







GANs(Generative Adversarial Networks)由Ian Goodfellow等人在2014年的论文《Generative Adversarial Networks》中首次提出,是生成模型领域的一项突破性工作。但在原论文中只是提出并通过数学方法证明了这一理念,但当时仅仅只是通过多层感知机模拟了这一模型。而GANs真正的应用则是在之后的DCGAN(Deep Convolutional GAN),由Alec Radford等人在2015年的论文《Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks》中提出,是GAN的改进版本,首次将卷积神经网络(CNN)成功引入GAN框架,显著提升了生成图像的质量和稳定性。这次我们就根据论文原文的描述来复现论文模型,进行DCGAN的代码演练。当然pytorch也给出过一个对于celeba数据集进行DCGAN训练的代码,但我们这次主要是想对原文进行复现,顺便也讲一下复现论文代码的思路。
数据集
原文中作者说使用了三种数据集:LSUN、Imagenet-1k和一个新组装的人脸数据集。我们就用第一个LSUN数据集进行试验。根据原文中描述,它是使用了bedroom数据集进行的试验。因此首先我们先从Github上将压缩包下载下来,下载下来的内容如下图。
根据README中内容,我们在anaconda中可以运行如下代码,当然如果你用的是别的环境也可以运行。
# Download the whole latest data set
python download.py
# Download the whole latest data set to <data_dir>
python download.py -o <data_dir>
# Download data for bedroom
python download.py -c bedroom
# Download testing set
python download.py -c test
通过运行download文件我们可以将bedroom数据集中的图片下载到指定文件夹路径下,数据集包含了train和val两部分,分别命名为bedroom_train_lmdb.zip和bedroom_val_lmdb.zip。然后将两个压缩包中的文件夹分别解压出来,得到两个文件夹分别命名为bedroom_train_lmdb和bedroom_val_lmdb。之后根据README文件,我们可以在anaconda中运行如下代码,当然如果你用的是别的环境也可以运行。此处默认是data.py和数据集文件夹在同一个文件夹下。
python data.py export bedroom_train_lmdb --out_dir bedroom_train --flat
python data.py export bedroom_val_lmdb --out_dir bedroom_val --flat
得到的结果如下图

bedroom_train和bedroom_val两个文件夹当中分别包含了训练集图片和验证集图片,部分示例如下图。
train:

val:

到此为止获取数据集的任务完成。
值得注意的是在实际训练中DCGAN是不需要验证集的,这里只是顺便把验证集也下载下来,后续试验过程仅会使用训练集数据。
代码实现
首先我们根据原文中的描述搭建初始参数和模型。当然这首先是需要知道GANs的原理,这里就不多赘述了,有需要的话可以参考我之前写的有关发明GANs的论文讲解。链接: 读个论文(二)—— Generative Adversarial Nets。
首先我们知道GANs包含一个生成器和一个鉴别器,通常用G和D来表示。DCGAN中没有全链接层的参与,因为作者觉得虽然可以提高模型稳定性但会损害收敛速度对于。对于输入和输出原文表述是这样的:GAN的第一层以均匀的噪声分布Z为输入,可以称为全连接,因为它只是一个矩阵乘法,但结果被重塑为四维张量,并用作卷积堆栈的开始。对于鉴别器,最后一个卷积层被平坦化,然后被馈送到单个sigmoid输出中。具体结构示意图如下。
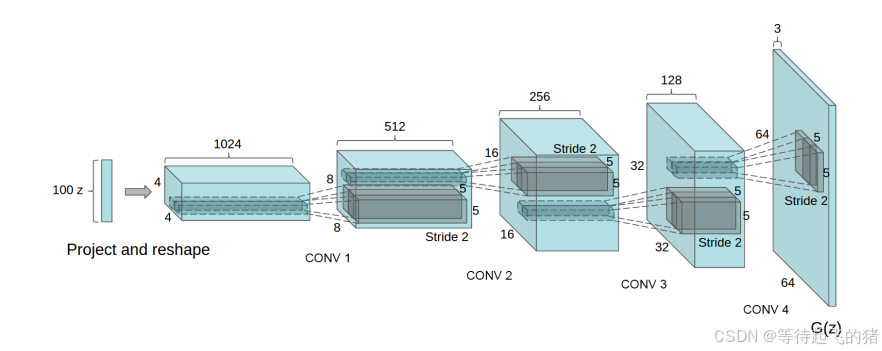
对于归一化部分,根据原文中的表述:对于生成器和鉴别器,我们使用batchnorm,但不对生成器输出层和鉴别器输入层应用,这是因为将batchnorm直接应用于所有层会导致样本振荡和模型不稳定。
对于激活部分,根据原文中的表述:在生成器中对所有层使用ReLU激活,但输出层使用Tanh,在所有层的鉴别器中使用LeakyReLU激活。
到此为止生成器和鉴别器的模型代码我们就可以写出来。但我们还需要补充每一层具体的参数,因此要参考上图。通过上图我们可以看出生成器输入是一个100维的噪声向量,通过原文说的**四个小跨步卷积(four fractionally-strided convolutions)**输出一个RGB三维向量。当然在代码中我们使用的是转置卷积也就是反卷积,并且在很多论文中也说这个是反卷积,但作者却说这个说法不正确,至于具体是什么情况就不知道了,只能说我们用转置卷积是肯定没有问题的。而对于鉴别器,我们输入是一张RGB三维向量构建的图片,大小为3 *64 *64。输出则是一个二分类的值,只有一维,这也是我们为什么用sigmoid的原因,我们只需要做出真假的分类。
因此在将参数带入之后,我们可以得到模型的部分的代码如下。虽然原图中可以看出卷积层的输出channels分别为1024,512,256,128,但由于我们在自己的时候没有那么强大的显卡,处理不了那么大的参数和数据集,因此在实际做的时候参考了pytorch给出的代码,将输出的channels分别设为512,256,128,64。(当然原图中的参数设置我也尝试了,实在是训练不起来,一开始Loss_D和Loss_G就有一个直接归0了)对于LeakyRelu的参数原文中有提到,我会放在后面一起说。
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.main = nn.Sequential(
nn.ConvTranspose2d(in_channels=100, out_channels=512, kernel_size=4, stride=1, padding=0, bias=False),
nn.BatchNorm2d(512),
nn.ReLU(True),
nn.ConvTranspose2d(in_channels=512, out_channels=256, kernel_size=4, stride=2, padding=1, bias=False),
nn.BatchNorm2d(256),
nn.ReLU(True),
nn.ConvTranspose2d(in_channels=256, out_channels=128, kernel_size=4, stride=2, padding=1, bias=False),
nn.BatchNorm2d(128),
nn.ReLU(True),
nn.ConvTranspose2d(in_channels=128, out_channels=64, kernel_size=4, stride=2, padding=1, bias=False),
nn.BatchNorm2d 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









