






embedding
-
将升维降维比喻成靠近或者远离一幅画,深度学习的过程就是不断前进后退直到找到一个合适的最能看清画的距离
-
embedding层将我们的稀疏矩阵,通过一些线性变换,变成了一个密集矩阵,这个密集矩阵用了N个特征来表征所有的文字,在这个密集矩阵中,表象上代表着密集矩阵跟单个字的一一对应关系,实际上还蕴含了大量的字与字之间,词与词之间甚至句子与句子之间的内在关。他们之间的关系,用的是嵌入层学习来的参数进行表征。从稀疏矩阵到密集矩阵的过程,叫做embedding,很多人也把它叫做查表,因为他们之间也是一个一一映射的关系。
- Embedding层就是以one hot为输入、中间层节点为字向量维数的全连接层!而这个全连接层的参数,就是一个“字向量表”。
- 再次强调,降低了运算量不是因为词向量的出现,而是因为把one hot型的矩阵运算简化为了查表操作。
池化层 线性层 激活函数
-
池化层
池化的作用则体现在降采样:保留显著特征、降低特征维度,增大 kernel 的感受野。 另外一点值得注意:pooling 也可以提供一些旋转不变性。 池化层可对提取到的特征信息进行降维,一方面使特征图变小,简化网络计算复杂度并在一定程度上避免过拟合的出现;一方面进行特征压缩,提取主要特征。
有最大池化和平均池化两张方式。 -
线性层
又称为全连接层,其每个神经元与上一个层所有神经元相连,实现对前一层的线性组合或线性变换。 -
激活函数层

如果没有非线性变换,由于矩阵乘法的结合性,多个线性层的组合等价于一个线性层。
激活函数对特征进行非线性变换,赋予了多层神经网络具有深度的意义。
常见激活函数:Sigmoid、tanh、ReLU、LeakyReLU、PReLUde、RReLU
bert
原理



用Sep将句子分为两部分,分别赋予ID0和1,并给不同的向量以区分



代码

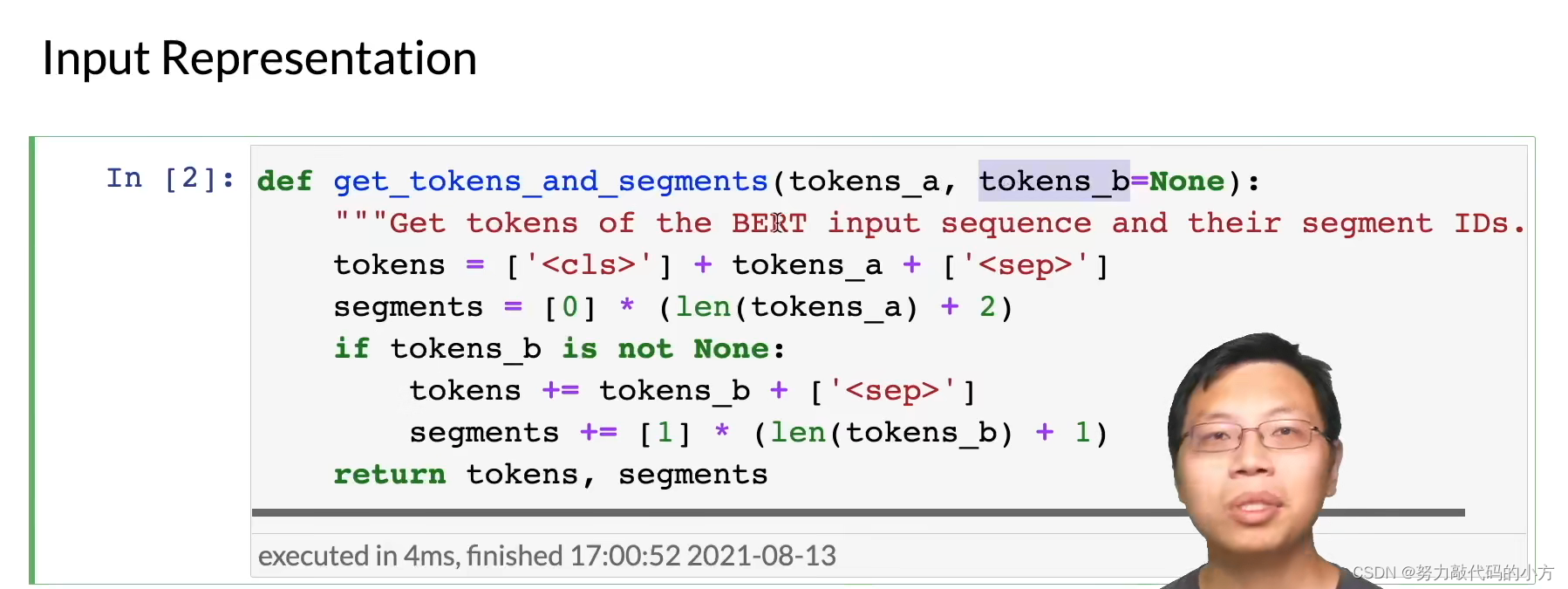
第一个句子是segment 0 +2是因为有两个分隔符
第二个句子是segment1 中间用分隔 同+1 是因为分隔符
至此将句子变为bert的输入

[2,8,768] 即[batch size ,文本长度, 隐藏层数目]

Tokenizer
Pytorch Transformer Tokenizer常见输入输出实战详解
通常,我们会直接使用Transformers包中的AutoTokenizer类来创建并使用分词器。分词器的工作流程如下:
- 将给定的文本拆分为称为Token(词或标记)的单词(或部分单词、标点符号等)。
- 将这些Token转换为数字编码,以便构建张量并将其提供给模型。
- 添加模型正常工作所需的任何输入数据。例如特殊字符[CLS],[SEP]等
三个最常用的输出字段:“input_idx”、“attention_mask”,“token_type_ids”
Hugging face
scp远程安全复制文件
scp 远程安全复制文件
scp是 secure copy 的缩写,相当于cp命令 + SSH。它的底层是 SSH 协议,默认端口是22,相当于先使用ssh命令登录远程主机,然后再执行拷贝操作。
scp主要用于以下三种复制操作。
- 本地复制到远程。
- 远程复制到本地。
- 两个远程系统之间的复制。
使用scp传输数据时,文件和密码都是加密的,不会泄漏敏感信息。
复制本地文件夹到远程指定端口:
E:\study\BigData>scp -P 25604 -r data root@192.168.xx.xx:/root/wx_bigdata
pytorch
微软PyTorch基础知识
(特别详细)
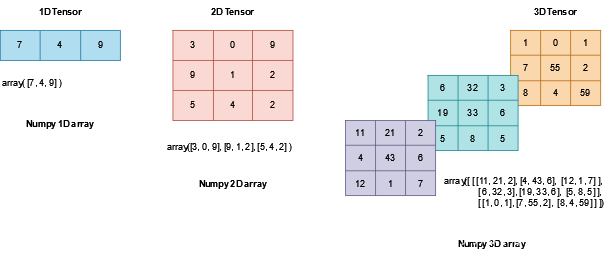
tensors
类似于矩阵的数据结构,但可以在GPU上跑
# 初始化
# form data
data = [[1, 2],[3, 4]]
x_data = torch.tensor(data)
# from numpy array
np_array = np.array(data)
x_np = torch.from_numpy(np_array)
# from another tensor
x_ones = torch.ones_like(x_data) # retains the properties of x_data
print(f"Ones Tensor: \n {x_ones} \n")
#Ones Tensor:
#tensor([[1, 1],
# [1, 1]])
x_rand = torch.rand_like(x_data, dtype=torch.float) # overrides the datatype of x_data
print(f"Random Tensor: \n {x_rand} \n")
#Random Tensor:
# tensor([[0.2476, 0.2297],
# [0.6623, 0.8990]])
# 随机或固定值
shape = (2,3,)# 固定张量为2*3
rand_tensor = torch.rand(shape)# 随机
ones_tensor = torch.ones(shape)# 全1
zeros_tensor = torch.zeros(shape)# 全0
# 常用参数
# shape、dtype、device
默认情况下,张量是在CPU上创建的,可以通过以下方法移动到GPU上:
# We move our tensor to the GPU if available
if torch.cuda.is_available():
tensor = tensor.to('cuda')
切片
tensor = torch.ones(4, 4)
print('First row: ',tensor[0])
print('First column: ', tensor[:, 0])
print('Last column:', tensor[..., -1])
tensor[:,1] = 0
print(tensor)
#First row: tensor([1., 1., 1., 1.])
#First column: tensor([1., 1., 1., 1.])
#Last column: tensor([1., 1., 1., 1.])
#tensor([[1., 0., 1., 1.],
# [1., 0., 1., 1.],
# [1., 0., 1., 1.],
# [1., 0., 1., 1.]])
拼接
t1 = torch.cat([tensor, tensor, tensor], dim=1)
print(t1)
#tensor([[1., 0., 1., 1., 1., 0., 1., 1., 1., 0., 1., 1.],
# [1., 0., 1., 1., 1., 0., 1., 1., 1., 0., 1., 1.],
# [1., 0., 1., 1., 1., 0., 1., 1., 1., 0., 1., 1.],
# [1., 0., 1., 1., 1., 0., 1., 1., 1., 0., 1., 1.]])
数学运算
#rand_like()返回与 input 大小相同的张量,该张量由区间上均匀分布的随机数填充[0, 1)
# This computes the matrix multiplication between two tensors. y1, y2, y3 will have the same value
#矩阵相乘
y1 = tensor @ tensor.T
y2 = tensor.matmul(tensor.T)
y3 = torch.rand_like(tensor)
torch.matmul(tensor, tensor.T, out=y3)
# This computes the element-wise product. z1, z2, z3 will have the same value
#对应位相乘
z1 = tensor * tensor
z2 = tensor.mul(tensor)
z3 = torch.rand_like(tensor)
torch.mul(tensor, tensor, out=z3)
其他操作
- item() 将单一元素的张量转为普通变量
- 后缀_表示就地操作 如tensor.add_(5)即tensor加5并赋给tensor
- CPU上的张量和Numpy数组可以共享底层内存位置,即同时变化
n = np.ones(5)
t = torch.from_numpy(n)
np.add(n, 1, out=n)
print(f"t: {t}")# t: tensor([2., 2., 2., 2., 2.], dtype=torch.float64)
print(f"n: {n}")# n: [2. 2. 2. 2. 2.]
ema(指数移动平滑)
【炼丹技巧】指数移动平均(EMA)的原理及PyTorch实现
实现代码(用于理解ema结构):
class EMA():
def __init__(self, model, decay):
self.model = model
self.decay = decay
self.shadow = {}
self.backup = {}
def register(self):
for name, param in self.model.named_parameters():
if param.requires_grad:
self.shadow[name] = param.data.clone()
def update(self):
for name, param in self.model.named_parameters():
if param.requires_grad:
assert name in self.shadow
new_average = (1.0 - self.decay) * param.data + self.decay * self.shadow[name]
self.shadow[name] = new_average.clone()
def apply_shadow(self):
for name, param in self.model.named_parameters():
if param.requires_grad:
assert name in self.shadow
self.backup[name] = param.data
param.data = self.shadow[name]
def restore(self):
for name, param in self.model.named_parameters():
if param.requires_grad:
assert name in self.backup
param.data = self.backup[name]
self.backup = {}
# 初始化
ema = EMA(model, 0.999)
ema.register()
# 训练过程中,更新完参数后,同步update shadow weights
def train():
optimizer.step()
ema.update()
# eval前,apply shadow weights;eval之后,恢复原来模型的参数
def evaluate():
ema.apply_shadow()
# evaluate
ema.restore()
【炼丹技巧】指数移动平均(EMA)【在一定程度上提高最终模型在测试数据上的表现(例如accuracy、FID、泛化能力…)】
ema实际就是求出前n次的平均值。
实际使用时,我们在训练过程仍然使用原来的权重 weights,因为ema的 shadow_weights是根据w的值求得的。
之后在测试过程中使用 shadow_weights 来代替 weights 作为神经网络边的权重,这样在测试数据上效果会更好。















 3934
3934











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









