









Cascade Transformers for End-to-End Person Search
Abstract
行人检索的目标是从一组场景图像中定位目标行人,由于尺度变化、姿态/视角变化和遮挡,这个任务十分具有挑战性。本文提出级联遮挡注意力Transformer (Cascade Occluded Attention Transformer, COAT)用于端到端行人搜索。三级级联的设计重点是在第一阶段检测行人,而随后的两个阶段同时完成并逐步完善行人检测和重识别的表示。在每个阶段,遮挡注意力Transformer在联合阈值上应用更严格的交叉,迫使网络学习粗到细的姿态/尺度不变特征。同时,本文还计算了每个检测的遮挡注意力,以区分一个人的token与其他行人或背景。通过这种方式,我们模拟了在token级别上其他物体遮挡感兴趣的行人的效果。通过全面的实验,在两个基准数据集上取得了最先进的性能,证明了本文所提出方法的好处。
Journal:2022 IEEE/CVF CONFERENCE ON COMPUTER VISION AND PATTERN RECOGNITION (CVPR)
DOI地址:DOI10.1109/CVPR52688.2022.00712
论文地址:https://arxiv.org/abs/2203.09642
会议日期:JUN 18-24, 2022
作者名称:Rui Yu1,2*, Dawei Du1, Rodney LaLonde1, Daniel Davila1, Christopher Funk1,Anthony Hoogs1, Brian Clipp1 ,1Kitware, Inc., NY & NC, USA,2Pennsylvania State University, PA, USA
代码地址:https://github.com/Kitware/COAT
1.Introduction
行人检索旨在从场景图像库集中定位特定的目标行人,这是一个极其困难的细粒度识别和检索问题。一个行人检索系统必须既泛化以将行人从背景中分离出来,又专门化以区分彼此的身份。
在实际应用中,行人检索系统必须在各种尺寸的图像中检测行人,并在分辨率和视角发生较大变化的情况下重新识别行人。为此,现代行人搜索方法,无论是两步法还是一步法(即端到端),都由可靠的行人检测和判别性特征嵌入学习组成。两步方法[5,10,13,18,30,38]对由单独的目标检测器发现的裁剪的行人块进行行人重识别(ReID)。相比之下,端到端方法[2,20,32 - 34,39]在更高效的多任务学习框架中共同解决检测和重识别子任务。然而,如图1所示,它们仍然面临三个主要挑战:

图1,行人搜索的主要挑战:尺度变化、姿态/视角变化和遮挡。相同颜色的方框表示相同的ID。为了更好地观察,我们在右下角突出显示了小规模的个体。
- 行人检测和行人重识别在特征学习上存在冲突。行人检测旨在学习在人群中泛化的特征,以区分人与背景,而行人重识别旨在学习在人群中不泛化但能区分人与人的特征。现有工作遵循"重识别优先"[33]或"检测优先"[20]原则,让一个子任务优先于另一个子任务。然而,在依赖任一优先策略时,很难平衡两个子任务在不同情况下的重要性。
- 显著的尺度或姿态变化增加了身份识别的难度。特征金字塔或可变形卷积[14,18,33]已被用于解决特征学习中的尺度、姿态或视角失调。然而,简单的特征融合策略可能会在特征嵌入中引入额外的背景噪声,导致重识别性能较差。
- 与背景物体或其他行人的遮挡会使外观表示更加模糊。以往的行人搜索方法大多采用基于锚点的[20]或无锚点的[33]方法对行人进行整体外观建模。尽管行人搜索的准确性有所提高,但在复杂的遮挡情况下,这些方法仍然容易失败。
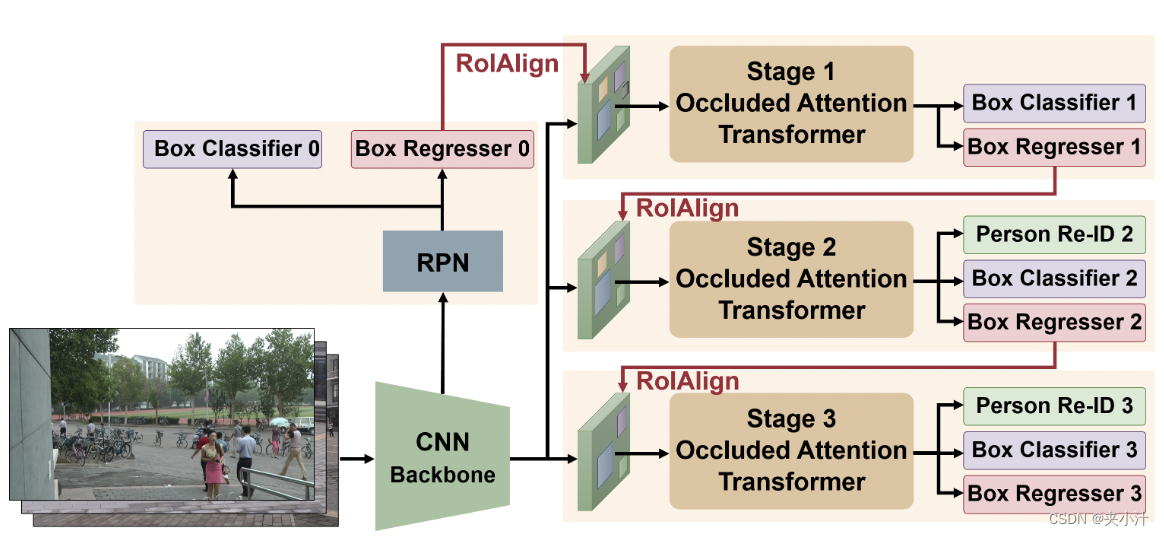
为了应对上述挑战,如图2所示,本文提出一种新的级联遮挡注意力Transformer (COAT)用于端到端行人搜索。首先,受方法Cascade R-CNN[1]的启发,本文分三个阶段采用由粗到细的策略来提高行人检测和行人重识别的质量。第一阶段侧重于从背景中区分人(检测),但关键是,没有经过训练来区分人与人(重识别),其中重识别损失后期包括检测和重定向损失。这种设计提高了检测性能(见第4.3节),因为第一阶段可以在行人中泛化,而无需区分行人。后续阶段同时完善前一阶段的边界框估计和身份嵌入(见表1)。其次,在级联的每个阶段应用多尺度卷积Transformer,将基本特征图划分为对应不同尺度的多个切片。Transformer的注意力鼓励网络学习每个尺度上每个人的可区分部分的嵌入,有助于克服区域不对齐的问题。用一种遮挡注意力机制来增强Transformer的学习特征嵌入,该机制综合地模拟了遮挡。在小批量中随机混合实例的部分token,并学习每个实例的token库之间的交叉注意力。这训练了Transformer将token与其他前景和背景检测建议区分开。在具有挑战性的CUHK-SYSU[32]和PRW[38]数据集上的实验表明,所提出的网络优于现有的端到端方法,特别是在PRW数据集上的跨摄像机设置方面。

图2,提出的级联式行人搜索框架。
本文贡献:
- 提出了第一个基于级联Transformer的端到端行人搜索框架。渐进式设计有效地平衡了行人检测和行人重识别,Transformer有助于处理尺度和姿态/视角的变化。
- 在多尺度Transformer中使用遮挡注意力机制来提高性能,在遮挡场景中生成有判别力的细粒度人物表示。
- 在两个数据集CUHK-SYSU和PRW上的实验结果表明,COAT方法优于现有的行人搜索方法。
2.Related Work
行人搜索:行人搜索方法大致可以分为两步法和一步法(端到端)的两种方法。两步法[5,10,13,18,30]依次将行人检测器(例如Faster R-CNN [27], RetinaNet[22]或FCOS[28])和行人识别模型相结合。例如,Wang等人在[30]中构建了一个行人搜索系统,其中包括一个身份引导的查询检测器和一个适应于ReID模型的检测结果检测器。另一方面,一步法(端到端法)[6,20,32,33]将两种模型集成到一个统一的框架中,以提高效率,[6]共享行人检测和行人重识别特征,但在极坐标系中将其分解为径向范数和角度。Yan等人[33]提出了第一个无锚点的行人搜索方法,在不同层面(即规模、区域和任务)解决了不对齐问题。Li和Miao[20]分享了行人检测和行人重识别的主干表示,但通过双头网络依次解决这两个子任务。受Cascade R-CNN[1]的启发,本文所提出方法遵循一种基于端到端的策略,通过一个三阶段的级联框架逐步平衡行人检测和行人重识别。
行人重识别中的视觉Transformer:视觉Transformer (ViT)[11]是在原始的用于自然语言处理的transformer模型[29]的基础上,第一个用于提取特征用于图像识别的纯Transformer网络。在CNN被广泛用于提取基本特征后,减少了纯Transformer方法所需的训练数据规模。Luo等人[25]开发了一个空间Transformer网络,从整体图像中采样一个仿射图像以匹配部分图像。Li等人[19]提出了部分感知Transformer,通过不同的部分发现来执行遮挡行人重识别。Zhang等人[36]引入了一种基于Transformer的特征校准,将大规模特征作为全局先验进行集成。本文是文献中第一个用多尺度卷积Transformer进行行人搜索的论文。它不仅可以学习到有判别力的ReID特征,还可以通过级联管道将行人与背景区分开。
Transformer中的注意力机制:注意力机制在Transformer中起着至关重要的作用。最近,许多ViT变体[3,16,21,35]已经使用各种token attention方法计算出了具有判别力的特征。Chen等人[3]提出了一种带有交叉注意力token融合模块的双分支Transformer,以结合两种尺度的块特征。[21]交替在特征图块上进行注意力的局部表示,在单通道特征图上进行注意力的全局表示。Yuan等人[35]引入标记到标记的过程,在保留结构信息的同时逐步将图像标记为标记。[16]通过shift和patch shuffle操作重新排列transformer层的patch嵌入。与这些在实例内重新排列特征的方法不同,所提出的遮挡注意力模块考虑了来自小批量的正实例或负实例之间的token交叉注意力。因此,该方法学会了通过综合模仿遮挡来区分token与其他物体。
3.Cascade Transformers
正如之前的工作[14,20,33]所讨论的,行人检测和行人重识别的目标是冲突的。因此,很难在骨干网络顶部联合学习两个子任务的有判别力的统一表示。与方法Cascade R-CNN[1]类似,本文将特征学习分解为多尺度Transformer的T阶段中的顺序步骤。也就是说,Transformer中的每个头逐级细化预测目标的检测和重识别精度。因此,我们可以逐步学习从粗到细的统一嵌入。
然而,在被其他人、物体或背景遮挡的情况下,网络可能会受到目标身份的噪声表示的影响。本文在多尺度Transformer中开发了遮挡注意力机制来学习遮挡鲁棒表示。如图2所示,我们的网络是基于Faster R-CNN目标检测器骨干与区域候选网络(Region Proposal Network, RPN)。通过引入一个级联的遮挡注意力Transformer(见图3)来扩展框架,以端到端的方式进行训练。

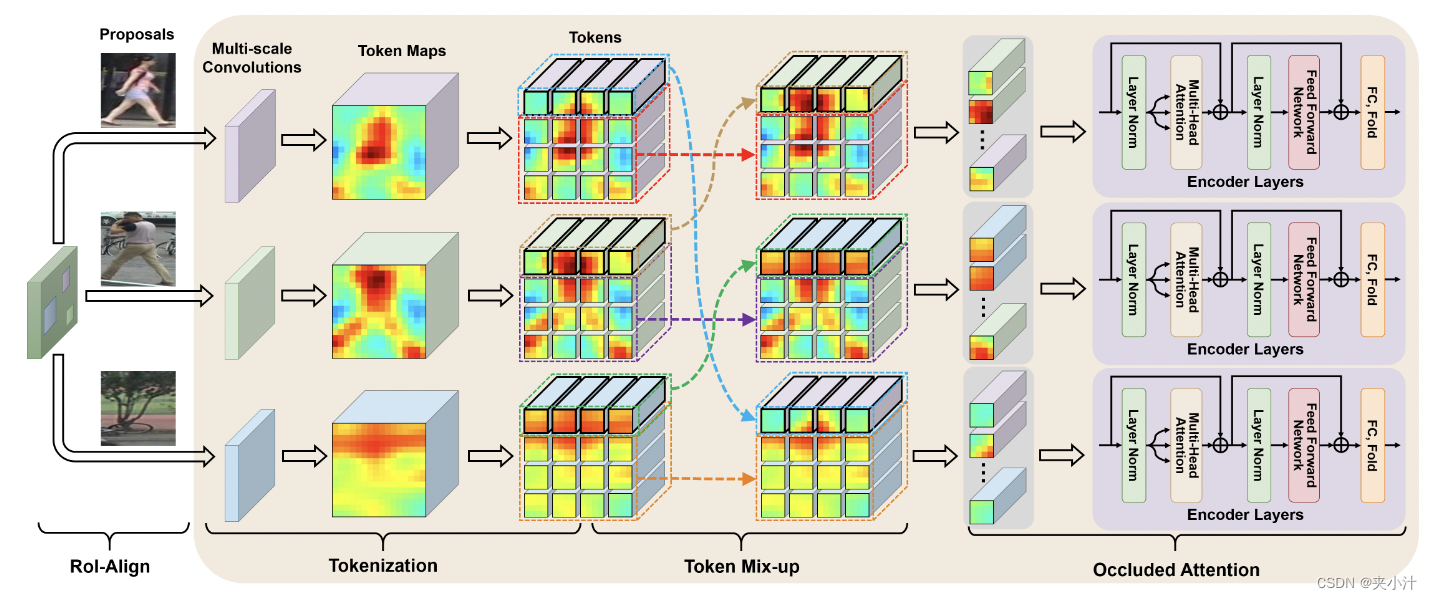
图3,遮挡注意力Transformer的架构。在一个mini-batch中,用于token交换的随机选择的区域是相同的。为清晰起见,只在一个mini-batch中显示了三个实例,并在一个尺度上显示了遮挡注意力。最好的观察视图使用彩色。
3.1.Coarse-to-fine Embeddings
从粗粒度到细粒度
从ResNet-50[15]主干提取1024维特征图后,使用RPN生成区域候选框。对于每个候选区域,应用RoI-Align操作[27]池化一个h × w区域作为基础特征图F,其中h和w分别表示特征图的高度和宽度,c为通道数。
然后,我们采用多级级联结构来学习行人检测和行人重识别的嵌入。RPN的输出候选框在第一阶段用于重新采样正负实例,然后采用第一阶段的框(box)输出作为第二阶段的输入,依此类推。在每个阶段t,每个候选框的池化特征图被发送到该阶段的卷积Transformer。为了获得高质量的实例,级联结构逐渐施加越来越严格的阶段约束。在实际应用中,我们逐步提高了交并比(Intersection over Union, IoU)阈值。每个阶段的Transformer后面都有三个头,如NAE[6],包括一个人/背景分类器、一个候选框回归器和一个行人重识别鉴别器。请注意,我们在第一阶段删除了行人重识别鉴别器,以便在细化之前将网络集中于首先检测场景中的所有行人。
3.2.Occluded Attention Transformer
遮挡注意力Transformer
在下文中,我们描述了遮挡注意力Transformer的细节,如图3所示。
标记化。给定一个基础特征图
F
ˉ
=
R
h
×
w
×
c
^
\bar{\mathcal F}=\mathbb R^{h \times w \times \hat{c}}
Fˉ=Rh×w×c^,其中
c
^
=
c
n
\hat{c}=\frac{c}{n}
c^=nc处理每个规模的token。与ViT[11]对大图像块进行标记化相比,我们的Transformer利用一系列卷积层来基于切片特征映射生成标记
F
ˉ
\bar{\mathcal F}
Fˉ。我们的方法受益于CNN的归纳偏差,并学习CNN的局部空间上下文,让不同的尺度由不同大小的卷积核来实现。
在将切片特征图
F
ˉ
=
R
h
×
w
×
c
^
\bar{\mathcal F}=\mathbb R^{h \times w \times \hat{c}}
Fˉ=Rh×w×c^转换为新的token映射图
F
ˉ
=
R
h
^
×
w
^
×
c
^
\bar{\mathcal F}=\mathbb R^{\hat{h} \times \hat{w} \times \hat{c}}
Fˉ=Rh^×w^×c^后,我们将其展平为一个实例的token输入
x
=
R
h
^
w
^
×
c
^
\textbf x=\mathbb R^{\hat{h} \hat{w} \times \hat{c}}
x=Rh^w^×c^,token的数量计算为:
N
=
h
^
w
^
d
2
=
⌊
h
+
2
p
−
k
s
+
1
⌋
×
⌊
w
+
2
p
−
k
s
+
1
⌋
d
2
N=\frac{\hat{h} \hat{w}}{d^2}=\frac{\lfloor \frac{h+2p-k}{s}+1 \rfloor \times \lfloor \frac{w+2p-k}{s}+1 \rfloor}{d^2}
N=d2h^w^=d2⌊sh+2p−k+1⌋×⌊sw+2p−k+1⌋其中我们有卷积层的内核大小
k
k
k、步幅
s
s
s和填充
p
p
p,
d
d
d是每个令牌的patch大小。
遮挡注意力。为了处理遮挡,我们在Transformer中引入了一种新的token级遮挡注意力机制来模拟实际应用中发现的遮挡。具体来说,我们首先从mini-batch中的所有检测候选框中收集token,表示为token库
X
=
{
x
1
,
x
2
,
.
.
.
,
x
P
}
\text X=\{\textbf x_1,\textbf x_2,...,\textbf x_P\}
X={x1,x2,...,xP},其中
P
P
P是每个阶段的批次中的检测候选框数量。由于来自RPN得候选框包含正实例和负实例,因此token库由前景的行人部分和背景的所有对象组成。我们基于所有实例的相同交换索引集
M
\mathcal M
M,在token库之间交换token。如图3所示,交换的token对应于token映射中语义一致但随机选择的子区域,每个交换的token表示为:
x
i
=
{
x
i
(
M
ˉ
)
,
x
j
(
M
)
}
,
i
=
1
,
2
,
.
.
.
,
P
,
i
≠
j
\textbf x_i=\{\textbf x_i(\mathcal{\bar M}),\textbf x_j(\mathcal M)\},i=1,2,...,P,i \neq j
xi={xi(Mˉ),xj(M)},i=1,2,...,P,i=j
其中,
x
i
\textbf x_i
xi表示从token库中随机选择的另一个样本,
M
ˉ
\mathcal{\bar M}
Mˉ表示
M
\mathcal M
M的补集,即
x
i
=
x
i
(
M
ˉ
)
∪
x
i
(
M
)
\textbf x_i=\textbf x_i(\mathcal{\bar M})\cup \textbf x_i(\mathcal M)
xi=xi(Mˉ)∪xi(M)。给定交换的token库
X
\textbf X
X,我们计算它们之间的多尺度自注意力,如图3所示。在每个token的规模方面,我们运行Transformer的两个子层(即多头自注意力MSA和前馈网络FFN,如[29]所示)。具体来说,通过三个独立的全连接层,混合token
x
\textbf x
x被转换成查询矩阵
Q
∈
R
h
^
w
^
×
c
^
\textbf Q \in \mathbb R^{\hat{h} \hat{w} \times \hat{c}}
Q∈Rh^w^×c^,键矩阵
K
∈
R
h
^
w
^
×
c
^
\textbf K \in \mathbb R^{\hat{h} \hat{w} \times \hat{c}}
K∈Rh^w^×c^和值矩阵
V
∈
R
h
^
w
^
×
c
^
\textbf V \in \mathbb R^{\hat{h} \hat{w} \times \hat{c}}
V∈Rh^w^×c^,我们可以进一步计算所有值的多头注意力和加权和为:
MSA
(
Q,K,V
)
=
softmax
(
Q
K
T
c
^
/
m
)
V
}
\text{MSA}(\textbf{Q,K,V})=\text{softmax}(\frac{\textbf{Q} \textbf{K}^{\text T}}{\sqrt{\hat c /m}})\textbf V\}
MSA(Q,K,V)=softmax(c^/mQKT)V}
其中,我们将查询、键和值分成m个头,以获得更多的多样性,即从尺寸为
h
^
w
^
×
c
^
\hat{h} \hat{w} \times \hat{c}
h^w^×c^的张量到大小为
h
^
w
^
×
c
^
m
\hat{h} \hat{w} \times \frac{\hat{c}}{m}
h^w^×mc^的张量。然后,将独立的注意力输出连接起来,并线性变换到预期维度。在 MSA 模块之后,FFN 模块非线性转换每个token以增强其表示能力。并且将增强的特征投影到
h
^
×
w
^
×
c
^
\hat{h} \times \hat{w} \times \hat{c}
h^×w^×c^大小,作为Transformer的输出。
最后,我们将n个尺度的Transformer的输出连接到原始空间大小
h
^
×
w
^
×
c
\hat{h} \times \hat{w} \times c
h^×w^×c。请注意,每个Transformer外都有一个残差连接。在全局平均池化(Global Average Pooling, GAP)层之后,提取的特征被馈送到后续头部以进行候选框的回归、行人/背景分类和行人重识别。
与并发工作的关系。不同领域有两个并发的基于ViT的工作[3,16]。Chen等人[3]开发了一个多尺度Transformer,包括两个具有小patch和大patch标记的单独分支,两种尺度表示基于交叉注意力token融合模块学习,其中每个分支的单个token被视为查询,以与其他分支交换信息。相反的是,我们利用一系列具有不同内核的卷积层来生成多尺度标记。最后,我们将Transformer特定切片中每个尺度对应的增强特征图连接起来。
为了解决行人重识别中的遮挡和错位问题,He等人[16]将行人部分patch嵌入,打乱并重新分组,每组包含单个实例的多个随机patch嵌入。该方法首先在mini-batch中交换实例的部分token,然后基于混合token计算遮挡注意力。因此,因此,最终嵌入部分涵盖了从不同行人或背景对象中提取特征的目标行人,从而产生更具遮挡鲁棒性的表示。
3.3.Training and Inference
在训练阶段,本文所提出的网络是基于端到端训练的,用于行人检测和行人重识别。行人检测损失
L
d
e
t
\mathcal L_{det}
Ldet由回归和分类损失项组成。前者是真实框和前景框之间回归向量的平滑-L1损失,而后者计算估计框预测分类概率的交叉熵损失。
为监督行人重识别,本文使用经典的非参数在线实例匹配(Online Instance Matching, OIM)损失[32]
L
OIM
\mathcal L_{\text{OIM}}
LOIM,其维护一个查找表(Lookup Table, LUT)和一个循环队列(Circle Queue, CQ),分别存储最近mini-batch中所有已标记和未标记身份的特征。我们可以有效地计算mini-batch和LUT/CQ中样本之间的余弦相似度,用于嵌入学习。受[24]启发,添加了另一个交叉熵损失函数
L
ID
\mathcal L_{\text{ID}}
LID来预测行人的身份,以进行额外的ID级监督。总之,我们通过使用以下多阶段损失来训练所提出的COAT方法:
c
c
c其中
t
∈
{
1
,
2
,
.
.
.
,
T
}
t \in \{1,2,...,T\}
t∈{1,2,...,T}表示阶段的索引,
T
T
T是级联阶段的数量。利用
λ
OIM
\lambda_{\text{OIM}}
λOIM和
λ
ID
\lambda_{\text{ID}}
λID系数平衡OIM和ID损失。
I
(
t
>
1
)
\mathbb I(t>1)
I(t>1)是表示我们在第一阶段不考虑行人重识别损失的指标函数。
在推理阶段,我们通过删除图3中的token混合步骤,将遮挡注意力机制替换为Transformer中的经典自注意力模块。我们在最后阶段输出具有相应嵌入的检测边界框,并使用NMS操作去除冗余框。
4.Experiments
所有实验都是在PyTorch中使用一个NVIDIA A100 GPU进行的。为了与之前的工作公平比较,本文使用ResNet-50[15]的前4个残差块(conv1 ~ conv4)作为骨干网络,并将图像大小调整为900 × 1500作为输入。
4.1.Datasets
本文在两个公开的数据集上评估了所提出方法。CUHK-SYSU数据集[32]在18,184张图像中标注了8,432个身份和96,143个边界框。对于6,978张图片中的2,900个测试身份,默认图库大小设置为100。PRW数据集[38]从6个摄像头收集数据,包括11,816帧中的932个身份和43,110个行人候选框。将PRW划分为包含5,704帧、482个身份的训练集和包含6,112帧、2,057个查询行人的测试集。
我们遵循行人检索的标准评估指标[32,38]。如果具有相同身份的预测框和真实框之间的重叠率大于0.5 IoU,则匹配框。对于行人检测,我们使用召回率和平均精度(AP)。对于行人重识别,我们使用平均精度均(mean Average Precision, mAP)和累积匹配特征(top-1)分数。
4.2.Implementation Details
与Cascade R-CNN[1]类似,我们级联框架中使用级联数量
T
=
3
T = 3
T=3个阶段,每个阶段每张图像提取128个检测候选框。根据[6,20,32],将基础特征图的比例尺设为
h
=
w
=
14
h = w = 14
h=w=14。图2中交换token的索引设为token映射中的随机横条或竖条。图3中的正面次数设为
m
=
8
m = 8
m=8。三个连续阶段的IoU检测阈值设置为
0.5
,
0.6
,
0.7
0.5,0.6,0.7
0.5,0.6,0.7。对于三个阶段,计算token的卷积层的核大小设置为
k
=
{
1
×
1
,
3
×
3
}
k = \{1 × 1,3 × 3\}
k={1×1,3×3},并设置相应的步长
s
=
{
1
,
1
}
s =\{1,1\}
s={1,1}和填充
p
=
{
0
,
1
}
p =\{0,1\}
p={0,1},以保证输出特征映射的大小相同。由于特征尺寸较小,我们在图2中设置
d
=
1
d = 1
d=1,即进行逐像素标记化。
CUHK-SYSU和PRW的OIM损失CQ值分别为5000和500。式子
L
=
∑
t
=
1
T
L
d
e
t
t
+
I
(
t
>
1
)
(
λ
OIM
L
OIM
t
+
λ
ID
L
ID
t
)
\mathcal L =\sum_{t=1}^T \mathcal L_{det}^t + \mathbb I(t>1)(\lambda_{\text{OIM}}\mathcal L_{\text{OIM}}^t+\lambda_{\text{ID}}\mathcal L_{\text{ID}}^t)
L=∑t=1TLdett+I(t>1)(λOIMLOIMt+λIDLIDt)中的损失权值设为
λ
OIM
=
λ
ID
=
0.5
\lambda_{\text{OIM}}=\lambda_{\text{ID}}=0.5
λOIM=λID=0.5。我们使用动量为0.9的SGD优化器训练模型15个epoch,初始学习率在第一个epoch期间升高到0.003,在第10个epoch时降低到原来的10倍。在推理阶段,我们使用具有0.4/0.4/0.5阈值的NMS来删除第一/第二/第三阶段检测到的冗余框。
4.3.Ablation Studies
我们在PRW数据集[38]上进行了一系列消融实验,以分析设计决策。
级联结构的贡献。为了显示级联结构的贡献,本文根据级联级数和IoU阈值评估了从粗到细的约束。
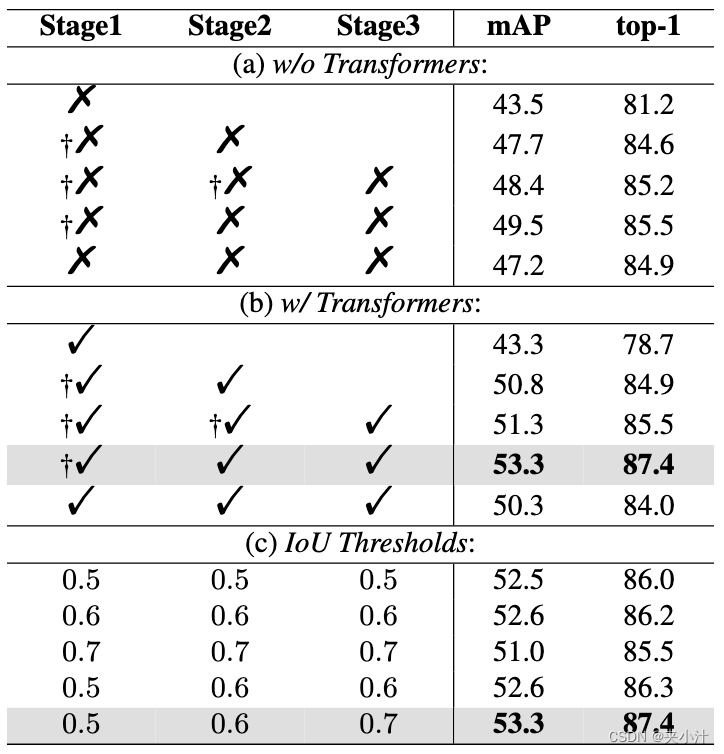
首先,在每个阶段用与[6,20,32]相同的ResNet块(conv5)替换遮挡注意力Transformer。如表1-a所示,级联结构在增加阶段数时显著提高了行人搜索精度,即:其中,mAP从43.5%提高到49.5%,top-1准确率从81.2%提高到85.5%。当引入所提出的遮挡注意力Transformer时,性能得到了进一步提高(见表1-b),这证明了遮挡注意力transformer的有效性。
此外,级联设计中不断增加的IoU阈值提高了行人搜索性能。如表1-c所述,每个阶段相同的IoU阈值产生的精度低于我们的方法。例如,如果
u
t
=
0.5
u_t= 0.5
ut=0.5或
u
t
=
0.7
u_t= 0.7
ut=0.7,则会引入更多的假阳性或假阴性。相比之下,该方法可以选择质量不断提高的检测候选框,以获得更好的性能。在第一阶段生成更多的候选检测,在第三阶段只生成高度重叠的检测。

表1,PRW[38]上COAT不同级联变体的比较。“%”意味着使用与[6,20,32]相同的ResNet块(conv5),而“!”意味着在每个阶段使用所提出的Transformer。"†"是指没有行人重识别损失的头。灰色高亮表示为我们的最终系统选择的参数。
行人检测与行人重识别的关系。正如引言中所讨论的,行人检测和行人重识别之间存在冲突。在图4中,我们探讨两个子任务之间的关系。将本文提出的COAT方法与最先进的NAE[6]和SeqNet[20]进行比较,它们具有相同的Faster R-CNN检测器。我们构造了三种具有不同阶段的COAT变体,即COAT-
t
t
t,其中
t
=
1
,
2
,
3
t= 1,2,3
t=1,2,3表示阶段的数量。当只考虑行人重识别而不是行人搜索时,即当给出ground-truth检测框时,COAT优于两个竞争对手(NAE和SeqNet),在top-1上提高了3%以上,在mAP上提高了6%以上。同时,我们的行人检测精度略低于SeqNet[20]。这些结果表明,改进的ReID性能来自于从粗到细的人嵌入,而不是更精确的检测。

图4,COAT和在PRW上的两种比较方法的检测和行人搜索结果,提供了(仅行人重识别)和不提供(行人搜索)的ground-truth检测框。∗表示使用ground-truth框的oracle结果。
我们还观察到,行人检测性能从
t
=
1
t = 1
t=1提高到
t
=
2
t = 2
t=2,但在
t
=
3
t = 3
t=3时略有下降。推测这是因为在权衡行人检测和行人重识别时,本文所提出方法COAT更侧重于学习行人重识别的判别性嵌入,同时略有牺牲检测性能。此外,从表1(a)(b)中可以看出,在第一阶段具有行人重识别损失的COAT变体的表现比我们的方法更差(mAP为50.3 vs. 53.3)。同时学习一个用于行人检测和行人重识别的鉴别表示是非常困难的。因此,我们在COAT方法的第1阶段删除了ReID鉴别器头(图2)。如果我们继续在第2阶段删除ReID鉴别器,ReID性能在mAP中下降了约2%。这表明ReID嵌入确实从多阶段细化中受益。
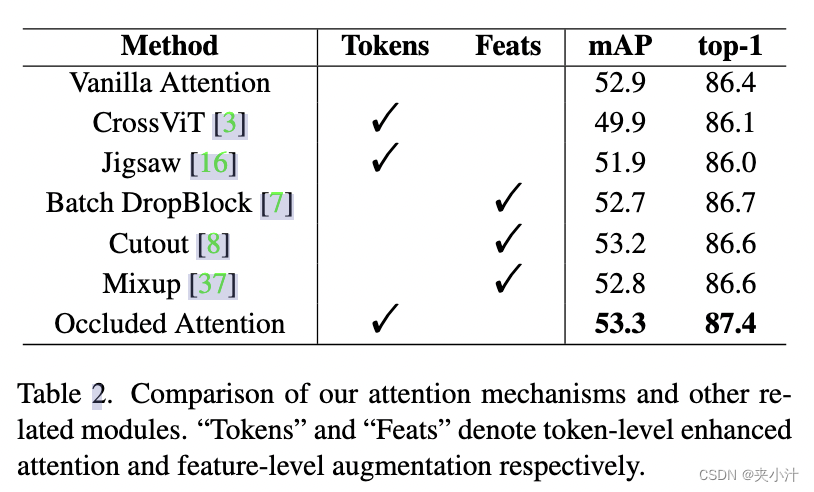
与其他注意力机制的比较。为验证遮挡注意力机制在Transformer中的有效性,本文将最近提出的Jigsaw[16]和CrossViT[3]应用在该方法中。如3.2节所述,Jigsaw Patch[16]通过shift和Patch shuffle操作来生成鲁棒的ReID特征。CrossViT[3]是一个双分支transformer,用于学习多尺度特征。还值得注意的是,它们利用大型图像块作为纯视觉transformer的输入。我们还评估了COAT变体一种香草自注意力机制,称为香草注意力。
在表2中,CrossViT[3]侧重于在两种尺度的token之间交换信息,出现了较差的mAP。结果表明,Jigsaw[16]对mAP也有一定影响。我们推测,在这样小的14 × 14基础特征图中,无论是在CrossViT[3]中交换查询信息,还是在Jigsaw[16]中的shift和shuffle特征操作都是不明确的,限制了它们用于行人搜索的能力。相比之下,本文所提出的遮挡注意力是针对小特征图设计的,并获得了更好的性能,在mAP上提高了0.4%,在top-1分数上提高了1.0%。本文没有在不同的分支中共享类标记,也没有基于单个实例对特征图的通道进行混洗,而是在小批量中有效地学习不同实例的上下文信息,并将人与其他人或背景区分开来,以合成地模仿遮挡。

表2:我们的注意力机制和其他相关模块的比较。“Tokens”和“Feats”分别表示令牌级增强注意力和特征级增强。
与特征增强的比较。我们的方法与之前针对行人重识别的增强策略相关,如Batch DropBlock Network[7]、Cutout[8]和Mixup[37]。如表2所示,使用特征增强并没有提高行人搜索的精度,只是用零来增加特征块。
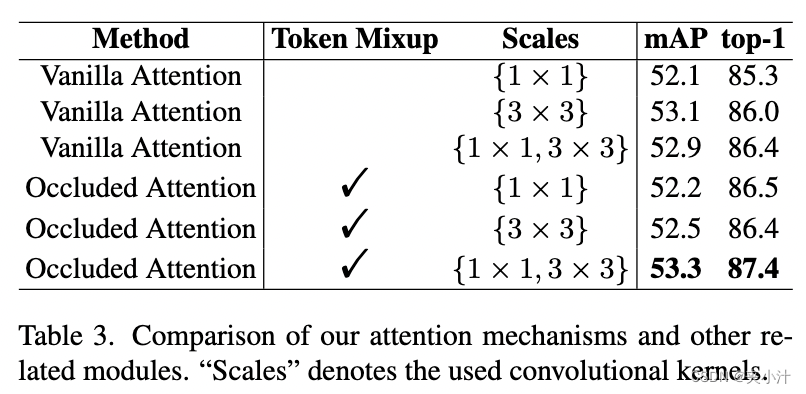
遮挡注意力机制的影响。如3.2节所述,我们使用遮挡注意力来计算具有判别力的行人嵌入。我们在表3中评估了遮挡注意力(token mixup)和不同尺度的使用。注意,在遮挡注意力的情况下,top-1分数从86.4提高到87.4,并且用于分词的多个卷积核提高了性能。请注意,多个卷积不会增加模型大小,因为特征图
F
{\mathcal F}
F是为每个尺度进行通道切片的。

表3:我们的注意力机制和其他相关模块的比较,“Scales”表示使用的卷积核。
4.4.Comparison with State-of-the-art
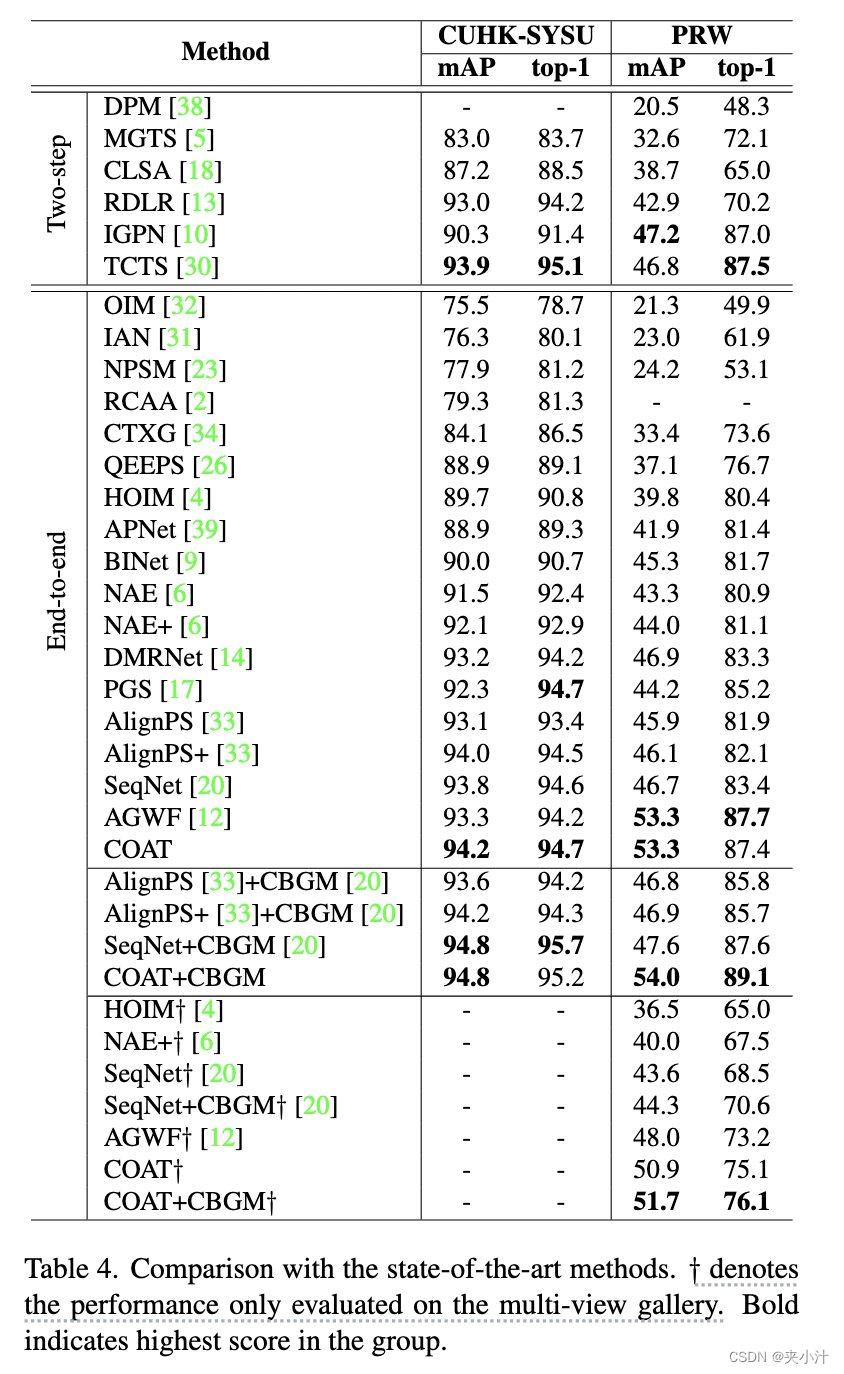
如表4所示,在两个数据集上,我们将我们的COAT与最先进的算法进行了比较,包括两步方法[5,10,13,18,30,38]和一步(端到端)方法[2,4,6,9,12,17,20,23,26,31 - 34,39]。

表4:与最先进的方法的比较。† 表示仅在多视图图库上评估的性能。粗体表示组中得分最高的分数。
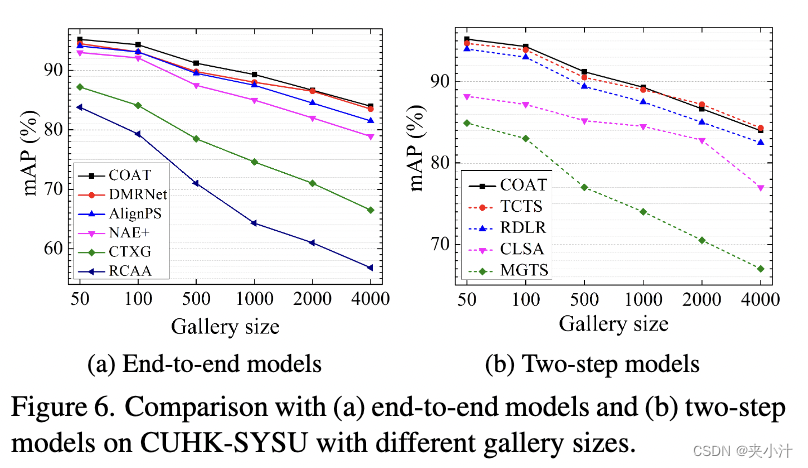
在数据集CUHK-SYSU上的结果。在gallery大小为100的情况下,与最佳的两步法方法TCTS[30]相比,该方法取得了最好的94.2% mAP和94.7%的top-1分数,其中明确训练了边界框和ReID特征细化模块。在端到端方法中,所提方法的性能优于目前最先进的多尺度无锚框表示的AlignPS+[33]、两阶段细化的SeqNet[20]和基于部分分类的子网络AGWF[12]。结果表明了所提出的级联多尺度表示的有效性。利用后处理操作CBGM (Context Bipartite Graph Matching)[20],该方法的mAP和top-1得分均有小幅提高。为了进行综合评估,如图6所示,我们在增加图库大小时比较了竞争方法的mAP分数。由于在图库集中考虑更多分散注意力的人是一件具有挑战性的事情,所以所有比较方法的性能都会随着图库大小的增加而降低。然而,所提出方法始终优于所有端到端方法和大多数两步方法。当图库规模大于1000时,该方法的性能略低于两步TCTS[30]。

图6:与(a)端到端模型和(b)不同图库大小的CUHK-SYSU两步模型的比较。
在数据集PRW上的结果。虽然PRW数据集[38]比CUHK-SYSU数据集[32]更具挑战性,训练数据更少但gallery规模更大,但结果显示出相似的趋势。该方法取得了与AGWF[12]相当的性能,与SeqNet[20]相比,mAP和top-1得分分别提高了6.7%和4.0%。与本文方法中的Faster R-CNN[27]相比,DMRNet[14]和AlignPS[33]利用了更强的目标检测器,如RetinaNet[22]和FCOS[28],但仍然取得了较差的性能。此外,我们比较了PRW的多视图库(见表4中“†”标记的组)的性能。所提出方法在mAP和Top-1分数方面都优于现有方法,具有明显的优势。将这归因于级联transformer结构,该结构产生了更有判别力的ReID特征,特别是在姿态/视角发生显著变化的跨相机环境中。
定性结果。两个数据集上的一些示例行人搜索结果如图5所示。我们的方法可以处理轻微/中度遮挡和比例/姿势变化的情况,而其他最先进的方法,如SeqNet[20]和NAE[6]在这些情况下失败。

图5:PRW(第一行)和CUHK-SYSU(第二行和第三行)数据集上NAE[6]、SeqNet[20]和COAT的前1人搜索结果的定性示例,其中小查询、失败和正确情况分别用黄色、红色和绿色框突出显示
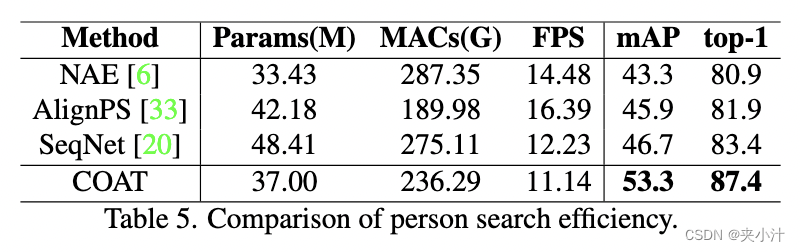
效率比较。我们将效率与 NAE [6]、AlignPS [33] 和 SeqNet [20] 三个具有代表性的端到端网络进行比较,这些网络具有公开发布的源代码。我们使用相同的尺度测试图像和相同的 GPU 评估方法。
从表5中,我们比较了参数数量、乘累加操作(mac)和每秒帧数(FPS)的运行速度。与其他对比方法相比,该方法的计算复杂度更低,速度略慢,但在mAP和top-1精度上分别取得了+6.6%和+4.0%的提升。与[11,16]相比,COAT在Transformer中只采用了一个编码器层,并使用多尺度卷积来减少标记化前的通道数量,提高了涂层的效率。

表5:行人搜索效率比较
5.Conclusion
本文开发了一种新的级联遮挡注意力Transformer (COAT)用于端到端行人搜索。值得注意的是,COAT通过一个级联Transformer框架为行人检测和行人识别学习了一种具有判别力的从粗到细的表示。同时,遮挡注意力机制综合地模拟来自前景或背景目标的遮挡。COAT优于最先进的方法,我们希望这将激发更多基于Transformer的行人搜索方法的研究。
伦理方面的考虑:与大多数技术一样,行人搜索方法可能会带来社会效益和负面影响。如何使用这项技术至关重要。例如,行人搜索可以识别有关行人,以协助执法和反恐行动。然而,这项技术应该仅用于进入非隐私的地方,如公共区域、机场和有明确标识的私人建筑。这些系统不应在没有合理理由的情况下使用,也不应由试图获取其所有公民的无处不在活动信息以使迫害和镇压成为可能的不公正的政府使用。
为了可比性,本研究使用了之前工作中收集的人类受试者图像。CUHK-SYSU[32]是从“街拍”和“电影快照”中收集的,而PRW[38]是在大学校园的公共区域用摄像机收集的。这两篇论文都没有提到道德委员会(例如,机构审查委员会)的审查,但这些论文是在CVPR或大多数主要人工智能会议上建立这个新标准之前发表的。但这些论文是在 CVPR 或大多数主要 AI 会议上建立这个新标准之前发布的。我们的偏好将是与道德收集的人员搜索数据集一起工作,欢迎来自其道德合规作者的公共披露。我们相信社区应该专注于开发伦理人员搜索数据集的资源,并指出使用遗留、不道德收集的数据集。
确认:该材料基于美国空军在合同号FA8650-19-C-6036下支持的工作。本材料中表达的任何意见、发现和结论或建议都是作者的观点,不一定反映美国空军的观点。
6.Our Experiments
表6-1 本实验的相关配置和具体参数
| 实验配置 | 具体参数 |
|---|---|
| GPU | RTX 3090(24GB) |
| CPU | 15 vCPU AMD EPYC 7542 32-Core Processor |
| 内存 | 80GB |
| 数据集 | CUHK-SYSU |
| 图片尺寸 | 900 × 1500 |
| 骨干网络 | ResNet-50 |
| 服务器环境 | Auto DL |
表6-2 本实验所需要的安装包和具体版本
| 安装包 | 具体版本 |
|---|---|
| cudatoolkit | 11.0 |
| numpy | 1.19.2 |
| pillow | 8.2.0 |
| pip | 21.0.1 |
| python | 3.8.8 |
| pytorch | 1.7.1 |
| scipy | 1.6.2 |
| torchvision | 0.8.2 |
| tqdm | 4.60.0 |
| scikit-learn | 0.24.1 |
| black | 21.5b0 |
| flake8 | 3.9.0 |
| isort | 5.8.0 |
| tabulate | 0.8.9 |
| future | 0.18.2 |
| tensorboard | 2.4.1 |
| tensorboardx | 2.2 |
本实验基于CUHK-SYSU数据集在不同实验条件下的实验结果如表6-3所示。由于算法涉及多个Transformer结构,所以训练时所需要的显存较大。为了满足更高需求的batch_size,在选择GPU上本实验进行了两种选择,并分别进行了测试。实验结果表明,当batch_size增加时,各项指标都有所提升。但由于本实验没有在多个同GPU下进行并行实验,所以实验还有一定的不足之处。
表6-3 基于CUHK-SYSU数据集的实验结果
| GPU | 学习率 | batch_size | epoch | mAP | top-1 | top-5 | top-10 |
|---|---|---|---|---|---|---|---|
| A100 | 0.003 | 4 | 12 | 93.44% | 93.93% | 98.03% | 98.55% |
| RTX 3090 | 0.003 | 2 | 12 | 92.41% | 93.07% | 97.72% | 98.21% |
| RTX 3090 | 0.003 | 2 | 1 | 41.64% | 45.21% | 58.21% | 62.21% |
针对同一GPU的不同学习率,本文进行了实验。batch_size的调整要配合学习率的调整,一般是正比关系,batch_size增大两倍,学习率增大两倍或者根号二倍。减小也是相应更改。所以此处经过调整后,结果有了提升,如表6-4所示。
表6-4 基于CUHK-SYSU数据集的优化实验结果
| GPU | 学习率 | batch_size | epoch | mAP | top-1 | top-5 | top-10 |
|---|---|---|---|---|---|---|---|
| RTX 3090 | 0.003 | 2 | 1 | 41.64% | 45.21% | 58.21% | 62.21% |
| RTX 3090 | 0.002 | 2 | 1 | 44.89% | 48.52% | 62.52% | 66.69% |
| RTX 3090 | 0.002 | 2 | 2 | 79.32% | 80.72% | 91.55% | 94.10% |
总结实验结果,我对算法的未来改进思路如下:
- 针对OIM和IDLoss进行修改:OIM损失函数需要计算每个样本与所有其他样本之间的相似度,因此训练时间复杂度较高。在大规模数据集上训练模型时,训练时间可能会变得非常长。如果负样本选择不当,可能会导致模型训练不稳定或分类性能下降。可以尝试引入Triplet Loss和Contrastive Loss进行修改;
- 对于Transformer结构优化:由于显存不足,可以尝试使用梯度累积模拟更大的batch,或者使用动态填充模拟数据批量训练;
- 尝试引入稀疏注意力进行优化;
- 更改骨干网络进行训练,如PVT等;
- 设置更多的子实验及消融实验,比如实现数据集PRW上的算法评估。

















 1304
1304

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}