






1、论文
源码:(tensorflow)
本人主要复现的是非官方的pytorch版本代码,链接如下:
ChangeZH/Pytorch_DDcGAN: 基于Pytorch的DDCGAN非官方复现。 (github.com)
2、网络结构
这里我复现的是可见光与红外图像的融合,因此仅给出这部分网络结构,主要包括1个生成器和2个判别器(鉴别器)。生成器的目的是基于专门设计的内容损失生成一个融合图像,以欺骗两个鉴别器,而两个鉴别器的目的是区分融合图像和两个源图像之间的结构差异。因此,该融合的图像被迫同时保持红外图像中的热辐射和可见光图像中的纹理细节。
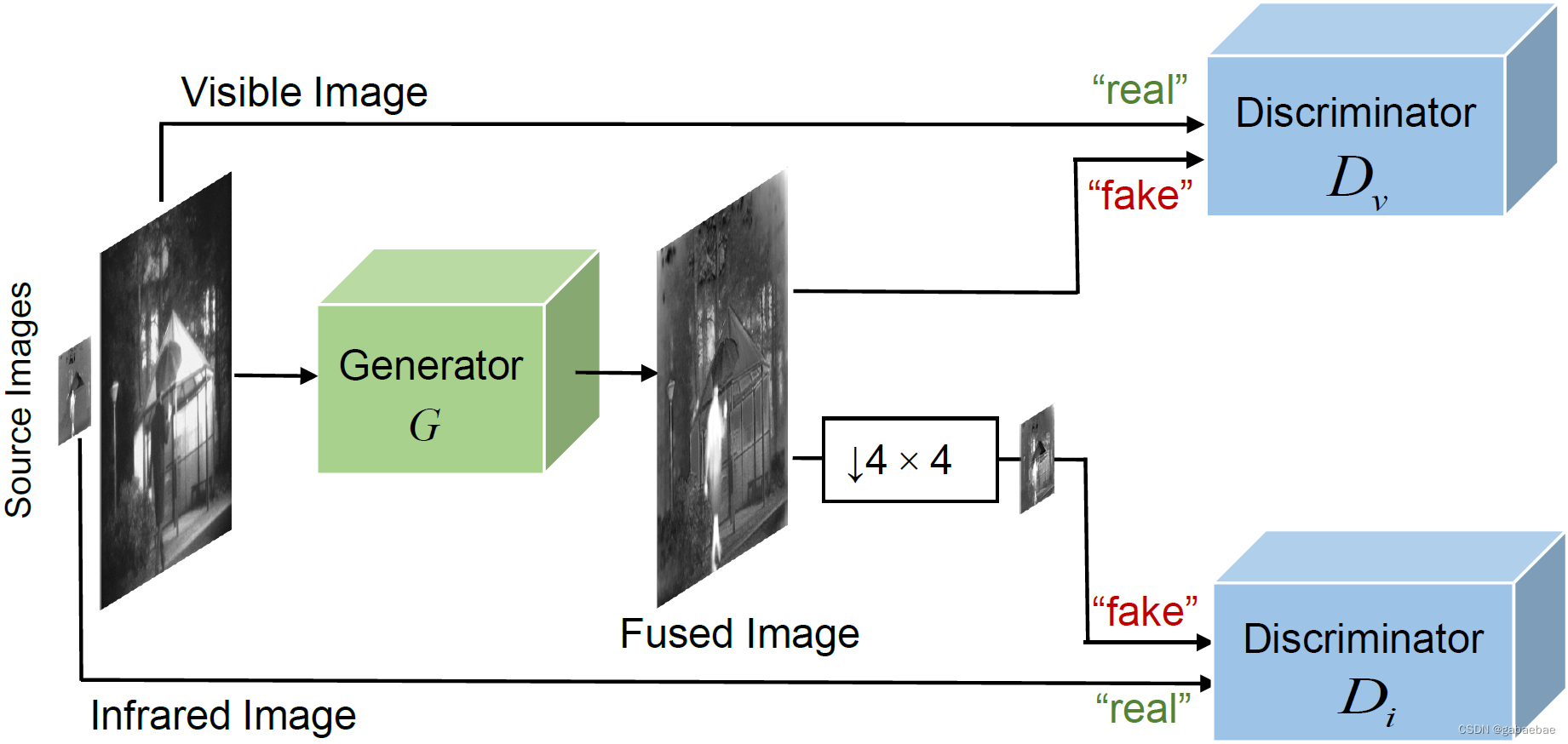
2.1 生成器
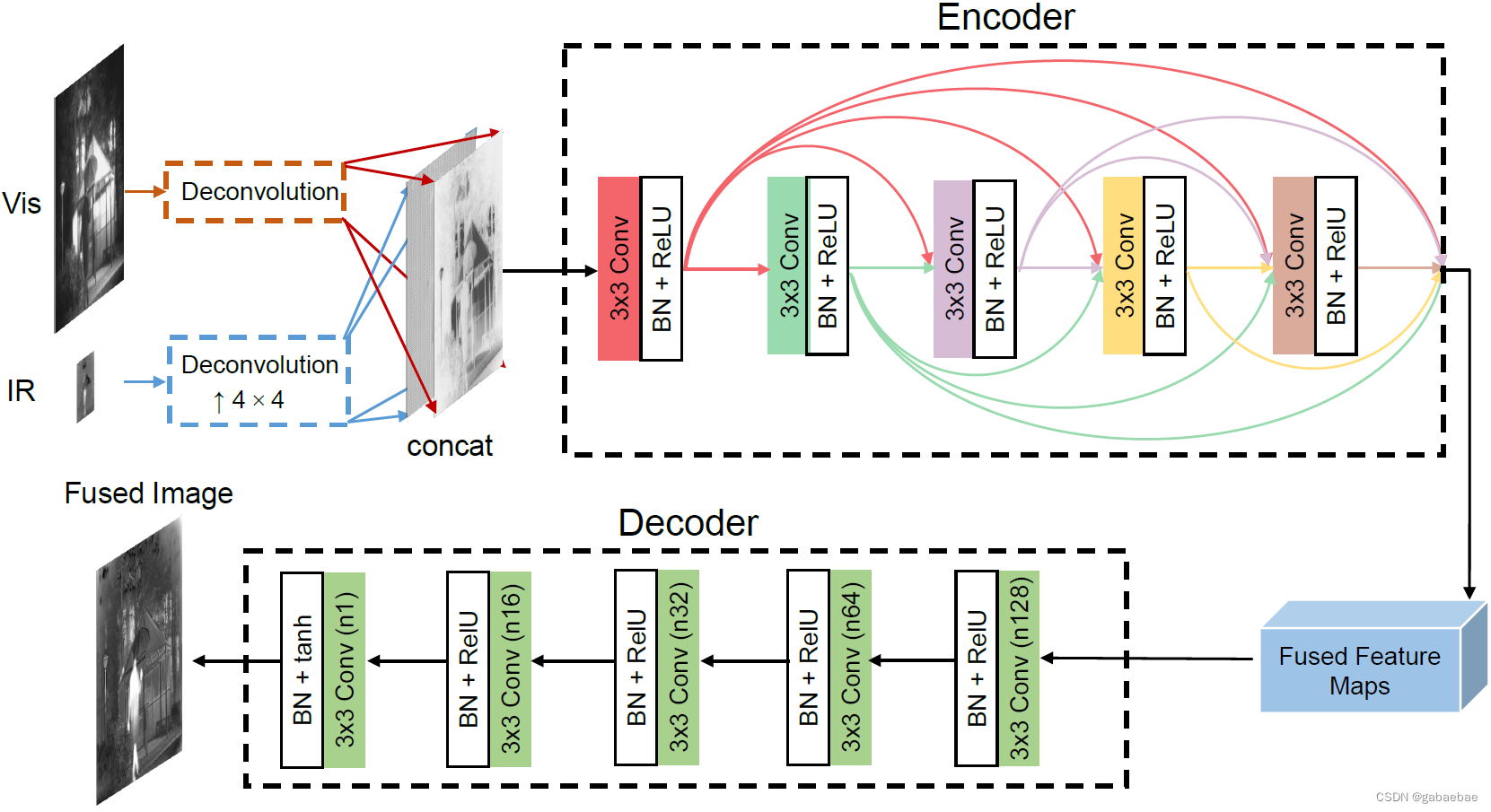
生成器网络结构如下图所示,主要包括编码器、解码器两部分。
算法首先对输入的红外图像和可见光图像进行反卷积,并对红外图像进行上采样(这里默认红外图像分辨率低于可见光),然后将同一分辨率的红外和可见光图像的特征图进行拼接,作为编码器的输入。
编码器是一个五层的DenseNet结构,即每一层使用之前所有层提取的特征。每一层卷积核大小为3x3,步长为1,为了避免梯度爆炸/消失,应用批量归一化BN,最后采用ReLU激活函数加快收敛。解码器包括五层Conv,每层的卷积核都是3x3。解码器最终的输出就是融合图像。
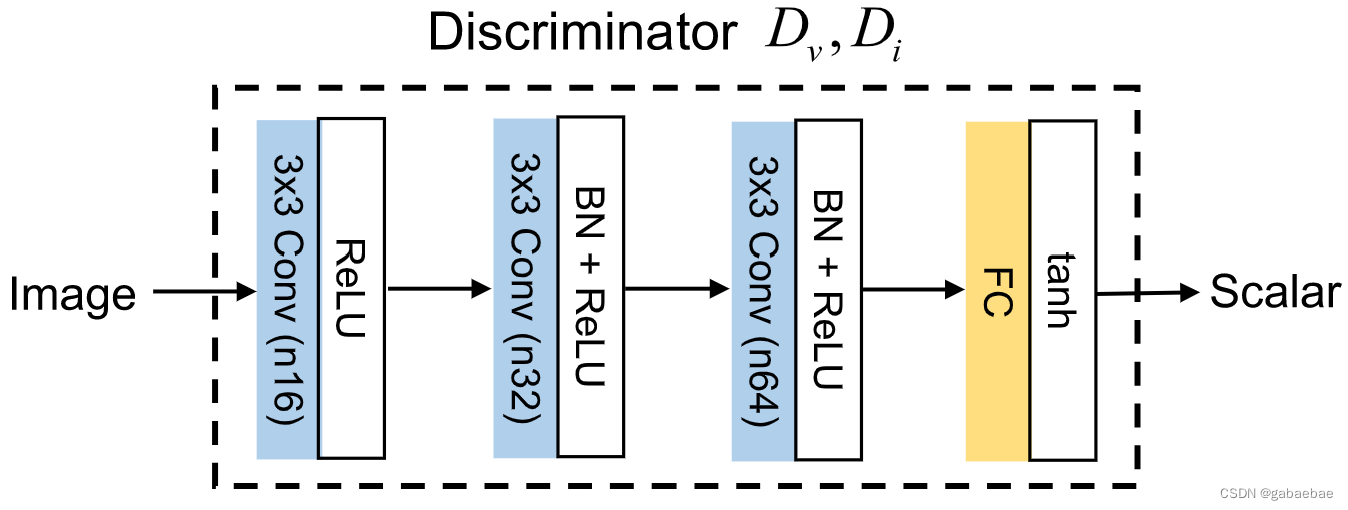
2.2 判别器
算法中两个判别器结构一样,旨在将产生的融合图像与可见图像和红外图像区分开。如图所示,判别器包括三层Conv,所有卷积层的步长都设为2。在最后一层全连接层FC中,使用tanh激活函数来生成一个标量,表示输入图像是源图像而不是生成器G中生成的融合图像的概率。
3、代码复现
下载的代码目录结构如下:

3.1 train.py代码修改
1、将os.mkdir改为os.makedirs。
【原因】os.mkdir不能生成多级目录。
try:
os.makedirs(f'./weights/{project_name}/')
os.makedirs(f'./weights/{project_name}/Generator/')
os.makedirs(f'./weights/{project_name}/Discriminator/')
except:
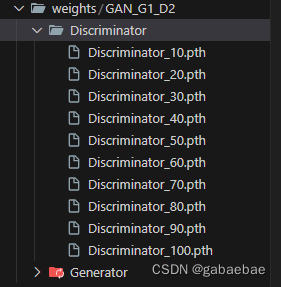
pass2、权重保存
源代码中epoch为100,每个epoch都保存了权重,我改为10次保存一次。修改代码如下:
if epoch % 10 == 0:
torch.save(Generator, f'./weights/{project_name}/Generator/Generator_{epoch}.pth')
torch.save(Discriminator,
f'./weights/{project_name}/Discriminator/Discriminator_{epoch}.pth')此时,根目录会生成如下权重文件:包括判别器和生成器
3.2 test.py代码修改
测试部分的原代码报错较多,这里直接给出我最终的test.py。
import torch
from PIL import Image
from torchvision import transforms
import sys
sys.path.append(".")
from core.model import build_model
from core.utils import load_config
# from core.model.build import build_model
# from core.utils.config import load_config
# config = load_config('../config/Pan-GAN.yaml')
config = load_config('./config/GAN_G1_D2.yaml')
GAN_Model = build_model(config)
vis_img = Image.open('./demo/test_vis.jpg')
inf_img = Image.open('./demo/test_inf.jpg')
# trans = transforms.Compose([transforms.Resize((256, 256)), transforms.ToTensor()])
trans = transforms.Compose([transforms.Resize((512, 512)), transforms.ToTensor()])
vis_img = trans(vis_img)
inf_img = trans(inf_img)
data = {'Vis': vis_img.unsqueeze(0), 'Inf': inf_img.unsqueeze(0)}
GAN_Model.Generator.load_state_dict(torch.load('./weights/GAN_G1_D2/Generator/Generator_50.pth').state_dict())
Generator_feats, Discriminator_feats, confidence = GAN_Model(data)
untrans = transforms.Compose([transforms.ToPILImage()])
img = untrans(Generator_feats['Generator_1'][0])
print(img.size)
img.save('test_result.jpg')
出现的主要错误如下:
1、ModuleNotFoundError: No module named 'core'
这部分对应修改如下:
import sys
sys.path.append(".")
from core.model import build_model
from core.utils import load_config
# from core.model.build import build_model
# from core.utils.config import load_config2、FileNotFoundError: [Errno 2] No such file or directory: '../config/GAN_G1_D2.yaml'
这部分对应修改如下:
# config = load_config('../config/Pan-GAN.yaml')
config = load_config('./config/GAN_G1_D2.yaml')
GAN_Model = build_model(config)
vis_img = Image.open('./demo/test_vis.jpg')
inf_img = Image.open('./demo/test_inf.jpg')3、No such file or directory: './weights/Generator/Generator_100.pth'
这里看你生成的权重文件保存在哪,对应修改即可。我的路径如下:weights/GAN_G1_D2/Generator/Generator_100.pth
4、RuntimeError: Calculated padded input size per channel: (2 x 2). Kernel size: (4 x 4). Kernel size can't be greater than actual input size
这部分修改如下:将256*256改为512*512。
# trans = transforms.Compose([transforms.Resize((256, 256)), transforms.ToTensor()])
trans = transforms.Compose([transforms.Resize((512, 512)), transforms.ToTensor()])5、img = untrans(Generator_feats['Generator'][0]) KeyError: 'Generator'
这部分对应将'Generator'改为'Generator_1'。
# img = untrans(Generator_feats['Generator'][0])
img = untrans(Generator_feats['Generator_1'][0])4、结束语
以上是对本人学习过程中遇到的问题进行的简单总结,希望能帮到大家!但笔者最后的融合图像很奇怪,这里给出一个示例,图片从左到右分别是可见光、红外、融合图像。



关于融合图像的一些问题:
我看代码里作者使用的训练图像中是有彩色图像的,融合图像的彩色会不会跟这个有关系?最后融合图像为什么和输入图像不一致呢?
以上问题欢迎大家在评论区交流!感谢!!!
5、-------------更新2024.9.5---------------
在项目根目录下,有一个debug文件夹,里面能看到不同epoch的融合效果。

关于最终融合图像显示问题,我结合debug函数中的相关代码,在测试代码中添加了部分操作:
GAN_Model = build_model(config)
vis_img = Image.open('./demo/test_vis.jpg') #test_vis.jpg
inf_img = Image.open('./demo/test_inf.jpg')#test_inf.jpg
# trans = transforms.Compose([transforms.Resize((256, 256)), transforms.ToTensor()])
trans = transforms.Compose([transforms.Resize((512, 512)), transforms.ToTensor()])
vis_img = trans(vis_img)
inf_img = trans(inf_img)
data = {'Vis': vis_img.unsqueeze(0), 'Inf': inf_img.unsqueeze(0)}
GAN_Model.Generator.load_state_dict(torch.load('./weights/GAN_G1_D2/Generator/Generator_100.pth').state_dict()) #./weights/GAN_G1_D2/Generator/Generator_50.pth
Generator_feats, Discriminator_feats, confidence = GAN_Model(data)
#------新增,实现图像显示------
mean=Generator_Train_config['mean']
std=Generator_Train_config['std']
mean_t = torch.FloatTensor(mean).view(3, 1, 1).expand(vis_img.shape)
std_t = torch.FloatTensor(std).view(3, 1, 1).expand(vis_img.shape)
Generator_feats['Generator_1'][0] = Generator_feats['Generator_1'][0] * std_t + mean_t
untrans = transforms.Compose([transforms.ToPILImage()])
img = untrans(Generator_feats['Generator_1'][0])最后融合图像显示正常,但还是没有很理想······



















 1530
1530

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









