










K-近邻算法(KNN)概念
K Nearest Neighbor 算法又简称KNN算法,是机器学习里面一个比较经典的算法。
1、定义
中国有句古话,叫做近朱者赤近墨者黑,大概意思是接近好人可以使人变好,接近坏人可以使人变坏,也就是大概可以通过你身边的朋友反映出你是怎么样的一个人啊。
K近邻算法定义:如果一个样本在特征空间中的K个最相似(即特征空间中最近邻)的样本大多数都属于某一个类别,则该样本也属于这个类别。

这是一张北京地图,当你有几个朋友在北京的时候,你第一次去北京,但是你不知道自己是在哪个区,你就可以问问你的朋友们,当你离某个朋友最近的时候,那么如果这个朋友在海淀区的话,那么你也大概率的在海淀区。(当然有手机直接掏出手机地图查看除外)
2、距离公式
距离的计算各种各样,远远超出我们所熟悉的两点之间的距离,这里我给大家介绍六种常用的距离计算公式,剩下的自己可以去了解一下,希望对大家今后的机器学习有所帮助。
2.1欧式距离(Euclidean Distance)
欧式距离是我们最常见最容易直观理解的距离方法,从我们初中高中的时候学习的就是欧式距离。
二维平面上点a(x1,y1)和b(x2,y2)之间的欧式距离:
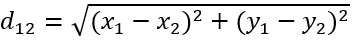
三维平面上点a(x1,y1,z1)和b(x2,y2,z2)之间的欧式距离:

因为人类平常生活的空间就是三维空间,当超过三维就很难想象,也就是只有爱因斯坦这种级别的大脑才能想象出四维空间。n维度空间点a(x11, x12, x13,……,x1n)与b(x21, x22, x23,……, x2n)间的欧式距离(两个n维向量):
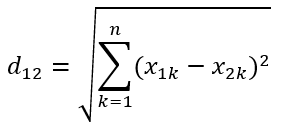
举例:
x=[ [1,1], [2,2], [3,3], [4,4] ]
d=1.4142 2.8284 4.2426 1.4142 2.8284 1.4142
2.2曼哈顿距离(Manhattan Distance)
在曼哈顿街区要从一个十字路口开车到另外一个十字路口,开车的距离肯定不可能是两点之间的直线距离,这个实际的开车距离就是曼哈顿距离,所以曼哈顿距离也称之为“城市街区距离”。

二维平面两点a(x1,y1)和b(x2,y2)间的曼哈顿距离:
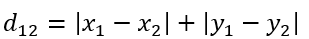
n维度空间点a(x11, x12, x13,……,x1n)与b(x21, x22, x23,……, x2n)间的曼哈顿距离:
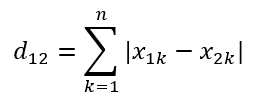
举例:
x=[ [1,1], [2,2], [3,3], [4,4] ]
d=2 4 6 2 4 2
2.3切比雪夫别(Chebyshev Distance)
在国际象棋中,国王可以选择直行、横行、斜行,所以国王走一步可以移动到相邻8个方格中的任意其中一个方格中,国王从格子(x1,y1)走到格子(x2,y2)最少需要走多少步,这个距离就叫切比雪夫距离。

国王的走法:

二维平面a(x1,y1)和b(x2,y2)间的切比雪夫距离:
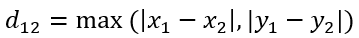
n维度空间点a(x11, x12, x13,……,x1n)与b(x21, x22, x23,……, x2n)间的切比雪夫距离:
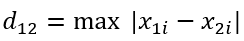
举例:
x=[ [1,1], [2,2], [3,3], [4,4] ]
d=1 2 3 1 2 3
2.4闵可夫斯基距离(Minkowski Distance)
闵氏距离不是指一种距离,而是一组距离的定义,是对多个距离度量公式的概括性的表述。
两个n维变量a(x11, x12, x13,……,x1n)与b(x21, x22, x23,……, x2n)间闵可夫斯基距离为定义为:
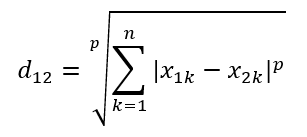
其中p是一个变参数,
·当p=1时,就是曼哈顿距离
·当p=2时,就是欧式距离
·当p=∞时,就是切比雪夫距离
小结:
闵氏距离以及以上的距离都存在一个很致命的缺陷,比如:我们生活中常见的样本之间的特征之间不能之间划等号,二维样本(身高:cm)和(体重:kg),a(180,70),b(190,70),c(180,80),a与c之间的闵氏距离和a与b之间的闵氏距离相等,但是实际上身高的10cm不能和体重10kg之间划等号。
闵氏距离的缺点:
(1)将各个分量的量纲(scale),也就是忽略了“单位”,将“单位”相同看待;
(2)未考虑各个分量的分布(期望、方差等)可能是不同的。
2.5标准化欧式距离(Standardized EuclideanDistance)
标准化欧式距离是针对欧式距离的一种改进思路,既然各维分量都是不一样的,那可以先将各个分量都标准化到均值、方差相等。假设样本的均值为m,标准差为s,X的标准化变量为:
“标准变化量”表示为:

标准化欧式距离为:
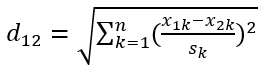
举例:
x=[ [1,1], [2,2], [3,3], [4,4] ]
d=2 .2361 4.4721 6.7082 2.2361 4.4721 2.2361
2.6余弦距离(Cosine Distance)
几何中,夹角余弦可用来衡量两个向量方向的差异,余弦值的取值范围是[-1,1]在机器学习当中,借用这个概念来衡量样本向量之间的差异。
二维空间中向量A(x1,y1)与向量B(x2,y2)的夹角余弦公式为:
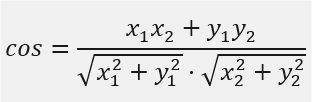
两个n维样本a(x11, x12, x13,……,x1n)与b(x21, x22, x23,……, x2n)的夹角余弦为:
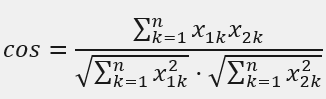
举例:
x=[ [1,1], [2,2], [2,5], [1,-4] ]
d=0.9487 0.9191 -0.5145 0.9965 -0.7593 -0.8107
2.7汉明距离(Hamming Distance)
2.8杰卡德距离(Jaccard Distance)
2.9马氏距离(Mahalanobis Distance)
以上六种希望可以帮助大家理解,这三者距离大家可以自己去了解一下。
3、Kd树
根据KNN每次需要预测一个点时,都需要计算训练数据集里每个点到这个点的距离,然后选出距离最近邻的k个点进行投票。数据小的时候,k近邻的时候计算比较小,当数据集很大的时候,这个计算成本非常高,针对N个成本,D个特征的数据集,算法的复杂度为O(DN^2),这个复杂度的计算会在以后的算法里面跟大家说明的。
Kd树的定义:为了避免每次都要重新计算一遍距离,算法会把距离信息保存到一棵树里面,这样在计算之前从树里查询距离信息,尽量避免重新计算。其基本原理是:如果A和B的距离很远,B和C的距离很近,那么A和C的距离也很远。有这样的信息,就可以先避免很多的计算,就可以在合适的时候跳过距离远的点。
3.1Kd树的原理

在这个集合当中寻找到8这个值,可以先从到一直寻找,但是需要7次,我们可以先将这个集合进行排序,升序排序为[2,3,4,5,6,7,8,9],然后取中间值5,第二次取中间值7,第三次取中间值8,这样就需要3次就可以找到8。关于如何排序,以后我会在算法中为大家介绍。Kd树的建立也同样如此。

黄色的点作为根节点,上面的点归左子树,下面的点归右子点,接下来再不断地划分,分割的那条线就叫做分割超平面。在一维平面中是一个点,二维平面是线,三维平面是面。

3.2Kd树的建立
最近邻搜索:Kd树是一种对k维空间中的实例点进行存储以便对其进行快速检索的树形数据结构,Kd树是一种二叉树,表示K维空间的一种划分,构造Kd树相当于不断地用垂直于坐标轴的超平面将K维空间切分,构成一系列的K维超矩形区域。Kd树的每个结点对应于一个K维超矩形区域。利用Kd树可以省去对大部分数据点的搜索,从而减少搜索的计算量。

举个例子吧
给定一个二维空间数据集:T={(2,3),(5,4),(9,6),(4,7),(8,1),(7,2)},构造一个平衡Kd树
第一次:
x轴–2,5,9,4,8,7–>2,4,5,7,8,9
y轴–3,4,6,7,1,2–>1,2,3,4,6,7
首先选择x轴,找到中间点5和7,我们选择(7,2)
第二次:
左面:(2,3),(4,7),(5,4)–>3,4,7
右面:(8,1),(9,6)–>1,6
从y轴开始选择
左边选择点是(5,4),右边可以随便选择,我选择了(9,6)
第三次:
从x轴开始选择

这就是Kd树的构造过程。

首先选择点(7,2)点,平面(7,2)垂直于横轴将空间分为左右两个矩形;接着左矩形以(5,4)和(9,6)垂直于纵轴,最后(2,3),(4,7),(8,1)垂直于横轴分成矩形,如此递归,最后得到这样的特征空间划分和Kd树。
3.3K近邻算法API

3.4K值选择
K值过小:容易受到异常点的影响,容易发生过拟合,整体模型变复杂
K值过大:受到样本均衡的问题,容易发生欠拟合,整体模型变简单
K=N,模型无效
近似误差:对现有训练集的训练误差,关注训练集,如果近似误差过小可能会出现过拟合的现象,对现有的训练数据集能很好的预测,但是对未知的测试样本将会出现大偏差的预测,模型本身不是最接近最佳模型。
近似误差———过拟合——在训练集上表现好在测试集上表现不好
估计误差:可以理解为对测试集的测试误差,关注测试集,估计误差小说明对未知数据的预测能力好,模型本身最接近最佳模型。
估计误差——估计误差好才是真的好
3.5k近邻算法总结
优点:简单有效、重新训练的代价低、适合类域交叉样本、适合大样本自动分类
缺点:惰性学习、类别评分不是规格化、输出可解释性不强、对不均衡的样本不擅长、计算量较大
样本不均衡,收集到的数据每个类别占比严重失衡,解决方案(重新采集样本)
在K近邻的API中,n_neighbors= 如何设置这个数是最好的,也就是如何选择K值最好。
交叉验证:将拿到的数据,分为训练集和验证集,训练集分为几份就是几折交叉验证
训练集:训练集+验证集
测试集:测试集
目的:不能提高模型整体的准确率,为了让被评估的模型更加准确可信
网格搜索:通常情况下,有很多参数需要手动指定,(n_neighbors=)的值,这种就叫做超参数需要手动操作的参数,但是手动过程比较复杂,所以需要对模型预设几种超参数组合,每组参数都采用交叉验证来评估,最后选出最优参数组合建立模型。
4、案例:鸢尾花种类预测
4.1特征工程
特征预处理:通过一些转换函数将特征数据转换成更加适合算法模型的特征数据过程。
归一化/标准化目的:特征的单位或者大小相差较大,或者某特征的方差相比其他的特征要大出几个数量级,容易影响目标结果,使得一些算法无法学习到其他的特征。
归一化:通过原始数据进行变换把数据映射到[0,1]之间
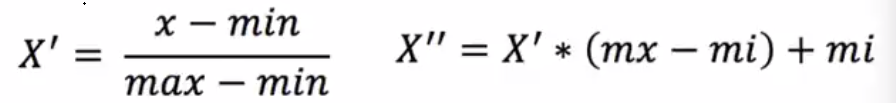
作用每一列,max为每列的最大值,min为每列的最小值,mx默认为1,mi默认为0
注意:归一化最大值最小值是变化的,另外最大值最小值非常容易受到异常点影响,所以这种方法鲁棒性较差,只适用于传统精小数据场景。
标准化
通过对原始数据进行变换到均值为0,标准差为1范围内
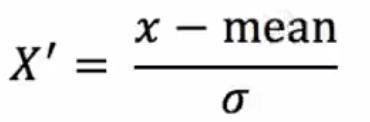
作用于每一列,mean为平均值,σ代表标准差
异常值影响小,适用于现代嘈杂大数据场景
4.2鸢尾花种类预测
数据集介绍:实例属性:150(三个类各有50个),是一类多重变量分析的数据集。
大家可以自行取查看这个数据集,没有安装的话也可以pip install sklearn

数据集划分,训练集0.8,测试集0.2

4.3KNN案例

4.4KNN案例鸢尾花案例,cv,example,交叉验证和网格搜索

总结:以上就是我对机器学习当中k近邻的学习总结,希望对大家的机器学习有所帮助,以后我会尽量更新机器学习和python算法和一些经典算法,希望对大家的学习能起到帮助,最后,推荐几个b站学习水平给大家吧。
BV1DU4y15719
BV1R64y1X7sc
BV18E411F781















 5603
5603











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









