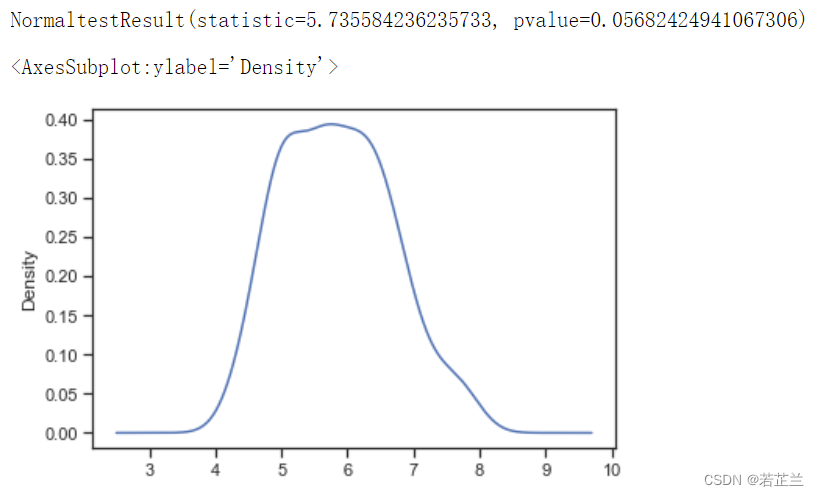
# 1.2检验数据的正态分布及p_test 的计算 -- 分析petal_length是否符合正态分布:
import scipy.stats as ss
p_test= np.array(dataset["sepal_length"].T)
print(ss.normaltest(p_test))
from matplotlib import pyplot as plt
p_test = pd.Series(p_test)
p_test.plot(kind="kde")
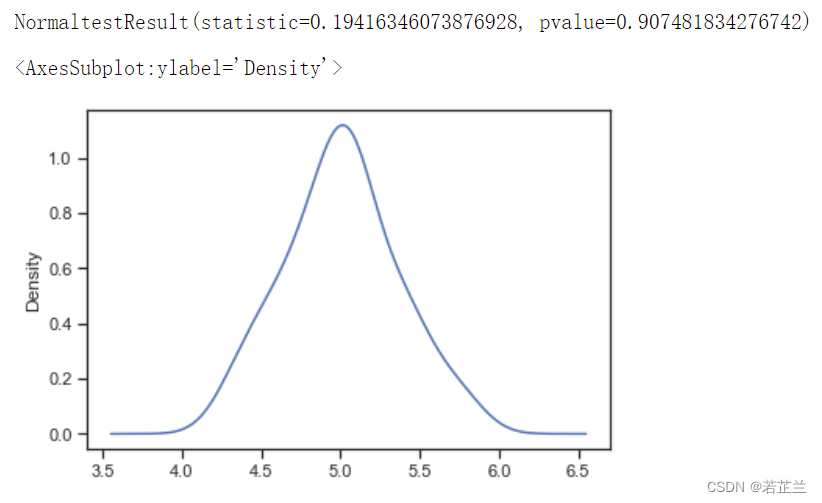
# 2.2 分析petal_length是否符合正态分布:
import scipy.stats as ss
data_ = dataset[dataset["species"] == "setosa"]
p_test= np.array(data_["sepal_length"].T)
print(ss.normaltest(p_test))
from matplotlib import pyplot as plt
p_test = pd.Series(p_test)
p_test.plot(kind="kde")
2. 正态概率分布图
# 正态概率分布图:-- histogram and normal probability plot
from scipy import stats
sns.distplot(dataset["sepal_length"], fit=norm)
fig = plt.figure()
res = stats.probplot(dataset["sepal_length"], plot=plt)
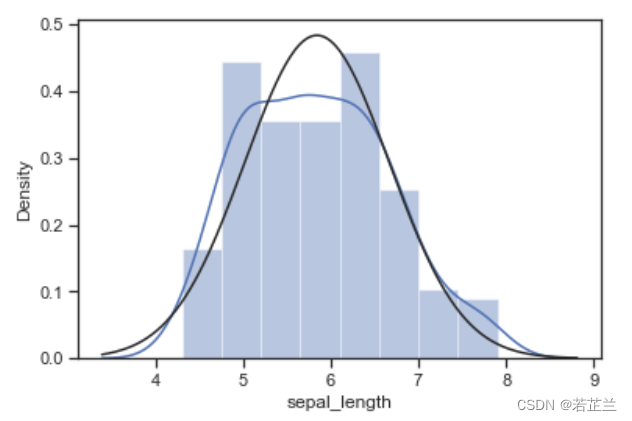
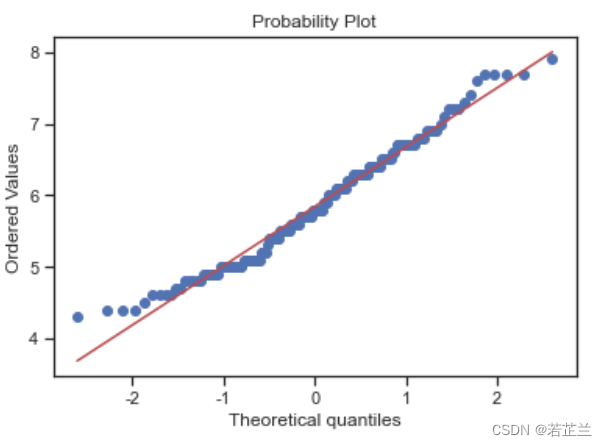
3. 正态分布图 – norm.pdf() 函数的计算与绘制
# 3.1 绘制正态分布图
from scipy.stats import norm
fig, axes = plt.subplots()
sigma = dataset["sepal_length"].std()
mu = dataset["sepal_length"].mean()
num_bins = 20
x = dataset["sepal_length"]
n, bins, patches = axes.hist(x, num_bins, density=1)
# 计算正态分布概率密度函数
y = norm.pdf(bins, mu, sigma)
axes.plot(bins, y, "r--")
axes.set_title("sepal_length(cm)的正态分布图")
fig.tight_layout()
plt.show()
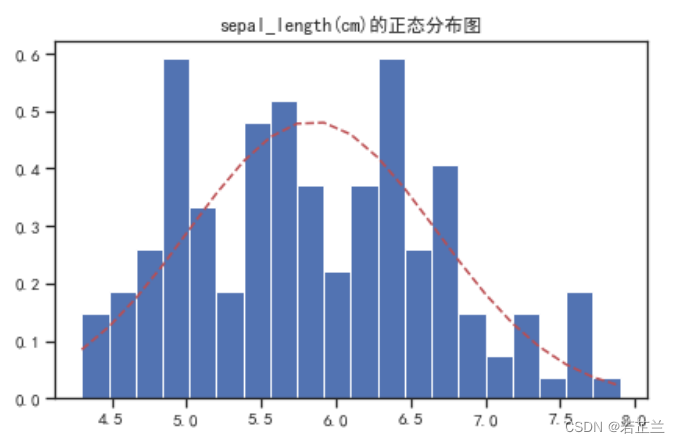
# 3.2 绘制正态分布图 -- 关注于某种品种的花瓣长度的数据分析
mpl.rcParams["font.family"] = "SimHei"
data_ = dataset[dataset["species"]=="setosa"]
from scipy.stats import norm
fig, axes = plt.subplots()
sigma = data_["sepal_length"].std()
mu = data_["sepal_length"].mean()
num_bins = 20
x = data_["sepal_length"]
n, bins, patches = axes.hist(x, num_bins, density=1,color="g")
y = norm.pdf(bins, mu, sigma)
axes.plot(bins, y, "r--")
axes.set_title("Setosa: sepal_length(cm)的正态分布图")
fig.tight_layout()
plt.show()
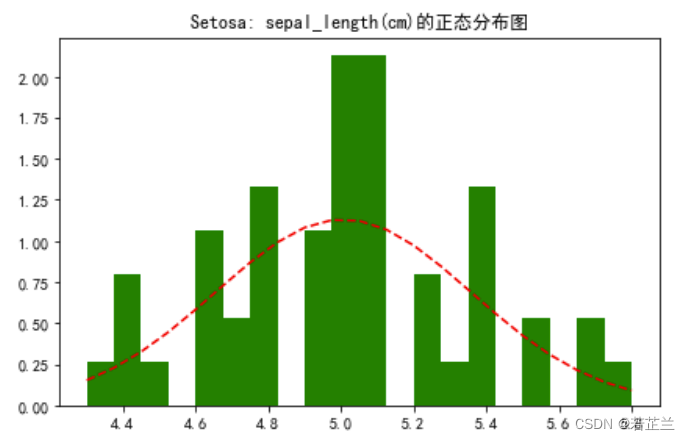
4. 回归图 – lmplot()函数
# 绘制回归图
import seaborn as sns
sns.lmplot(x="sepal_length", y="petal_length", hue="species", data=dataset)
plt.show()
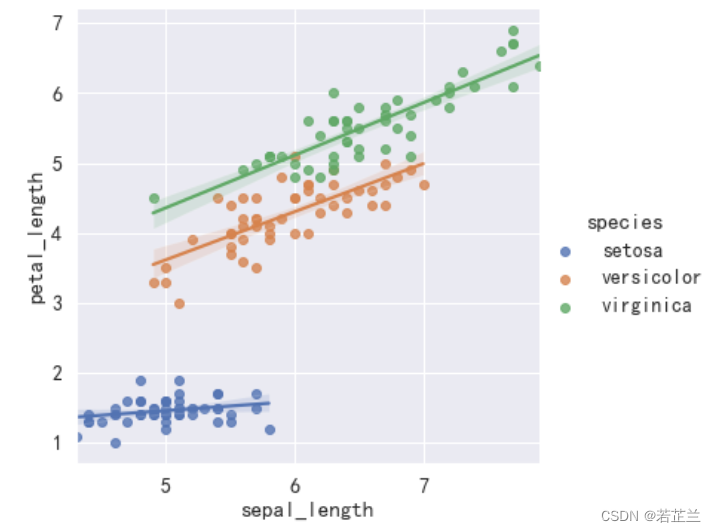
5. 回归图 – 使用regplot()函数
# 绘制线性回归图 -- 分别绘制
fig, axes = plt.subplots(1, 2, figsize=(8, 4))
sns.regplot(x="petal_length", y="petal_width", data=dataset, color="g", ax=axes[0])
sns.regplot(x="sepal_length", y="sepal_width", data=dataset, color="orange", ax=axes[1])
plt.show()

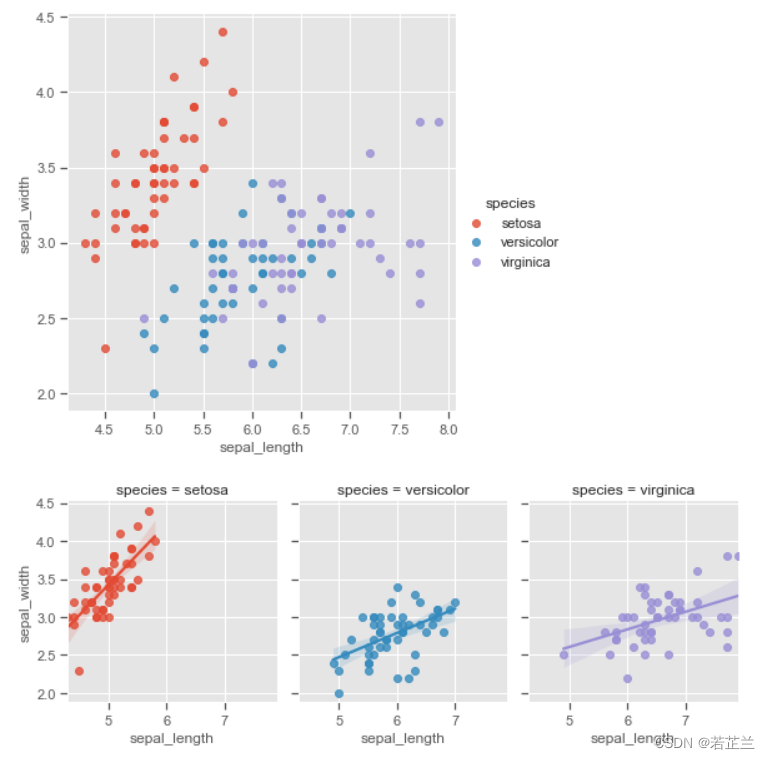
6. 回归图 – 使用lmplot()函数
# 使用lmplot()函数绘制和呈现不同类别的两两特征属性的相关情况
plt.style.use("ggplot")
sns.lmplot(x="sepal_length", y="sepal_width", hue="species",
data=dataset, fit_reg=False, size=5)
sns.lmplot(x="sepal_length", y="sepal_width", col="species", hue="species",
data=dataset, fit_reg=True, size=3, aspect=0.9, col_wrap=3)
plt.show()
附录:
1. Joyplot() 函数的介绍
‘data:绘制数据集’
‘column’:使用data的中的有限列进行绘图
‘by=None’:分组列
‘gird=false:添加网格线
‘xlabelsize=none x轴标签的大小
‘ylabelsize=none y轴标签的大小
‘xrot=none x轴刻度线标签旋转角度
‘yrot=none y轴刻度线标签旋转角度
‘hist=flase显示直方图
‘fade=flase如果设定的是true,则显示渐变色
‘ylim’=‘max共享y轴的刻度
ll=‘true 曲线下的填充颜色
linecolor=‘None;曲线的颜色
blackground=none:背景颜色
overlap=1:控制重叠程度
‘title’=none 添加图表的标题
‘colormap=none 色谱

















 317
317

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









