






论文标题:GraphFPN: Graph Feature Pyramid Network for Object Detection
代码下载地址:https://github.com/GangmingZhao/GraphFPN-Graph-Feature-Pyramid-Network-for-Object-Detection.
首先从train.py文件开始看起,这是项目的train文件

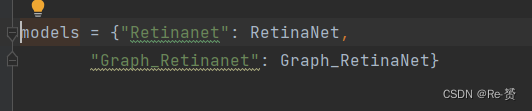
model参数从models中选出了训练使用的模型,config的默认情况可以在configs.py中查看
configs.num_classes = 15
configs.backbone = "Resnet50"
configs.Arch = "Graph_Retinanet" "
知道了默认的参数我们可以去到get_model.py查看models的定义,发现默认选用的模型是Graph_RetinaNet
寻找Graph_RetinaNet函数的定义,在network.py文件下
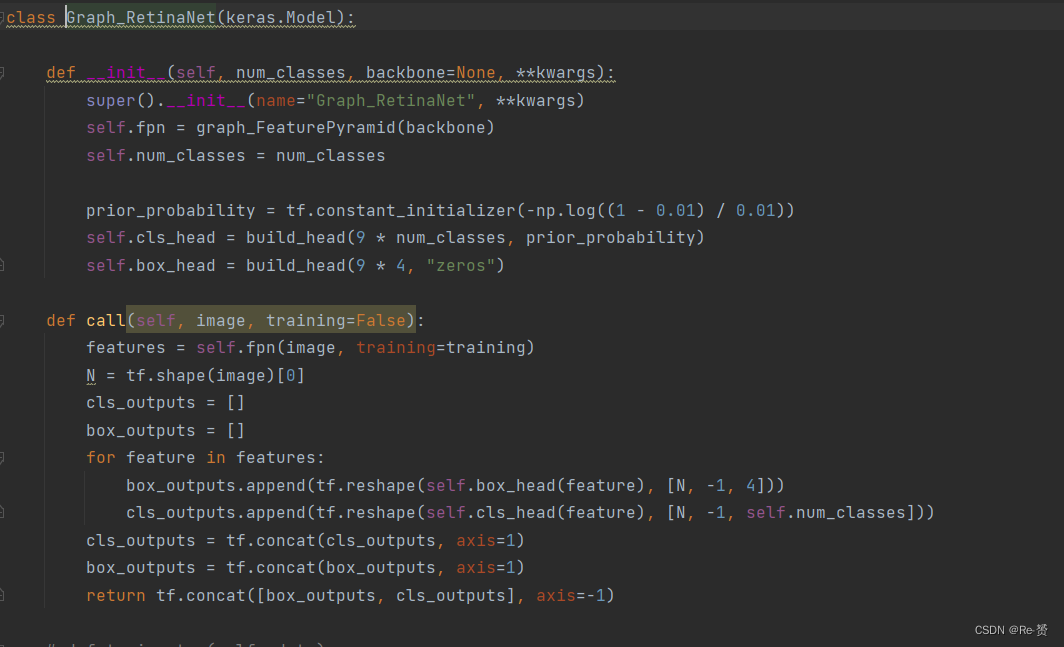
这个model首先继承了keras.Model,这个父类用于搭建和配置神经网络训练的模型,通过Model这个方法可以调用很多API去实现训练神经网络。
查看init方法,fpn参数获得了graph_FeaturePyramid的返回值。继续查看graph_FeaturePyramid的函数内容,这是一个继承了keras.layers.Layer的类,tensorflow中的类tf.keras.layers.Layer可用于创建神经网络中的层
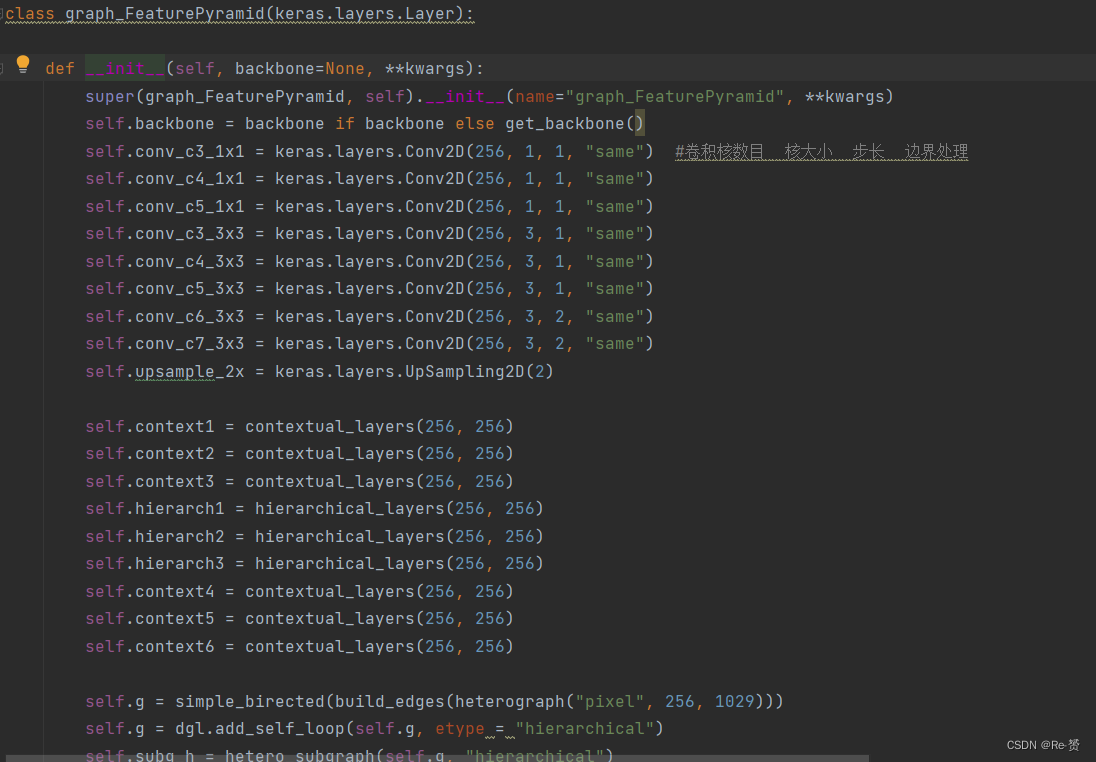
首先查看init方法,因为我们有backbone参数,所以直接将self.backbone赋值为Resnet50。
接下来查看keras.layers.Conv2D的参数
filters:卷积核的数目(即输出的维度)
kernel_size:卷积核的宽度和长度。
strides:卷积的步长。
padding:补0策略,为"valid", "same" 。
"valid"不填充,eg:图像28*28,过滤器5*5,步长为5,最后三行三列舍弃,输出大小为:[(28-3-5)/5]+1=5,即输出图像是5*5的,代表只进行有效的卷积,即对边界数据不处理。
"same"填充,当滑动步长大于1时:填充数=K-I%S(K:卷积核边长,I:输入图像边长,S:滑动步长),滑动步长为1时,填充数是卷积核边长减1,eg:5*5的图用3*3的核,步长为1时same填充之后是7*7,代表保留边界处的卷积结果,通常会导致输出shape与输入shape相同,因为卷积核移动时在边缘会出现大小不够的情况。
keras.layers.UpSampling2D 就是对图片数据在高与宽的方向进行数据插值倍增。
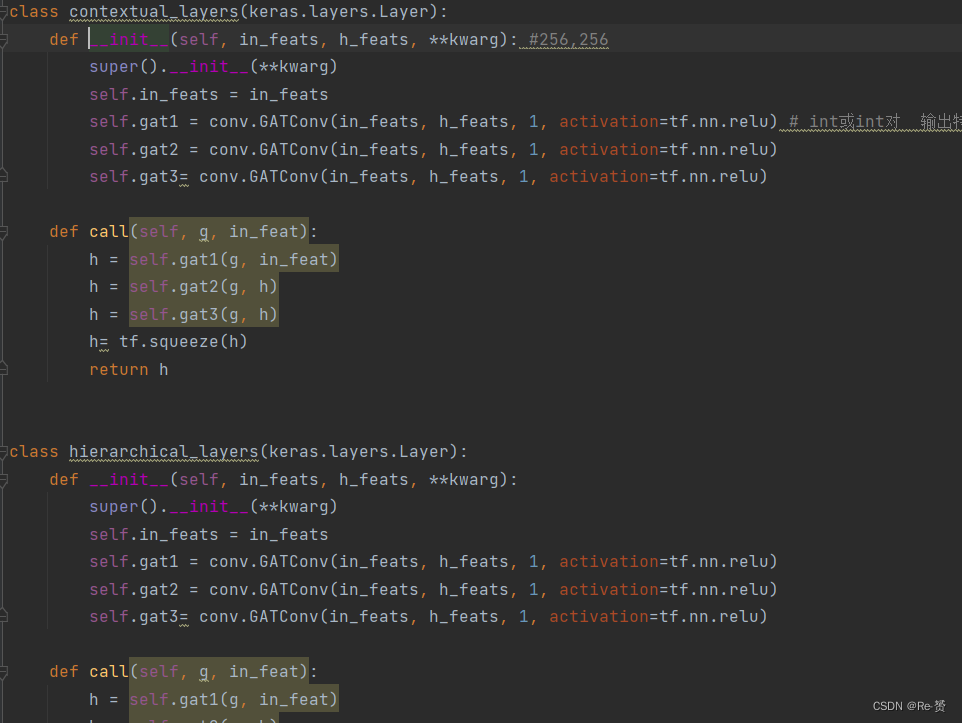
contextual_layers和hierarchical_layers是构建图神经网络的函数,同样继承keras.layers.Layer
在这两个函数里最主要的函数是conv.GATConv,这是图神经网络所使用的函数它的定义如下
in_feats: int 或 int 对。如果是无向二部图,则in_feats表示(source node, destination node)的输入特征向量size;如果in_feats是标量,则source node=destination node。
out_feats: int。输出特征size。
num_heads: int。Multi-head Attention中heads的数量。
feat_drop=0.: float。特征丢弃率。
attn_drop=0.: float。注意力权重丢弃率。
negative_slope=0.2: float。LeakyReLU的参数。
residual=False: bool。是否采用残差连接。
activation=None:用于更新后的节点的激活函数。
接着回到主方法graph_FeaturePyramid中,在新建了许多cnn层和图神经网络层后
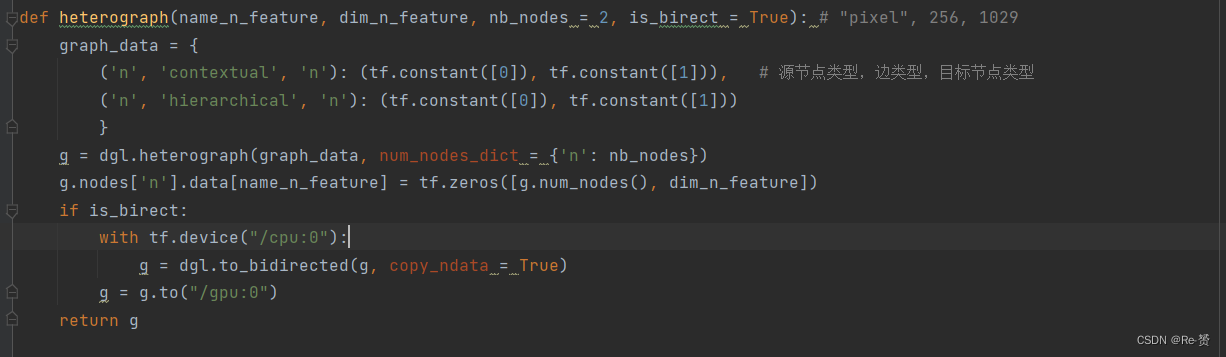
self.g = simple_birected(build_edges(heterograph("pixel", 256, 1029))) //建立了一个simple graph
self.g = dgl.add_self_loop(self.g, etype = "hierarchical") //添加自环,避免出现孤立点
self.subg_h = hetero_subgraph(self.g, "hierarchical") //划分子图
self.subg_c = hetero_subgraph(self.g, "contextual") //划分子图
注意其中的heterograph方法,这是写在graph.py中的方法。
其中dgl.DGLHeteroGraph是基本异构图类:key是一个三元组被称为规范边类型,value 是一堆源数组和目标数组,其中创建了('n', 'contextual', 'n')边的类型下的一条边:0->1,和('n', 'hierarchical', 'n')边的类型下的一条边:0->1
g.nodes[‘n’].data[name_n_feature]:设置/获取"n"类型的节点的"pixel"特征,将其赋值为256*1029的零矩阵
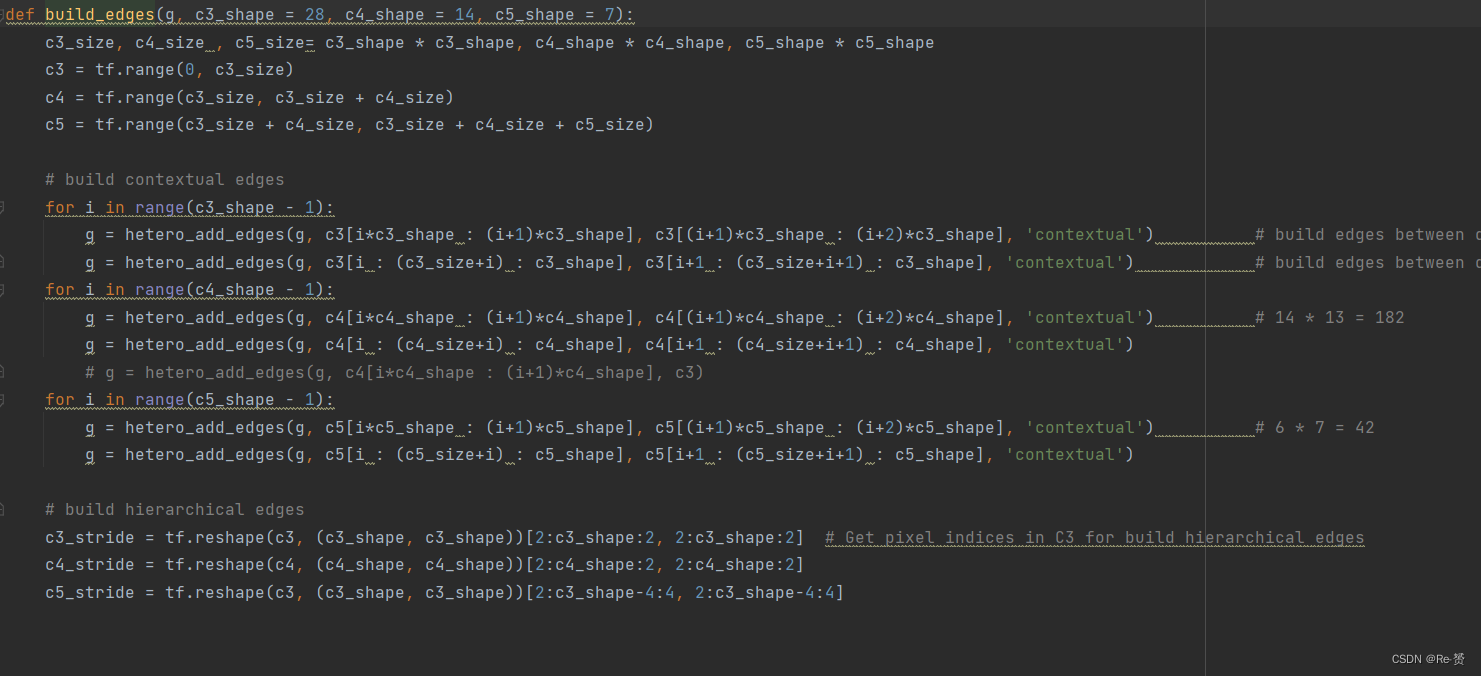
得到异构图后build_edges函数进行图的建边操作,28,14,7对应之后Resnet网络提取后得到的3种特征图的大小,接着通过3个循环在每一张特征图中,每一个像素点都和其上下左右建立边的联系(前三个循环所建立的)
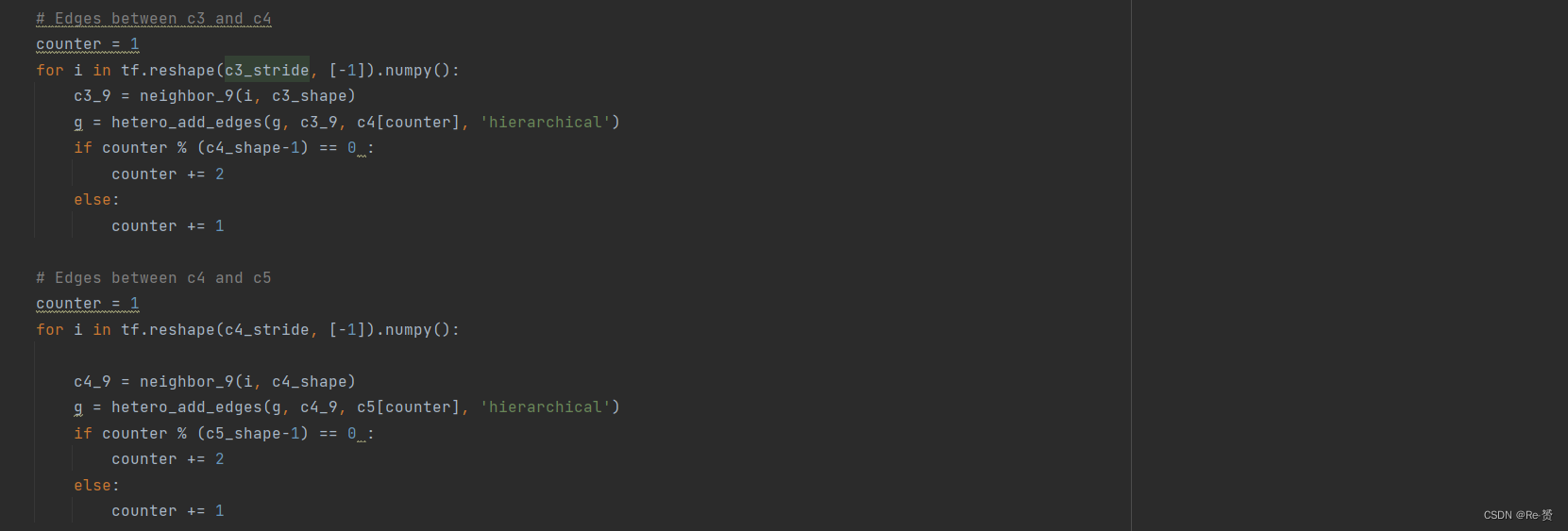
接着跨层建立不同特征图与不同特征图之间的联系,即c3与c4,c4与c5,c3与c5之间每一个点之间的边联系
以上便是graph_FeaturePyramid这个函数的初始化情况,大致来说这个函数构建了一个包含CNN和GNN的网络层次,用于之后的模型训练。
来看Graph_RetinaNet这模型类中init剩下的几步操作:
self.num_classes = num_classes // configs.num_classes = 15
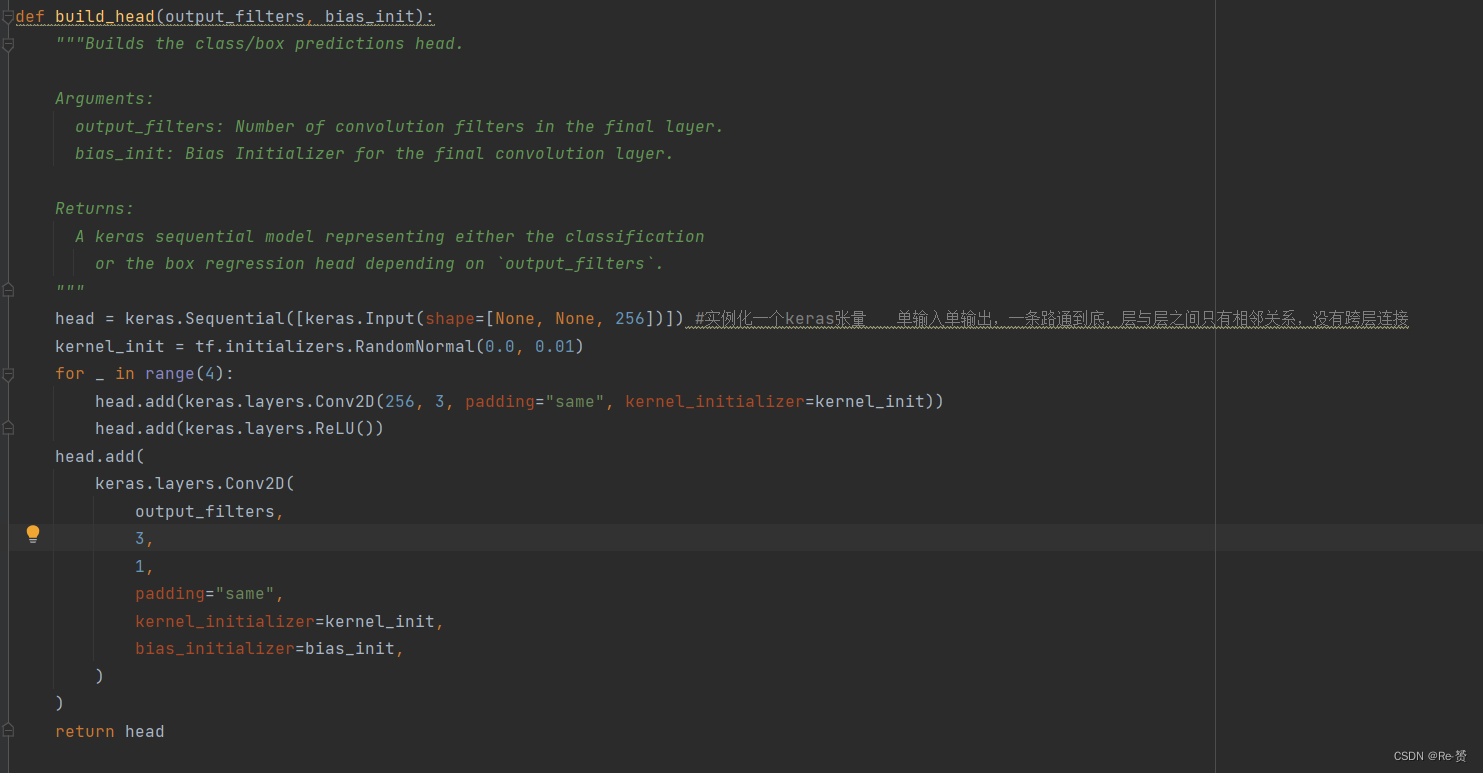
self.cls_head = build_head(9 * num_classes, prior_probability)
self.box_head = build_head(9 * 4, “zeros”)
这两步应该是为了构建后续回归和分类任务的头函数,可以在network.py中查看到这些头的定义,可以看到这个头主要由CNN组成
以上关于model的初始化问题结束,接下来关注模型的call方法也就是train时运行的函数















 856
856











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









