






PSTR: End-to-End One-Step Person Search With Transformers
Abstract
本文提出一种新的基于Transformer的一步行人搜索框架PSTR,在一个架构中联合执行行人检测和行人重识别(re-id)。PSTR包括一个行人搜索专用(PSS)模块,该模块包含用于行人检测的检测编码器-解码器以及用于行人重识别的判别式重识别解码器。判别式重识别解码器利用具有共享解码器的多级监督方案进行判别式re-id特征学习,还包括一个部分注意力块来编码一个人不同部位之间的关系。本文进一步提出一种简单的多尺度方案,以支持不同规模的行人实例的重识别。PSTR联合实现了物体级识别(检测)和实例级匹配(重识别)的不同目标。本文首次提出了一个基于Transformer的端到端一步法行人搜索框架。本文在CUHK-SYSU和PRW两个常用的数据集上进行了实验。我们广泛的消融实验显示了所提议方法PSTR的贡献的优点。此外,所提出的PSTR在两个基准上都设置了新的最先进水平。在具有挑战性的PRW基准上,PSTR取得了56.5%的平均精度(mAP)分数。
Journal:2022 IEEE/CVF CONFERENCE ON COMPUTER VISION AND PATTERN RECOGNITION (CVPR)
论文地址:https://arxiv.org/pdf/2204.03340.pdf
会议日期:JUN 18-24, 2022
发表日期:Thu, 7 Apr 2022
作者名称:Jiale Cao, Yanwei Pang, Rao Muhammad Anwer, Hisham Cholakkal, Jin Xie, Mubarak Shah, Fahad Shahbaz Khan
代码地址:https://github.com/JialeCao001/PSTR
1.Introduction
行人搜索旨在从真实世界的未裁剪图像库中检测和识别目标行人,这可以看作是行人检测[2,20,24,36]和行人重识别(re-id)[7, 18, 38]的联合任务。行人搜索需要解决这两个不同子任务的挑战,并在一个统一的框架中联合优化它们。
行人搜索方法大致可以分为两步方法[5,11,39]和一步方法[6,32,34]。两步方法通常将两个子任务分离开来,其中行人检测和行人重识别是分别执行的(图1(a))。首先,使用一个现成的检测网络(如Faster R-CNN[25])来检测行人;其次,对检测到的行人进行裁剪并将其调整为固定分辨率,然后利用行人重识别网络来识别裁剪后的行人。虽然取得了很好的性能,但大多数两步方法的计算成本很高。相比之下,一步方法使用单个网络同时检测和识别行人(图1(b))。首先,通过共享网络提取特征;然后,由同一网络中的两个分支执行行人检测和重识别。
尽管最近在行人搜索方面取得了进展,但两步法和一步法都采用了手工设计的机制,如使用非最大抑制(NMS)程序来过滤每个人的重复预测。最近,Transformer[9,24]在几个视觉任务中显示出了有希望的结果,包括目标检测[2,37]。基于Transformer的目标检测器的编码器-解码器设计减轻了采用不同手工设计组件的需要,从而形成更简单的端到端可训练架构。此外,Transformer架构可以很容易地扩展到多任务学习框架[13,27]。尽管它们最近取得了成功,但Transformer还没有被用于行人搜索。本文研究了设计一个简单但准确的基于Transformer的端到端一步行人搜索框架的问题。
在设计基于一步Transformer的行人搜索框架时,一种简单的方法是采用目标检测器,如DETR[3]来检测行人,而重识别子任务可以以不同的方式执行。(i)可以通过引入re-id辅助任务来修改目标检测器中的Transformer解码器。(ii)两个独立的标准编码器-解码器网络可用于执行检测和重识别子任务。然而,我们观察到这些策略很难取得令人满意的结果。

图1所示,将所提出的PSTR架构(c)与现有的两步(a)和一步(b)范式进行比较。
(a)在两步范式中,行人检测和行人重识别子任务是通过两个独立的网络执行的。在这里,边界框首先由检测网络预测,然后裁剪和调整大小(C&R),然后将其馈送到re-id网络。
(b)在one-step模式中,检测和重识别分支共享相同的骨干网络。
(c)与这两种范式不同,所提出的PSTR是一种基于Transformer的端到端单步架构,具有person-search专用模块,可以联合执行检测和重识别,而不需要NMS后处理步骤。
1.1. Motivation
我们考虑改进的re-id特征判别性:行人搜索框架下的检测和重识别子任务
改进re-id特征判别性:行人搜索中的检测和重识别子任务具有不同的目标。行人检测致力于通过区分行人类别和背景来进行目标级别的识别和定位。在这里,图像内部和图像间(跨图像)的所有行人实例都被分组到一个行人类别中。另一方面,行人重识别子任务旨在识别实例级的行人。这里,我们希望将行人实例与图像数据库进行匹配,因此需要区分同一行人类别中不同行人的实例。因此,Transformer re-id解码器需要与对应的检测器不同,并希望生成具有判别力的特征,专门用于执行实例级匹配。
编码多尺度信息以实现行人重识别:尺度变化是行人搜索中一个具有挑战性的问题。同一个人在不同的摄像机下可能尺度变化较大,增加了行人匹配的难度。大多数现有的行人检测方法要么遵循先检测行人再调整大小到固定分辨率的策略,要么采用特征RoI pooling方案[25]来获得尺度不变的表示。本文研究了一种在Transformer架构中编码多尺度信息的方法,以实现行人搜索中的重识别,而不是图像缩放或特征池化。
1.2. Contributions
本文提出了一种新的基于Transformer的端到端行人搜索框架PSTR。PSTR将行人搜索视为序列预测问题,检测图像中的所有行人以及他们各自的re-id特征(图1©)。本文在PSTR中引入了一个行人搜索专用(PSS)模块,可以同时进行行人检测和重识别。PSS模块旨在通过引入一个判别性re-id解码器来提高re-id特征的特征判别性,该解码器利用了一个共享解码器设计的多级监督方案。在判别式re-id解码器中引入部分注意力块,以捕获不同部分的关系。此外,我们提出了一个简单的多尺度方案的判别式re-id解码器,以解决不同尺度下的行人匹配问题。据我们所知,PSTR是第一个基于Transformer的端到端一步行人搜索框架。
我们在CUHK-SYSU[32]和PRW[39]数据集上验证了PSTR的有效性。我们全面的消融实验显示了贡献的优点。此外,PSTR在两个基准上都设置了新的最先进水平。当使用ResNet50[13]时,PSTR在PRW基准上取得了49.5%的mAP得分,而在单个V100 GPU上的运行速度为56毫秒(ms)(见图2)。在基于Transformer的骨干[29]上,PSTR获得了最好的报告结果,mAP得分为56.5%。

图2,在PRW测试集上与现有的一步方法进行了精度(AP)和速度(ms)的比较。所有方法都使用ResNet50骨干网络,并且在V100 GPU上报告了速度。所提出的基于端到端一步Transformer的PSTR在速度和精度方面都优于现有方法。
2.Related Work
行人搜索:行人搜索方法大致可以分为两步法和一步法。为了解决检测和重识别子任务,两步方法[11,16,39]利用两个单独的网络专门用于检测[22,23,25]和重识别[1,35]。Zhang等人通过引入两个独立的模型对行人搜索进行探索。Chen等人[5]提出了一种掩码引导的双流网络来获得增强的特征表示。Wang等人在[28]中使用了基于身份引导的查询检测器来提取类查询候选框,并采用了适应于行人重识别检测的模型。一步方法将行人检测和行人重识别集成到一个统一的框架中。Xiao等人[32]在Fast R-CNN中引入re-id分支进行行人匹配。Chen等人[6]提出使用范数感知嵌入来分离检测和重识别。Munjal等人[21]通过在骨干中集成一个查询引导的孪生挤压-激励块来建立查询图像和图库图像之间的关系。[8]的工作采用孪生网络,将整个图像和裁剪后的人物作为输入,以更好地指导人物的特征学习。现有的一些工作[4,17,34]探索了利用上下文信息进行人员搜索的问题。最近,Yan等人[33]提出了一种新的无锚点的行人搜索方法(AlignPS)。
基于Transformer的端到端目标检测:最近,DETR[3]引入了一个端到端的目标检测管道,通过一组检测查询来预测目标。DETR算法存在收敛速度慢、对小尺寸对象处理性能较差的问题。为了解决这些问题,Deformable DETR[41]用一个可变形注意力模块代替标准注意力模块,该模块专注于参考点周围的一小部分局部采样点。对于输入图像,从主干获得的特征首先由编码器增强。通过增强特征和检测查询,可变形Transformer解码器生成N个最终的目标特征。最后,预测头预测分类分数和边界位置。
3.Method
整体架构:图3(a)显示了我们的PSTR的整体架构。基于transformer的目标检测器deformable DETR[41]。PSTR用person-search specialized (PSS)模块取代了可变形DETR中的标准编码器-解码器(图3(b))。PSS模块用于执行行人搜索的检测和重识别,它包括一个检测编码器-解码器和一个判别式重识别解码器。检测编码器-解码器采用骨干特征,并使用三个级联解码器和一个预测头进行行人回归和分类,如[41]。判别式re-id解码器利用多级监督方案和共享解码器设计,将来自三个检测解码器之一的re-id特征查询作为输入。然后生成具有判别力的re-id特征用于实例级匹配。在判别式(共享)重识别解码器中,多级监督方案提供不同的输入重识别特征查询和框采样位置,从而指导行人搜索的特征学习。除了共享设计外,新的判别式re-id解码器还包括一个部分注意力解码器,以捕获不同人体部分之间的关系。为了支持不同尺度下跨行人实例的重识别,利用PSS模块利用不同层的特征进行多尺度扩展。然后,将得到的多尺度re-id特征串联起来,与查询对象进行实例级匹配。

(a)端到端单步PSTR的总体架构。PSTR包括一个主干和一个人员搜索专用(PSS)模块,用于执行人员搜索的检测和重新识别。
(b) PSS模块由检测编码器-解码器和新型判别式重识别解码器组成。检测编码器-解码器采用骨干特征,并使用三个级联解码器和一个预测头进行行人回归和分类。判别式re-id解码器利用具有共享解码器的多级监督方案,在训练期间将来自三个检测解码器之一的re-id特征查询作为输入。多级监督方案使检测到的盒子位置多样化并输入re-id特征查询,从而增强re-id特征的可判别性。进一步在判别式re-id解码器中引入部分注意力块,以捕获一个人不同部位之间的关系。PSS模块被用于多尺度扩展,以支持不同尺度下跨行人实例的重识别。
3.1. Person Search-Specialized Module
在PSTR中,我们从骨干网络(如ResNet[13]或PVT[29])获得特征,并将其通过可变形卷积层来提取局部信息。得到的特征Pi被提供给我们的人员搜索专用(PSS)模块。此外,PSS模块将一组检测查询作为额外的输入,并分别生成用于检测和重识别的特征。PSS模块由一个检测编码器-解码器(章节3.1.1)和一个判别式re-id解码器(章节3.1.2)组成。检测编码器-解码器为检测查询预测分类和回归特征。另一方面,判别式re-id解码器为检测查询提取re-id特征。
3.1.1 Detection Encoder-Decoder
在PSS模块中,基于可变形DETR[41]构建检测编码器-解码器。如图3(b)所示,检测编码器-解码器由3个编码器和3个解码器组成,利用特征 P i P_{i} Pi作为输入。每个编码器都有一个可变形的自注意力层和一个MLP层。每个编码器的输出特征表示为 F e 1 F_{e1} Fe1, F e 2 F_{e2} Fe2, F e 3 F_{e3} Fe3。因此,第一个解码器将 F e 3 F_{e3} Fe3特征和 N N N个检测查询作为输入。每个解码器包含一个标准的自注意力层,一个可变形的交叉注意力层和一个MLP层。每个解码器的输出特征表示为 F d 1 F_{d1} Fd1、 F d 2 F_{d2} Fd2、 F d 3 F_{d3} Fd3。我们对所有三个编码器和解码器使用的特征长度为256。将解码器特征用于预测头进行框分类和回归,并进一步使用这些特征获取重识别特征查询,以实现具有判别力的重识别解码器。
3.1.2 Discriminative Re-id Decoder
我们引入判别式re-id解码器,为每个行人产生判别式re-id特征。图3(b)显示了我们的判别式re-id解码器。它将特征
P
i
P_{i}
Pi作为输入。判别式re-id解码器利用共享解码器设计的多级监督。为此,判别式re-id解码器利用来自不同检测解码器的特征
F
d
1
F_{d1}
Fd1、
F
d
2
F_{d2}
Fd2、
F
d
3
F_{d3}
Fd3作为reid特征查询,以提高训练过程中re-id特征查询和盒位置(采样位置)的多样性。在推理过程中,利用特征
F
d
3
F_{d3}
Fd3作为re-id特征查询,得到具有判别力的re-id特征。进一步引入由两个部分注意力层组成的部分注意力块,以捕获一个人不同部位之间的关系。判别式re-id解码器通过从检测解码器中获取re-id查询,直接对特征
P
i
P_{i}
Pi进行操作。这种架构设计对于re-id子任务来说比基于标准编码器-解码器的设计更准确。
共享解码器设计的多级监督:设计re-id解码器的一种直接方法是使用最后一个检测特征
F
d
3
F_{d3}
Fd3作为re-id特征查询,并使用re-id解码器进行特征预测,如图4(A)所示。这种设计实现了次优的性能,可能是因为缺乏从单层监督中学习到的判别力强的re-id特征。本文提出两种头韵方案,在re-id解码器中采用多级(中间)监督,以更好地进行re-id特征学习。我们将提出的两种方案称为并行重识别解码器和共享重识别解码器。图4(b)和图4©显示了所提出的两种方案。并行re-id解码器将来自每个检测解码器的特征作为re-id特征查询,利用3个并行解码器层生成re-id特征
F
r
1
F_{r1}
Fr1,
F
r
2
F_{r2}
Fr2,
F
r
3
F_{r3}
Fr3。在这里,re-id特征
F
r
1
F_{r1}
Fr1,
F
r
2
F_{r2}
Fr2仅在训练期间用于提供多级(中间)监督。与并行重识别解码器方案不同,共享重识别解码器方案采用孪生结构,三个重识别特征查询都有一个共享解码器来生成三个重识别特征。与并行re-id解码器类似,共享re-id解码器方案在训练过程中也仅利用特征
F
r
1
F_{r1}
Fr1,
F
r
2
F_{r2}
Fr2。
如前所述,行人搜索中的行人检测和重识别两个子任务具有不同的目标(对象级识别和实例级匹配)。基于此,我们直接利用骨干特征作为判别式re-id解码器的输入,而不是使用检测编码器的特征。通过经验验证,与使用检测编码器的特征相比,这可以带来优越的性能。

图4。re-id解码器设计方案比较。
(a)单层监督的re-id解码器方案使用最后一个检测特征Fd3作为re-id特征查询,使用re-id解码器进行特征预测。与这种单级监督方案不同,本文提出了两种多级监督的重id解码器设计:(b)并行重id和©共享重id解码器。(b)并行re-id方案采用3个并行解码器层,将检测解码器特征(Fd1, Fd2, Fd3)作为查询来生成re-id特征。与并行重识别方案不同,©共享重识别方案采用孪生结构,所有检测解码器都有一个共同的共享重识别解码器来产生相应的重识别特征( F r 1 F_{r1} Fr1, F r 2 F_{r2} Fr2, F r 3 F_{r3} Fr3)。
部分注意力块:为了编码一个人不同部位之间的关系,我们在我们的判别式re-id解码器中引入了部分注意力块(见图5),它采用两层。与可变形注意力[41]类似,我们使用查询特征来预测采样点,这些采样点代表一个人的不同部位。然而,我们观察到来自查询的注意力权重很难有效地捕获行人实例中的部件关系。因此,与标准的可变形注意力不同,我们没有使用来自查询特征的注意力权重。部分注意力在采样点对特征进行平均,然后通过调整交叉注意力模块来聚合不同部分的特征以生成输出。

图5,部分注意力块和部分注意力层。
(a)判别式re-id解码器中的部分注意力块。该块包含两个部分注意力层,以编码不同部分(点)之间的关系。
(b)部分注意力层利用查询特征预测采样点。通过交叉注意力融合来自不同部位的特征,聚合这些采样点对应的特征。
3.2. Multi-Scale Discriminative Re-id Decoder
尺度变化是行人匹配的一个主要挑战,因为同一个人可能被不同尺度的不同摄像机捕捉到。为解决这个问题,本文通过在不同尺度上使用判别式re-id解码器,对其进行了简单的扩展。不同尺度的判别式重识别解码器将检测解码器特征作为重识别特征查询。为了提取多尺度re-id特征,额外的re-id解码器将特征(如 P 2 P_{2} P2, P 3 P_{3} P3)作为输入并进行re-id特征生成。在训练过程中,这些判别式重识别解码器受到独立重识别损失的监督。在推理过程中,将这些具有判别力的不同尺度的re-id特征串联起来,得到用于行人匹配的多尺度re-id特征。
3.3. Training and Inference
PSTR预测图像中每个检测查询的分类分数、位置和reid特征。检测特征
F
d
1
F_{d1}
Fd1、
F
d
2
F_{d2}
Fd2、
F
d
3
F_{d3}
Fd3分别经过2层MLP进行分类定位。特征
F
r
1
F_{r1}
Fr1,
F
r
2
F_{r2}
Fr2,
F
r
3
F_{r3}
Fr3直接用作re-id特性。
在训练过程中,我们建立了一个查找表
V
V
V和一个循环队列
U
U
U来指导重识别特征学习。将所有
L
L
L标记身份的re-id特征存储在
V
V
V中,并将最近mini-batch中
Q
Q
Q标记身份的re-id特征存储在
U
U
U中。在每次迭代中,我们首先计算当前小批量中的re-id特征(例如
F
r
1
F_{r1}
Fr1)与
V
V
V和
U
U
U中所有特征之间的相似性。然后,我们基于相似度计算在线实例匹配(OIM)损失(如下所述)。在反向传播过程中,如果mini-batch中的re-id特征属于真实身份
i
i
i,则更新
V
V
V的第
i
i
i个条目。通过弹出旧的身份,我们同时将新的未标记身份的re-id特征推入
U
U
U。OIM损失[32]最大化当前小批量中每个重识别特征的期望对数似然,即
L
o
i
m
=
l
o
g
p
t
L_{oim} = log p_t
Loim=logpt。这里,pt是一个重识别特征属于真实身份t的概率,根据重识别特征与
V
V
V和
U
U
U上的特征之间的相似度计算。最终得到总的损失函数为:
L
=
λ
1
L
c
l
s
+
λ
2
L
i
o
u
+
λ
3
L
l
1
+
λ
4
L
o
i
m
L = \lambda_1 L_{cls} + \lambda_2 L_{iou} + \lambda_3 L_{l1} + \lambda_4 L_{oim}
L=λ1Lcls+λ2Liou+λ3Ll1+λ4Loim。
L
c
l
s
L_{cls}
Lcls表示分类损失,
L
i
o
u
L_{iou}
Liou表示边界框IoU损失,
L
l
1
L_{l1}
Ll1表示边界框
l
1
\mathcal l_1
l1代价,
L
o
i
m
L_{oim}
Loim表示OIM损失。
λ
1
\lambda_1
λ1,
λ
2
\lambda_2
λ2,
λ
3
\lambda_3
λ3,
λ
4
\lambda_4
λ4是平衡不同损失的超参数,分别设为2.0,5.0,2.0,0.5。
在推理过程中,从一组gallery图像中在给定的query图像中搜索一个带注释的(边界框)查询人。首先,使用PSTR生成查询图像的多个预测,其中每个预测包括分类分数、边界框和re-id特征。然后,将查询人的re-id特征设置为与查询人边界框重叠最大的预测的re-id特征;最后,生成所有图库图像的预测结果,并计算查询人与图库图像中预测结果的re-id特征相似度,以识别图库图像中匹配的人。
4. Experiments
4.1. Datasets and Implementation Details
CUHK-SYSU[32]是一个大规模的人物搜索数据集。总共有18,184张图像,涵盖了各种现实世界的挑战,包括视角变化、光照变化和不同的背景。它有96143个带注释的行人,8432个不同的身份。训练集包括11,206张图像,55272名行人和5532个身份。测试集包含6978张图像,40871名行人和2900个身份。在推理过程中,数据集定义了不同大小的图库集,范围从50到4000。与[32,33]一样,我们使用图库大小为100的标准设置进行实验。此外,分析了改变图库大小时的性能。
PRW[39]是一个由6个静态摄像机采集的具有挑战性的人物搜索数据集。训练集包含5704张图像,18048名行人和482个身份。测试集有6,112张图像,25,062名行人和450个身份。
评价指标:我们采用两个标准指标进行人员搜索性能评价:平均精度(mAP)和top-1精度。
实现细节:用两个ImageNet[26]预训练骨干进行了实验:ResNet50[13]和最近引入的基于transformer的PVTv2-B2[29],它们具有类似的参数。我们的PSTR使用AdamW优化器在单个Tesla V100 GPU上进行训练。在训练过程中,采用了一种多尺度训练方案,并将焦点OIM损失作为对齐[33]。在推理过程中,将测试图像缩放为1500 × 900像素的固定大小。模型总共训练了24个epoch,我们使用的小批量大小为2。初始学习率设置为0.0001,并在第19和23个epoch将学习率降低10倍。我们会用MindSpore来支持它。
4.2. State-of-the-art Comparison
本文将基于端到端Transformer的PSTR与最先进的两步和一步方法进行了比较。
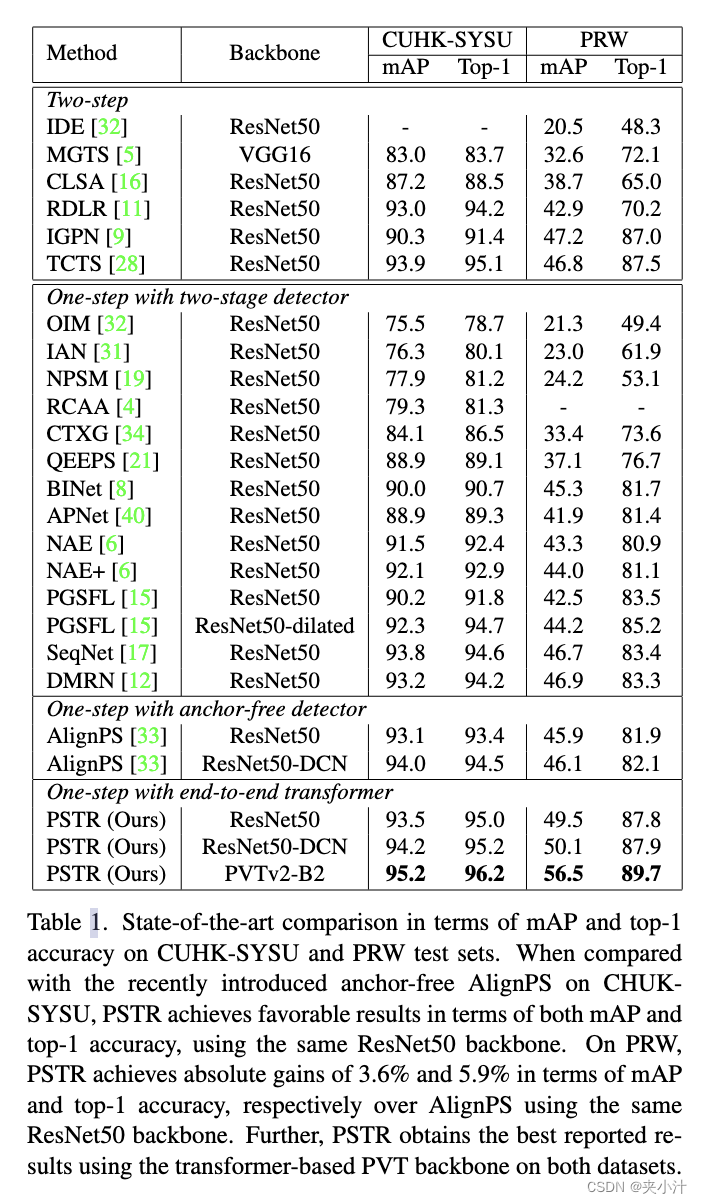
在CUHK-SYSU上的对比:表1显示了在CUHK-SYSU测试集[32]上画廊大小为100的性能。在已有的两步方法中,IGPN[9]和TCTS[28]分别取得了90.3%和93.9%的mAP得分。在基于一步和两阶段检测的方法中,SeqNet[17]和DMRN[12]分别获得了93.8%和93.2%的mAP得分。最近引入的一步无锚框对齐[33]与相同的ResNet50骨干实现了93.1的mAP分数。我们使用相同的backbone实现了93.5%的mAP得分。就top-1精度而言,PSTR达到了95.0%,与最近引入的AlignPS[33]相比,绝对提高了1.6%,同时在相同的Resnet50骨干网下,运行速度略快(AlignPS: 61ms vs. PSTR: 56ms)。此外,在使用基于transformer的PVTv2-B2骨干网络时,所提PSTR取得了更好的效果,mAP和top-1准确率分别达到95.2%和96.2%。值得一提的是,PVTv2-B2和ResNet50骨干网的参数是可比较的。

表1:在CUHK-SYSU和PRW测试集上mAP和top-1准确率的最新比较。与最近在CHUK-SYSU上引入的无锚点对齐相比,使用相同的ResNet50骨干网络,PSTR在mAP和top-1精度方面都取得了良好的结果。在PRW上,PSTR在mAP和top-1精度方面分别比使用相同ResNet50骨干网的对齐实现了3.6%和5.9%的绝对增益。此外,PSTR在两个数据集上使用基于Transformer的PVT骨干获得了最佳报告结果。
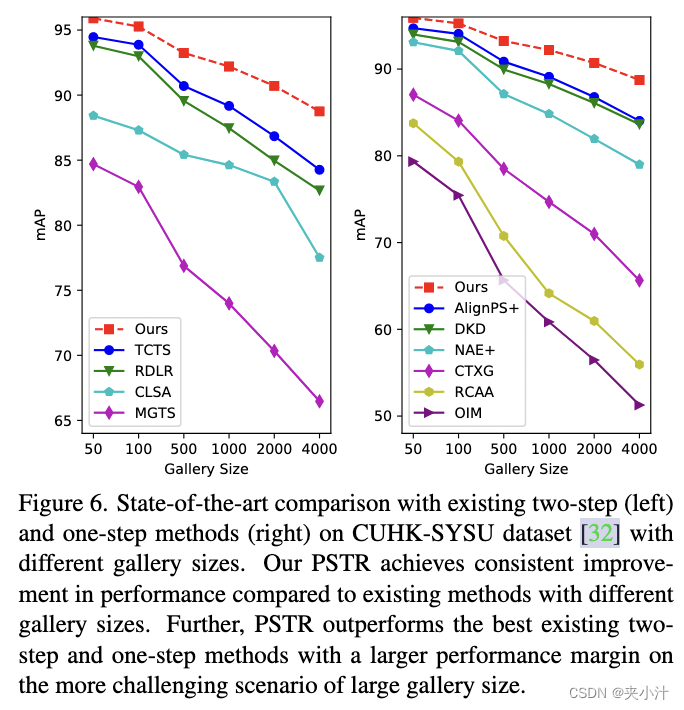
我们进一步在CUHK-SYSU测试集上进行了最先进的性能比较,图库大小从50到4,000不等。图6将我们的PSTR与现有的两步和一步方法在mAP方面进行了比较。我们的 PSTR 在不同的图库大小下始终优于现有的行人搜索方法。
![图6:在CUHK-SYSU数据集[32]上与现有的两步方法(左)和一步方法(右)进行了不同画廊大小的最新比较。](https://i-blog.csdnimg.cn/blog_migrate/679bee9a9df3e42deab943edc482eb95.png)
图6:在CUHK-SYSU数据集[32]上与现有的两步方法(左)和一步方法(右)进行了不同画廊大小的最新比较。与具有不同图库大小的现有方法相比,PSTR在性能上取得了一致的提高。此外,PSTR在更具有挑战性的大图库规模的场景下,表现出了更大的性能余量,优于现有最好的两步和一步方法。
PRW对比:表1显示了在PRW测试集[39]上的最新对比。在已有的两步方法中,TCTS[28]和IGPN[9]分别取得了46.8%和47.2%的mAP得分和87.5%和87.0%的top-1准确率得分。在基于一步两阶段检测的行人搜索方法中,DMRN[12]和SeqNet[17]的mAP得分分别为46.9%和46.7%,top-1准确率得分分别为83.3%和83.4%。AlignPS[33]分别取得了45.9%和81.9%的mAP和top-1准确率。使用相同的ResNet50骨干网,PSTR在mAP和top-1精度方面实现了3.6和5.9的绝对提升。请注意,与AlignPS不同,我们基于transformer的onestep PSTR不依赖于NMS后处理步骤。
此外,我们与 SeqNet 变体 (SeqNet†) 进行了比较,后者进一步在 SeqNet 中引入了后处理策略来细化查询和图库之间的匹配分数。为了与 SeqNet† 进行公平比较,我们在 PSTR(命名为 PSTR†)中引入了相同的匹配分数策略,实现了 50.1% 和 89.2% 的 mAP 和 top-1 准确率,对应于比 SeqNet† 绝对增益 2.5% 和 1.6%。我们还与 [37] 最近的工作进行了比较,该工作引入了人员搜索方法 DKD,其中采用了一种新颖的知识蒸馏策略。然而,DKD 需要分别训练 re-id 模型和人员搜索模型以及仔细的增强设计。此外,DKD 需要更长的训练(与我们的相比长 4× 以上)。我们的 PSTR 实现了良好的 top-1 性能(DKD:87.1% 与 Ours:87.8%),而推理速度快 25%。此外,我们的 PSTR 不需要专门的训练方案(re-id 的单独模型以及人员搜索和更长的训练)。最后,我们利用我们的一步 PSTR(没有任何后处理步骤)和 PVTv2-B2 主干(表1),在该数据集上报告的最佳结果,mAP 和 top-1 准确率分别为 56.5% 和 89.7%。
4.3 Ablation Study
使用共享 re-id 解码器进行多级监督:表2(a) 显示了在我们的 reid 解码器中使用共享解码器设计(共享 re-id 解码器)进行多级监督的影响,如图 4( c ) 所示。当使用单个 re-id 解码器(图 4 (a))并将最后一个检测解码器的特征作为输入时,我们在 mAP 上获得了 47.4%,在 top-1 准确度上获得了 84.9%。与单级监督设计相比,我们的并行re-id解码器设计中多级监督方案(图4 (b)))在mAP和top-1精度方面的绝对增益分别为4.0%和2.1%。当使用我们的多级监督与共享解码器设计(共享 re-id 解码器)时,可以获得最好的结果。值得一提的是,上述所有监督级别(单个或多级)都仅在训练期间使用。在推理时,来自最后一个检测解码器的特征被用作上述所有方法 (ac) 的 re-id 解码器的输入。这些结果表明,具有共享解码器设计的多级监督能够更好地重新识别特征学习。
输入特征对 re-id 解码器的影响:表2(b) 显示了不同输入特征对判别 re-id 解码器的影响。当使用检测编码器的输出特征作为 re-id 解码器的输入特征时,性能下降。例如,当将最后一个检测编码器的输出特征作为 re-id 解码器的输入时,mAP 的性能下降了 4.4%。这种下降可能是由于检测(对象级识别)和 re-id(实例级匹配)的不同目标。
部分注意块的影响:我们还将标准可变形注意力与我们在表2中的部分注意力进行了比较。部分注意力在 mAP 上提高了 0.4%,top-1 准确度提高了 0.5%。

表2:不同设计选择对判别式re-id解码器的影响。(a)不同解码器结构的影响,如图4所示,包括单个re-id解码器、并行re-id解码器和共享re-id解码器。(b)不同特征对re-id解码器的影响,包括来自检测编码器层1、2、3和骨干的特征。©不同注意力层的影响,包括可变形注意力和局部注意力。
多尺度re-id解码器:最后,我们将多尺度re-id解码器与表3中的单尺度、双尺度和三尺度进行对比,分析其影响。展示了多尺度重识别解码器的影响,包括单尺度重识别解码器、双尺度重识别解码器和三尺度重识别解码器。多尺度re-id解码器将最后N个特征图作为不同分支的输入。三尺度re-id解码器取得了最佳性能。展示了三尺度re-id解码器中单个尺度的性能。

表3:多尺度re-id解码器的影响。上面展示了单尺度、双尺度和三尺度re-id解码器的性能。下图显示了我们的具有三个尺度的多尺度re-id解码器的单个尺度的性能。
定性结果:我们首先在图9中提供了PSTR与最先进的AlignPS+[33]之间的一些定性比较。对于给定的查询人,显示top-1匹配结果。与AlignPS+算法相比,PSTR算法成功地检测和识别了不同场景下的人物。我们进一步在图7和图8中展示了CUHK-SYSU测试集[32]和PRW测试集[39]上的一些定性结果。PSTR在不同挑战场景下准确识别了图库图像中的查询人。

图7:在CUHK-SYSU测试集[32]上的定性结果。我们展示了五个不同查询的前两个匹配结果。所提出的PSTR能够在复杂的室外和室内场景下准确地检测和识别查询行人。
图8:PRW测试集[39]的定性结果。我们展示了四种不同的查询的前两次匹配结果。我们的 PSTR 准确地检测和识别不同相机中的查询行人。

图9:与AlignPS+[33]定性比较。我们展示了AligPS+和PSTR的top-1匹配结果。对于这三个查询,我们的PSTR都实现了正确的匹配。
5.Conclusion and Limitations
我们提出了一种基于端到端Transformer的一步的行人搜索方法,称为 PSTR。在 PSTR 中,我们引入了一种新的行人搜索专用 (PSS) 模块来检测和重新识别。PSS 模块包括一个检测编码器-解码器和一个判别重识别解码器,它使用具有共享解码器的多级监督方案来更好地进行重新识别特征学习。此外,它利用部分注意块来捕获不同部分之间的关系。此外,我们介绍了我们的 re-id 解码器的简单多尺度扩展。在两个基准上的实验揭示了拟议贡献的好处,导致两个数据集的最新结果。我们观察到我们的 PSTR 偶尔会在严重遮挡或极端弱光条件下挣扎。我们将在未来利用它。与其他视觉任务(即人脸识别)类似,如果不可靠地部署,则行人搜索可能会侵犯个人隐私。在未来使用行人搜索或其他视觉技术来保护公民安全时,建立相关的法律和政策是很重要的。
确认:这项工作得到了国家重点研发计划(2018AAA0102800)、国家自然科学基金(61906131)、天津市自然科学基金(21JCQQNJC004020)和CAAI-Huawei MindSpore开放基金的支持。















 4089
4089

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}