







系列目录
lab1 地址 : lab1
lab2 地址 :lab2
lab3 地址 :lab3
lab4 地址 :lab4
lab5 地址 :lab5
lab6 地址 :lab6
一、实验概述
In this lab you will implement log-based rollback for aborts and log-based crash recovery。
在本次试验中主要实现的是由于基于日志的回滚(aborts)与基于日志的故障恢复,也因此就是要实现undo与redo日志的实现。
SimpleDB日志格式
在LogFile中日志格式主要有以下几种:
static final int ABORT_RECORD = 1;
static final int COMMIT_RECORD = 2;
static final int UPDATE_RECORD = 3;
static final int BEGIN_RECORD = 4;
static final int CHECKPOINT_RECORD = 5;
ABORT_BEGIN: 事务开始时调用,由Transaction. start()调用LogFile中的logXactionBegin()进行写入。ABORT_RECORD: 事务发生abort时调用,由Transaction.transactionComplete()调用LogFile中的logAbort()进行写入。COMMIT_RECORD: 事务commit时调用,由Transaction.transactionComplete()调用LogFile中的logCommit()进行写入。同时调用logCommit()会调用force()会强制将还在channel缓冲的数据刷到disk。UPDATE_RECORD:脏页刷盘时写入(也因此不管事务有无提交,后续讨论force相关再提)。调用logWrite()写入更新记录日志。CHECKPOINT_RECORD: 当log system关闭时或由测试文件调用,由方法logCheckpoint()写入,并且这个方法会先调用force(),再调用Database.getBufferPool().flushAllPages();强制刷新。其记录的则是当前live的事务(因为需要将它们刷盘)。
值得一提的关于写入的方法都应该是先写入日志相关的,然后再进行
Database.getBufferPool().flushAllPages()刷新数据实现WAL(Write-Ahead Logging),实现备份容灾。
而关于每种日志的格式,则在各自调用写入的方法中。
steal/force策略:
-
steal/no-steal主要决定了磁盘上是否会包含uncommitted的数据。force/no-force主要决定了磁盘上是否会不包含已经committed的数据。
-
之前lab4在outline2.3节中也有也有提过,只不过是针对BufferPool实现的NO STEAL/FORCE:
- You shouldn’t evict dirty (updated) pages from the buffer pool if they are locked by an uncommitted transaction (this is NO STEAL).
- On transaction commit, you should force dirty pages to disk (e.g., write the pages out) (this is FORCE)。
当时是由于严格两阶段提交,所以BufferPool上的脏页必须等事务提交才能将脏页刷入,磁盘上不包含uncommitted的数据。
-
- 而BufferPool毕竟是存在内存上的,由于断电等故障会导致数据丢失。因此对于如果需要回滚到事务提交前的状态则需要undo日志,实现STEAL。且对于已经进行修改的脏页,需要恢复则可以通过redo日志来进行刷取到磁盘。并且不要求事务提交后强制将数据刷进磁盘,实现日志的NO FORCE。
- 而对日志的NO FORCE还有一个好处就是将磁盘的写入由随机写为了顺序写,因为假设像BufferPool一样,那么备份的日志则是随机IO,而redo日志的实现方式则是一条更新语句,追加一条redo日志,变为了追加写,也就是顺序IO。在备份数据上将会更快。
- 现在DBMS常用的是steal/no-force策略,因此一般都需要记录redo log和undo log。这样可以获得较快的运行时性能,代价就是在数据库恢复(recovery)的时候需要恢复备份,增大了系统重启的时间。
而对于lab中的代码其实也都是写死的,而不是配置的,因此对force/no-force还是需要讨论的。首先来看日志是否是在提交事务时进行刷盘,也就是看COMMIT_RECORD对应的logCommit是在什么时候调用:
public void transactionComplete(boolean abort) throws IOException {
if (started) {
//write abort log record and rollback transaction
if (abort) {
Database.getLogFile().logAbort(tid); //does rollback too
}
// Release locks and flush pages if needed
Database.getBufferPool().transactionComplete(tid, !abort); // release locks
// write commit log record
if (!abort) {
Database.getLogFile().logCommit(tid);
}
//setting this here means we could possibly write multiple abort records -- OK?
started = false;
}
}
可以看出在事务完成时,BufferPool与log system都进行force刷盘了。而这其实就不能算是no-force。
而回看outline中具体的描述:
Your BufferPool already implements abort by deleting dirty pages, and pretends to implement atomic commit by forcing dirty pages to disk only at commit time. Logging allows more flexible buffer management (STEAL and NO-FORCE), and our test code calls BufferPool.flushAllPages() at certain points in order to exercise that flexibility.
这段描述关于STEAL and NO-FORCE其实是指BufferPool.flushAllPages() 中的调用,而与事务分开讨论了。
/**
* Write all pages of the specified transaction to disk.
*/
public synchronized void flushPages(TransactionId tid) throws IOException {
// some code goes here
// not necessary for lab1|lab2
for (Map.Entry<PageId, LRUCache.Node> group : this.lruCache.getEntrySet()) {
PageId pid = group.getKey();
Page flushPage = group.getValue().val;
TransactionId flushPageDirty = flushPage.isDirty();
Page before = flushPage.getBeforeImage();
// 涉及到事务提交就应该setBeforeImage,更新数据,方便后续的事务终止能回退此版本
flushPage.setBeforeImage();
if (flushPageDirty != null && flushPageDirty.equals(tid)) {
Database.getLogFile().logWrite(tid, before, flushPage);
Database.getCatalog().getDatabaseFile(pid.getTableId()).writePage(flushPage);
}
}
}
/**
* Flushes a certain page to disk
*
* @param pid an ID indicating the page to flush
*/
private synchronized void flushPage(PageId pid) throws IOException {
// some code goes here
// not necessary for lab1
Page target = lruCache.get(pid);
if(target == null){
return;
}
TransactionId tid = target.isDirty();
if (tid != null) {
Page before = target.getBeforeImage();
Database.getLogFile().logWrite(tid, before,target);
Database.getCatalog().getDatabaseFile(pid.getTableId()).writePage(target);
}
}
从这里则可以看出,这边虽然flushPage进行BufferPool刷盘了,但是对于log system来说只是写入更新log,则这一步的确是no-force。那么反过来在看flushPages的调用时机就变得很重要。而刚刚分析了flushPages的调用其实与事务绑定有很大的关联,并且在事务完成的时候自动就提交了,也因此如果真的要做到no-force,则就只能按照outline的描述中,单单只在测试代码调用BufferPool.flushAllPages() 这个函数,与事务分开实现steal与no-force。
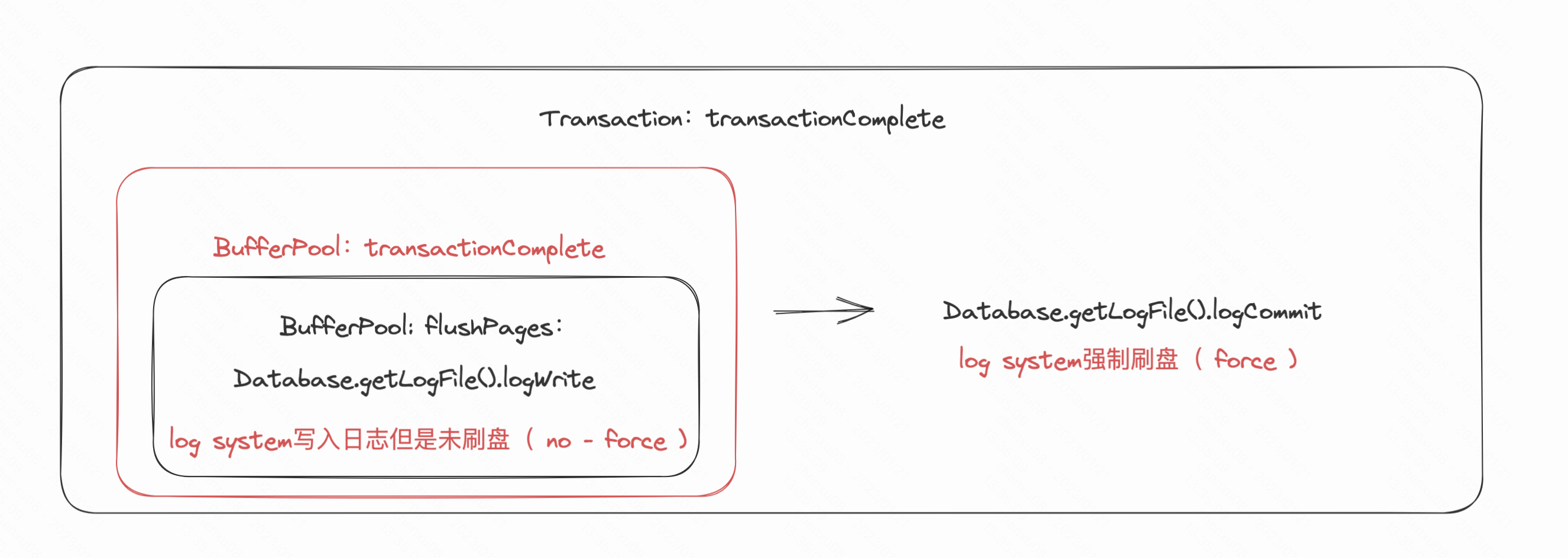
理解steal/force的原因笔者觉得其实还有一个重点:因为logWrite其实就是写入脏页,而实验中BufferPool的2SPL(严格两阶段锁定协议)因为2SPL,是做到事务与脏页强绑定的,需要等到事务提交才能刷取脏页到磁盘。这就意味着脏页中没有未提交的事务。而大部分的情况下我们BufferPool可以不需要2SPL。因为很多时候只是普通提交一个sql,而这并不需要直接刷盘,直接采用普遍的淘汰方式如先进先出、LRU、LFU等,等没有可用的页时(全是脏页时,脏页中也可能会有已经提交后的脏页),再全部刷盘,减少io操作。
二、实验正文
Exercise 1 - rollback
练习一实现的是回滚。实现回滚的重点则是具体回看以上日志格式提到的写入格式。然后区分开来,最终读取UPDATE_RECORD中的before页面(修改前的页面)实现回滚,并且一次事务中可能会有多个更新记录。然后一次事务中的更新记录必须只回滚一次。所以需要去重,否则会导致多次回退版本,导致测试不通过。
public void rollback(TransactionId tid)
throws NoSuchElementException, IOException {
synchronized (Database.getBufferPool()) {
synchronized (this) {
preAppend();
// some code goes here
raf.seek(tidToFirstLogRecord.get(tid.getId()));
Set<PageId> rollbackPage = new HashSet<>();
while (true){
try {
int curType = raf.readInt();
long curTid = raf.readLong();
// 每次回滚对应页只能回滚上一次版本,因此一个页中的多次修改记录也只能rollback一次
switch (curType){
// 除了update其他全都略过
case CHECKPOINT_RECORD:
int keySize = raf.readInt();
while (keySize-- > 0) {
raf.readLong();
raf.readLong();
}
break;
case UPDATE_RECORD:
Page beforeImg = readPageData(raf);
Page afterImg = readPageData(raf);
if(curTid == tid.getId() && !rollbackPage.contains(beforeImg.getId())){
rollbackPage.add(beforeImg.getId());
DbFile file = Database.getCatalog().getDatabaseFile(beforeImg.getId().getTableId());
file.writePage(beforeImg);
Database.getBufferPool().removePage(afterImg.getId());
}
}
// 略过offset
raf.readLong();
}catch (EOFException e){
break;
}
}
}
}
}
Exercise 2 - Recovery
做exercise2则需要深入理解下recovery的条件,什么时候进行recovery。
- 日志中的checkpoint会导致数据强制刷盘。而检查点的触发条件,在正常情况下,仅仅只是周期性的定时检查,不涉及事务。因此在checkpoint的阶段可能会有未提交的事务也有已经提交的事务但是未刷盘,而此时对于前者则需要回滚(undo),对于已经提交的事务此时需要redo。
- 还有一个点就是什么时候开始读取第一个恢复点。第一个恢复点应该是crash时记录到的checkpoint中记录的最早的活跃的事务的offset。并且获取正在live的事务的必须只能通过checkpoint,而不能通过
tidToFirstLogRecord,因为在crash情况下tidToFirstLogRecord内存的数据访问不到。当然为了快速通过实验也可以直接从0开始读取全量日志进行恢复工作,但是这种做法应该是不提倡的。
/**
* recover的点应该正在活跃的事务中最早的那个
* tidToFirstLogRecord中记录的key只有存活的
*/
public synchronized long getRecoverOffset(){
try {
raf.seek(0);
long checkPoint = raf.readLong();
if(checkPoint == -1){
return -1L;
}else {
// 移动到检查点,并略过日志头(type,tid信息)
raf.seek(checkPoint);
raf.readInt();
raf.readLong();
int keySize = raf.readInt();
long recoverOffset = Long.MAX_VALUE;
while (keySize-- > 0) {
raf.readLong();
long offset = raf.readLong();
if(offset < recoverOffset){
recoverOffset = offset;
}
}
return recoverOffset;
}
} catch (IOException e) {
throw new RuntimeException(e);
}
}
/**
* 理论上存在刚好执行到commit写入log后但是未force此时crash了,这时需要redo
* 而对于在事务未提交却crash的则需要undo
* Recover the database system by ensuring that the updates of
* committed transactions are installed and that the
* updates of uncommitted transactions are not installed.
*/
public void recover() throws IOException {
synchronized (Database.getBufferPool()) {
synchronized (this) {
recoveryUndecided = false;
// some code goes here
raf = new RandomAccessFile(logFile, "rw");
Map<Long, List<Page>> beforeImgs = new HashMap<>();
Map<Long, List<Page>> afterImgs = new HashMap<>();
HashSet<Long> committed = new HashSet<>();
long recoverOffset = getRecoverOffset();
if(recoverOffset != -1L){
raf.seek(recoverOffset);
}
while (true){
try {
int curType = raf.readInt();
long curTid = raf.readLong();
switch (curType){
case COMMIT_RECORD:
committed.add(curTid);
break;
case CHECKPOINT_RECORD:
int keySize = raf.readInt();
while (keySize-- > 0) {
raf.readLong();
raf.readLong();
}
break;
case UPDATE_RECORD:
Page beforeImg = readPageData(raf);
Page afterImg = readPageData(raf);
List<Page> undoList = beforeImgs.getOrDefault(curTid,new ArrayList<>());
List<Page> redoList = afterImgs.getOrDefault(curTid,new ArrayList<>());
undoList.add(beforeImg);
redoList.add(afterImg);
beforeImgs.put(curTid,undoList);
afterImgs.put(curTid,redoList);
}
// 略过offset
raf.readLong();
}catch (EOFException e){
break;
}
}
// 处理未提交的事务利用before进行undo
for (long tid :beforeImgs.keySet()) {
if (!committed.contains(tid)) {
List<Page> pages = beforeImgs.get(tid);
for (Page undo : pages) {
Database.getCatalog().getDatabaseFile(undo.getId().getTableId()).writePage(undo);
}
}
}
//处理已提交事务利用after进行redo
for (long tid : committed) {
if (afterImgs.containsKey(tid)) {
List<Page> pages = afterImgs.get(tid);
for (Page redo : pages) {
Database.getCatalog().getDatabaseFile(redo.getId().getTableId()).writePage(redo);
}
}
}
}
}
}
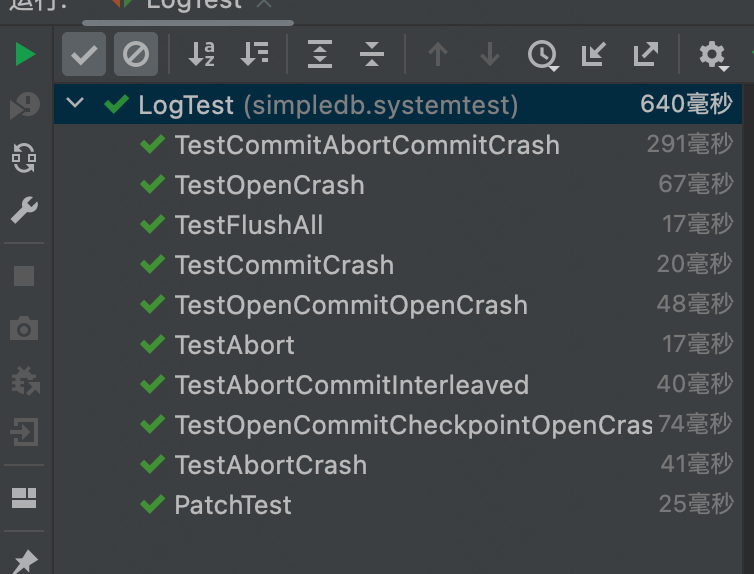
测试结果:
总结
至此6.830的实验就到此为止了,难度相较于会比6.824来的低,因为并发下的测试相对于没有那么多,且java的单元测试也比较简单,但是边看书、ppt,学一套lab下来还是可以比较清楚的数据库的实现。
















 849
849











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











